Sprzężenie wewnętrzne, sprzężenie zewnętrzne, sprzężenie krzyżowe? Co daje?
To ważne pytanie. Kiedyś widziałem kod Visual Basic z osadzonymi w nim kodami T-SQL. Kod VB pobiera rekordy tabeli z wieloma instrukcjami SELECT, po jednym SELECT * na tabelę. Następnie łączy wiele zestawów wyników w zestaw rekordów. Absurd?
Dla młodych deweloperów, którzy to zrobili, tak nie było. Ale kiedy poprosili mnie o ocenę, dlaczego system działa wolno, ten problem jako pierwszy zwrócił moją uwagę. Zgadza się. Nigdy nie słyszeli o złączeniach SQL. W stosunku do nich byli uczciwi i otwarci na sugestie.
Jak opisać złączenia SQL? Być może pamiętasz jedną piosenkę – Wyobraź sobie przez Johna Lennona:
Możesz powiedzieć, że jestem marzycielem, ale nie tylko.
Mam nadzieję, że pewnego dnia dołączysz do nas, a świat będzie jednością.
W kontekście piosenki łączenie się jednoczy. W bazie danych SQL połączenie rekordów z 2 lub więcej tabel w jeden zestaw wyników tworzy sprzężenie .
Ten artykuł jest początkiem trzyczęściowej serii poświęconej złączeniom SQL:
- DOŁĄCZENIE WEWNĘTRZNE
- POŁĄCZENIE ZEWNĘTRZNE, które obejmuje LEWY, PRAWY i PEŁNY
- POŁĄCZENIE KRZYŻOWE
Ale zanim zaczniemy omawiać INNER JOIN, opiszmy ogólnie złączenia.

Więcej informacji o SQL JOIN
Sprzężenia pojawiają się zaraz po klauzuli FROM. W najprostszej postaci wygląda to tak, jakby używano standardu SQL-92:
FROM <źródło tabeli> [] JOIN <źródło tabeli> [] [ON ] [ JOIN <źródło tabeli> [] [ON ] JOIN <źródło tabeli> [] [ON ]][WHERE ] Opiszmy codzienne sprawy związane z JOIN.
Źródła tabeli
Według Microsoftu można dodać do 256 źródeł tabel. Oczywiście zależy to od zasobów Twojego serwera. Nigdy w życiu nie grałem przy więcej niż 10 stołach, nie wspominając o 256. W każdym razie źródłami przy stołach mogą być:
- Stół
- Widok
- Synonim tabeli lub widoku
- Zmienna tabeli
- Funkcja o wartościach tabelarycznych
- Tabela pochodna
Alias tabeli
Alias jest opcjonalny, ale skraca kod i minimalizuje pisanie. Pomaga również uniknąć błędów, gdy nazwa kolumny istnieje w co najmniej dwóch tabelach używanych w operacjach SELECT, UPDATE, INSERT lub DELETE. Dodaje również przejrzystości Twojemu kodowi. Jest to opcjonalne, ale polecam używanie aliasów. (O ile nie lubisz wpisywać źródeł tabeli według nazwy).
Warunek dołączenia
Słowo kluczowe ON poprzedza warunek złączenia, który może być pojedynczym złączeniem lub kolumnami z 2 kluczami z 2 połączonych tabel. Lub może to być łączenie złożone wykorzystujące więcej niż 2 kluczowe kolumny. Określa, w jaki sposób tabele są powiązane.
Jednak używamy warunku złączenia tylko dla złączeń INNER i OUTER. Użycie go na CROSS JOIN spowoduje błąd.
Ponieważ warunki łączenia definiują relacje, potrzebują operatorów.
Najczęstszym operatorem warunku złączenia jest operator równości (=). Inne operatory, takie jak> lub <, również działają, ale są rzadkie.
SQL JOIN a podzapytania
Większość sprzężeń można przepisać jako podzapytania i odwrotnie. Zapoznaj się z tym artykułem, aby dowiedzieć się więcej o podzapytaniach w porównaniu z połączeniami.
