Wprowadzenie
W kręgach baz danych powszechnie wiadomo, że indeksy poprawiają wydajność zapytań albo całkowicie spełniają wymagany zestaw wyników (Covering Indexes) lub działają jako wyszukiwania, które z łatwością kierują silnik zapytań do dokładnej lokalizacji wymaganego zestawu danych. Jednak, jak wiedzą doświadczeni administratorzy baz danych, nie należy być entuzjastycznie nastawionym do tworzenia indeksów w środowiskach OLTP bez zrozumienia natury obciążenia. Używając Query Store w instancji SQL Server 2019 (Query Store został wprowadzony w SQL Server 2016), dość łatwo jest pokazać wpływ indeksu na wstawki.
Wstaw bez indeksu
Zaczynamy od przywrócenia bazy danych WideWorldImporters Sample, a następnie utworzenia kopii Sales. Tabela faktur przy użyciu skryptu z Listingu 1. Zauważ, że przykładowa baza danych ma już włączoną opcję Query Store w trybie do odczytu i zapisu.
-- Listing 1 Utwórz kopię fakturSELECT * INTO [SPRZEDAŻ].[INVOICES1] FROM [SPRZEDAŻ].[INVOICES] WHERE 1=2;
Zauważ, że w tabeli, którą właśnie utworzyliśmy, nie ma żadnych indeksów. Wszystko, co mamy, to struktura tabeli. Po zakończeniu wstawiamy do nowej tabeli, używając danych z jej rodzica, jak pokazano na Listingu 2.
-- Listing 2 Wypełnij Faktury1-- OBCIĄĆ TABELĘ [SPRZEDAŻ].[FAKTURY1]WSTAW DO [SPRZEDAŻ].[FAKTURY1] SELECT * Z [SPRZEDAŻ].[FAKTURY]; PRZEJDŹ 100
Podczas tej operacji Query Store przechwytuje plan wykonania zapytania. Rysunek 1 pokazuje pokrótce, co dzieje się pod