Hybrid Cloud to powszechny projekt architektury w każdej firmie. Koncepcja ta łączy chmurę publiczną, chmurę prywatną, a nawet rozwiązania on-premise, pozwalając firmom na elastyczność w zakresie miejsca przechowywania i sposobu korzystania z danych. Pomaga również we wdrażaniu środowiska wysokiej dostępności. Problem polega na tym, że wdrożenie tego rodzaju środowiska może być trudnym i czasochłonnym zadaniem. W tym blogu zobaczymy, czym jest Hybrid Cloud, kilka kwestii, które należy wziąć pod uwagę przed jej użyciem, oraz jak wdrożyć to środowisko za pomocą ClusterControl.
Co to jest chmura hybrydowa?
Jest to topologia wykorzystująca połączenie chmury prywatnej i publicznej, a nawet usług lokalnych. Brzmi to podobnie do środowiska Multi-Cloud, ale główna różnica polega na tym, że ta koncepcja odnosi się konkretnie do kombinacji publicznego i prywatnego, które mogą obejmować również lokalizacje.
Uwagi dotyczące hybrydowych baz danych w chmurze
Przejście do środowiska hybrydowego jest inne dla każdej firmy, ponieważ ma ona swój własny, unikalny zestaw danych, wymagań, ograniczeń i procesów, które mu towarzyszą.
Zobaczmy kilka kwestii, które należy wziąć pod uwagę przy planowaniu tego rodzaju topologii.
-
Zgodność:wybierz dostawcę specjalizującego się w Twojej branży i znającego unikalne środki zgodności, które muszą być spełnione, niezależnie od tego, czy jest to HIPAA, FISMA, PCI, czy jakiekolwiek inne przepisy, które akceptuje Twoja firma. Ostatecznie strategia zarządzania bazą danych powinna być określona na podstawie architektury, która najlepiej spełni potrzeby Twojej firmy i będzie się skalować wraz z rozwojem.
-
Obciążenia:każda baza danych ma inne obciążenia. Niektóre z nich sprawdzą się lepiej w chmurze publicznej, niektóre lokalnie, a niektóre w chmurze prywatnej. Znajomość obciążenia pracą jest niezbędna do znalezienia najlepszego miksu dla Twoich baz danych.
-
Zarządzanie i konserwacja:Nowe środowisko oznacza nowy sposób zarządzania nim i utrzymywania danych. Upewnij się, że masz odpowiednie elementy i ludzi do zarządzania tymi nowymi środowiskami, które musisz określić przed wykonaniem skoku.
Jak wdrożyć PostgreSQL w hybrydowym środowisku chmury
Założymy, że masz uruchomioną instalację ClusterControl i utworzyłeś już dwa różne konta dostawcy chmury lub jedno konto, jeśli używasz chmury publicznej i prywatnej w tym samym dostawcy chmury lub jeśli używasz połączenie środowisk Cloud i On-prem.
Przygotowywanie środowiska chmury
Najpierw musisz utworzyć swoje środowisko w głównym dostawcy chmury. W tym przypadku użyjemy AWS z 2 węzłami PostgreSQL:

Upewnij się, że ruch SSH i PostgreSQL z serwera ClusterControl jest dozwolony przez edytowanie grupy bezpieczeństwa:

Następnie przejdź do dodatkowego dostawcy chmury lub do serwerów prywatnych lub lokalnych i utwórz co najmniej jedną maszynę wirtualną, która będzie węzłem gotowości.

I ponownie upewnij się, że zezwalasz na ruch SSH i PostgreSQL z serwera ClusterControl:

W tym przypadku zezwalamy na ruch bez żadnych ograniczeń w źródle, ale to tylko przykład i nie jest zalecane w rzeczywistości.
Wdrażanie klastra PostgreSQL
Przejdź do serwera ClusterControl i wybierz opcję „Wdróż”. Jeśli masz już uruchomioną instancję PostgreSQL, musisz zamiast tego wybrać opcję „Importuj istniejący serwer/bazę danych”.
Wybierając PostgreSQL, musisz określić Użytkownika, Klucz lub Hasło oraz port, aby połączyć się przez SSH z węzłami PostgreSQL. Potrzebna jest również nazwa nowego klastra i jeśli chcesz, aby ClusterControl zainstalował dla Ciebie odpowiednie oprogramowanie i konfiguracje.