Połączenia i tabele pochodne
Używanie tabel pochodnych w łączeniu wygląda tak:
FROM tabela1 aINNER JOIN (WYBIERZ y.kolumna3 z tabeli2 x INNER JOIN tabela3 y na x.kolumna1 =y.kolumna1) b ON a.col1 =b.col2 Łączy się z wyniku innej instrukcji SELECT i jest całkowicie poprawne.
Będziesz miał więcej przykładów, ale zajmijmy się ostatnią rzeczą dotyczącą SQL JOINS. W ten sposób łączą się procesy Optymalizatora zapytań SQL Server.
Jak SQL Server przetwarza połączenia
Aby zrozumieć, jak działa ten proces, musisz wiedzieć o dwóch rodzajach związanych z nim operacji:
- Operacje logiczne odpowiadają typom złączeń użytych w zapytaniu:INNER, OUTER lub CROSS. Ty, jako programista, definiujesz tę część przetwarzania podczas tworzenia zapytania.
- Operacje fizyczne – Optymalizator zapytań wybiera najlepszą operację fizyczną odpowiednią dla Twojego przyłączenia. Najlepszy oznacza najszybszy do uzyskania wyników. Plan wykonania twojego zapytania pokaże wybrane fizyczne operatory złączenia. Te operacje to:
- Dołączanie do pętli zagnieżdżonych. Ta operacja jest szybka, jeśli jedna z dwóch tabel jest mała, a druga duża i zindeksowana. Wymaga najmniejszej liczby operacji we/wy przy najmniejszej liczbie porównań, ale nie jest dobre w przypadku dużych zestawów wyników.
- Scal Dołącz. Jest to najszybsza operacja dla dużych i posortowanych zestawów wyników według kolumn użytych w łączeniu.
- Dołączanie haszujące. Optymalizator zapytań używa go, gdy zestaw wyników jest zbyt duży dla pętli zagnieżdżonej, a dane wejściowe są nieposortowane w przypadku łączenia scalającego. Hash jest bardziej wydajny niż sortowanie go w pierwszej kolejności i stosowanie łączenia scalającego.
- Dołączanie adaptacyjne. Począwszy od SQL Server 2017, umożliwia wybór między pętlą zagnieżdżoną a skrótem . Metoda łączenia jest odroczona do momentu przeskanowania pierwszego wejścia. Ta operacja dynamicznie przełącza się na lepsze połączenie fizyczne bez ponownej kompilacji.

Dlaczego musimy się tym przejmować?
Jedno słowo:wydajność.
Jedną rzeczą jest wiedzieć, jak tworzyć zapytania ze sprzężeniami, aby uzyskać prawidłowe wyniki. Kolejnym jest sprawienie, by działał tak szybko, jak to możliwe. Musisz się tym bardziej martwić, jeśli chcesz mieć dobrą reputację wśród swoich użytkowników.
Na co więc należy zwrócić uwagę w planie wykonania dla tych operacji logicznych?
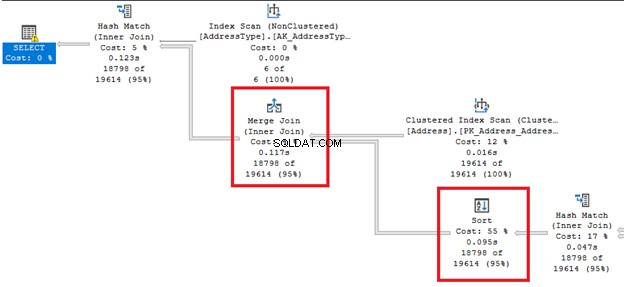
- Załóżmy, że operator sortowania poprzedza sprzężenie scalające . Ta operacja sortowania jest kosztowna w przypadku dużych tabel (rysunek 2). Możesz to naprawić, wstępnie sortując tabele wejściowe w łączeniu.
