W tym artykule przyjrzymy się, jak indeks może poprawić wydajność zapytań.
Wprowadzenie
Indeksy w Oracle i innych bazach danych to obiekty, które przechowują odniesienia do danych w innych tabelach. Służą do poprawy wydajności zapytań, najczęściej instrukcji SELECT.
Nie są „srebrną kulą” — nie zawsze rozwiązują problemy z wydajnością za pomocą instrukcji SELECT. Jednak z pewnością mogą pomóc.
Rozważmy to na konkretnym przykładzie.
Przykład
W tym przykładzie użyjemy pojedynczej tabeli o nazwie Klient, która zawiera takie kolumny, jak ID, Imię, Nazwisko, maksymalna wartość kredytu, wartość daty utworzenia i inne kolumny, których nie będziemy używać.
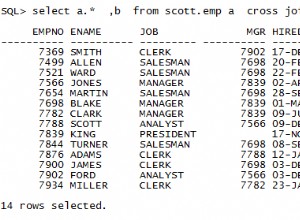
SELECT customer_id,first_name,last_name, max_credit, created_date FROM customer;
Oto próbka tabeli.
[identyfikator tabeli=38 /]
Teraz znajdziemy:
- Którzy klienci zostali dodani do tabeli w tym samym dniu co pierwsi klienci
- Klienci filtrowani według nazwiska w kolejności rosnącej
- Wyświetl identyfikator klienta, imię, nazwisko, maksymalny kredyt i datę utworzenia
Aby to zrobić, utwórz następujące zapytanie:
SELECT customer_id,
first_name,
last_name,
max_credit,
created_date
FROM customer
WHERE created_date = (
SELECT MIN(created_date)
FROM customer
)
ORDER BY last_name; Wynik wygląda tak:
[identyfikator tabeli=39 /]
Pokazuje dane, które chcemy.
Wydajność przed zastosowaniem indeksu
Przyjrzyjmy się teraz planowi wyjaśniania tego zapytania. Uzyskałem to, uruchamiając EXPLAIN PLAN FOR dla instrukcji SELECT i następującą komendę:
SELECT * FROM TABLE(dbms_xplan.display);
Możesz uzyskać podobny wynik wyjściowy, korzystając z funkcji Wyjaśnij plan w swoim IDE.
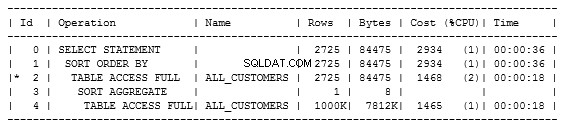
Widzimy, że wykonuje pełny dostęp do tabeli w dwóch punktach, a mianowicie w podzapytaniu i w zapytaniu zewnętrznym. Dzieje się tak, ponieważ w tabeli nie ma indeksów do użycia.
Kosztuje 2934. Po uruchomieniu zapytanie pobrało 785 wierszy w 1,9 sekundy. Może się wydawać, że to szybko, ale to tylko przykład, który możemy poprawić. Zapytania w rzeczywistych systemach mogą trwać znacznie dłużej.
Jednym ze sposobów poprawy wydajności tego zapytania jest dodanie indeksu do kolumny created_date. Ta kolumna jest używana zarówno w klauzuli WHERE zapytania zewnętrznego, jak i w funkcji MIN zapytania wewnętrznego.
Dodaj indeks
Możemy dodać indeks do tej tabeli, aby poprawić wydajność zapytania. Ten indeks będzie przechowywany w kolumnie created_date, dzięki czemu kod może wyglądać tak:
CREATE INDEX idx_cust_cdate ON customer (created_date);
Teraz indeks jest tworzony tylko w tej kolumnie. Powinno to poprawić wydajność naszego zapytania, ale najpierw musimy to sprawdzić.
Stworzyliśmy indeks b-drzewa, który prawdopodobnie jest wszystkim, czego potrzebujemy w tej kolumnie. Wkrótce potwierdzimy to w planie wyjaśnień. Napisałem przewodnik po indeksach Oracle, w tym, jak dowiedzieć się, jakiego typu indeksu należy użyć, a także wiele innych cennych informacji.
Wydajność po dodaniu indeksu
Uruchommy ponownie plan wyjaśniania tego zapytania.
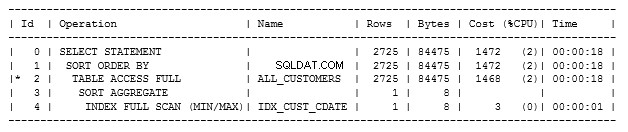
Widzimy, że indeks został użyty w ostatnim kroku. Pokazuje, że wykonano pełne skanowanie z indeksem idx_cust_cdate, który właśnie stworzyliśmy.
Pokazuje również całkowity koszt 1472 i pobiera 785 rekordów w 0,9 sekundy.
Środowisko wykonawcze poprawiło się tylko nieznacznie (z 1,9 do 0,9 sekundy), ale jest to poprawa o około 50% dzięki dodaniu indeksu do tego małego zestawu danych.
Jak wspomniano wcześniej, prawdziwe zapytania będą bardziej skomplikowane niż to i ich wykonanie zajmie więcej czasu. Ale to jest przykład, jak indeks może poprawić plan zapytania i czas wykonywania zapytania.