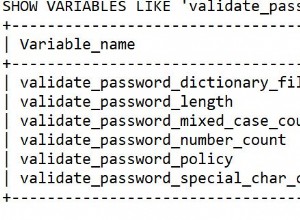
Indeksy przyspieszają działanie baz danych SQL. Mogą być klastrowane lub nieklastrowane. Ale co to oznacza i gdzie należy je zastosować?
Znam to uczucie. Byłam tam. Osoby początkujące często nie wiedzą, który indeks użyć w jakich kolumnach. Jednak nawet eksperci muszą przemyśleć tę kwestię przed podjęciem decyzji, a różne sytuacje wymagają różnych decyzji. Jak zobaczysz później, istnieją zapytania, w których indeks klastrowy będzie świecił w porównaniu z indeksem nieklastrowym i na odwrót.
Jednak najpierw musimy poznać każdego z nich. Jeśli szukasz tych samych informacji, dzisiaj jest Twój szczęśliwy dzień.
W tym artykule dowiesz się, jakie są te indeksy i kiedy ich używać. Oczywiście będą dostępne próbki kodu, które możesz wypróbować w praktyce. Więc weź frytki lub pizzę i trochę napojów gazowanych lub kawy i przygotuj się na zanurzenie się w tej wnikliwej podróży.
Gotowy?
Co to jest indeks klastrowy
Indeks klastrowy to indeks, który definiuje fizyczną kolejność sortowania wierszy w tabeli lub widoku.
Aby zobaczyć to w rzeczywistej formie, weźmy Pracownika tabela w AdventureWorks2017 baza danych.
Klucz podstawowy jest również indeksem klastrowym, a klucz jest oparty na BusinessEntityID kolumna. Kiedy wykonasz SELECT w tej tabeli bez ORDER BY, zobaczysz, że jest ona posortowana według klucza podstawowego.
Wypróbuj sam, korzystając z poniższego kodu:
USE AdventureWorks2017
GO
SELECT TOP 10 * FROM HumanResources.Employee
GO
Teraz zobacz wynik na rysunku 1:
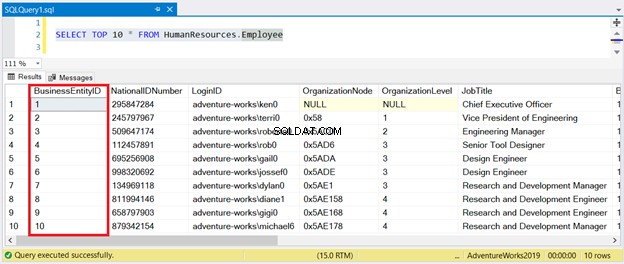
Jak widać, nie musisz sortować zestawu wyników za pomocą BusinessEntityID . Dba o to indeks klastrowy.
W przeciwieństwie do indeksów nieklastrowych, na jedną tabelę może przypadać tylko 1 indeks klastrowy. Co jeśli spróbujemy tego u Pracownika stół?
CREATE CLUSTERED INDEX IX_Employee_NationalID
ON HumanResources.Employee (NationalIDNumber)
GO
Poniżej mamy podobny błąd:
Msg 1902, Level 16, State 3, Line 4
Cannot create more than one clustered index on table 'HumanResources.Employee'. Drop the existing clustered index 'PK_Employee_BusinessEntityID' before creating another.
Kiedy używać indeksu klastrowego?
Kolumna jest najlepszym kandydatem do indeksu klastrowego, jeśli spełniony jest jeden z następujących warunków:
- Jest używany w dużej liczbie zapytań w klauzuli WHERE i łączy.
- Będzie używany jako klucz obcy do innej tabeli, a ostatecznie do przyłączeń.
- Unikalne wartości kolumn.
- Wartość będzie mniej prawdopodobna.
- Ta kolumna służy do zapytania o zakres wartości. Operatory takie jak>, <,>=, <=lub BETWEEN są używane z kolumną w klauzuli WHERE.
Ale indeksy klastrowe nie są dobre, jeśli kolumna lub kolumny
- częste zmiany
- są szerokie klawisze lub kombinację kolumn z dużymi klawiszami.
Przykłady
Indeksy klastrowe można tworzyć za pomocą kodu T-SQL lub dowolnego narzędzia GUI programu SQL Server. Możesz to zrobić w T-SQL podczas tworzenia tabeli, tak:
CREATE TABLE [Person].[Person](
[BusinessEntityID] [int] NOT NULL,
[PersonType] [nchar](2) NOT NULL,
[NameStyle] [dbo].[NameStyle] NOT NULL,
[Title] [nvarchar](8) NULL,
[FirstName] [dbo].[Name] NOT NULL,
[MiddleName] [dbo].[Name] NULL,
[LastName] [dbo].[Name] NOT NULL,
[Suffix] [nvarchar](10) NULL,
[EmailPromotion] [int] NOT NULL,
[AdditionalContactInfo] [xml](CONTENT [Person].[AdditionalContactInfoSchemaCollection]) NULL,
[Demographics] [xml](CONTENT [Person].[IndividualSurveySchemaCollection]) NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED
(
[BusinessEntityID] ASC
)
GO
Możesz to zrobić za pomocą ALTER TABLE po tworzenie tabeli bez indeksu klastrowego:
ALTER TABLE Person.Person ADD CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED (BusinessEntityID)
GO
Innym sposobem jest użycie CREATE CLASTERED INDEX:
CREATE CLUSTERED INDEX [PK_Person_BusinessEntityID] ON Person.Person (BusinessEntityID)
GO
Jeszcze jedną alternatywą jest użycie narzędzia SQL Server, takiego jak SQL Server Management Studio lub dbForge Studio dla SQL Server.
