Wszyscy zostaliśmy zepsuci przez zdolność wyszukiwarek do „obejścia” takich rzeczy, jak błędy w pisowni, różnice w pisowni nazw lub każda inna sytuacja, w której wyszukiwane hasło może pasować na stronach, których autorzy wolą używać innej pisowni słowa. Dodanie takich funkcji do naszych własnych aplikacji opartych na bazach danych może w podobny sposób wzbogacić i ulepszyć nasze aplikacje, a podczas gdy komercyjne systemy zarządzania relacyjnymi bazami danych (RDBMS) zapewniają własne, w pełni opracowane, niestandardowe rozwiązania tego problemu, koszty licencjonowania tych narzędzi mogą być mniejsze. sięgnij po mniejszych programistów lub małe firmy tworzące oprogramowanie.
Można by argumentować, że można to zrobić za pomocą sprawdzania pisowni. Jednak sprawdzanie pisowni jest zazwyczaj bezużyteczne, gdy dopasowuje poprawną, ale alternatywną pisownię nazwy lub innego słowa. Dopasowanie dźwiękowe wypełnia tę funkcjonalną lukę. To jest temat dzisiejszego samouczka programowania:jak wyszukiwać dźwięki za pomocą Pythona za pomocą metafonów.
Co to jest Soundex?
Soundex został opracowany na początku XX wieku jako środek do dopasowywania nazw na podstawie ich brzmienia w amerykańskim spisie ludności. Był następnie używany przez różne firmy telekomunikacyjne do dopasowywania nazw klientów. Jest on nadal używany do dopasowywania danych fonetycznych do dnia dzisiejszego, mimo że jest ograniczony do pisowni i wymowy amerykańskiego angielskiego. Ogranicza się również do liter angielskich. Większość RDBMS, takich jak SQL Server i Oracle, wraz z MySQL i jego wariantami, implementuje funkcję Soundex i pomimo swoich ograniczeń jest nadal używana do dopasowywania wielu nieangielskich słów.
Co to jest podwójny metafon?
Metafon algorytm został opracowany w 1990 roku i pokonuje niektóre ograniczenia Soundex. W 2000 roku ulepszony następny, Podwójny metafon , został opracowany. Double Metaphone zwraca podstawową i drugorzędną wartość, która odpowiada dwóm sposobom wymawiania pojedynczego słowa. Do dziś algorytm ten pozostaje jednym z lepszych algorytmów fonetycznych typu open source. Metaphone 3 został wydany w 2009 roku jako ulepszenie Double Metaphone, ale jest to produkt komercyjny.
Niestety, wiele znanych RDBMS wspomnianych powyżej nie implementuje Double Metaphone, a większość Znane języki skryptowe nie zapewniają obsługiwanej implementacji Double Metaphone. Jednak Python dostarcza moduł, który implementuje Double Metaphone.
Przykłady przedstawione w tym samouczku programowania w języku Python wykorzystują MariaDB w wersji 10.5.12 i Python 3.9.2, oba działające w systemie Kali/Debian Linux.
