Funkcje RANK, DENSE_RANK i ROW_NUMBER służą do pobierania rosnącej liczby całkowitej. Zaczynają się wartością opartą na warunku narzuconym przez klauzulę ORDER BY. Wszystkie te funkcje wymagają poprawnego działania klauzuli ORDER BY. W przypadku danych podzielonych na partycje licznik całkowity jest resetowany do 1 dla każdej partycji.
W tym artykule szczegółowo przestudiujemy funkcje RANK, DENSE_RANK i ROW_NUMBER, ale wcześniej utwórzmy fałszywe dane, na których te funkcje mogą być używane, chyba że Twoja baza danych ma pełną kopię zapasową.
Przygotowywanie fikcyjnych danych
Wykonaj następujący skrypt, aby utworzyć bazę danych o nazwie ShowRoom i zawierającą tabelę o nazwie Samochody (zawierającą 15 losowych rekordów samochodów):
CREATE Database ShowRoom; GO USE ShowRoom; CREATE TABLE Cars ( id INT, name VARCHAR(50) NOT NULL, company VARCHAR(50) NOT NULL, power INT NOT NULL ) USE ShowRoom INSERT INTO Cars VALUES (1, 'Corrolla', 'Toyota', 1800), (2, 'City', 'Honda', 1500), (3, 'C200', 'Mercedez', 2000), (4, 'Vitz', 'Toyota', 1300), (5, 'Baleno', 'Suzuki', 1500), (6, 'C500', 'Mercedez', 5000), (7, '800', 'BMW', 8000), (8, 'Mustang', 'Ford', 5000), (9, '208', 'Peugeot', 5400), (10, 'Prius', 'Toyota', 3200), (11, 'Atlas', 'Volkswagen', 5000), (12, '110', 'Bugatti', 8000), (13, 'Landcruiser', 'Toyota', 3000), (14, 'Civic', 'Honda', 1800), (15, 'Accord', 'Honda', 2000)
Funkcja RANKING
Funkcja RANK służy do pobierania uszeregowanych wierszy na podstawie warunku klauzuli ORDER BY. Na przykład, jeśli chcesz znaleźć nazwę samochodu z trzecią najwyższą mocą, możesz użyć funkcji RANK.
Zobaczmy, jak działa funkcja RANK:
SELECT name,company, power, RANK() OVER(ORDER BY power DESC) AS PowerRank FROM Cars
Powyższy skrypt znajduje i klasyfikuje wszystkie rekordy w tabeli Samochody i porządkuje je w kolejności malejącej mocy. Wynik wygląda tak:
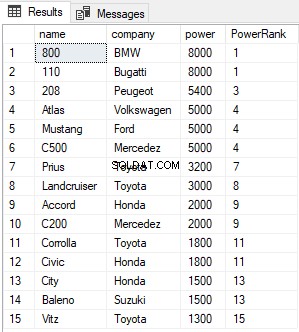
Kolumna PowerRank w powyższej tabeli zawiera RANKĘ samochodów uporządkowanych według malejącej kolejności ich mocy. Ciekawą rzeczą dotyczącą funkcji RANK jest to, że jeśli istnieje powiązanie między N poprzednimi rekordami dla wartości w kolumnie ORDER BY, funkcja RANK pomija kolejne N-1 pozycji przed zwiększeniem licznika. Na przykład w powyższym wyniku istnieje remis dla wartości w kolumnie potęgi między pierwszym a drugim wierszem, dlatego funkcja RANK pomija następny (2-1 =1) jeden rekord i przeskakuje bezpośrednio do trzeciego wiersza.
Funkcja RANK może być używana w połączeniu z klauzulą PARTITION BY. W takim przypadku ranga zostanie zresetowana dla każdej nowej partycji. Spójrz na następujący skrypt:
SELECT name,company, power, RANK() OVER(PARTITION BY company ORDER BY power DESC) AS PowerRank FROM Cars
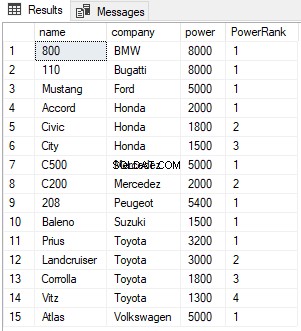
W powyższym skrypcie dzielimy wyniki według kolumny firmy. Teraz dla każdej firmy RANGA zostanie zresetowana do 1, jak pokazano poniżej:
Funkcja DENSE_RANK
Funkcja DENSE_RANK jest podobna do funkcji RANK, jednak funkcja DENSE_RANK nie pomija żadnych rang, jeśli istnieje remis między rangami poprzednich rekordów. Spójrz na następujący skrypt.
