Istnieje wiele przypadków użycia do generowania sekwencji wartości w SQL Server. Nie mówię o trwałej IDENTITY kolumna (lub nowa SEQUENCE w SQL Server 2012), ale raczej zestaw przejściowy, który ma być używany tylko przez okres istnienia zapytania. Lub nawet w najprostszych przypadkach — takich jak dodanie numeru wiersza do każdego wiersza w zestawie wyników — które mogą wymagać dodania ROW_NUMBER() funkcji do zapytania (lub jeszcze lepiej w warstwie prezentacji, która i tak musi przechodzić przez wyniki wiersz po wierszu).
Mówię o nieco bardziej skomplikowanych przypadkach. Na przykład możesz mieć raport, który pokazuje sprzedaż według daty. Typowym zapytaniem może być:
SELECT OrderDate = CONVERT(DATE, OrderDate), OrderCount = COUNT(*) FROM dbo.Orders GROUP BY CONVERT(DATE, OrderDate) ORDER BY OrderDate;
Problem z tym zapytaniem polega na tym, że jeśli w danym dniu nie ma zamówień, nie będzie żadnego wiersza na ten dzień. Może to prowadzić do zamieszania, mylących danych, a nawet błędnych obliczeń (pomyśl o średnich dziennych) dla dalszych odbiorców danych.
Tak więc istnieje potrzeba wypełnienia tych luk datami, których nie ma w danych. Czasami ludzie umieszczają swoje dane w tabeli #temp i używają WHILE pętla lub kursor do uzupełniania brakujących dat jeden po drugim. Nie pokażę tutaj tego kodu, ponieważ nie chcę zalecać jego używania, ale widziałem go wszędzie.
Zanim jednak zagłębimy się w daty, porozmawiajmy najpierw o liczbach, ponieważ zawsze możesz użyć sekwencji liczb, aby uzyskać sekwencję dat.
Tabela liczb
Od dawna jestem zwolennikiem przechowywania pomocniczej „tablicy liczb” na dysku (a także tabeli kalendarza).
Oto jeden ze sposobów na wygenerowanie prostej tabeli liczb z 1 000 000 wartości:
SELECT TOP (1000000) n = CONVERT(INT, ROW_NUMBER() OVER (ORDER BY s1.[object_id])) INTO dbo.Numbers FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 OPTION (MAXDOP 1); CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(n) -- WITH (DATA_COMPRESSION = PAGE) ;
Dlaczego MAXDOP 1? Zobacz post na blogu Paula White'a i jego artykuł Connect dotyczący celów wierszy.
Jednak wiele osób sprzeciwia się podejściu z tabelami pomocniczymi. Ich argument:po co przechowywać wszystkie te dane na dysku (iw pamięci), skoro mogą generować dane w locie? Mój licznik ma być realistyczny i myśleć o tym, co optymalizujesz; obliczenia mogą być kosztowne i czy jesteś pewien, że obliczanie zakresu liczb w locie zawsze będzie tańsze? Jeśli chodzi o miejsce, tabela Numbers zajmuje tylko około 11 MB skompresowanych i 17 MB nieskompresowanych. A jeśli tabela jest wystarczająco często przywoływana, powinna zawsze znajdować się w pamięci, dzięki czemu dostęp jest szybki.
Rzućmy okiem na kilka przykładów i niektóre z bardziej powszechnych podejść stosowanych w celu ich zaspokojenia. Mam nadzieję, że wszyscy możemy się zgodzić, że nawet przy 1000 wartości nie chcemy rozwiązywać tych problemów za pomocą pętli lub kursora.
Generowanie ciągu 1000 liczb
Zaczynając od prostego, wygenerujmy zestaw liczb od 1 do 1000.
Tabela liczb
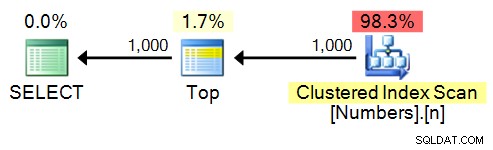
Oczywiście z tabelą liczb to zadanie jest całkiem proste:
SELECT TOP (1000) n FROM dbo.Numbers ORDER BY n;
Plan:
spt_values
Jest to tabela używana przez wewnętrzne procedury składowane do różnych celów. Wydaje się, że jego użycie w Internecie jest dość powszechne, chociaż jest nieudokumentowane, nieobsługiwane, może pewnego dnia zniknąć, a ponieważ zawiera tylko skończony, nieunikalny i nieciągły zestaw wartości. W SQL Server 2008 R2 istnieje 2164 unikalnych i 2508 łącznych wartości; w 2012 roku jest 2167 unikalnych i 2515 łącznie. Obejmuje to duplikaty, wartości ujemne, a nawet użycie DISTINCT , mnóstwo luk po przekroczeniu liczby 2048. Więc obejściem jest użycie ROW_NUMBER() aby wygenerować ciągłą sekwencję, zaczynając od 1, na podstawie wartości w tabeli.