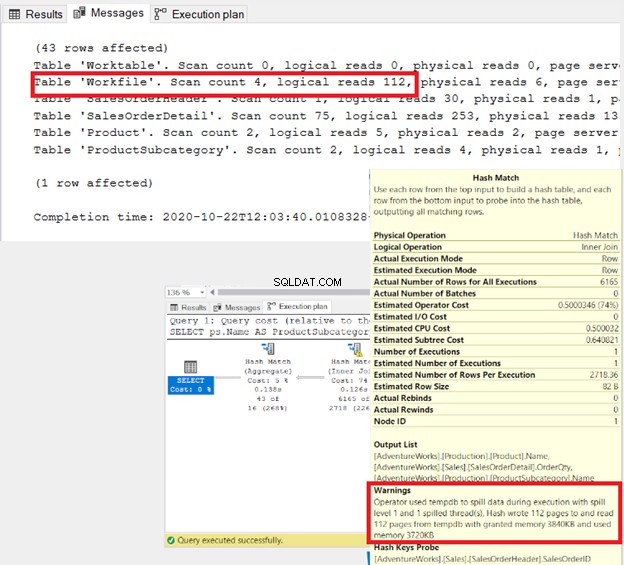
- Załóżmy, że w tabelach wejściowych połączenia scalającego znajdują się duplikaty . SQL Server zapisze duplikaty drugiej tabeli w tabeli roboczej w tempdb. Następnie dokona tam porównań. STATISTICS IO ujawni wszystkie zaangażowane tabele robocze.
- Gdy ogromne ilości danych przelewają się do tempdb w Hash jo w, STATISTICS IO pokaże duży logiczny odczyt w WorkFiles lub WorkTables. Ostrzeżenie pojawi się również w Planie wykonania (Rysunek 3). Możesz zastosować dwie rzeczy:wstępnie posortować tabele wejściowe lub zmniejszyć liczbę sprzężeń, jeśli to możliwe. W rezultacie Optymalizator zapytań może wybrać inne połączenie fizyczne.
Wskazówki dotyczące dołączania
Wskazówki dotyczące złączeń są nowością w programie SQL Server 2019. Gdy są używane w sprzężeniach, informują optymalizator kwerendy, aby przestał decydować, co jest najlepsze dla kwerendy. Ty jesteś szefem, jeśli chodzi o użycie połączenia fizycznego.
A teraz zatrzymaj się, właśnie tam. Prawda jest taka, że optymalizator zapytań zazwyczaj wybiera najlepsze sprzężenie fizyczne dla zapytania. Jeśli nie wiesz, co robisz, nie używaj wskazówek dotyczących łączenia.
Możliwe wskazówki, które możesz określić, to LOOP, MERGE, HASH lub REMOTE.
Nie korzystałem z podpowiedzi łączenia, ale oto składnia:
JOIN <źródło tabeli> [] ON Wszystko o INNER JOIN
INNER JOIN zwraca wiersze z pasującymi rekordami w obu tabelach na podstawie warunku. Jest to również domyślne połączenie, jeśli nie określisz słowa kluczowego INNER:
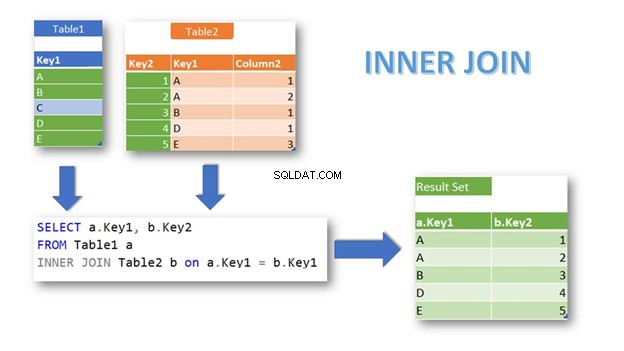
Jak widzisz, pasujące wiersze z Tabela1 i Tabela2 są zwracane przy użyciu Klucza1 jako warunek sprzężenia. Tabela1 rekord mający Klucz1 =„C” jest wykluczone, ponieważ nie ma pasujących rekordów w Tabela2 .
Za każdym razem, gdy tworzę zapytanie, moim pierwszym wyborem jest INNER JOIN. OUTER JOIN pojawia się tylko wtedy, gdy wymagają tego wymagania.
Składnia INNER JOIN
W T-SQL obsługiwane są dwie składnie INNER JOIN:SQL-92 i SQL-89.