Jak dodać podwójny metafon do Pythona
Jak każdy moduł Pythona, narzędzie pip może być użyte do zainstalowania Double Metaphone. Składnia zależy od Twojej instalacji Pythona. Typowa instalacja Double Metaphone wygląda następująco:
# Typical if you have only Python 3 installed $ pip install doublemetaphone # If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install DoubleMetaphone
Pamiętaj, że dodatkowa wielkość liter jest zamierzona. Poniższy kod jest przykładem użycia Double Metaphone w Pythonie:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 1 - Demo script to verify functionality
Powyższy skrypt Pythona daje następujące dane wyjściowe po uruchomieniu w zintegrowanym środowisku programistycznym (IDE) lub edytorze kodu:
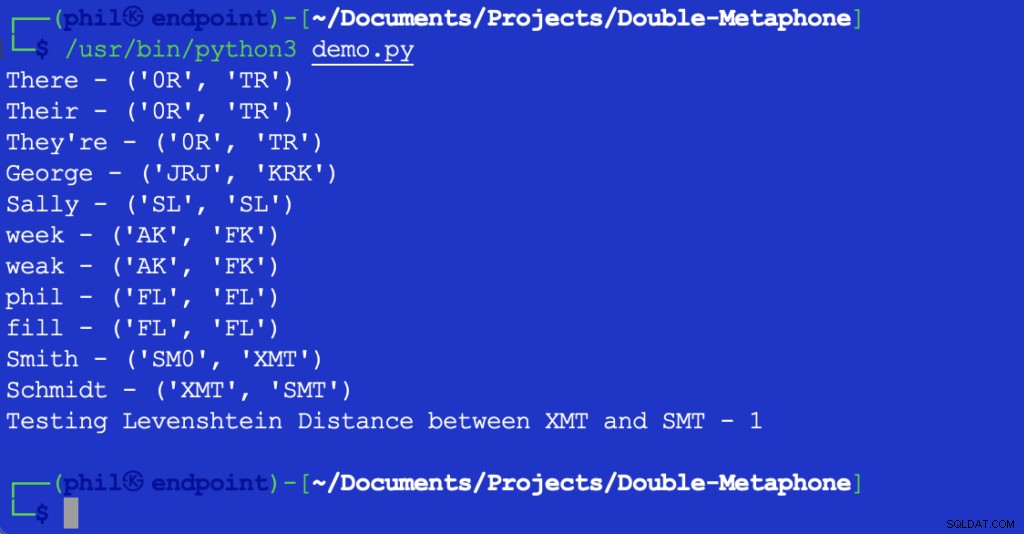
Rysunek 1 – Wyjście skryptu demonstracyjnego
Jak widać tutaj, każde słowo ma zarówno pierwotną, jak i wtórną wartość fonetyczną. Słowa, które pasują zarówno do wartości podstawowych, jak i drugorzędnych, są uważane za dopasowania fonetyczne. Mówi się, że słowa, które mają co najmniej jedną wartość fonetyczną lub które mają tę samą pierwszą parę znaków w dowolnej wartości fonetycznej, są fonetycznie blisko siebie.
Większość wyświetlane litery odpowiadają ich angielskiej wymowie. X może odpowiadać KS , SH lub C . 0 odpowiada tym dźwięk w u lub tam . Samogłoski są dopasowywane tylko na początku słowa. Ze względu na niezliczoną liczbę różnic w regionalnych akcentach nie można powiedzieć, że słowa mogą być obiektywnie dokładne, nawet jeśli mają te same wartości fonetyczne.
Porównywanie wartości fonetycznych z Pythonem
Istnieje wiele zasobów internetowych, które mogą opisać pełne działanie algorytmu Double Metaphone; jednak nie jest to konieczne, aby z niego korzystać, ponieważ jesteśmy bardziej zainteresowani porównywaniem obliczone wartości, bardziej niż jesteśmy zainteresowani obliczeniem wartości. Jak wspomniano wcześniej, jeśli istnieje co najmniej jedna wartość wspólna między dwoma słowami, można powiedzieć, że wartości te są dopasowaniami fonetycznymi i wartości fonetyczne, które są podobne są fonetycznie bliskie .
Porównywanie wartości bezwzględnych jest łatwe, ale jak określić, czy ciągi są podobne? Chociaż nie ma ograniczeń technicznych, które uniemożliwiają porównywanie ciągów zawierających wiele słów, porównania te są zwykle niewiarygodne. Trzymaj się porównywania pojedynczych słów.
Jakie są odległości Levenshteina?
Odległość Levenshteina między dwoma ciągami to liczba pojedynczych znaków, które muszą zostać zmienione w jednym ciągu, aby pasował do drugiego ciągu. Para strun o mniejszej odległości Levenshteina jest bardziej do siebie podobna niż para strun o większej odległości Levenshteina. Odległość Levenshteina jest podobna do Odległości Hamminga , ale ta ostatnia jest ograniczona do ciągów o tej samej długości, ponieważ wartości fonetyczne Double Metaphone mogą mieć różną długość, bardziej sensowne jest porównanie ich przy użyciu odległości Levenshteina.
