Czy lubisz analizować ciągi? Jeśli tak, jedną z niezbędnych funkcji łańcuchowych do użycia jest SQL SUBSTRING. Jest to jedna z tych umiejętności, które programista powinien posiadać w każdym języku.
Więc jak to robisz?
Ważne punkty w analizie ciągów
Załóżmy, że dopiero zaczynasz analizować. O jakich ważnych punktach musisz pamiętać?
- Wiedz, jakie informacje są osadzone w ciągu.
- Uzyskaj dokładne pozycje każdej informacji w ciągu. Być może będziesz musiał policzyć wszystkie znaki w ciągu.
- Poznaj rozmiar lub długość każdego fragmentu informacji w ciągu.
- Użyj odpowiedniej funkcji ciągu, która może łatwo wyodrębnić każdą informację z ciągu.
Znajomość wszystkich tych czynników przygotuje Cię do używania SQL SUBSTRING() i przekazywania do niego argumentów.
Składnia SQL SUBSTRING

Składnia SQL SUBSTRING jest następująca:
SUBSTRING(wyrażenie ciągu, początek, długość)
- wyrażenie tekstowe – a literał ciągu lub wyrażenie SQL, które zwraca ciąg.
- rozpocznij – liczba, od której rozpocznie się ekstrakcja. Jest również oparty na 1 – pierwszy znak w argumencie wyrażenia łańcuchowego musi zaczynać się od 1, a nie od 0. W SQL Server zawsze jest to liczba dodatnia. Jednak w MySQL lub Oracle może być dodatnia lub ujemna. Jeśli jest ujemny, skanowanie rozpoczyna się od końca ciągu.
- długość – długość znaków do wyodrębnienia. SQL Server tego wymaga. W MySQL lub Oracle jest to opcjonalne.
4 przykłady SQL SUBSTRING
1. Używanie SQL SUBSTRING do wyodrębniania z literału ciągu
Zacznijmy od prostego przykładu z dosłownym ciągiem. Używamy nazwy słynnej koreańskiej grupy dziewcząt, BlackPink, a Rysunek 1 ilustruje, jak będzie działać SUBSTRING:

Poniższy kod pokazuje, jak go wyodrębnimy:
-- extract 'black' from BlackPink (English)
SELECT SUBSTRING('BlackPink',1,5) AS result
Teraz przyjrzyjmy się również zestawowi wyników na rysunku 2:
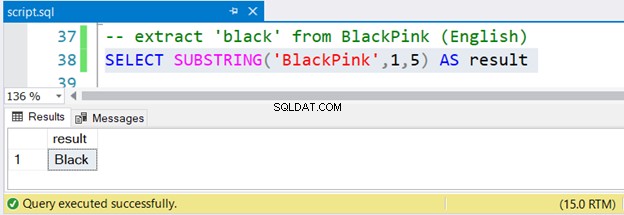
Czy to nie łatwe?
Aby wyodrębnić Czarny od Czarnoróżowy , zaczynasz od pozycji 1, a kończysz na pozycji 5. Od BlackPink jest koreański, dowiedzmy się, czy SUBSTRING działa na koreańskich znakach Unicode.
(ZASTRZEŻENIE :Nie umiem mówić, czytać ani pisać po koreańsku, więc dostałem koreańskie tłumaczenie z Wikipedii. Użyłem także Tłumacza Google, aby zobaczyć, które znaki odpowiadają Czarnemu i różowy . Proszę wybacz mi, jeśli to źle. Mam jednak nadzieję, że nadejdzie kwestia, którą staram się wyjaśnić w poprzek)
Zróbmy napis w języku koreańskim (patrz rysunek 3). Użyte znaki koreańskie przekładają się na BlackPink:

Teraz zobacz poniższy kod. Wyodrębnimy dwa znaki odpowiadające Czarnemu .
-- extract 'black' from BlackPink (Korean)
SELECT SUBSTRING(N'블랙핑크',1,2) AS result
Czy zauważyłeś koreański ciąg poprzedzony przez N ? Używa znaków Unicode, a SQL Server przyjmuje NVARCHAR i powinien być poprzedzony przez N . To jedyna różnica w wersji angielskiej. Ale czy będzie działać dobrze? Zobacz rysunek 4:
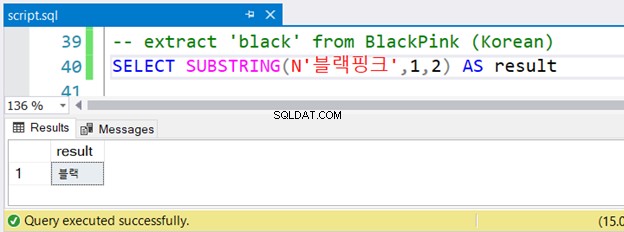
Działał bez błędów.
