We wtorek w T-SQL w tym miesiącu Steve Jones (@way0utwest) poprosił nas o omówienie naszych najlepszych lub najgorszych doświadczeń z wyzwalaczami. Chociaż prawdą jest, że wyzwalacze są często niemile widziane, a nawet obawiają się, mają kilka ważnych przypadków użycia, w tym:
- Audyt (przed dodatkiem SP1 2016, kiedy ta funkcja stała się bezpłatna we wszystkich wydaniach)
- Egzekwowanie reguł biznesowych i integralności danych, gdy nie można ich łatwo zaimplementować w ograniczeniach, a nie chcesz, aby były zależne od kodu aplikacji lub samych zapytań DML
- Utrzymywanie historycznych wersji danych (przed przechwytywaniem danych zmian, śledzeniem zmian i tabelami czasowymi)
- Kolejkowanie alertów lub przetwarzanie asynchroniczne w odpowiedzi na określoną zmianę
- Zezwalanie na modyfikacje widoków (poprzez wyzwalacze ZAMIAST)
To nie jest wyczerpująca lista, tylko krótkie podsumowanie kilku scenariuszy, których doświadczyłem, w których wyzwalacze były wtedy właściwą odpowiedzią.
Kiedy wyzwalacze są konieczne, zawsze lubię badać użycie wyzwalaczy zamiast wyzwalaczy PO. Tak, są one trochę bardziej wstępne*, ale mają kilka całkiem ważnych zalet. Przynajmniej teoretycznie perspektywa zapobiegania działaniu (i jego konsekwencjom w dzienniku) wydaje się o wiele bardziej skuteczna niż pozwolenie na to, aby wszystko się wydarzyło, a następnie cofnięcie go.
*Mówię to, ponieważ musisz ponownie zakodować instrukcję DML w wyzwalaczu; dlatego nie nazywa się ich PRZED wyzwalaczami. Rozróżnienie jest tutaj ważne, ponieważ niektóre systemy implementują prawdziwe wyzwalacze PRZED, które po prostu uruchamiają się jako pierwsze. W SQL Server wyzwalacz INSTEAD OF skutecznie anuluje instrukcję, która spowodowała jego uruchomienie.
Załóżmy, że mamy prostą tabelę do przechowywania nazw kont. W tym przykładzie utworzymy dwie tabele, dzięki czemu będziemy mogli porównać dwa różne wyzwalacze i ich wpływ na czas trwania zapytania i wykorzystanie dziennika. Koncepcja polega na tym, że mamy regułę biznesową:nazwa konta nie jest obecna w innej tabeli, która reprezentuje „złe” nazwy, a wyzwalacz jest używany do wymuszenia tej reguły. Oto baza danych:
USE [master];
GO
CREATE DATABASE [tr] ON (name = N'tr_dat', filename = N'C:\temp\tr.mdf', size = 4096MB)
LOG ON (name = N'tr_log', filename = N'C:\temp\tr.ldf', size = 2048MB);
GO
ALTER DATABASE [tr] SET RECOVERY FULL;
GO A stoły:
USE [tr]; GO CREATE TABLE dbo.Accounts_After ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.Accounts_Instead ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.InvalidNames ( name sysname PRIMARY KEY ); INSERT dbo.InvalidNames(name) VALUES (N'poop'),(N'hitler'),(N'boobies'),(N'cocaine');
I wreszcie wyzwalacze. Dla uproszczenia mamy do czynienia tylko z wstawkami, i zarówno w przypadku po, jak i zamiast, po prostu przerwiemy całą partię, jeśli jakakolwiek nazwa narusza naszą regułę:
CREATE TRIGGER dbo.tr_Accounts_After
ON dbo.Accounts_After
AFTER INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
ROLLBACK TRANSACTION;
RETURN;
END
END
GO
CREATE TRIGGER dbo.tr_Accounts_Instead
ON dbo.Accounts_After
INSTEAD OF INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
RETURN;
END
ELSE
BEGIN
INSERT dbo.Accounts_Instead(AccountID, name, filler)
SELECT AccountID, name, filler FROM inserted;
END
END
GO Teraz, aby przetestować wydajność, spróbujemy po prostu wstawić 100 000 nazw do każdej tabeli, z przewidywalnym wskaźnikiem niepowodzeń wynoszącym 10%. Innymi słowy, 90 000 nazw jest w porządku, pozostałe 10 000 nie przechodzi testu i powoduje, że wyzwalacz albo cofa się, albo nie jest wstawiany, w zależności od partii.