Biblioteka odległości Pythona Levenshteina
Python można rozszerzyć o obsługę obliczeń odległości Levenshteina za pomocą modułu Pythona:
# If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install python-Levenshtein
Zwróć uwagę, że podobnie jak w przypadku instalacji DoubleMetaphone powyżej, składnia wywołania pip może się różnić. Moduł Pythona-Levenshteina zapewnia znacznie więcej funkcji niż tylko obliczenia odległości Levenshteina.
Poniższy kod pokazuje test obliczania odległości Levenshteina w Pythonie:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 2 - Demo extended to verify Levenshtein Distance calculation functionality
Wykonanie tego skryptu daje następujące dane wyjściowe:
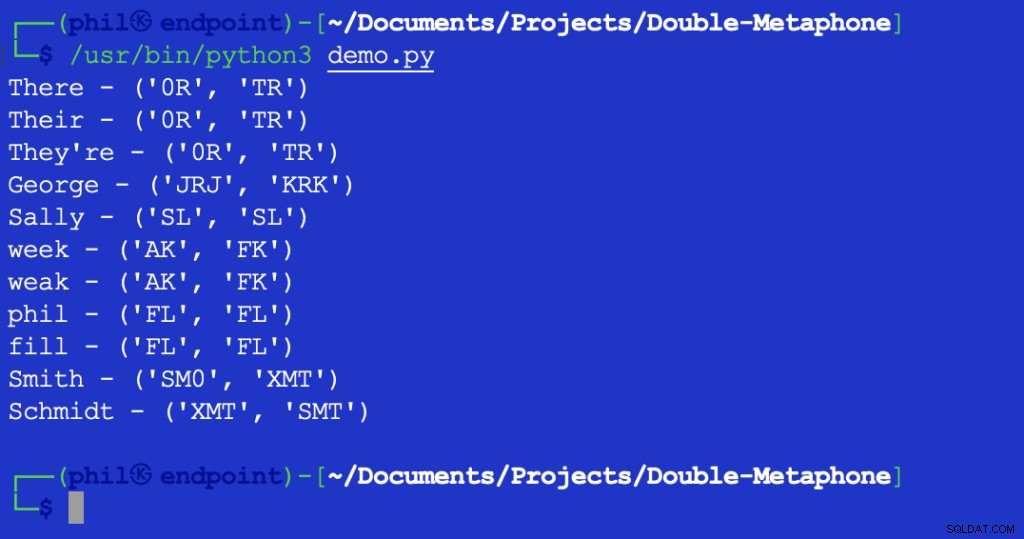
Rysunek 2 – Wyniki testu odległości Levenshteina
Zwrócona wartość 1 wskazuje, że pomiędzy XMT jest jeden znak i SMT to jest inne. W tym przypadku jest to pierwszy znak w obu ciągach.
Porównanie podwójnych metafonów w Pythonie
To, co następuje, nie jest ostateczną wersją porównań fonetycznych. To po prostu jeden z wielu sposobów na dokonanie takiego porównania. Aby skutecznie porównać fonetyczną bliskość dowolnych dwóch danych ciągów, każda wartość fonetyczna podwójnej metafony jednego ciągu musi zostać porównana z odpowiadającą jej wartością fonetyczną podwójnej metafony innego ciągu. Ponieważ obie wartości fonetyczne danego ciągu mają równą wagę, średnia tych wartości porównawczych da dość dobre przybliżenie bliskości fonetycznej:
PN = [ Dist(DM11, DM21,) + Dist(DM12, DM22,) ] / 2.0
Gdzie:
- DM1(1) :Pierwsza wartość podwójnego metafonu ciągu 1,
- DM1(2) :Druga wartość podwójnego metafonu ciągu 1
- DM2(1) :Pierwsza wartość podwójnego metafonu ciągu 2
- DM2(2) :Druga wartość podwójnego metafonu ciągu 2
- PN :Bliskość fonetyczna, przy czym wartości niższe są bliższe niż wartości wyższe. Wartość zerowa wskazuje na podobieństwo fonetyczne. Najwyższa wartość to liczba liter w najkrótszym ciągu.
