To ten wtorek miesiąca – wiesz, ten, w którym odbywa się impreza blokowa blogerów znana jako wtorek T-SQL. W tym miesiącu jego gospodarzem jest Russ Thomas (@SQLJudo), a tematem jest „Calling All Tuners and Gear Heads”. Zajmę się tutaj problemem związanym z wydajnością, ale przepraszam, że może nie być w pełni zgodny z wytycznymi, które Russ przedstawił w swoim zaproszeniu (nie zamierzam używać podpowiedzi, flag śledzenia ani przewodników po planach) .
Na SQLBits w zeszłym tygodniu przedstawiłem prezentację na temat wyzwalaczy, w której uczestniczył mój dobry przyjaciel i kolega MVP Erland Sommarskog. W pewnym momencie zasugerowałem, że przed utworzeniem nowego wyzwalacza w tabeli należy sprawdzić, czy jakieś wyzwalacze już istnieją, i rozważyć połączenie logiki zamiast dodawania dodatkowego wyzwalacza. Moje powody dotyczyły przede wszystkim łatwości konserwacji kodu, ale także wydajności. Erland zapytał, czy kiedykolwiek testowałem, czy jest jakieś dodatkowe obciążenie związane z uruchamianiem wielu wyzwalaczy dla tego samego działania, i musiałem przyznać, że nie, nie zrobiłem nic rozległego. Więc zrobię to teraz.
W AdventureWorks2014 stworzyłem prosty zestaw tabel, które zasadniczo reprezentują sys.all_objects (~2700 wierszy) i sys.all_columns (~9500 rzędów). Chciałem zmierzyć wpływ na obciążenie pracą różnych podejść do aktualizacji obu tabel — zasadniczo użytkownicy aktualizują tabelę kolumn i używasz wyzwalacza do aktualizacji innej kolumny w tej samej tabeli i kilku kolumn w tabeli obiektów.
- T1:linia bazowa :Załóżmy, że możesz kontrolować dostęp do wszystkich danych za pomocą procedury składowanej; w takim przypadku aktualizacje obu tabel można wykonać bezpośrednio, bez konieczności uruchamiania wyzwalaczy. (Nie jest to praktyczne w prawdziwym świecie, ponieważ nie można niezawodnie zabronić bezpośredniego dostępu do tabel).
- T2:Pojedynczy wyzwalacz w stosunku do innej tabeli :Załóżmy, że można sterować instrukcją aktualizacji w odniesieniu do tabeli, której dotyczy problem, i dodać inne kolumny, ale aktualizacje tabeli dodatkowej muszą zostać zaimplementowane za pomocą wyzwalacza. Zaktualizujemy wszystkie trzy kolumny jednym oświadczeniem.
- T3:Pojedynczy wyzwalacz dla obu tabel :W tym przypadku mamy wyzwalacz z dwoma instrukcjami, z których jedna aktualizuje drugą kolumnę w tabeli, której dotyczy problem, a druga aktualizuje wszystkie trzy kolumny w tabeli dodatkowej.
- T4:Pojedynczy wyzwalacz dla obu tabel :Podobnie jak T3, ale tym razem mamy wyzwalacz z czterema instrukcjami, z których jedna aktualizuje drugą kolumnę w tabeli, której dotyczy problem, i aktualizacją instrukcji dla każdej kolumny w tabeli pomocniczej. Może to być sposób obsługi, jeśli wymagania są dodawane z czasem, a oddzielne stwierdzenie jest uważane za bezpieczniejsze pod względem testowania regresji.
- T5:Dwa wyzwalacze :Jeden wyzwalacz aktualizuje tylko tabelę, której dotyczy problem; druga używa pojedynczej instrukcji do aktualizacji trzech kolumn w tabeli dodatkowej. Może to być sposób, w jaki to się robi, jeśli inne wyzwalacze nie zostaną zauważone lub jeśli ich modyfikowanie jest zabronione.
- T6:Cztery wyzwalacze :Jeden wyzwalacz aktualizuje tylko tabelę, której dotyczy problem; pozostałe trzy aktualizują każdą kolumnę w tabeli dodatkowej. Ponownie, może to być sposób, w jaki to się robi, jeśli nie wiesz, że istnieją inne wyzwalacze lub jeśli boisz się dotknąć innych wyzwalaczy z powodu obaw związanych z regresją.