ZŁĄCZENIE WEWNĘTRZNE SQL-92
FROM <źródło1 tabeli> []INNER JOIN <źródło2 tabeli> [] ON [INNER JOIN <źródło3 tabeli> [] ON INNER JOIN <źródło tabeliN> [] ON ][WHERE ] ZŁĄCZENIE WEWNĘTRZNE SQL-89
FROM <źródło1 tabeli> [alias1], <źródło2 tabeli> [alias2] [, <źródło3 tabeli> [alias3], <źródłoN tabeli> [aliasN]]WHERE ()[AND ( )ORAZ ()ORAZ ()] Która składnia INNER JOIN jest lepsza?
Pierwszą składnią łączenia, której się nauczyłem, była SQL-89. Kiedy wreszcie pojawił się SQL-92, pomyślałem, że jest zbyt długi. Pomyślałem też, że skoro dane wyjściowe były takie same, po co zawracać sobie głowę wpisywaniem większej liczby słów kluczowych? Graficzny projektant zapytań miał wygenerowany kod SQL-92 i zmieniłem go z powrotem na SQL-89. Ale dzisiaj wolę SQL-92, nawet jeśli muszę pisać więcej. Oto dlaczego:
- Intencja typu przyłączenia jest jasna. Następny facet lub dziewczyna, który będzie zajmował się moim kodem, będzie wiedział, co jest przeznaczone w zapytaniu.
- Zapomnienie warunku złączenia w składni SQL-92 wywoła błąd. Tymczasem zapomnienie warunku złączenia w SQL-89 będzie traktowane jako CROSS JOIN. Gdybym miał na myśli dołączenie INNER lub OUTER, byłby to niezauważalny błąd logiczny, dopóki użytkownicy nie narzekają.
- Nowe narzędzia są bardziej skłonne do SQL-92. Jeśli kiedykolwiek ponownie użyję graficznego projektanta zapytań, nie muszę zmieniać go na SQL-89. Nie jestem już uparty, więc moje tętno wróciło do normy. Pozdrawiam mnie.
Powyższe powody są moje. Możesz mieć swoje powody, dla których wolisz SQL-92 lub dlaczego go nienawidzisz. Zastanawiam się, jakie to są powody. Daj mi znać w sekcji komentarzy poniżej.
Ale nie możemy zakończyć tego artykułu bez przykładów i wyjaśnień.
10 przykładów ŁĄCZENIA WEWNĘTRZNEGO
1. Łączenie 2 stołów
Oto przykład 2 tabel połączonych razem przy użyciu INNER JOIN w składni SQL-92.
-- Wyświetl kamizelki, kaski i lekkie produktyUSE AdventureWorksGOSELECT p.IDProduktu,P.Name AS [Produkt],ps.ProductSubcategoryID,ps.Name AS [ProductSubCategory]FROM Production.Product pINNER JOIN Production.ProductSubcategory ps ON P.ProductSubcategoryID =ps.ProductSubcategoryIDGDZIE P.ProductSubcategoryID IN (25, 31, 33); -- dla kamizelki, kasku i światła -- podkategorie produktów Określasz tylko te kolumny, których potrzebujesz. W powyższym przykładzie określono 4 kolumny. Wiem, że to za dużo niż SELECT *, ale pamiętaj:to najlepsza praktyka.
Zwróć także uwagę na użycie aliasów tabel. Zarówno Produkt i Podkategoria Produktu tabele mają kolumnę o nazwie [Nazwa ]. Jeśli nie określisz aliasu, zostanie wyzwolony błąd.
Tymczasem oto równoważna składnia SQL-89:
-- Wyświetl kamizelki, kaski i lekkie produktyUSE AdventureWorksGOSELECT p.ID produktu,P.Name AS [Produkt],ps.ProductSubcategoryID,ps.Name AS [ProductSubCategory]FROM Production.Product p, Production.ProductSubcategory ps GDZIE P.ProductSubcategoryID =ps.ProductSubcategoryIDAND P.ProductSubcategoryID IN (25, 31, 33); Są takie same, z wyjątkiem warunku złączenia wymieszanego w klauzuli WHERE ze słowem kluczowym AND. Ale pod maską, czy naprawdę są takie same? Sprawdźmy zestaw wyników, IO STATISTICS i plan wykonania.