Ta formuła załamuje się w przypadkach takich jak Schmidt (XMT, SMT) i Smith (SM0, XMT) gdzie pierwsza wartość fonetyczna pierwszego ciągu odpowiada drugiej wartości fonetycznej drugiego ciągu. W takich sytuacjach obaj Schmidt i Kowalski można uznać za fonetycznie podobne ze względu na wspólną wartość. Kod funkcji bliskości powinien stosować powyższy wzór tylko wtedy, gdy wszystkie cztery wartości fonetyczne są różne. Formuła ma również słabości podczas porównywania ciągów o różnej długości.
Pamiętaj, że nie ma wyjątkowo skutecznego sposobu porównywania strun o różnej długości, mimo że obliczenie odległości Levenshteina między dwoma strunami uwzględnia różnice w długości strun. Możliwym obejściem byłoby porównanie obu ciągów do długości krótszego z dwóch ciągów.
Poniżej znajduje się przykładowy fragment kodu, który implementuje powyższy kod, wraz z kilkoma przykładami testowymi:
# demo2.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testwords = ["Philippe", "Phillip", "Sallie", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt", "Harold", "Herald"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
print ("Distance between AK and AK - " + str(distance('AK', 'AK')) + "]")
print ("Comparing week and weak - [" + str(Nearness("week", "weak")) + "]")
print ("Comparing Harold and Herald - [" + str(Nearness("Harold", "Herald")) + "]")
print ("Comparing Smith and Schmidt - [" + str(Nearness("Smith", "Schmidt")) + "]")
print ("Comparing Philippe and Phillip - [" + str(Nearness("Philippe", "Phillip")) + "]")
print ("Comparing Phil and Phillip - [" + str(Nearness("Phil", "Phillip")) + "]")
print ("Comparing Robert and Joseph - [" + str(Nearness("Robert", "Joseph")) + "]")
print ("Comparing Samuel and Elizabeth - [" + str(Nearness("Samuel", "Elizabeth")) + "]")
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 3 - Implementation of the Nearness Algorithm Above
Przykładowy kod Pythona daje następujące dane wyjściowe:
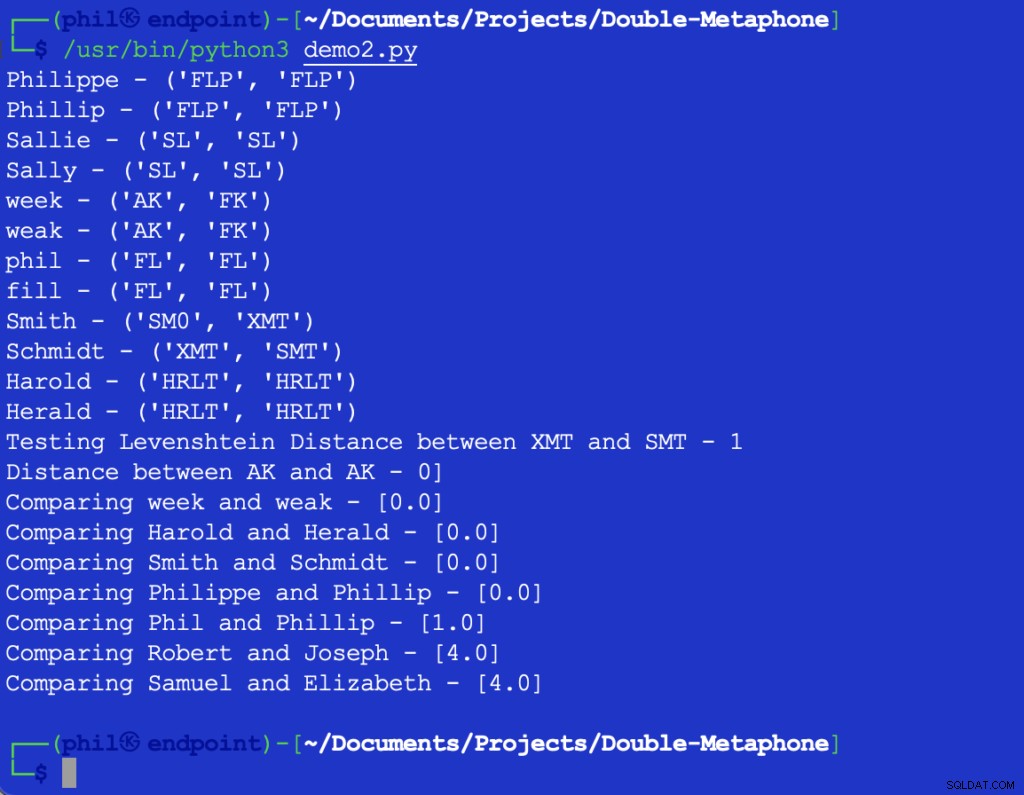
Rysunek 3 – Dane wyjściowe algorytmu bliskości
Zestaw próbek potwierdza ogólny trend, że im większe różnice w słowach, tym wyższy wynik Bliski funkcja.