maską. Czytając od lewej do prawej, widzimy, że SQL Server wykonuje wstawki przy użyciu Identyfikatora planu 563 – skanowanie indeksu klucza podstawowego tabeli źródłowej w celu pobrania danych, a następnie wstawienie tabeli do tabeli docelowej. (Czytanie od lewej do prawej). Zauważ, że w tym przypadku większość kosztów znajduje się na wstawce do tabeli – 99% kosztu zapytania.
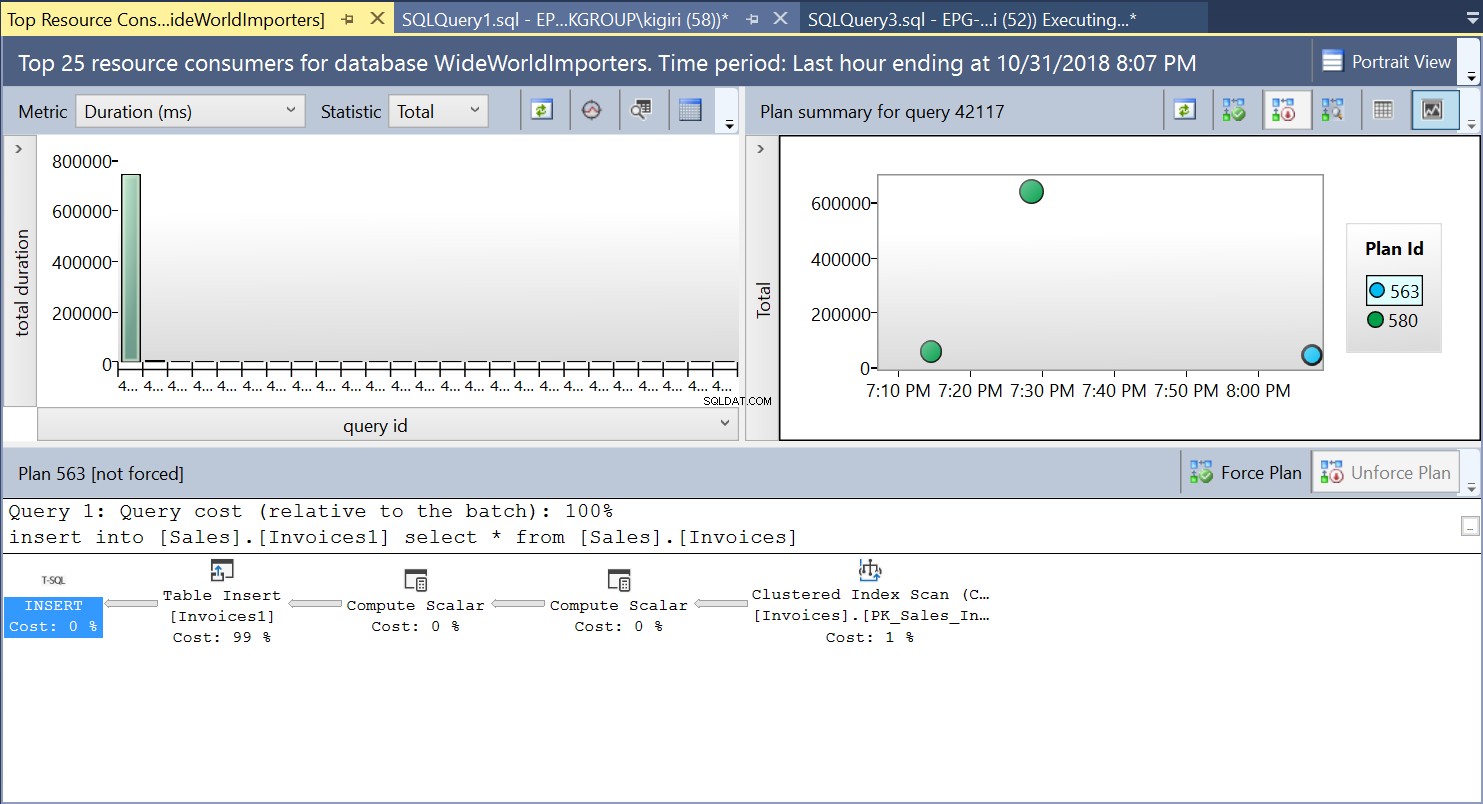
Rys. 1 Plan wykonania 563
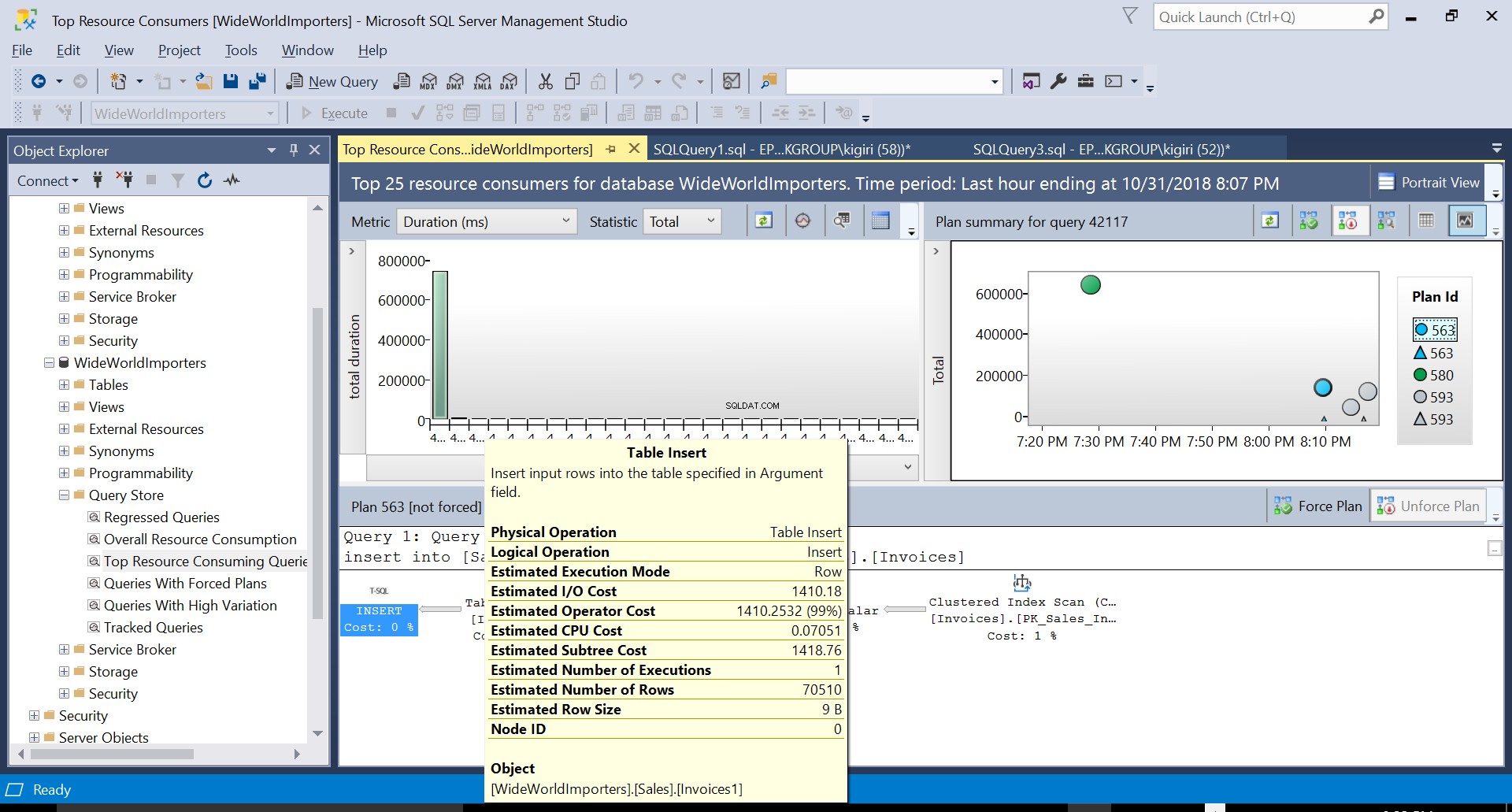
Rys. 2 Wstawianie tabeli w miejscu docelowym
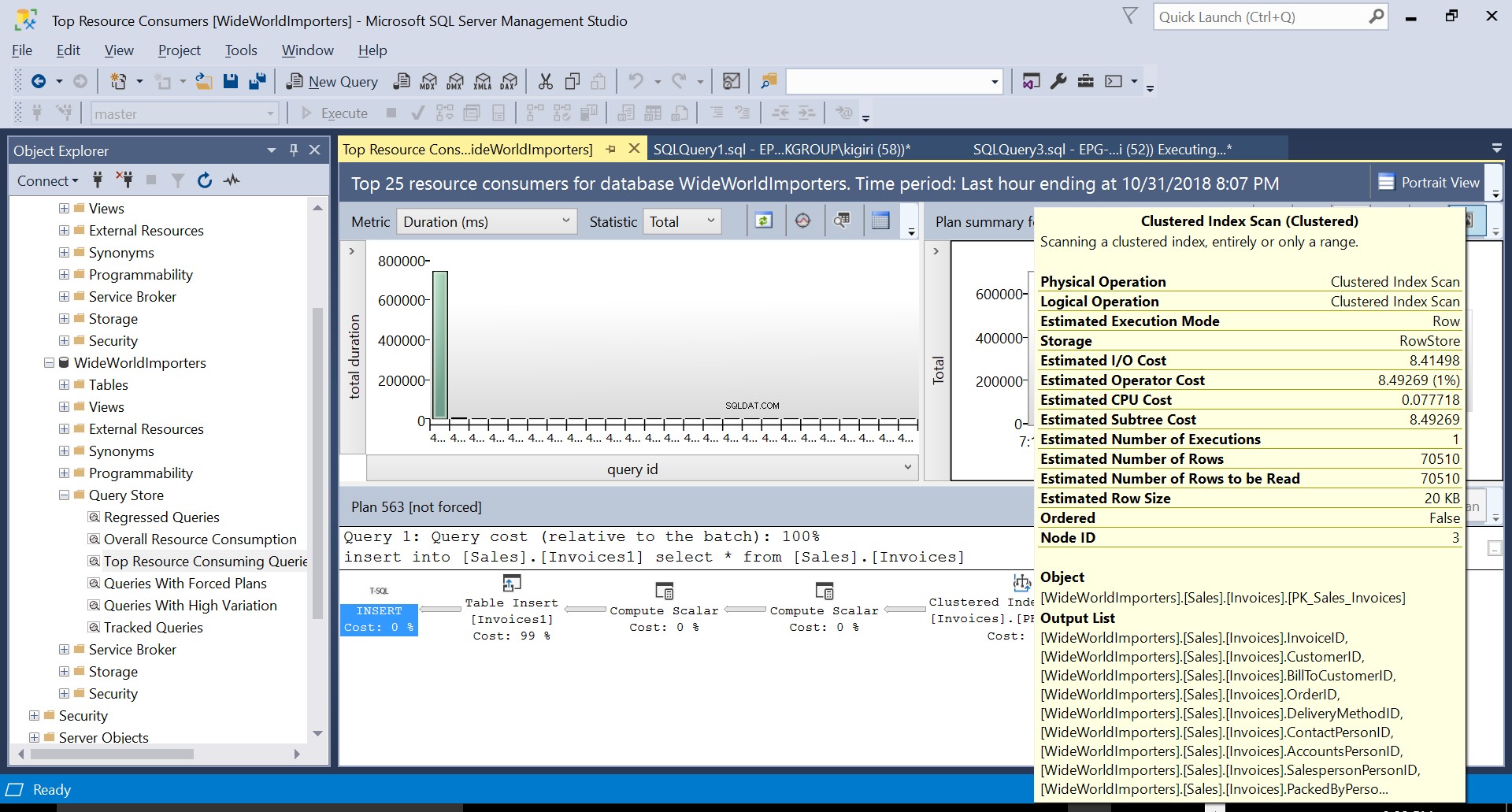
Rys. 3 Skanowanie indeksu klastrowego w tabeli źródłowej
Wstaw z indeksem
