Podczas wykonywania zapytania optymalizator programu SQL Server próbuje znaleźć najlepszy plan zapytania na podstawie istniejących indeksów i dostępnych najnowszych statystyk przez rozsądny czas, oczywiście, jeśli plan ten nie jest już przechowywany w pamięci podręcznej serwera. Jeśli nie, zapytanie jest wykonywane zgodnie z tym planem, a plan jest przechowywany w pamięci podręcznej serwera. Jeśli plan został już zbudowany dla tego zapytania, zapytanie jest wykonywane zgodnie z istniejącym planem.
Interesuje nas następujący problem:
Podczas kompilacji planu zapytania, przy sortowaniu możliwych indeksów, jeśli serwer nie znajdzie najlepszego indeksu, brakujący indeks jest zaznaczany w planie zapytania, a serwer prowadzi statystyki dotyczące takich indeksów:ile razy serwer wykorzystałby ten indeks i ile kosztowałoby to zapytanie.
W tym artykule przeanalizujemy te brakujące indeksy – jak sobie z nimi radzić.
Rozważmy to na konkretnym przykładzie. Utwórz kilka tabel w naszej bazie danych na serwerze lokalnym i testowym:
[rozwiń tytuł =”Kod”]
if object_id ('orders_detail') is not null drop table orders_detail;
if object_id('orders') is not null drop table orders;
go
create table orders
(
id int identity primary key,
dt datetime,
seller nvarchar(50)
)
create table orders_detail
(
id int identity primary key,
order_id int foreign key references orders(id),
product nvarchar(30),
qty int,
price money,
cost as qty * price
)
go
with cte as
(
select 1 id union all
select id+1 from cte where id < 20000
)
insert orders
select
dt,
seller
from
(
select
dateadd(day,abs(convert(int,convert(binary(4),newid()))%365),'2016-01-01') dt,
abs(convert(int,convert(binary(4),newid()))%5)+1 seller_id
from cte
) c
left join
(
values
(1,'John'),
(2,'Mike'),
(3,'Ann'),
(4,'Alice'),
(5,'George')
) t (id,seller) on t.id = c.seller_id
option(maxrecursion 0)
insert orders_detail
select
order_id,
product,
qty,
price
from
(
select
o.id as order_id,
abs(convert(int,convert(binary(4),newid()))%5)+1 product_id,
abs(convert(int,convert(binary(4),newid()))%20)+1 qty
from orders o cross join
(
select top(abs(convert(int,convert(binary(4),newid()))%5)+1) *
from
(
values (1),(2),(3),(4),(5),(6),(7),(8)
) n(num)
) n
) c
left join
(
values
(1,'Sugar', 50),
(2,'Milk', 80),
(3,'Bread', 20),
(4,'Pasta', 40),
(5,'Beer', 100)
) t (id,product, price) on t.id = c.product_id
go [/rozwiń]
Struktura jest prosta i składa się z dwóch tabel. Pierwsza tabela to zamówienia z takimi polami jak identyfikator, data sprzedaży i sprzedawca. Drugi to szczegóły zamówienia, gdzie niektóre towary są wyszczególnione wraz z ceną i ilością.
Spójrz na proste zapytanie i jego plan:
select count(*) from orders o join orders_detail d on o.id = d.order_id where d.cost > 1800 go
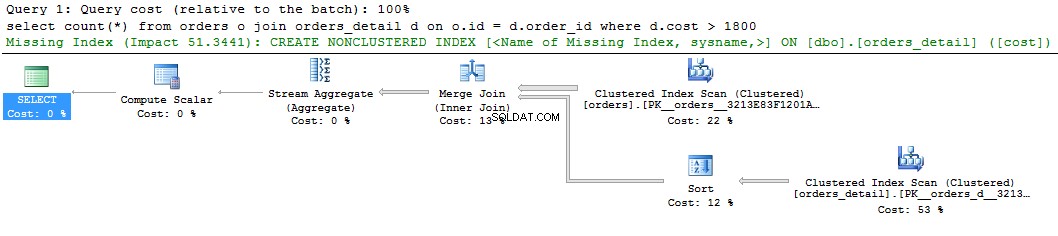
Na graficznym wyświetlaczu planu zapytania widzimy zieloną podpowiedź o brakującym indeksie. Jeśli klikniesz go prawym przyciskiem myszy i wybierzesz „Brakujące szczegóły indeksu ..”, pojawi się tekst sugerowanego indeksu. Jedyne, co należy zrobić, to usunąć komentarze z tekstu i nadać indeksowi nazwę. Skrypt jest gotowy do wykonania.