Integracja bazy danych w Pythonie
Powyższy kod narusza lukę funkcjonalną między danym RDBMS a implementacją Double Metaphone. Ponadto, implementując Bliski w Pythonie, łatwo ją zastąpić, jeśli preferowany będzie inny algorytm porównania.
Rozważ następującą tabelę MySQL/MariaDB:
create table demo_names (record_id int not null auto_increment, lastname varchar(100) not null default '', firstname varchar(100) not null default '', primary key(record_id)); Listing 4 - MySQL/MariaDB CREATE TABLE statement
W większości aplikacji opartych na bazach danych oprogramowanie pośrednie tworzy instrukcje SQL służące do zarządzania danymi, w tym ich wstawiania. Poniższy kod wstawi kilka przykładowych nazw do tej tabeli, ale w praktyce każdy kod z aplikacji internetowej lub aplikacji komputerowej, która zbiera takie dane, może zrobić to samo.
# demo3.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testNames = ["Smith, Jane", "Williams, Tim", "Adams, Richard", "Franks, Gertrude", "Smythe, Kim", "Daniels, Imogen", "Nguyen, Nancy",
"Lopez, Regina", "Garcia, Roger", "Diaz, Catalina"]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
for name in testNames:
nameParts = name.split(',')
# Normally one should do bounds checking here.
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
sql = "insert into demo_names (lastname, firstname) values(%s, %s)"
values = (lastname, firstname)
insertCursor = mydb.cursor()
insertCursor.execute (sql, values)
mydb.commit()
mydb.close()
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Inserting sample data into a database.