Zobacz zestaw wyników 9 rekordów:
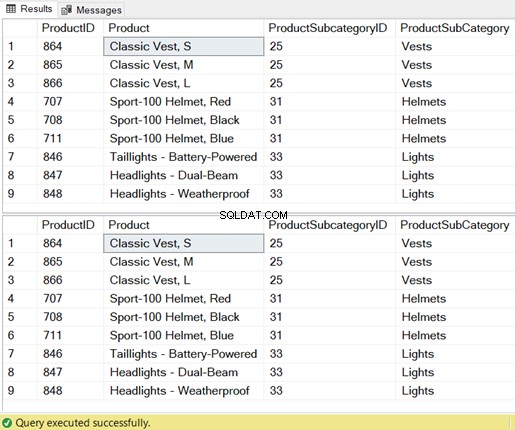
To nie tylko wyniki, ale również zasoby wymagane przez SQL Server są takie same.
Zobacz logiczne odczyty:
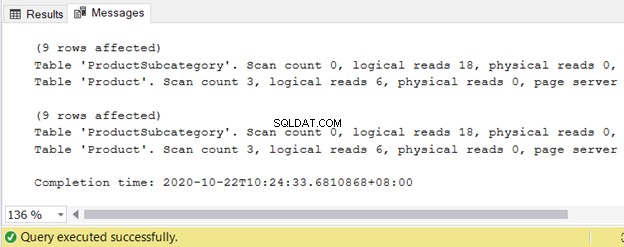
Wreszcie, plan wykonania ujawnia ten sam plan zapytań dla obu zapytań, gdy ich QueryPlanHashes są równe. Zwróć także uwagę na podświetlone operacje na diagramie:
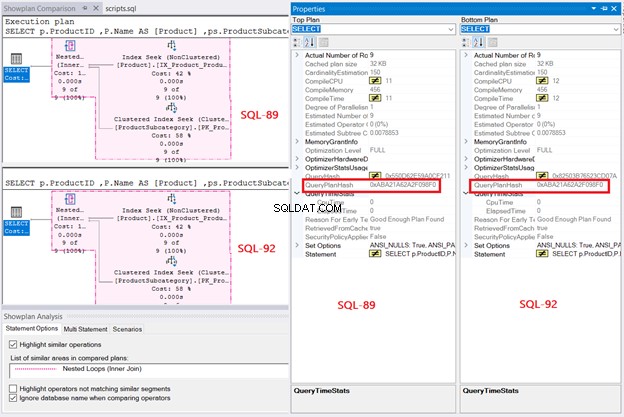
Z ustaleń wynika, że przetwarzanie zapytań SQL Server jest takie samo, niezależnie od tego, czy jest to SQL-92, czy SQL-89. Ale jak powiedziałem, przejrzystość w SQL-92 jest dla mnie znacznie lepsza.
Rysunek 7 pokazuje również zagnieżdżone łączenie pętli używane w planie. Czemu? Zestaw wyników jest mały.
2. Dołączanie do wielu stołów
Sprawdź poniższe zapytanie przy użyciu 3 połączonych tabel.
-- Pobierz całkowitą liczbę zamówień na kategorię produktówUSE AdventureWorksGOSELECT ps.Name AS ProductSubcategory,SUM(sod.OrderQty) AS TotalOrdersFROM Production.Product pinNER JOIN Sales.SalesOrderDetail sod ON P.ProductID =sod.ProductIDINNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID =soh.SalesOrderIDINNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID =ps.ProductSubcategoryIDWHERE soh.OrderDate BETWEEN '1/1/2014' AND '31.12.2014'AND p.ProductSubcategory 1,2) GRUPUJ WEDŁUG ps.NazwaHAVING ps.Nazwa IN („Rowery górskie”, „Rowery szosowe”) 3. Połączenie kompozytowe
Możesz także dołączyć do 2 stołów za pomocą 2 klawiszy, aby je powiązać. Sprawdź przykład poniżej. Używa 2 warunków złączenia z operatorem AND.