Najpierw musimy zrobić trochę porządków przed każdą partią:
TRUNCATE TABLE dbo.Accounts_Instead; TRUNCATE TABLE dbo.Accounts_After; GO CHECKPOINT; CHECKPOINT; BACKUP LOG triggers TO DISK = N'C:\temp\tr.trn' WITH INIT, COMPRESSION; GO
Zanim zaczniemy mięso z każdej partii, policzymy wiersze w dzienniku transakcji i zmierzymy rozmiar oraz wolne miejsce. Następnie przejdziemy przez kursor, aby przetworzyć 100 000 wierszy w losowej kolejności, próbując wstawić każdą nazwę do odpowiedniej tabeli. Kiedy skończymy, ponownie zmierzymy liczbę wierszy i rozmiar dziennika oraz sprawdzimy czas trwania.
SET NOCOUNT ON;
DECLARE @batch varchar(10) = 'After', -- or After
@d datetime2(7) = SYSUTCDATETIME(),
@n nvarchar(129),
@i int,
@err nvarchar(512);
-- measure before and again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CONVERT(int, FILEPROPERTY(name,N'SpaceUsed')))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR
SELECT name, i = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM
(
SELECT DISTINCT TOP (90000) LEFT(o.name,64) + '/' + LEFT(c.name,63)
FROM sys.all_objects AS o
CROSS JOIN sys.all_columns AS c
UNION ALL
SELECT TOP (10000) N'boobies' FROM sys.all_columns
) AS x (name)
ORDER BY i;
OPEN c;
FETCH NEXT FROM c INTO @n, @i;
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
IF @batch = 'After'
INSERT dbo.Accounts_After(AccountID,name) VALUES(@i,@n);
IF @batch = 'Instead'
INSERT dbo.Accounts_Instead(AccountID,name) VALUES(@i,@n);
END TRY
BEGIN CATCH
SET @err = ERROR_MESSAGE();
END CATCH
FETCH NEXT FROM c INTO @n, @i;
END
-- measure again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT duration = DATEDIFF(MILLISECOND, @d, SYSUTCDATETIME()),
CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CAST(FILEPROPERTY(name,N'SpaceUsed') AS int))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
CLOSE c; DEALLOCATE c; Wyniki (uśrednione z 5 przebiegów każdej partii):
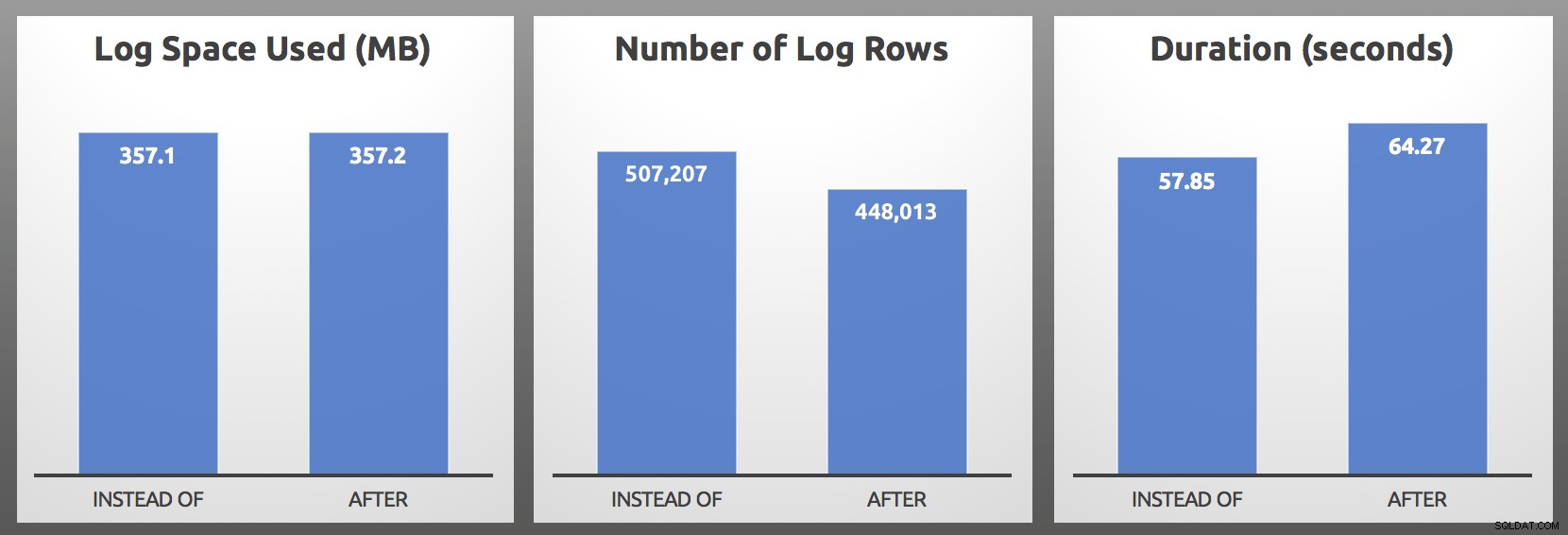 PO vs. ZAMIAST:Wyniki
PO vs. ZAMIAST:Wyniki
W moich testach użycie dziennika było prawie identyczne, z ponad 10% większą liczbą wierszy dziennika generowanych przez wyzwalacz INSTEAD OF. Pod koniec każdej partii kopałem trochę:
SELECT [Operation], COUNT(*) FROM sys.fn_dblog(NULL, NULL) GROUP BY [Operation] ORDER BY [Operation];
A oto typowy wynik (podkreśliłem główne delty):
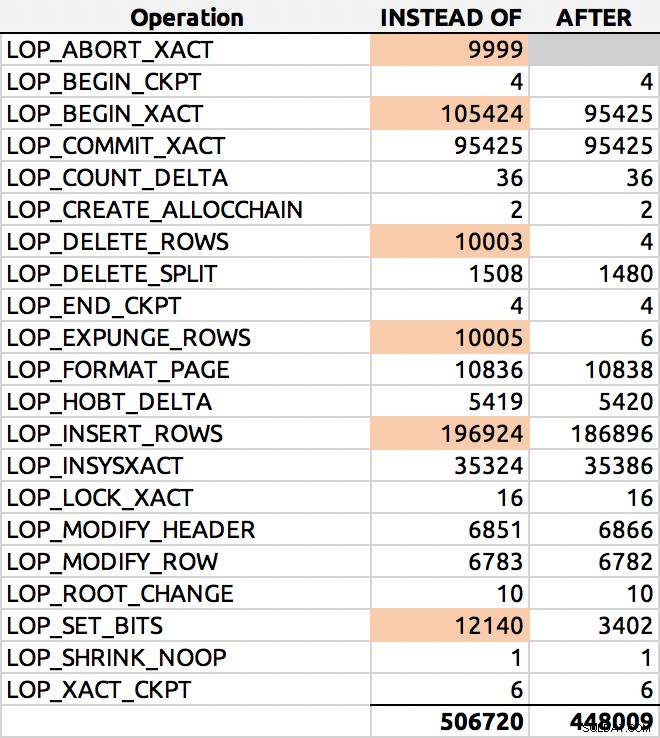 Dystrybucja wierszy dziennika
Dystrybucja wierszy dziennika
Zagłębię się w to głębiej innym razem.
Ale kiedy się do tego zabrać…
…najważniejszą metryką prawie zawsze będzie czas trwania , aw moim przypadku spust INSTEAD OF działał co najmniej 5 sekund szybciej w każdym pojedynczym teście head-to-head. Jeśli to wszystko brzmi znajomo, tak, rozmawiałem o tym wcześniej, ale wtedy nie zauważyłem tych samych objawów w wierszach dziennika.
Pamiętaj, że może to nie być dokładny schemat lub obciążenie, możesz mieć bardzo inny sprzęt, współbieżność może być wyższa, a wskaźnik niepowodzeń może być znacznie wyższy (lub niższy). Moje testy przeprowadzono na izolowanej maszynie z dużą ilością pamięci i bardzo szybkimi dyskami SSD PCIe. Jeśli dziennik znajduje się na wolniejszym dysku, różnice w wykorzystaniu dziennika mogą przeważyć nad innymi metrykami i znacznie zmienić czas trwania. Wszystkie te czynniki (i więcej!) mogą wpłynąć na Twoje wyniki, więc powinieneś testować w swoim środowisku.
Chodzi jednak o to, że wyzwalacze zamiast wyzwalaczy mogą być lepiej dopasowane. Teraz, gdybyśmy tylko mogli uzyskać wyzwalacze ZAMIAST DDL…