Uruchomienie tego kodu niczego nie drukuje, ale zapełnia tabelę testową w bazie danych w celu użycia następnej listy. Zapytanie do tabeli bezpośrednio w kliencie MySQL może sprawdzić, czy powyższy kod zadziałał:
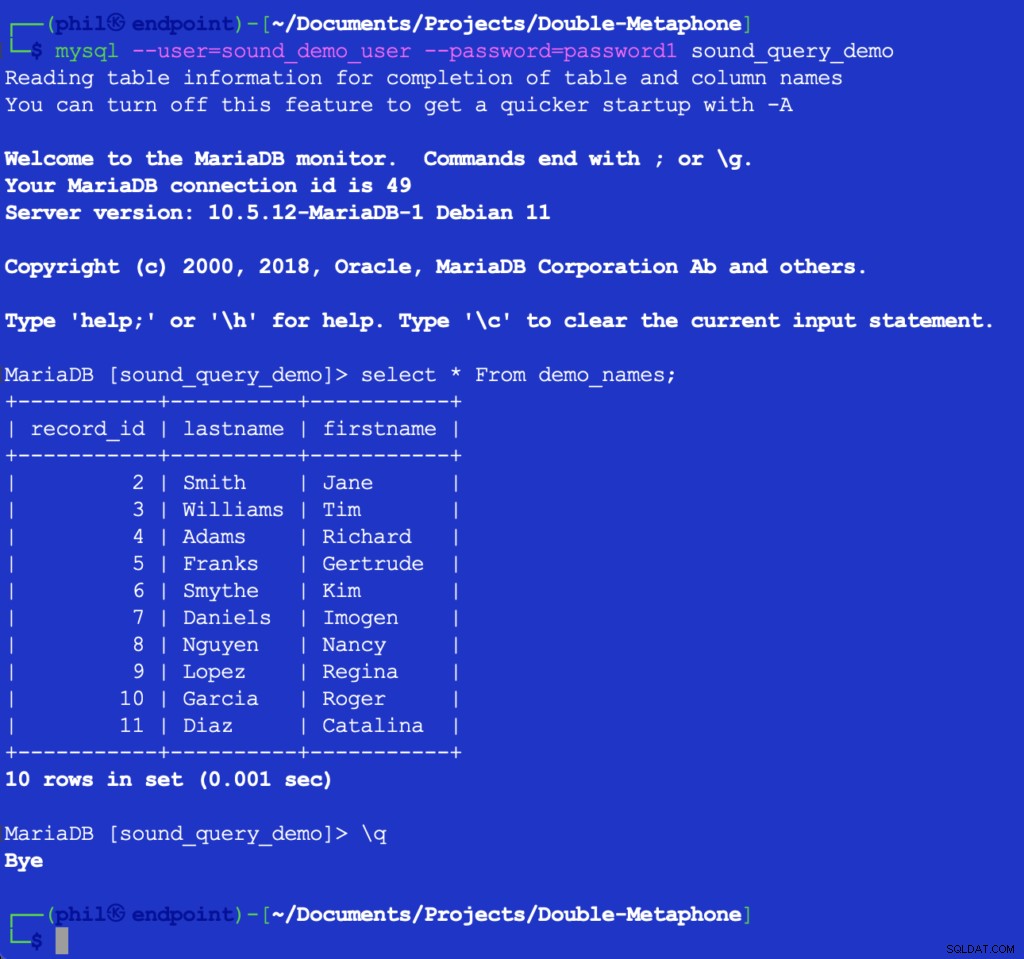
Rysunek 4- Wstawione dane tabeli
Poniższy kod wprowadzi pewne dane porównawcze do danych tabeli powyżej i wykona porównanie z nimi:
# demo4.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
comparisonNames = ["Smith, John", "Willard, Tim", "Adamo, Franklin" ]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
sql = "select lastname, firstname from demo_names order by lastname, firstname"
cursor1 = mydb.cursor()
cursor1.execute (sql)
results1 = cursor1.fetchall()
cursor1.close()
mydb.close()
for comparisonName in comparisonNames:
nameParts = comparisonName.split(",")
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
print ("Comparison for " + firstname + " " + lastname + ":")
for result in results1:
firstnameNearness = Nearness (firstname, result[1])
lastnameNearness = Nearness (lastname, result[0])
print ("\t[" + firstname + "] vs [" + result[1] + "] - " + str(firstnameNearness)
+ ", [" + lastname + "] vs [" + result[0] + "] - " + str(lastnameNearness))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Nearness Comparison Demo
Uruchomienie tego kodu daje nam następujące dane wyjściowe:
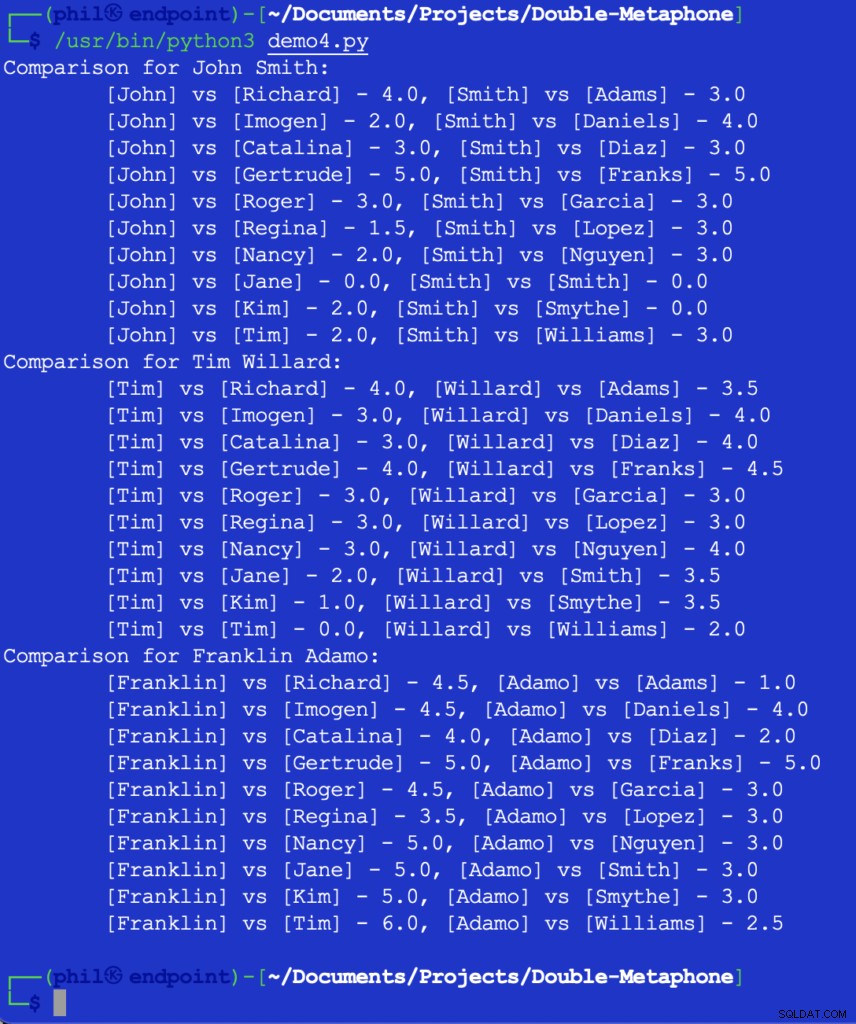
Rysunek 5 – Wyniki porównania bliskości