SELECT a.column1,b.column1,b.column2FROM Tabela1 aINNER JOIN Tabela2 b ON a.column1 =b.column1 AND a.column2 =b.column2 4. ŁĄCZENIE WEWNĘTRZNE Korzystanie z fizycznego łączenia zagnieżdżonej pętli
W poniższym przykładzie Produkt stół posiada 9 rekordów – mały zestaw. Połączona tabela to SalesOrderDetail – duży zestaw. Optymalizator zapytań użyje połączenia zagnieżdżonej pętli, jak pokazano na rysunku 8.
USE AdventureWorksGOSELECT sod.SalesOrderDetailID,sod.IDProduktu,P.Name,P.ProductNumber,sod.OrderQtyFROM Sales.SalesOrderDetail sodINNER JOIN Produkcja.Produkt p ON sod.IDProduktu =p.IDProduktuWHERE P.ProductSubcategoryID IN(25 , 31, 33); 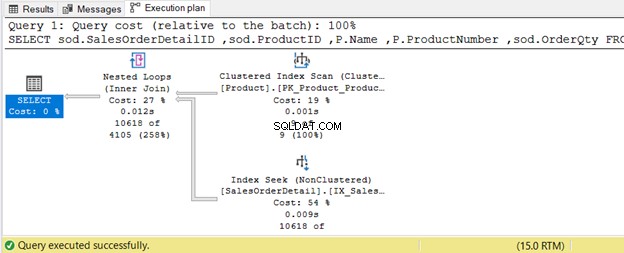
5. DOŁĄCZENIE WEWNĘTRZNE Korzystanie z połączenia fizycznego scalającego
Poniższy przykład używa łączenia scalającego, ponieważ obie tabele wejściowe są sortowane według SalesOrderID.
SELECT soh.SalesOrderID,soh.OrderDate,sod.SalesOrderDetailID,sod.ProductID,sod.LineTotalFROM Sales.SalesOrderHeader sohINNER JOIN sales.SalesOrderDetail sod ON soh.SalesOrderID =sod.SalesOrderID 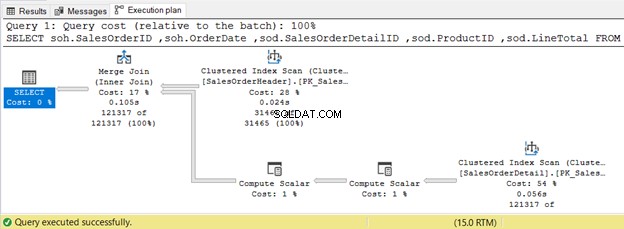
6. ŁĄCZENIE WEWNĘTRZNE Korzystanie z połączenia fizycznego haszującego
Poniższy przykład użyje Hash Join:
SELECT s.Name AS Store,SUM(soh.TotalDue) AS TotalSalesFROM Sales.SalesOrderHeader sohINNER JOIN Sales.Store s ON soh.SalesPersonID =s.SalesPersonIDGROUP BY s.Name 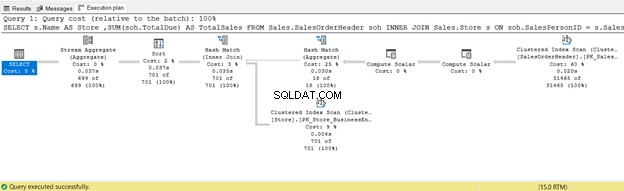
7. ŁĄCZENIE WEWNĘTRZNE Korzystanie z adaptacyjnego łączenia fizycznego
W poniższym przykładzie Sprzedawca tabela ma indeks Non-clustered ColumnStore na TerritoryID kolumna. Optymalizator zapytań zdecydował o połączeniu zagnieżdżonej pętli, jak pokazano na rysunku 11.