2. Używanie SQL SUBSTRING w MySQL z ujemnym argumentem startowym
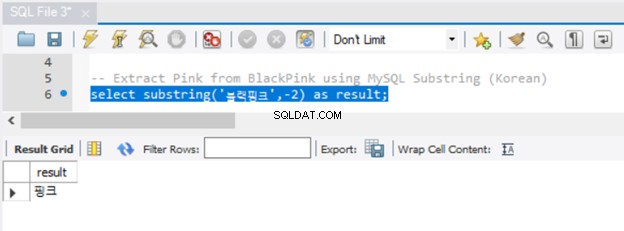
Posiadanie ujemnego argumentu start nie zadziała w SQL Server. Ale możemy mieć tego przykład przy użyciu MySQL. Tym razem wyodrębnijmy różowy od Czarnoróżowy . Oto kod:
-- Extract 'Pink' from BlackPink using MySQL Substring (English)
select substring('BlackPink',-4,4) as result;
Teraz przyjrzyjmy się wynikowi na rysunku 5:
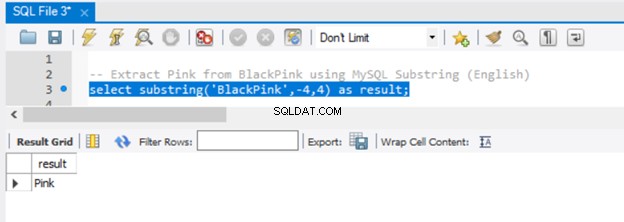
Ponieważ przekazaliśmy -4 do parametru start, wyodrębnianie rozpoczęło się od końca łańcucha, cofając się o 4 znaki. Aby osiągnąć ten sam wynik w SQL Server, użyj funkcji RIGHT().
Znaki Unicode działają również z MySQL SUBSTRING, jak widać na rysunku 6:
Działało dobrze. Ale czy zauważyłeś, że nie musimy poprzedzać ciągu N? Zauważ też, że istnieje kilka sposobów na uzyskanie podciągu w MySQL. Widziałeś już SUBSTRING. Równoważnymi funkcjami w MySQL są SUBSTR() i MID().
3. Parsowanie podciągów za pomocą argumentów o zmiennym początku i długości
Niestety nie wszystkie wyciągi ciągów używają stałych argumentów początku i długości. W takim przypadku potrzebujesz CHARINDEX, aby uzyskać pozycję ciągu, na który kierujesz. Spójrzmy na przykład:
DECLARE @lineString NVARCHAR(30) = N'김제니 01/16/example@sqldat.com'
DECLARE @name NVARCHAR(5)
DECLARE @bday DATE
DECLARE @instagram VARCHAR(20)
SET @name = SUBSTRING(@lineString,1,CHARINDEX('@',@lineString)-11)
SET @bday = SUBSTRING(@lineString,CHARINDEX('@',@lineString)-10,10)
SET @instagram = SUBSTRING(@lineString,CHARINDEX('@',@lineString),30)
SELECT @name AS [Name], @bday AS [BirthDate], @instagram AS [InstagramAccount]
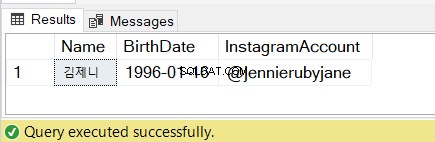
W powyższym kodzie musisz wyodrębnić imię i nazwisko w języku koreańskim, datę urodzenia i konto na Instagramie.
Zaczynamy od zdefiniowania trzech zmiennych do przechowywania tych informacji. Następnie możemy przeanalizować ciąg i przypisać wyniki do każdej zmiennej.
Możesz pomyśleć, że posiadanie ustalonych startów i długości jest prostsze. Poza tym możemy to namierzyć, przeliczając znaki ręcznie. Ale co, jeśli masz ich dużo na stole?
Oto nasza analiza:
- Jedynym stałym elementem w ciągu jest @ postaci na koncie na Instagramie. Możemy określić jego pozycję w łańcuchu za pomocą CHARINDEX. Następnie używamy tej pozycji, aby uzyskać początek i długość reszty.
- Data urodzenia jest w ustalonym formacie MM/dd/rrrr z 10 znakami.