SELECT name,company, power, RANK() OVER(PARTITION BY company ORDER BY power DESC) AS PowerRank FROM Cars
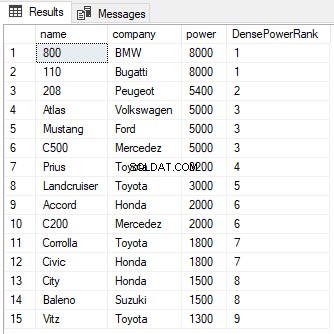
Z danych wyjściowych widać, że pomimo istnienia remisu między rangami w pierwszych dwóch wierszach, następna pozycja nie jest pomijana i ma przypisaną wartość 2 zamiast 3. Podobnie jak w przypadku funkcji RANK, klauzula PARTITION BY może być również używany z funkcją DENSE_RANK, jak pokazano poniżej:
SELECT name,company, power, DENSE_RANK() OVER(PARTITION BY company ORDER BY power DESC) AS DensePowerRank FROM Cars
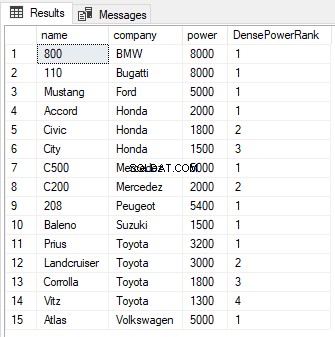
Funkcja ROW_NUMBER
W przeciwieństwie do funkcji RANK i DENSE_RANK, funkcja ROW_NUMBER po prostu zwraca numer wiersza posortowanych rekordów, zaczynając od 1. Na przykład, jeśli funkcje RANK i DENSE_RANK pierwszych dwóch rekordów w kolumnie ORDER BY są równe, oba mają przypisaną wartość 1 jako ich RANK i DENSE_RANK. Jednak funkcja ROW_NUMBER przypisze wartości 1 i 2 do tych wierszy, nie biorąc pod uwagę faktu, że są one jednakowo uwzględniane. Wykonaj następujący skrypt, aby zobaczyć, jak działa funkcja ROW_NUMBER.
SELECT name,company, power, ROW_NUMBER() OVER(ORDER BY power DESC) AS RowRank FROM Cars
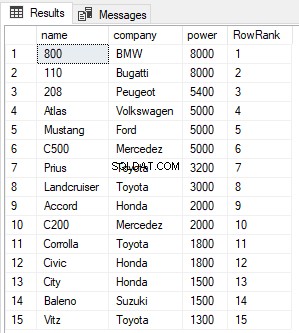
Z danych wyjściowych widać, że funkcja ROW_NUMBER po prostu przypisuje nowy numer wiersza do każdego rekordu, niezależnie od jego wartości.
Klauzula PARTITION BY może być również używana z funkcją ROW_NUMBER, jak pokazano poniżej:
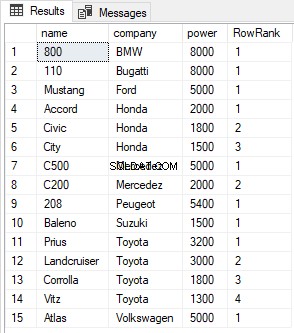
SELECT name, company, power, ROW_NUMBER() OVER(PARTITION BY company ORDER BY power DESC) AS RowRank FROM Cars
Wynik wygląda tak:
Podobieństwa między funkcjami RANK, DENSE_RANK i ROW_NUMBER
Funkcje RANK, DENSE_RANK i ROW_NUMBER mają następujące podobieństwa:
1- Wszystkie wymagają klauzuli order by.
2- Wszystkie zwracają rosnącą liczbę całkowitą o wartości bazowej 1.
3- W połączeniu z klauzulą PARTITION BY, wszystkie te funkcje resetują zwracaną wartość całkowitą do 1, jak widzieliśmy.
4- Jeśli nie ma zduplikowanych wartości w kolumnie używanej przez klauzulę ORDER BY, te funkcje zwracają to samo wyjście.