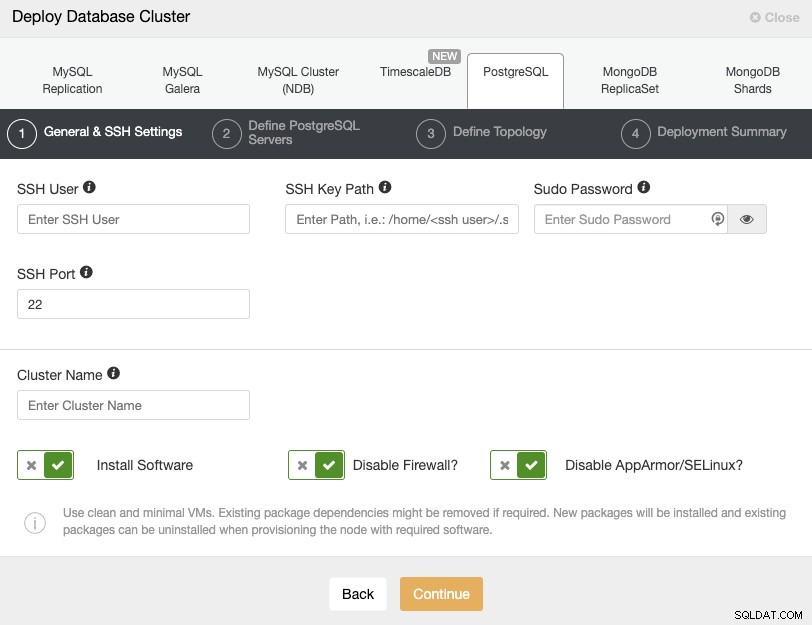
Sprawdź wymagania użytkownika ClusterControl, aby uzyskać więcej informacji na temat tego kroku.
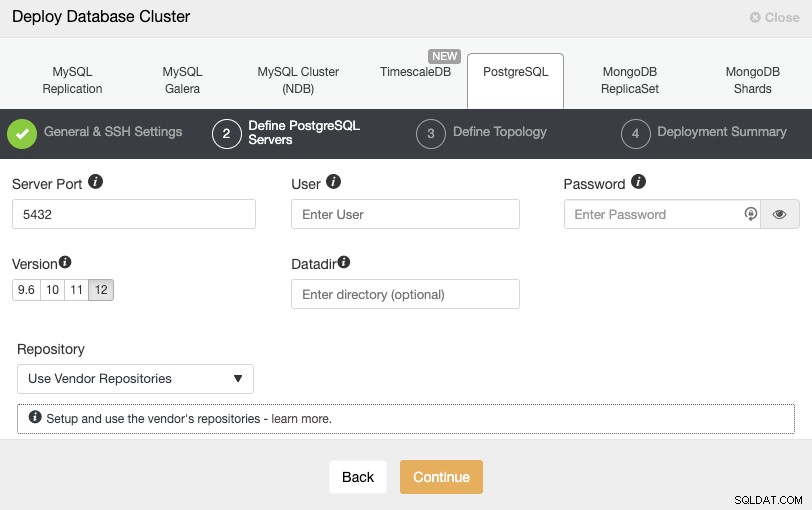
Po skonfigurowaniu informacji o dostępie SSH należy zdefiniować użytkownika bazy danych, wersję i katalog danych (opcjonalnie). Możesz również określić, którego repozytorium chcesz użyć. W następnym kroku musisz dodać swoje serwery do klastra, który zamierzasz utworzyć.
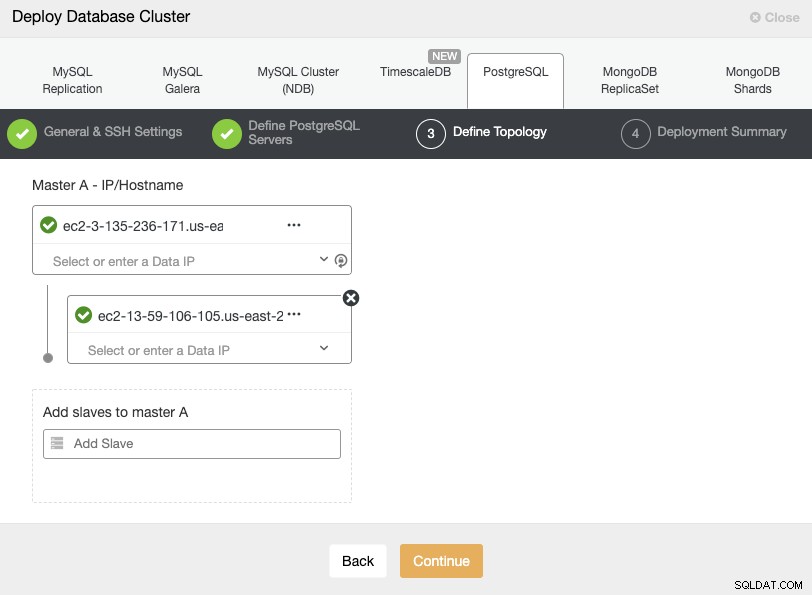
Podczas dodawania serwerów możesz wprowadzić adres IP lub nazwę hosta. W tym kroku możesz również dodać węzeł umieszczony w dodatkowym Cloud Provider lub on-prem, ponieważ ClusterControl nie ma żadnych ograniczeń dotyczących używanej sieci, ale aby było to bardziej przejrzyste, dodamy go w następnym Sekcja. Jedynym wymogiem jest posiadanie dostępu SSH do węzła.