Nie będziemy budować indeksu, który otrzymaliśmy z podpowiedzi dostarczonej przez SSMS. Zamiast tego zobaczymy, czy ten indeks będzie rekomendowany przez dynamiczne widoki połączone z brakującymi indeksami. Widoki są następujące:
select * from sys.dm_db_missing_index_group_stats select * from sys.dm_db_missing_index_details select * from sys.dm_db_missing_index_groups
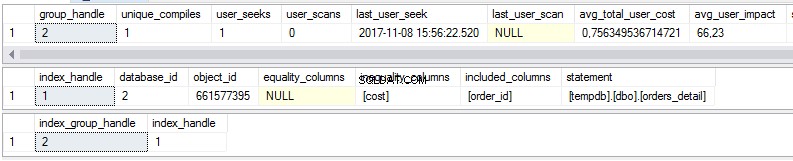
Jak widać, w pierwszym widoku dostępne są statystyki dotyczące brakujących indeksów:
- Ile razy zostałoby wykonane wyszukiwanie, gdyby istniał sugerowany indeks?
- Ile razy zostałoby wykonane skanowanie, gdyby istniał sugerowany indeks?
- Ostatnia data i godzina użycia indeksu
- Aktualny rzeczywisty koszt planu zapytania bez sugerowanego indeksu.
Drugi widok to treść indeksu:
- Baza danych
- Obiekt/tabela
- Posortowane kolumny
- Dodano kolumny w celu zwiększenia zasięgu indeksu
Trzeci widok to połączenie pierwszego i drugiego widoku.
W związku z tym nie jest trudno uzyskać skrypt, który wygeneruje skrypt do tworzenia brakujących indeksów z tych dynamicznych widoków. Skrypt wygląda następująco:
[rozwiń tytuł=”Kod”]
with igs as
(
select *
from sys.dm_db_missing_index_group_stats
)
, igd as
(
select *,
isnull(equality_columns,'')+','+isnull(inequality_columns,'') as ix_col
from sys.dm_db_missing_index_details
)
select --top(10)
'use ['+db_name(igd.database_id)+'];
create index ['+'ix_'+replace(convert(varchar(10),getdate(),120),'-','')+'_'+convert(varchar,igs.group_handle)+'] on '+
igd.[statement]+'('+
case
when left(ix_col,1)=',' then stuff(ix_col,1,1,'')
when right(ix_col,1)=',' then reverse(stuff(reverse(ix_col),1,1,''))
else ix_col
end
+') '+isnull('include('+igd.included_columns+')','')+' with(online=on, maxdop=0)
go
' command
,igs.user_seeks
,igs.user_scans
,igs.avg_total_user_cost
from igs
join sys.dm_db_missing_index_groups link on link.index_group_handle = igs.group_handle
join igd on link.index_handle = igd.index_handle
where igd.database_id = db_id()
order by igs.avg_total_user_cost * igs.user_seeks desc [/rozwiń]
Dla wydajności indeksu wyprowadzane są brakujące indeksy. Idealnym rozwiązaniem jest sytuacja, gdy ten zestaw wyników nic nie zwraca. W naszym przykładzie zestaw wyników zwróci co najmniej jeden indeks:

Kiedy nie ma czasu i nie masz ochoty zajmować się błędami klienta, wykonałem zapytanie, skopiowałem pierwszą kolumnę i wykonałem na serwerze. Potem wszystko działało dobrze.
Polecam świadomie traktować informacje o tych indeksach. Na przykład, jeśli system zaleca następujące indeksy:
create index ix_01 on tbl1 (a,b) include (c) create index ix_02 on tbl1 (a,b) include (d) create index ix_03 on tbl1 (a)
A te indeksy są używane do wyszukiwania, jest całkiem oczywiste, że bardziej logiczne jest zastąpienie tych indeksów jednym, który obejmie wszystkie trzy sugerowane:
create index ix_1 on tbl1 (a,b) include (c,d)
Dlatego dokonujemy przeglądu brakujących indeksów przed wdrożeniem ich na serwer produkcyjny. Mimo że…. Ponownie, na przykład, wdrożyłem utracone indeksy na serwerze TFS, zwiększając w ten sposób ogólną wydajność. Wykonanie tej optymalizacji zajęło minimum czasu. Jednak przy zmianie z TFS 2015 na TFS 2017 napotkałem problem, że nie było aktualizacji z powodu tych nowych indeksów. Niemniej jednak można je łatwo znaleźć po masce
select * from sys.indexes where name like 'ix[_]2017%'
Przydatne narzędzie:
dbForge Index Manager – poręczny dodatek SSMS do analizy stanu indeksów SQL i rozwiązywania problemów z fragmentacją indeksów.