Oto dane źródłowe, z którymi mamy do czynienia:
-- sys.all_objects: SELECT * INTO dbo.src FROM sys.all_objects; CREATE UNIQUE CLUSTERED INDEX x ON dbo.src([object_id]); GO -- sys.all_columns: SELECT * INTO dbo.tr1 FROM sys.all_columns; CREATE UNIQUE CLUSTERED INDEX x ON dbo.tr1([object_id], column_id); -- repeat 5 times: tr2, tr3, tr4, tr5, tr6
Teraz dla każdego z 6 testów uruchomimy nasze aktualizacje 1000 razy i zmierzymy czas
T1:Linia bazowa
To jest scenariusz, w którym mamy szczęście uniknąć wyzwalaczy (znowu niezbyt realistyczny). W takim przypadku będziemy mierzyć odczyty i czas trwania tej partii. Wstawiłem /*real*/ do tekstu zapytania, abym mógł łatwo pobrać statystyki tylko dla tych instrukcji, a nie dla jakichkolwiek instrukcji z wyzwalaczy, ponieważ ostatecznie metryki są gromadzone do instrukcji, które wywołują wyzwalacze. Zwróć też uwagę, że faktyczne aktualizacje, które wprowadzam, nie mają żadnego sensu, więc zignoruj to ustawiam sortowanie na nazwę serwera/instancji i principal_id obiektu do session_id bieżącej sesji .
UPDATE /*real*/ dbo.tr1 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; UPDATE /*real*/ s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID FROM dbo.src AS s INNER JOIN dbo.tr1 AS t ON s.[object_id] = t.[object_id] WHERE t.name LIKE '%s%'; GO 1000
T2:Pojedynczy wyzwalacz
W tym celu potrzebujemy następującego prostego wyzwalacza, który aktualizuje tylko dbo.src :
CREATE TRIGGER dbo.tr_tr2
ON dbo.tr2
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = SUSER_ID()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Następnie nasza partia musi tylko zaktualizować dwie kolumny w tabeli podstawowej:
UPDATE /*real*/ dbo.tr2 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; GO 1000
T3:Pojedynczy wyzwalacz dla obu tabel
W tym teście nasz wyzwalacz wygląda tak:
CREATE TRIGGER dbo.tr_tr3
ON dbo.tr3
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr3 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO A teraz testowana partia musi jedynie zaktualizować oryginalną kolumnę w tabeli podstawowej; drugi jest obsługiwany przez wyzwalacz:
UPDATE /*real*/ dbo.tr3 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T4:Pojedynczy wyzwalacz dla obu tabel
To jest jak T3, ale teraz wyzwalacz ma cztery instrukcje:
CREATE TRIGGER dbo.tr_tr4
ON dbo.tr4
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr4 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Partia testowa pozostaje niezmieniona:
UPDATE /*real*/ dbo.tr4 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T5:Dwa wyzwalacze
Tutaj mamy jeden wyzwalacz do aktualizacji tabeli podstawowej i jeden wyzwalacz do aktualizacji tabeli dodatkowej:
CREATE TRIGGER dbo.tr_tr5_1
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr5 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr5_2
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Partia testowa jest znowu bardzo prosta:
UPDATE /*real*/ dbo.tr5 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T6:Cztery wyzwalacze
Tym razem mamy wyzwalacz dla każdej kolumny, której to dotyczy; jeden w tabeli podstawowej i trzy w tabelach dodatkowych.
CREATE TRIGGER dbo.tr_tr6_1
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr6 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_2
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_3
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_4
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO A partia testowa:
UPDATE /*real*/ dbo.tr6 SET name += N'' WHERE name LIKE '%s%'; GO 1000
Pomiar wpływu obciążenia pracą
Na koniec napisałem proste zapytanie do sys.dm_exec_query_stats aby zmierzyć odczyty i czas trwania każdego testu:
SELECT [cmd] = SUBSTRING(t.text, CHARINDEX(N'U', t.text), 23), avg_elapsed_time = total_elapsed_time / execution_count * 1.0, total_logical_reads FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.text LIKE N'%UPDATE /*real*/%' ORDER BY cmd;
Wyniki
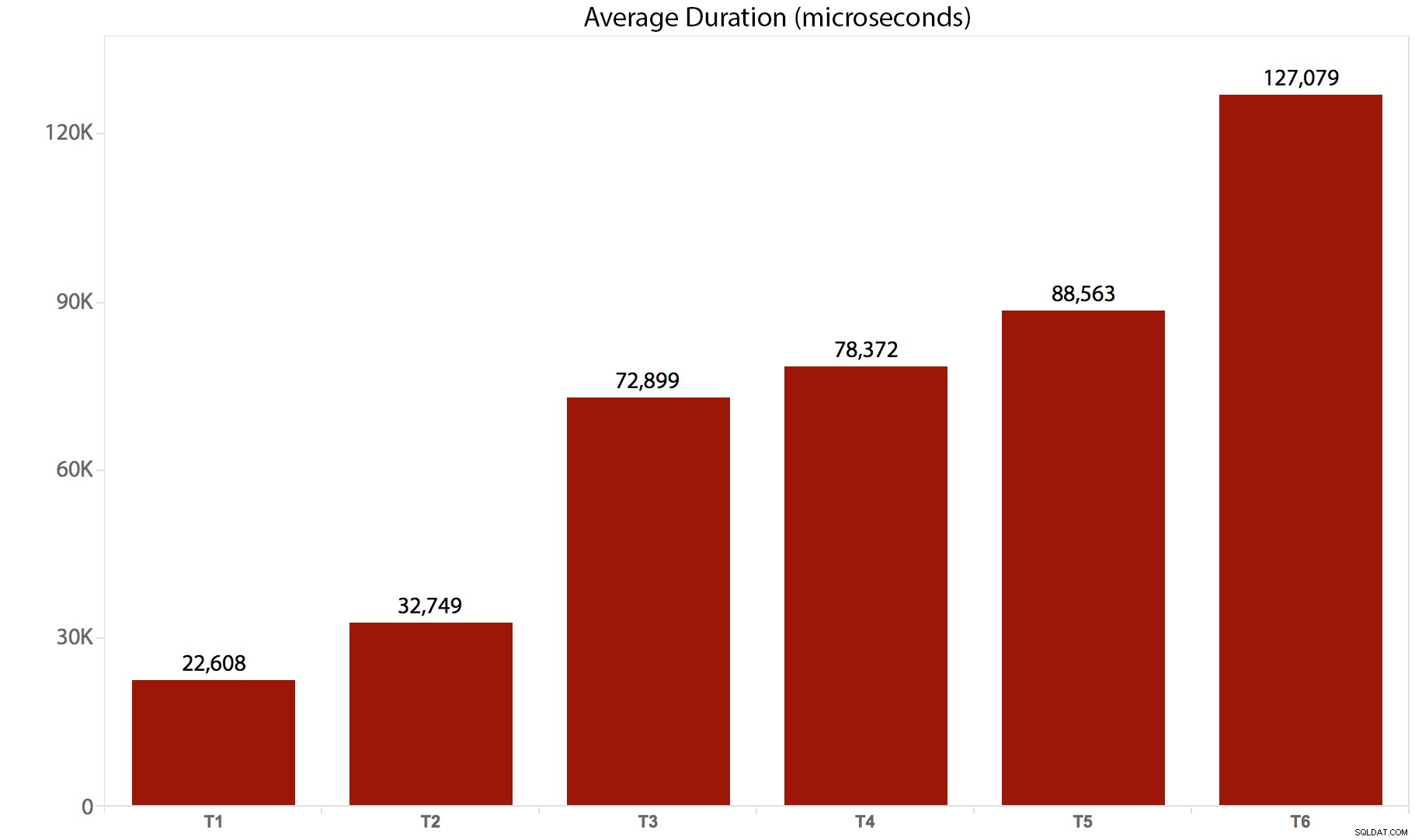
Przeprowadziłem testy 10 razy, zebrałem wyniki i wszystko uśredniłem. Oto jak to się zepsuło:
| Test/partia | Średni czas trwania (mikrosekundy) | Łączna liczba odczytów (8 tys. stron) |
|---|---|---|
| T1 :UPDATE /*prawdziwe*/ dbo.tr1 … | 22 608 | 205 134 |
| T2 :UPDATE /*prawdziwe*/ dbo.tr2 … | 32 749 | 11 331 628 |
| T3 :UPDATE /*prawdziwe*/ dbo.tr3 … | 72 899 | 22 838 308 |
| T4 :UPDATE /*prawdziwe*/ dbo.tr4 … | 78 372 | 44 463 275 |
| T5 :UPDATE /*prawdziwe*/ dbo.tr5 … | 88 563 | 41 514 778 |
| T6 :UPDATE /*prawdziwe*/ dbo.tr6 … | 127.079 | 100 330 753 |
Oto graficzna reprezentacja czasu trwania:
Wniosek
Jasne jest, że w tym przypadku każdy wyzwalacz, który jest wywoływany, wiąże się ze znacznym obciążeniem — wszystkie te partie ostatecznie wpłynęły na tę samą liczbę wierszy, ale w niektórych przypadkach te same wiersze zostały dotknięte wiele razy. Prawdopodobnie przeprowadzę dalsze testy, aby zmierzyć różnicę, gdy ten sam wiersz nigdy nie jest dotykany więcej niż raz – być może bardziej skomplikowany schemat, w którym za każdym razem trzeba dotykać 5 lub 10 innych tabel, a te różne stwierdzenia mogą być w jednym spuście lub w wielu. Domyślam się, że ogólne różnice będą napędzane bardziej przez takie rzeczy jak współbieżność i liczba wierszy, na które ma wpływ, niż przez sam wyzwalacz – ale zobaczymy.
Chcesz sam wypróbować demo? Pobierz skrypt tutaj.