- Aby wyodrębnić imię, zaczynamy od 1. Ponieważ data urodzenia ma 10 znaków plus @ znak, możesz dostać się do końcowego znaku nazwy w ciągu. Z pozycji @ postać, cofamy się o 11 znaków. SUBSTRING(@lineString,1,CHARINDEX(‘@’,@lineString)-11) to droga do zrobienia.
- Aby uzyskać datę urodzin, stosujemy tę samą logikę. Uzyskaj pozycję @ znak i przesuń 10 znaków wstecz, aby uzyskać wartość początkową daty urodzenia. 10 to stała długość. SUBSTRING(@lineString,CHARINDEX(‘@’,@lineString)-10,10) jak uzyskać datę urodzin.
- Wreszcie uzyskanie konta na Instagramie jest proste. Zacznij od pozycji @ znak za pomocą CHARINDEX. Uwaga:30 to limit nazw użytkowników na Instagramie.
Sprawdź wyniki na rysunku 7:
4. Używanie SQL SUBSTRING w instrukcji SELECT
Możesz również użyć SUBSTRING w instrukcji SELECT, ale najpierw musimy mieć dane robocze. Oto kod:
SELECT
CAST(P.LastName AS CHAR(50))
+ CAST(P.FirstName AS CHAR(50))
+ CAST(ISNULL(P.MiddleName,'') AS CHAR(50))
+ CAST(ea.EmailAddress AS CHAR(50))
+ CAST(a.City AS CHAR(30))
+ CAST(a.PostalCode AS CHAR(15)) AS line
INTO PersonContacts
FROM Person.Person p
INNER JOIN Person.EmailAddress ea
ON P.BusinessEntityID = ea.BusinessEntityID
INNER JOIN Person.BusinessEntityAddress bea
ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Person.Address a
ON bea.AddressID = a.AddressID
Powyższy kod tworzy długi ciąg zawierający imię i nazwisko, adres e-mail, miasto i kod pocztowy. Chcemy go również przechowywać w PersonelContacts tabela.
Teraz zajmijmy się kodem do inżynierii wstecznej za pomocą SUBSTRING:
SELECT
TRIM(SUBSTRING(line,1,50)) AS [LastName]
,TRIM(SUBSTRING(line,51,50)) AS [FirstName]
,TRIM(SUBSTRING(line,101,50)) AS [MiddleName]
,TRIM(SUBSTRING(line,151,50)) AS [EmailAddress]
,TRIM(SUBSTRING(line,201,30)) AS [City]
,TRIM(SUBSTRING(line,231,15)) AS [PostalCode]
FROM PersonContacts pc
ORDER BY LastName, FirstName
Ponieważ użyliśmy kolumn o stałym rozmiarze, nie ma potrzeby używania CHARINDEX.
Używanie SQL SUBSTRING w klauzuli WHERE – pułapka wydajności?
To prawda. Nikt nie może powstrzymać Cię przed użyciem SUBSTRING w klauzuli WHERE. Jest to poprawna składnia. Ale co, jeśli spowoduje to problemy z wydajnością?
Dlatego udowadniamy to na przykładzie, a następnie omawiamy, jak rozwiązać ten problem. Ale najpierw przygotujmy nasze dane:
USE AdventureWorks
GO
SELECT * INTO SalesOrders FROM Sales.SalesOrderHeader soh
Nie mogę zepsuć SalesOrderHeader stół, więc zrzuciłem go na inny stół. Następnie utworzyłem SalesOrderID w nowych Zamówieniach sprzedaży podaj klucz podstawowy.
Teraz jesteśmy gotowi na zapytanie. Używam dbForge Studio dla SQL Server z trybem profilowania zapytań WŁĄCZONYM do analizy zapytań.
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE SUBSTRING(so.AccountNumber,4,4) = '4030'
Jak widać, powyższe zapytanie działa poprawnie. Teraz spójrz na diagram profilu zapytania na rysunku 8:
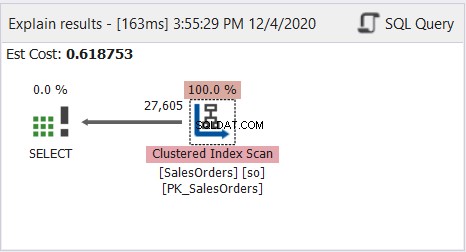
Diagram planu wygląda na prosty, ale przyjrzyjmy się właściwościom węzła Clustered Index Scan. W szczególności potrzebujemy informacji o czasie wykonywania:
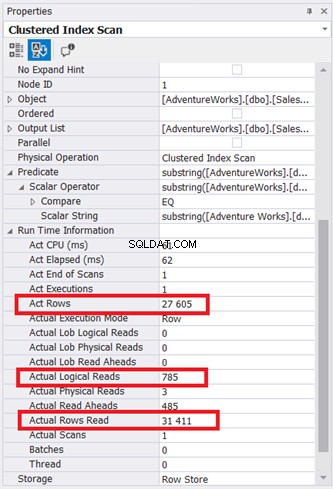
Ilustracja 9 przedstawia strony 785 * 8 KB odczytane przez silnik bazy danych. Zauważ również, że rzeczywisty odczyt wierszy to 31 411. Jest to łączna liczba wierszy w tabeli. Jednak zapytanie zwróciło tylko 27 605 rzeczywistych wierszy.
