Po pierwsze, ważne jest, aby wiedzieć, według których kolumn chcesz pogrupować i jak chcesz je pogrupować. Musisz to wiedzieć, aby skonfigurować CASE STATEMENT napiszemy jako kolumnę w naszej instrukcji select. W naszym przypadku, w grupie e-maili, które uzyskują dostęp do naszej witryny, chcemy wiedzieć, ile kliknięć każdy dostawca poczty e-mail rozlicza od początku sierpnia. Chcielibyśmy również porównać pojedynczego dostawcę usług poczty e-mail z resztą. W tym przykładzie użyjemy Gmaila jako naszego dostawcy usług.
W naszym SELECT oświadczenie, będziemy potrzebować DATE , PROVIDER i SUM CLICKS na naszej stronie. Możemy je uzyskać z TEST E MAILS tabeli w naszym źródle danych.
DATE kolumna jest dość prosta:
"Test E Mails"."Created_Date" AS "DATE
A ponieważ szukamy SUM CLICKS , będziemy musieli przesłać SUM funkcja nad CLICKS kolumna.
SUM("Test E Mails"."Clicks") AS "CLICKS"
To prowadzi nas do naszego CASE STATEMENT . Z dokumentacji PostgreSQL wiemy, że CASE STATEMENT, czyli instrukcja warunkowa, musi być uporządkowana w następujący sposób:
CASE
WHEN condition THEN result
[WHEN ...]
[ELSE result]
END
Naszym pierwszym i tylko w tym przypadku warunkiem jest to, że chcemy, aby wszystkie adresy e-mail dostarczane przez Gmaila były oddzielone od wszystkich innych dostawców poczty e-mail. Tak więc jedyne WHEN jest:
WHEN "Test E Mails"."Provider" = 'Gmail' THEN 'Gmail'
A oświadczenie else byłoby „Inne” dla każdego innego dostawcy adresu e-mail. Wynikowa tabela tego CASE STATEMENT z samymi odpowiednimi e-mailami. Wyglądałoby to tak:
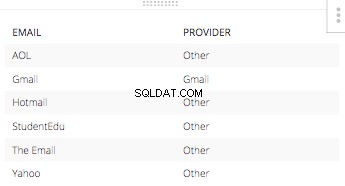
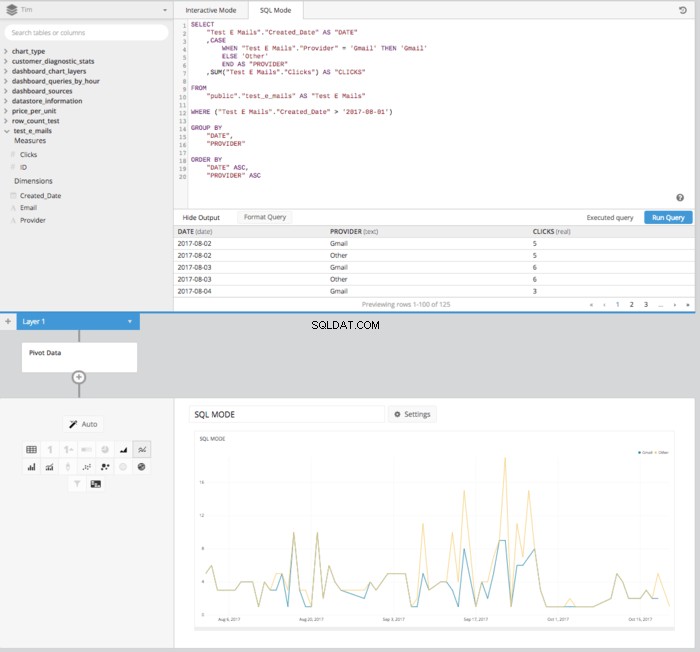
Kiedy połączysz wszystkie trzy z tych kolumn dla jednego SELECT STATEMENT i wrzuć resztę niezbędnych elementów do zbudowania zapytania SQL, wszystko nabierze kształtu poniżej.
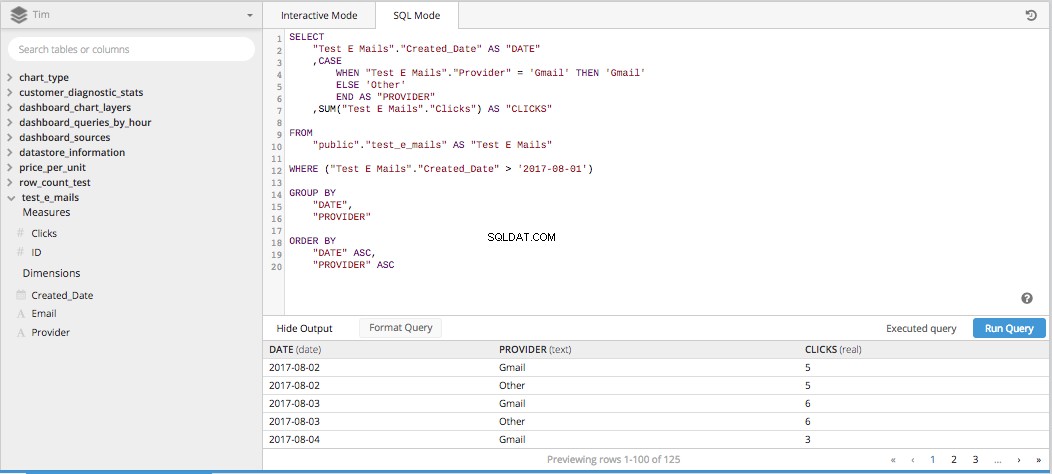
Następnie po dodaniu PIVOT DATA wejdź do potoku danych, otrzymamy odpowiednio ułożoną tabelę w odpowiednim formacie, aby skonfigurować wykres liniowy pokazujący porównywanie kliknięć w czasie.