Aby zilustrować ostatni punkt, utwórzmy nową tabelę Car1 w bazie danych ShowRoom bez zduplikowanych wartości w kolumnie mocy. Wykonaj następujący skrypt:
USE ShowRoom; CREATE TABLE Cars1 ( id INT, name VARCHAR(50) NOT NULL, company VARCHAR(50) NOT NULL, power INT NOT NULL ) INSERT INTO Cars1 VALUES (1, 'Corrolla', 'Toyota', 1800), (2, 'City', 'Honda', 1500), (3, 'C200', 'Mercedez', 2000), (4, 'Vitz', 'Toyota', 1300), (5, 'Baleno', 'Suzuki', 2500), (6, 'C500', 'Mercedez', 5000), (7, '800', 'BMW', 8000), (8, 'Mustang', 'Ford', 4000), (9, '208', 'Peugeot', 5400), (10, 'Prius', 'Toyota', 3200) The cars1 table has no duplicate values. Now let’s execute the RANK, DENSE_RANK and ROW_NUMBER functions on the Cars1 table ORDER BY power column. Execute the following script: SELECT name,company, power, RANK() OVER(ORDER BY power DESC) AS [Rank], DENSE_RANK() OVER(ORDER BY power DESC) AS [Dense Rank], ROW_NUMBER() OVER(ORDER BY power DESC) AS [Row Number] FROM Cars1
Wynik wygląda tak:
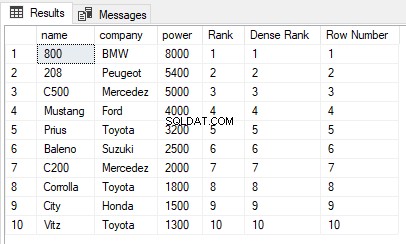
Widać, że nie ma zduplikowanych wartości w kolumnie potęgi, która jest używana w klauzuli ORDER BY, dlatego dane wyjściowe funkcji RANK, DENSE_RANK i ROW_NUMBER są takie same.
Różnica między funkcjami RANK, DENSE_RANK i ROW_NUMBER
Jedyna różnica między funkcjami RANK, DENSE_RANK i ROW_NUMBER polega na tym, że w kolumnie używanej w klauzuli ORDER BY występują zduplikowane wartości.
Jeśli wrócisz do tabeli Samochody w bazie danych ShowRoom, zobaczysz, że zawiera ona wiele zduplikowane wartości. Spróbujmy znaleźć RANK, DENSE_RANK i ROW_NUMBER tabeli Cars1 uporządkowane według potęgi. Wykonaj następujący skrypt:
SELECT nazwa,firma, władza,
RANK() OVER(ORDER BY power DESC) AS [Rank], DENSE_RANK() OVER(ORDER BY power DESC) AS [Dense Rank], ROW_NUMBER() OVER(ORDER BY power DESC) AS [Row Number] FROM Cars
Wynik wygląda tak:
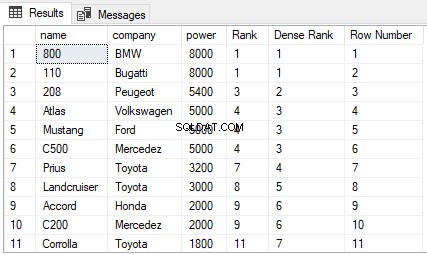
Z danych wyjściowych widać, że funkcja RANK pomija następne N-1 rang, jeśli jest remis między N poprzednimi rangami. Z drugiej strony funkcja DENSE_RANK nie pomija rang, jeśli istnieje remis między rangami. Wreszcie funkcja ROW_NUMBER nie dotyczy rankingu. Po prostu zwraca numer wiersza posortowanych rekordów. Nawet jeśli istnieją zduplikowane rekordy w kolumnie użytej w klauzuli ORDER BY, funkcja ROW_NUMBER nie zwróci zduplikowanych wartości. Zamiast tego będzie się zwiększać niezależnie od zduplikowanych wartości.
Przydatne linki:
Aby dowiedzieć się więcej o funkcjach ROW_NUMBER(), RANK() i DENSE_RANK(), przeczytaj fantastyczny artykuł Ahmada Yaseena:
Metody pozycjonowania wierszy w SQL Server:ROW_NUMBER(), RANK(), DENSE_RANK() i NTILE()