Cała tabela została odczytana przy użyciu indeksu klastrowego jako odniesienia.
Dlaczego?
Chodzi o to, że serwer SQL musi wiedzieć, czy 4030 jest podciągiem numeru Konta. Musi czytać i oceniać każdy zapis. Odrzuć wiersze, które nie są równe i zwróć potrzebne wiersze. Wykonuje zadanie, ale nie wystarczająco szybko.
Co możemy zrobić, aby działał szybciej?
Unikaj SUBSTRING w klauzuli WHERE i uzyskaj ten sam wynik szybciej
Teraz chcemy uzyskać ten sam wynik bez użycia SUBSTRING w klauzuli WHERE. Wykonaj poniższe czynności:
- Zmień tabelę, dodając kolumnę obliczaną z SUBSTRING(numer konta, 4,4) formuła. Nazwijmy go AccountCategory z braku lepszego terminu.
- Utwórz indeks nieklastrowy dla nowej AccountCategory kolumna. Uwzględnij datę zamówienia , Numer Konta i ID klienta kolumny.
To wszystko.
Zmieniamy klauzulę WHERE zapytania, aby dostosować nową AccountCategory kolumna:
SET STATISTICS IO ON
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE so.AccountCategory = '4030'
SET STATISTICS IO OFF
W klauzuli WHERE nie ma SUBSTRING. Sprawdźmy teraz diagram planu:
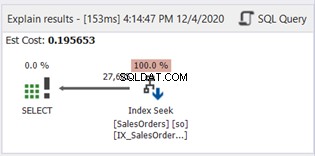
Skanowanie indeksu zostało zastąpione przez wyszukiwanie indeksu. Zauważ również, że SQL Server użył nowego indeksu w wyliczonej kolumnie. Czy nastąpiły również zmiany w odczytach logicznych i rzeczywistych odczytanych wierszach? Zobacz rysunek 11:
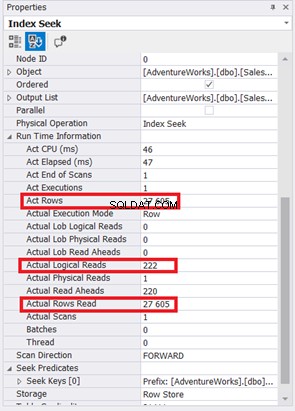
Zmniejszenie z 785 do 222 odczytów logicznych to wielka poprawa, ponad trzy razy mniej niż oryginalne odczyty logiczne. Zminimalizowało również rzeczywisty odczyt wierszy tylko do tych wierszy, których potrzebujemy.
Dlatego użycie SUBSTRING w klauzuli WHERE nie jest dobre dla wydajności i dotyczy każdej innej funkcji o wartościach skalarnych używanej w klauzuli WHERE.
Wniosek
- Programiści nie mogą uniknąć analizowania ciągów. Taka potrzeba pojawi się w taki czy inny sposób.
- Podczas analizowania ciągów niezbędne jest poznanie informacji w ciągu, pozycji każdej części informacji oraz ich rozmiarów lub długości.
- Jedną z funkcji analizujących jest SQL SUBSTRING. Potrzebuje tylko ciągu do przeanalizowania, pozycji do rozpoczęcia ekstrakcji i długości ciągu do wyodrębnienia.
- SUBSTRING może mieć różne zachowania między smakami SQL, takimi jak SQL Server, MySQL i Oracle.
- Możesz użyć SUBSTRING z literałowymi ciągami i ciągami w kolumnach tabeli.
- Użyliśmy również SUBSTRING ze znakami Unicode.
- Użycie SUBSTRING lub dowolnej funkcji o wartościach skalarnych w klauzuli WHERE może zmniejszyć wydajność zapytania. Napraw to za pomocą indeksowanej kolumny obliczeniowej.
Jeśli uznasz ten post za pomocny, udostępnij go na preferowanych platformach społecznościowych lub udostępnij swój komentarz poniżej?