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY number) FROM [master]..spt_values ORDER BY n;
Plan:

To powiedziawszy, dla tylko 1000 wartości możesz napisać nieco prostsze zapytanie, aby wygenerować tę samą sekwencję:
SELECT DISTINCT n = number FROM master..[spt_values] WHERE number BETWEEN 1 AND 1000;
Prowadzi to oczywiście do prostszego planu, ale szybko się załamuje (gdy sekwencja musi mieć więcej niż 2048 rzędów):
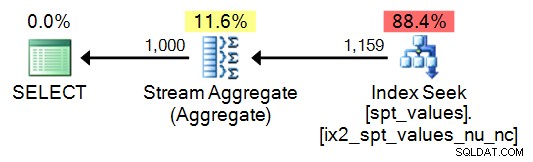
W każdym razie nie polecam korzystania z tego stołu; Włączam go w celach porównawczych, tylko dlatego, że wiem, jak wiele z tego jest i jak kuszące może być ponowne użycie napotkanego kodu.
sys.all_objects
Innym podejściem, które przez lata było jednym z moich ulubionych, jest użycie sys.all_objects . Podobnie jak spt_values , nie ma niezawodnego sposobu na bezpośrednie wygenerowanie ciągłej sekwencji, a te same problemy występują w przypadku skończonego zbioru (nieco poniżej 2000 wierszy w SQL Server 2008 R2 i nieco ponad 2000 wierszy w SQL Server 2012), ale w przypadku 1000 wierszy możemy użyć tego samego ROW_NUMBER() sztuczka. Powodem, dla którego podoba mi się to podejście, jest to, że (a) istnieje mniejsza obawa, że ten widok zniknie w najbliższym czasie, (b) sam widok jest udokumentowany i obsługiwany oraz (c) będzie działał w dowolnej bazie danych w dowolnej wersji od SQL Server 2005 bez konieczności przekraczania granic bazy danych (w tym zawartych baz danych).
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY [object_id]) FROM sys.all_objects ORDER BY n;
Plan:

Skumulowane CTE
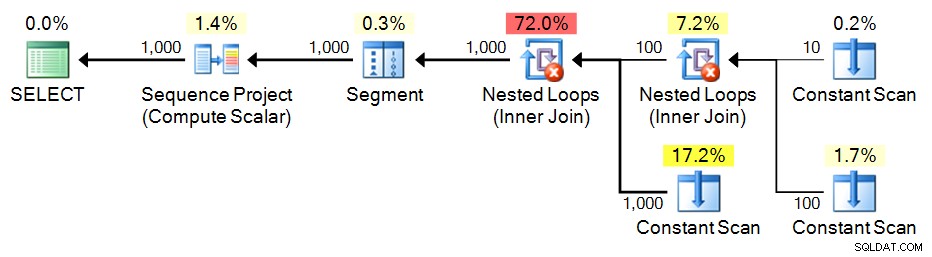
Uważam, że Itzik Ben-Gan zasługuje na najwyższe uznanie za to podejście; w zasadzie konstruujesz CTE z małym zestawem wartości, a następnie tworzysz iloczyn kartezjański względem samego siebie, aby wygenerować potrzebną liczbę wierszy. I znowu, zamiast próbować generować ciągły zestaw jako część bazowego zapytania, możemy po prostu zastosować ROW_NUMBER() do wyniku końcowego.