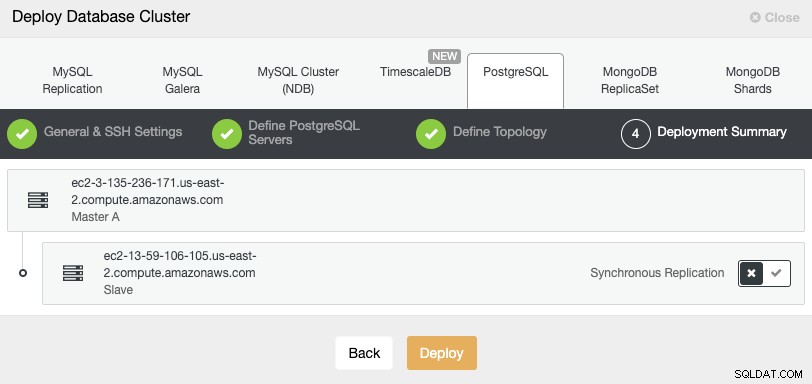
W ostatnim kroku możesz wybrać, czy twoja replikacja będzie synchroniczna czy asynchroniczna.
Jeśli dodajesz tutaj swój węzeł zdalny, ważne jest, aby użyć replikacji asynchronicznej, jeśli nie, na klaster mogą mieć wpływ opóźnienia lub problemy z siecią.
Możesz monitorować stan tworzenia w monitorze aktywności ClusterControl.
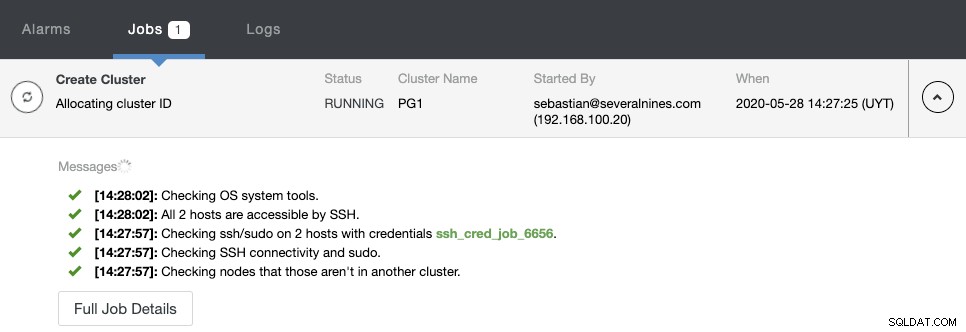
Po zakończeniu zadania możesz zobaczyć swój nowy klaster PostgreSQL na głównym ekranie ClusterControl.

Dodawanie zdalnego węzła w trybie gotowości
Po utworzeniu klastra możesz wykonywać na nim kilka zadań, takich jak wdrażanie/importowanie systemu równoważenia obciążenia lub węzła replikacji.
Przejdź do działań klastra i wybierz „Dodaj urządzenie podrzędne replikacji”:
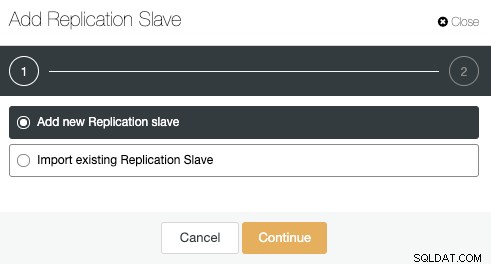
Użyjmy opcji „Dodaj nowe urządzenie podrzędne replikacji”, ponieważ zakładamy, że węzeł zdalny jest nową instalacją, jeśli nie, możesz zamiast tego użyć opcji „Importuj istniejące urządzenie podrzędne replikacji”.