W tym momencie do dewelopera należałoby podjęcie decyzji, jaki będzie próg dla tego, co stanowi przydatne porównanie. Niektóre z powyższych liczb mogą wydawać się nieoczekiwane lub zaskakujące, ale jednym z możliwych dodatków do kodu może być JEŻELI oświadczenie, aby odfiltrować każdą wartość porównania, która jest większa niż 2 .
Warto zauważyć, że same wartości fonetyczne nie są przechowywane w bazie danych. Dzieje się tak, ponieważ są one obliczane jako część kodu Pythona i nie ma rzeczywistej potrzeby przechowywania ich w dowolnym miejscu, ponieważ są odrzucane po zakończeniu programu, jednak programista może znaleźć wartość w przechowywaniu ich w bazie danych, a następnie zaimplementowaniu porównania funkcja w bazie danych procedura składowana. Jednak główną wadą tego jest utrata przenośności kodu.
Ostatnie przemyślenia na temat odpytywania danych za pomocą dźwięku za pomocą Pythona
Porównywanie danych za pomocą dźwięku nie wydaje się wzbudzać „miłości” ani uwagi, jaką może uzyskać porównywanie danych za pomocą analizy obrazu, ale jeśli aplikacja ma do czynienia z wieloma podobnie brzmiącymi wariantami słów w wielu językach, może być niezwykle przydatna narzędzie. Jedną z przydatnych cech tego typu analizy jest to, że programista nie musi być ekspertem lingwistyki ani fonetyki, aby móc korzystać z tych narzędzi. Deweloper ma również dużą elastyczność w definiowaniu sposobu porównywania takich danych; porównania można dostosować w zależności od aplikacji lub potrzeb logiki biznesowej.
Mamy nadzieję, że ta dziedzina badań przyciągnie więcej uwagi w sferze badawczej, a w przyszłości pojawią się bardziej wydajne i solidne narzędzia analityczne.