Następnie tworzymy indeks w tabeli docelowej za pomocą DDL z Listingu 3. Kiedy powtarzamy instrukcję z Listingu 2 po obcięciu tabeli docelowej, widzimy nieco inny plan wykonania (Plan ID 593 pokazany na Rys. 4). Nadal widzimy wstawkę tabeli, ale przyczynia się ona tylko do 58% do kosztu zapytania. Dynamika wykonania jest nieco wypaczona przez wprowadzenie sortowania i wkładki indeksowej. Zasadniczo dzieje się tak, że SQL Server musi wprowadzać odpowiednie wiersze do indeksu, gdy nowe rekordy są wprowadzane do tabeli.
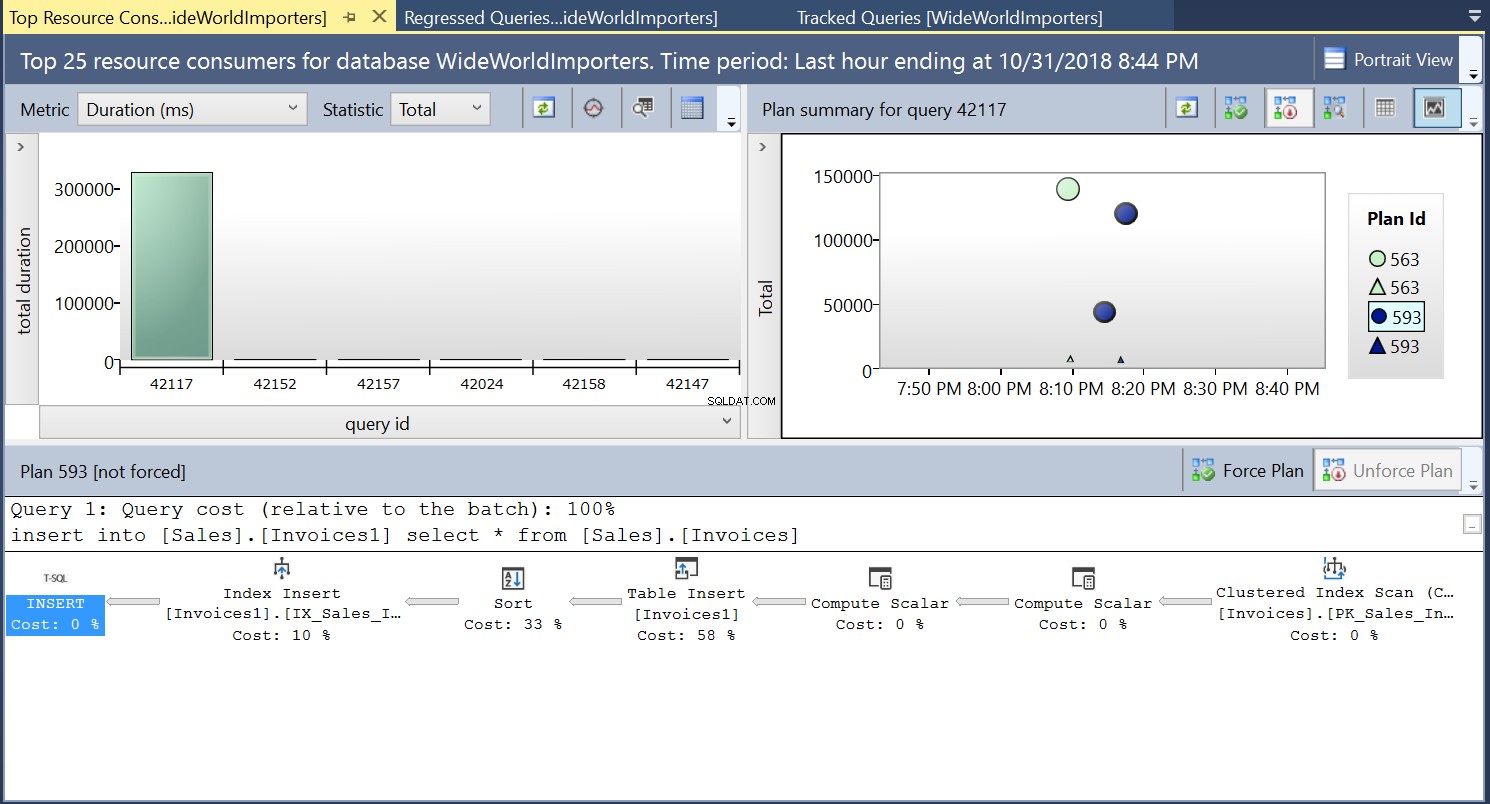
Rys. 4 Plan wykonania 593
Patrząc głębiej
Możemy zbadać szczegóły obu planów i zobaczyć, jak te nowe czynniki eskalują czas wykonania zestawienia. Plan 593 dodaje dodatkowe 300 ms do średniego czasu trwania wyciągu. Przy dużym obciążeniu pracą w środowisku produkcyjnym ta różnica może być znacząca.