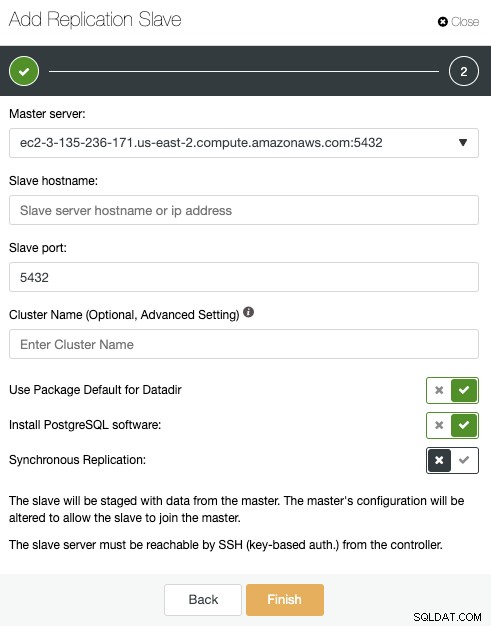
Tutaj wystarczy wybrać serwer główny, wprowadzić adres IP nowego serwera rezerwowego oraz port bazy danych. Następnie możesz wybrać, czy chcesz, aby ClusterControl zainstalował oprogramowanie i czy replikacja ma być synchroniczna czy asynchroniczna. Ponownie, jeśli dodajesz węzeł w innej lokalizacji (inny dostawca chmury lub lokalnie), powinieneś użyć replikacji asynchronicznej, aby uniknąć problemów związanych z wydajnością sieci.
W ten sposób możesz dodać dowolną liczbę replik i rozłożyć między nimi ruch odczytu za pomocą modułu równoważenia obciążenia, który możesz również zaimplementować za pomocą ClusterControl.
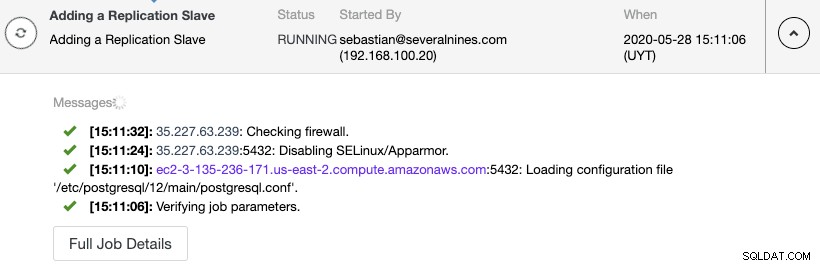
Możesz monitorować tworzenie węzła replikacji w monitorze aktywności ClusterControl.
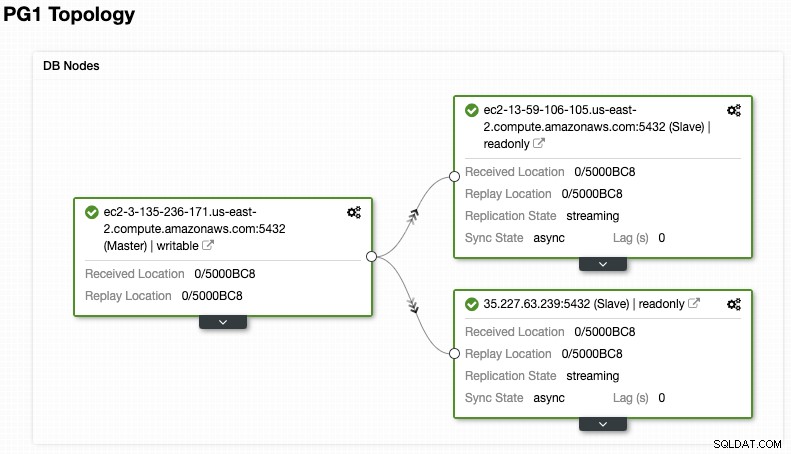
I sprawdź ostateczną topologię w sekcji Widok topologii.
Wnioski
Te funkcje ClusterControl pozwolą Ci szybko skonfigurować replikację w środowisku chmury hybrydowej, między różnymi dostawcami chmury, a nawet między dostawcą chmury a środowiskiem lokalnym, dla bazy danych PostgreSQL (i różnych technologii) oraz zarządzać konfiguracją w łatwy i przyjazny sposób. Jeśli chodzi o komunikację między dostawcami chmury lub między chmurą prywatną i publiczną, ze względów bezpieczeństwa należy ograniczyć ruch tylko ze znanych źródeł, aby zmniejszyć ryzyko nieautoryzowanego dostępu do sieci.