SELECTsp.BusinessEntityID,sp.SalesQuota,st.Name AS TerritoryFROM Sales.SalesPerson spinner JOIN Sales.SalesTerritory st ON sp.TerritoryID =st.TerritoryIDWHERE sp.TerritoryID BETWEEN 1 AND 5 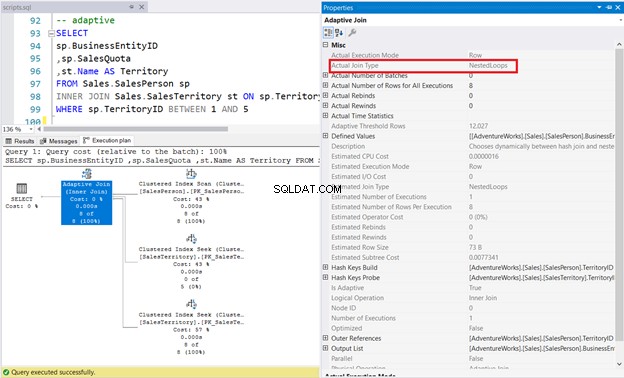
8. Dwa sposoby na przepisanie podzapytania do wewnętrznego sprzężenia
Rozważ to stwierdzenie z zagnieżdżonym podzapytaniem:
SELECT [IDZamówieniaSprzedaży], [DataZamówienia], [DataWysyłki], [IDKlienta]FROM Sprzedaż.NagłówekZamówieniaSprzedaży WHERE [IdentyfikatorKlienta] IN (SELECT [IdentyfikatorKlienta] FROM Sprzedaż.Klient WHERE IDosoby IN (SELECT IdentyfikatorPodmiotuBiznesowego FROM Osoba.Osoba GDZIE nazwisko LIKE N'I%' AND PersonType='SC')) Te same wyniki mogą pojawić się, jeśli zmienisz je na DOŁĄCZENIE WEWNĘTRZNE, jak poniżej:
SELECT o.[IDZamówieniaSprzedaży], o.[DataZamówienia], o.[Data Wysyłki], o.[IDKlienta]FROM Sprzedaż.NagłówekZamówieniaSprzedaży oINNER JOIN Sprzedaż.Klient c on o.IDKlienta =c.IDKlienta JOIN Osoba .Person p ON c.PersonID =p.BusinessEntityIDWHERE p.PersonType ='SC'AND p.lastname LIKE N'I%' Innym sposobem na przepisanie go jest użycie tabeli pochodnej jako źródła tabeli dla ZŁĄCZENIA WEWNĘTRZNEGO:
SELECT o.[IDZamówieniaSprzedaży],o.[DataZamówienia],o.[DataWysyłki],o.[IDKlienta]FROM Sprzedaż.NagłówekZamówieniaSprzedaży oINNER JOIN (SELECT c.IDKlienta, P.PersonType, P.LastName FROM Sales.Customer c INNER JOIN Osoba.Osoba p ON c.PersonID =P.BusinessEntityID WHERE p.PersonType ='SC' AND p.LastName LIKE N'I%') AS q ON o.CustomerID =q.CustomerID
Wszystkie 3 zapytania generują te same 48 rekordów.
9. Korzystanie ze wskazówek dołączania
Następujące zapytanie używa pętli zagnieżdżonej:
SELECT sod.SalesOrderDetailID,sod.IDProduktu,P.Name,P.ProductNumber,sod.OrderQtyFROM Sprzedaż.SalesOrderDetail sodINNER JOIN Produkcja.Produkt p ON sod.IDProduktu =p.IDProduktuWHERE P.ProductSubcategoryID IN(25, 31, 33);
Jeśli chcesz wymusić połączenie haszujące, dzieje się tak:
SELECT sod.SalesOrderDetailID,sod.IDProduktu,P.Name,P.ProductNumber,sod.OrderQtyFROM Sprzedaż.SprzedażSzczegółyZamówienia sodINNER HASH JOIN Produkcja.Produkt p ON sod.IDProduktu =p.IDProduktuWHERE P.ProductSubcategoryID IN(25 , 31, 33);
Pamiętaj jednak, że STATISTICS IO pokazuje, że wydajność spadnie, gdy wymusisz połączenie haszujące.