Włączenie operacji we/wy STATISTICS podczas wykonywania instrukcji INSERT tylko raz w obu przypadkach — z indeksem w tabeli docelowej i bez indeksu w tabeli docelowej — pokazuje również, że więcej pracy jest wykonywane w zakresie logicznego we/wy podczas wstawiania wierszy w tabeli z indeksami.
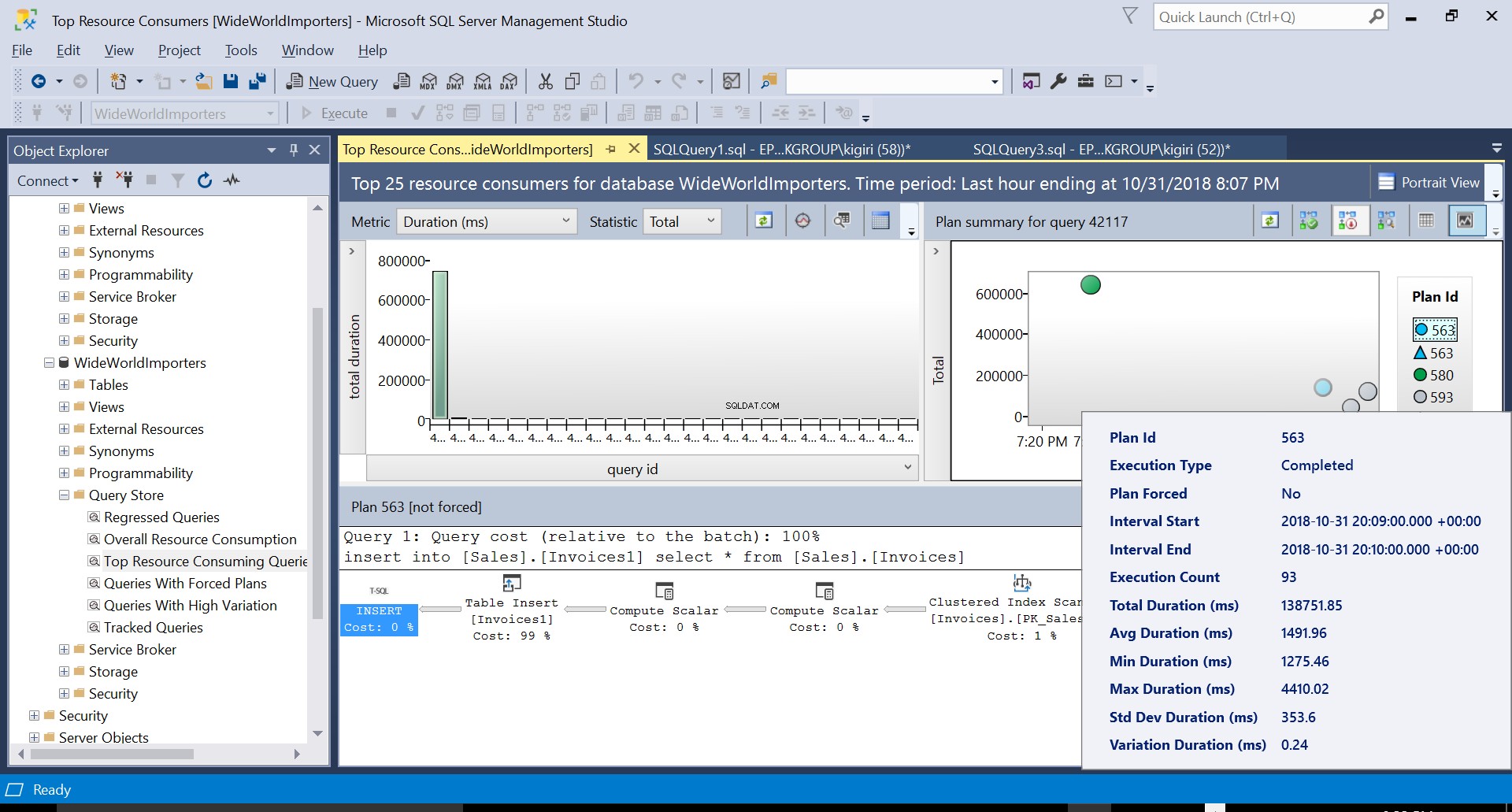
Rys. 5 Szczegóły planu wykonania 563
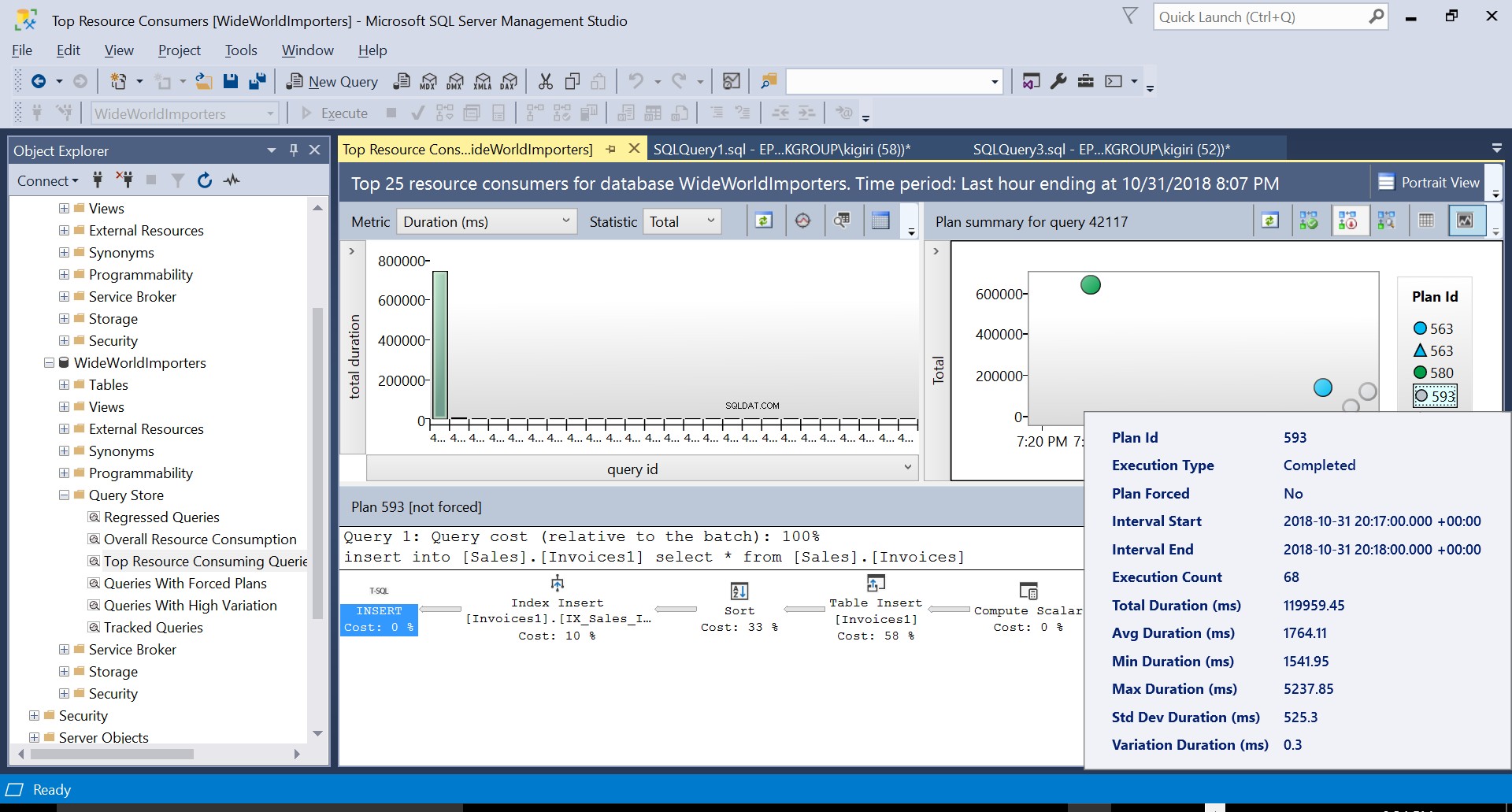
Rys. 4 Szczegóły planu wykonania 593
Brak indeksu:dane wyjściowe z włączoną funkcją STATISTICS IO:
Tabela „Faktury1”. Liczba skanów 0, odczyty logiczne 78372 , odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne LOB 0, odczyty fizyczne LOB 0, odczyty LOB z wyprzedzeniem 0.