Korzystając z Chartio, możemy wykonać wszystkie powyższe czynności bez pisania kodu SQL, ale wykorzystując funkcje Eksploratora danych i potoku danych. Po zbudowaniu naszego podstawowego zapytania, aby pobrać wszystkie kolumny, będziemy potrzebować SUM OF CLICKS , DATE i EMAIL ADDRESS możemy użyć potoku danych do manipulowania tymi danymi po SQL. Najpierw zbudujmy zapytanie.
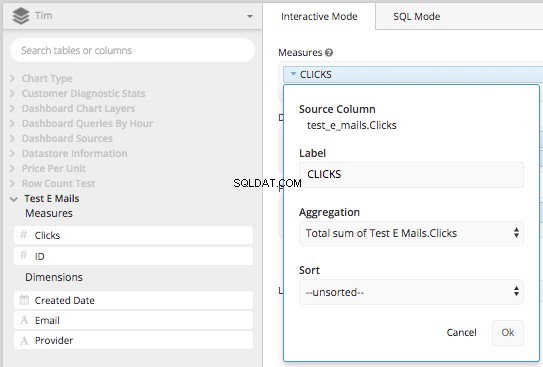
Przeciągnij „Kolumnę kliknięć” do pola miar i zagreguj ją według TOTAL SUM Kliknięć kolumny, a następnie ponownie oznacz ją „KLIKNIĘCIA”.
Następnie przeciągnij „Data utworzenia” i „Dostawca” do pola wymiarów i ponownie oznacz je etykietami „Data” i „Dostawca poczty e-mail”. Następnie za pomocą kolumny „Data utworzenia” możesz ustawić zakres dat (lub utworzyć swój WHERE klauzula) być wszystkim po 01.08.2017. To skutecznie zbuduje wszystko, czego potrzebujemy w zapytaniu bazowym, aby utworzyć CASE STATEMENT zrobiliśmy to powyżej, w Chartio Data Pipeline.
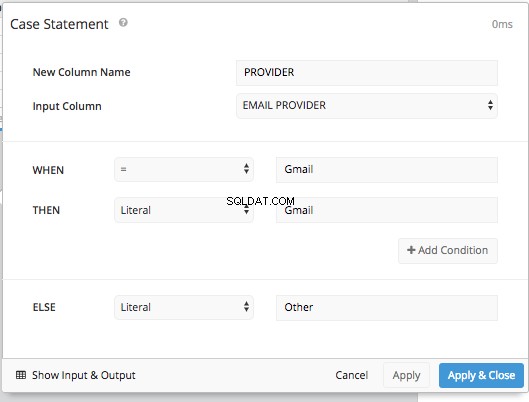
Dodawanie CASE STATEMENT krok potoku pozwala nam ustawić warunki dla WHEN i ELSE tak jak poprzednio, bez konieczności wpisywania całej składni SQL.
Następnie po ukryciu oryginalnej kolumny „Provider” i użyciu REORDER COLUMNS krok i PIVOT DATA krok otrzymamy ten sam układ tabeli, który otrzymaliśmy w trybie SQL i możemy zaprezentować tę samą tabelę, którą zrobiliśmy w trybie SQL.
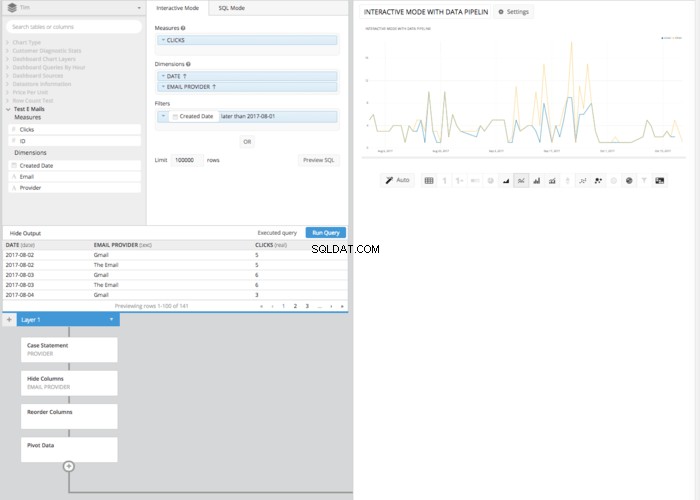
Chociaż może to zająć kilka kliknięć i kroków więcej niż w trybie SQL, wynikowy wykres liniowy wykonany w trybie interaktywnym nie wymaga znajomości składni SQL. Zamiast tego wystarczy podstawowe zrozumienie związanych z tym zasad. To kolejny przykład tego, jak Chartio pomaga przekazać moc danych w ręce wszystkich, niezależnie od znajomości SQL.