Tymczasem poniższe zapytanie korzysta z połączenia scalającego:
SELECT soh.SalesOrderID,soh.OrderDate,sod.SalesOrderDetailID,sod.ProductID,sod.LineTotalFROM Sales.SalesOrderHeader sohINNER JOIN sales.SalesOrderDetail sod ON soh.SalesOrderID =sod.SalesOrderID
Oto, co się stanie, gdy zmusisz go do zagnieżdżonej pętli:
SELECT soh.SalesOrderID,soh.OrderDate,sod.SalesOrderDetailID,sod.ProductID,sod.LineTotalFROM Sales.SalesOrderHeader sohINNER LOOP JOIN sales.SalesOrderDetail sod ON soh.SalesOrderID =sod.SalesOrderID
Po sprawdzeniu STATISTICS IO obu, wymuszenie ich w zagnieżdżonej pętli wymaga więcej zasobów do przetworzenia zapytania:
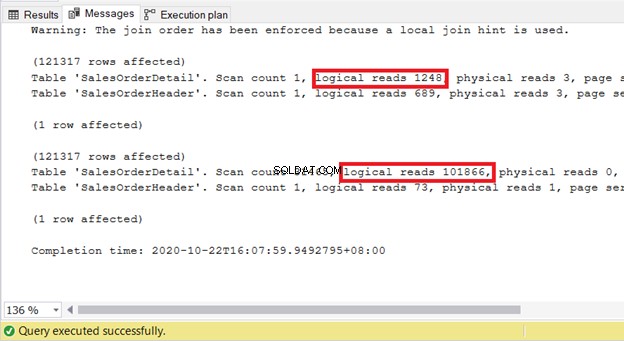
Dlatego używanie wskazówek dotyczących łączenia powinno być ostatnią deską ratunku podczas poprawiania wydajności. Pozwól, aby Twój SQL Server obsłużył to za Ciebie.
10. Korzystanie z INNER JOIN w UPDATE
Możesz również użyć INNER JOIN w instrukcji UPDATE. Oto przykład:
UPDATE Sales.SalesOrderHeaderSET ShipDate =getdate() FROM Sales.SalesOrderHeader oINNER JOIN Sales.Customer c on o.CustomerID =c.CustomerIDINNER JOIN Person.Person p ON c.PersonID =p.BusinessEntityIDGDZIE p.PersonType ='SC'
Ponieważ możliwe jest użycie połączenia w UPDATE, dlaczego nie wypróbować go za pomocą funkcji DELETE i INSERT?
SQL Join i INNER JOIN na wynos
O co więc chodzi w łączeniu SQL?
- Złączanie SQL łączy rekordy 2 lub więcej tabel w jeden zestaw wyników.
- Istnieją typy złączeń w SQL:INNER, OUTER i CROSS.
- Jako programista lub administrator decydujesz, których operacji logicznych lub typów połączeń użyć zgodnie z Twoimi wymaganiami.
- Z drugiej strony, Optymalizator zapytań wybiera najlepsze operatory łączenia fizycznego do użycia. Może to być pętla zagnieżdżona, scalanie, mieszanie lub adaptacja.
- Możesz użyć wskazówek dotyczących złączenia, aby wymusić użycie fizycznego złączenia, ale powinna to być ostatnia deska ratunku. W większości przypadków lepiej pozwolić, aby poradził sobie z tym Twój SQL Server.
- Znajomość fizycznych operatorów złączenia pomaga również w dostrajaniu wydajności zapytań.
- Ponadto podzapytania można przepisać za pomocą złączeń.
Tymczasem ten post pokazał 10 przykładów INNER JOIN. To nie tylko przykładowe kody. Niektóre z nich zawierają również inspekcję działania kodu od środka. To nie tylko pomoc w kodowaniu, ale także dbałość o wydajność. Ostatecznie wyniki powinny być nie tylko prawidłowe, ale także dostarczane szybko.
Jeszcze nie skończyliśmy. Następny artykuł będzie dotyczył ZŁĄCZEŃ ZEWNĘTRZNYCH. Bądź na bieżąco.
Zobacz także
Sprzężenia SQL umożliwiają pobieranie i łączenie danych z więcej niż jednej tabeli. Obejrzyj ten film, aby dowiedzieć się więcej o złączach SQL.