Tabela „Faktury”. Liczba skanów 1, odczyty logiczne 11400, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne LOB 0, odczyty fizyczne LOB 0, odczyty z wyprzedzeniem LOB 0.
(70510 wierszy dotyczy)
Indeks:dane wyjściowe z włączoną funkcją STATISTICS IO:
Tabela „Faktury1”. Liczba skanów 0, odczyty logiczne 81119 , odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne LOB 0, odczyty fizyczne LOB 0, odczyty LOB z wyprzedzeniem 0.
Stół „Stół roboczy”. Liczba skanów 0, odczyty logiczne 0, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty z wyprzedzeniem lobu 0.
Tabela „Faktury”. Liczba skanów 1, odczyty logiczne 11400 , odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne LOB 0, odczyty fizyczne LOB 0, odczyty LOB z wyprzedzeniem 0.
(70510 wierszy dotyczy)
Dodatkowe informacje
Microsoft i inne źródła dostarczają skrypty do badania środowiska produkcyjnego indeksów i identyfikowania takich sytuacji, jak:
- Zbędne indeksy – Zduplikowane indeksy
- Brakujące indeksy – Indeksy, które mogą poprawić wydajność w oparciu o obciążenie pracą
- Stoły – Tabele bez indeksów klastrowych
- Nadmiernie indeksowane tabele – Tabele z większą liczbą indeksów niż kolumn
- Użycie indeksu – Liczba wyszukiwań, skanów i wyszukiwań w indeksach
Pozycje 2, 3 i 5 są bardziej związane z wpływem na wydajność w odniesieniu do odczytów, podczas gdy pozycje 1 i 4 dotyczą wpływu na wydajność w odniesieniu do zapisów. Listingi 4 i 5 to dwa przykłady tych publicznie dostępnych zapytań.
