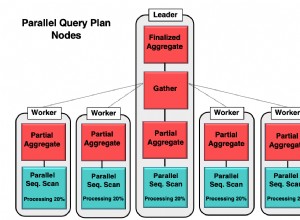
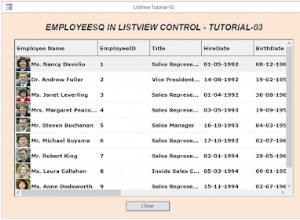
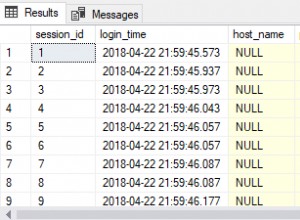
Jeśli nie masz absolutnie żadnych danych na temat swojego problemu, jesteś zmuszony do oszacowania.
Ogólna forma tej formuły jest wyjaśniona w komentarzach:
- jeśli używamy tylko jednej kolumny klawiszy (
x) indeksu wielokolumnowego (zckolumn), otrzymujemyawiersze (1% wszystkich wierszy). Więc dlax=1, wynikiem jestazgodnie z definicją. - jeśli znamy wartość dla każdej kolumny klucza w indeksie wielokolumnowym, otrzymujemy liczbę wierszy na cały klucz (
b); więc dlax=c, otrzymujemybwierszy (czyli 1 lub 10 ) z definicji. - pomiędzy (jeśli używamy par kluczy dla więcej niż jednej kolumny klucza, ale nie wszystkich), dla każdej dodatkowej znanej pary klucza możemy wykluczyć kilka dodatkowych wierszy:mamy
a-bwiersze, które nie będą należeć do przypadku, w którym znamy nasze pełne klucz (który miałbybwierszy) i z definicji powinny być wykluczone proporcjonalnie do stosunku użytecznych kolumn kluczy ((x-1)/(c-1)). -1w(x-1)/(c-1)to tylko zmiana (można po prostu użyć różnych nazw zmiennych), ponieważ musimy tylko policzyć dodatkowe kolumny, alecixto liczba zawierająca pierwszą kolumnę. (W szeregu czasowym można wywołać parametr dla pierwszej kolumnyt=0i-1robi dokładnie to).
Podsumowując, otrzymujemy a - (a-b) * (x-1)/(c-1) (a dla pierwszej kluczowej kolumny minus wiersze, które proporcjonalnie wykluczamy). Jest to (jeśli nieco przekształcisz to wyrażenie) dokładnie podana formuła. Szybka kontrola zdrowia psychicznego:dla x=1 (x-1=0 ), drugi termin to 0 i otrzymujemy a , zgodnie z pierwszym warunkiem; dla x=c , otrzymujemy a-(a-b)=b zgodnie z drugim warunkiem.
Nie jest nierozsądne zrobienie tego ansatz przy użyciu tych założeń, ale prawdopodobnie możesz znaleźć inną formułę, która ma równie dużo sensu. Jednak argumentowanie, że tak jest lepiej, byłoby trudniejszym zadaniem.
Następnie pojawia się kwestia wyboru wartości (b=10 i 1% w tym przypadku). Możesz oczywiście wybrać dowolną wartość. Aby zrobić to bez żadnych wiarygodnych danych, z wyjątkiem przeczucia, istnieje koncepcja o nazwie oszacowanie Fermi :
Zasadniczo wybierasz tylko rząd wielkości (1, 1000000, 1/100) dla swoich parametrów wejściowych i otrzymujesz rozsądny rząd wielkości dla swojego wyniku.
A więc ile wierszy pokryje nieunikalny klucz? To więcej niż 1, w przeciwnym razie uczyniłbyś go unikalnym kluczem, ale czy jest to bardziej 2, 10 czy 100? 10 jest prawdopodobnie dobrym przypuszczeniem (obejmuje wartość od około 3 do 30 w tym oszacowaniu). Więc chociaż te liczby mogły pochodzić z dwuletniego światowego badania dotyczącego dystrybucji kluczy, szacunkowe wartości w potęgach 10 są zwykle wyprowadzane w taki sposób. Jeśli chcesz mieć absolutną pewność, zapytaj programistę.
Oraz obowiązkowy xkcd dla tego rodzaju tematów:What-if? Pomaluj Ziemię