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), -- 10
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b), -- 10*10
e3(n) AS (SELECT 1 FROM e1 CROSS JOIN e2) -- 10*100
SELECT n = ROW_NUMBER() OVER (ORDER BY n) FROM e3 ORDER BY n; Plan:
Rekursywny CTE
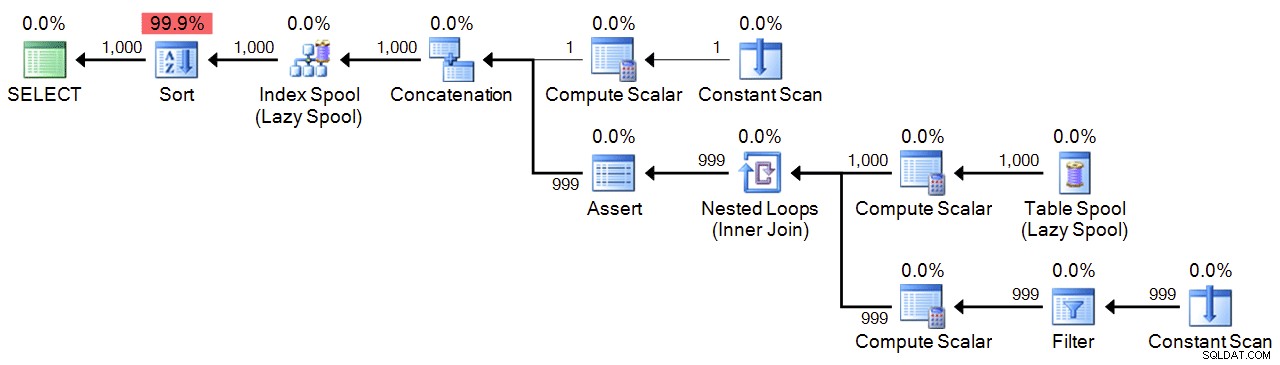
Na koniec mamy rekurencyjne CTE, które wykorzystuje 1 jako kotwicę i dodaje 1, aż osiągniemy maksimum. Ze względów bezpieczeństwa określam maksimum w obu WHERE klauzula części rekurencyjnej oraz w MAXRECURSION ustawienie. W zależności od liczby potrzebnych numerów może być konieczne ustawienie MAXRECURSION do 0 .
;WITH n(n) AS
(
SELECT 1
UNION ALL
SELECT n+1 FROM n WHERE n < 1000
)
SELECT n FROM n ORDER BY n
OPTION (MAXRECURSION 1000); Plan:
Wydajność
Oczywiście przy 1000 wartości różnice w wydajności są znikome, ale warto zobaczyć, jak działają te różne opcje:
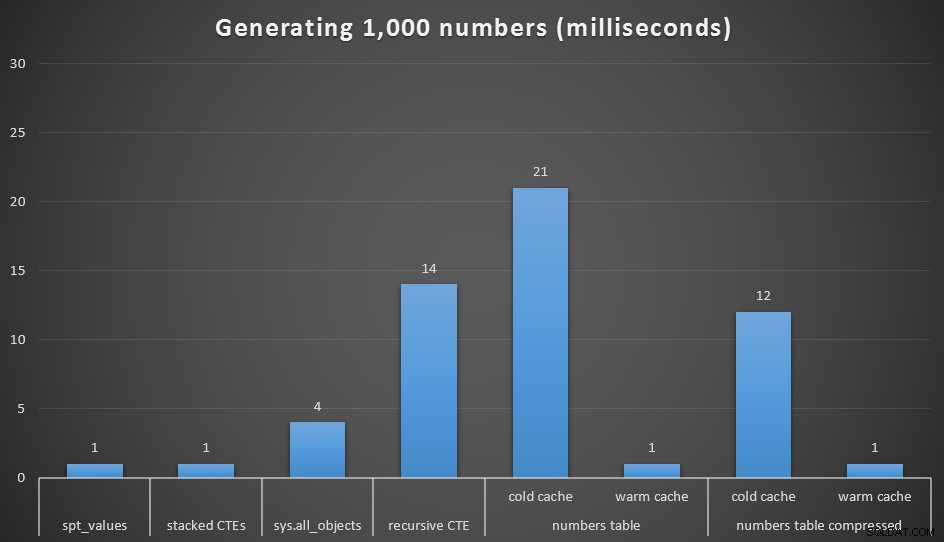
Uruchom w milisekundach, aby wygenerować 1000 ciągłych liczb
Uruchomiłem każde zapytanie 20 razy i wziąłem średnie czasy działania. Przetestowałem również dbo.Numbers tabeli, zarówno w formacie skompresowanym, jak i nieskompresowanym, z zimną i ciepłą pamięcią podręczną. Dzięki ciepłej pamięci podręcznej bardzo ściśle rywalizuje z innymi najszybszymi opcjami (spt_values , niezalecane i skumulowane CTE), ale pierwsze trafienie jest stosunkowo drogie (choć prawie się tak śmieję).
Ciąg dalszy nastąpi…
Jeśli jest to typowy przypadek użycia i nie zapuszczasz się daleko poza 1000 wierszy, mam nadzieję, że pokazałem najszybsze sposoby generowania tych liczb. Jeśli Twój przypadek użycia to większa liczba lub jeśli szukasz rozwiązań do generowania sekwencji dat, bądź na bieżąco. W dalszej części tej serii zajmę się generowaniem sekwencji 50 000 i 1 000 000 liczb oraz zakresów dat od tygodnia do roku.
[ Część 1 | Część 2 | Część 3 ]