-- LISTING 4 Sprawdź nadmiarowe indeksy;WITH INDEXCOLUMNS AS(SELECT DISTINCTSCHEMA_NAME (O.SCHEMA_ID) AS 'SCHEMANAME', OBJECT_NAME(O.OBJECT_ID) AS TABLENAME,I.NAME AS INDEXNAME, O.OBJECT_ID,I.INDEX_ID, I.TYPE, (WYBIERZ CASE KEY_ORDINAL WHEN 0 THEN NULL ELSE '['+COL_NAME(K.OBJECT_ID,COLUMN_ID) +']' END AS [DATA()]FROM SYS.INDEX_COLUMNS AS K WHERE K.OBJECT_ID =I.OBJECT_ID AND K.INDEX_ID =I.INDEX_IDORDER BY KEY_ORDINAL, COLUMN_ID FOR XML PATH('')) JAKO COLSFROM SYS.INDEXES JAK WEWNĘTRZNE ŁĄCZENIE SYS.OBJECTS O ON I.OBJECT_ID =O.OBJECT_ID INNER JOIN SYS.INDEX_COLUMNS IC ON IC. OBJECT_ID =I.OBJECT_ID AND IC.INDEX_ID =I.INDEX_IDINNER JOIN SYS.COLUMNS C ON C.OBJECT_ID =IC.OBJECT_ID AND C.COLUMN_ID =IC.COLUMN_IDGDZIE I.OBJECT_ID IN (WYBIERZ OBJECT_ID Z TYPU SYS.OBJECTS WHERE ') AND I.INDEX_ID <>0 ORAZ I.TYPE <>3 ORAZ I.TYPE <>6GRUP WEDŁUG O.SCHEMA_ID,O.OBJECT_ID,I.OBJECT_ID,I.NAME,I.INDEX_ID,I.TYPE) WYBIERZ IC1 .NAZWASCHEMATU,IC1.NAZWATABELI,IC1.INDEXNAME,IC1.COLS AS INDEXCOLS,IC2.INDEXNAME AS REDUNDANTINDEX NAZWA, IC2.COLS AS REDUNDANTINDEXCOLSFROM INDEXCOLUMNS IC1JOIN INDEXCOLUMNS IC2 ON IC1.OBJECT_ID =IC2.OBJECT_IDAND IC1.INDEX_ID <> IC2.INDEX_IDAND IC1.COLS <> IC2.COLSAND IC2.COLS LIKE REPLACE(IC1.'COLS,'[ [[]') + ' %'ORDER BY 1,2,3,5;-- LISTING 5 Sprawdź indeksy UżycieSELECT O.NAME AS TABLE_NAME, I.NAME AS INDEX_NAME, S.USER_SEEKS, S.USER_SCANS, S.USER_LOOKUPS, S.USER_UPDATESFROM SYS.DM_DB_INDEX_USAGE_STATS SINNER JOIN SYS.INDEXES ION I.INDEX_ID=S.INDEX_IDAND S.OBJECT_ID =I.OBJECT_IDINNER JOIN SYS.OBJECTS OON S.OBJECT_ID =O.OBJECT_IDSYS.; Wniosek
Za pomocą Query Store pokazaliśmy, że dodatkowe obciążenie indeksem może wprowadzić do planu wykonania przykładowej instrukcji insert. W środowisku produkcyjnym nadmierne i nadmiarowe indeksy mogą mieć negatywny wpływ na wydajność, szczególnie w bazach danych przeznaczonych dla obciążeń OLTP. Ważne jest, aby korzystać z dostępnych skryptów i narzędzi do badania indeksów i określania, czy rzeczywiście pomagają, czy szkodzą wydajności.
Przydatne narzędzie:
dbForge Index Manager – poręczny dodatek SSMS do analizy stanu indeksów SQL i rozwiązywania problemów z fragmentacją indeksów.