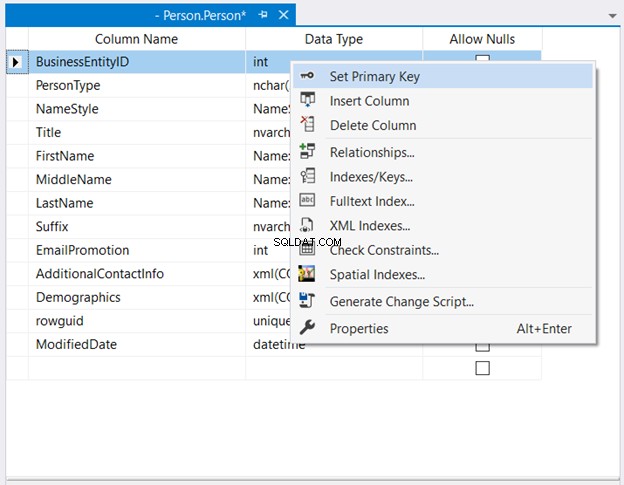
W Eksploratorze obiektów , rozwiń bazę danych i węzły tabeli. Następnie kliknij prawym przyciskiem myszy wybraną tabelę i wybierz Projekt . Na koniec kliknij prawym przyciskiem myszy kolumnę, która ma być kluczem podstawowym> Ustaw klucz główny > Zapisz zmiany w tabeli.
Rysunek 2 poniżej pokazuje, gdzie BusinessEntityID jest ustawiony jako klucz podstawowy.
Oprócz tworzenia jednokolumnowego indeksu klastrowego możesz użyć wielu kolumn. Zobacz przykład w T-SQL:
CREATE CLUSTERED INDEX [IX_Person_LastName_FirstName_MiddleName] ON [Person].[Person]
(
[LastName] ASC,
[FirstName] ASC,
[MiddleName] ASC
)
GO
Po utworzeniu tego klastrowego indeksu Osoba tabela zostanie fizycznie posortowana według nazwiska , Imię i MiddleName .
Jedną z zalet tego podejścia jest poprawa wydajności zapytań na podstawie nazwy. Poza tym sortuje wyniki według nazwy bez określania ORDER BY. Pamiętaj jednak, że jeśli nazwa się zmieni, tabela będzie musiała zostać zmieniona. Chociaż nie zdarza się to codziennie, wpływ może być ogromny, jeśli stół jest bardzo duży.
Co to jest indeks nieklastrowany
Indeks nieklastrowy to indeks z kluczem i wskaźnikiem do wierszy lub kluczy indeksu klastrowego. Ten indeks może dotyczyć zarówno tabel, jak i widoków.
W przeciwieństwie do indeksów klastrowych tutaj struktura jest oddzielona od tabeli. Ponieważ jest oddzielny, potrzebuje wskaźnika do wierszy tabeli, zwanego również lokalizatorem wierszy. Dlatego każdy wpis w indeksie nieklastrowym zawiera lokalizator i wartość klucza.
Indeksy nieklastrowe nie sortują fizycznie tabeli na podstawie klucza.
Klucze indeksu dla indeksów nieklastrowych mają maksymalny rozmiar 1700 bajtów. Możesz ominąć ten limit, dodając uwzględnione kolumny. Ta metoda jest dobra, jeśli zapytanie musi objąć więcej kolumn bez zwiększania rozmiaru klucza.
Możesz także tworzyć filtrowane indeksy nieklastrowane. Zmniejszy to koszty utrzymania indeksu i przechowywania, jednocześnie poprawiając wydajność zapytań.
Kiedy używać indeksu nieklastrowanego?
Kolumna lub kolumny są dobrymi kandydatami na indeksy nieklastrowane, jeśli spełnione są następujące warunki:
- Kolumna lub kolumny są używane w klauzuli WHERE lub łączeniu.
- Zapytanie nie zwróci dużego zestawu wyników.
- Potrzebne jest dokładne dopasowanie w klauzuli WHERE przy użyciu operatora równości.
Przykłady
To polecenie utworzy unikalny, nieklastrowany indeks w Pracowniku tabela:
CREATE UNIQUE NONCLUSTERED INDEX [AK_Employee_NationalIDNumber] ON [HumanResources].[Employee]
(
[NationalIDNumber] ASC
)
GO
Oprócz tabeli możesz utworzyć indeks nieklastrowy dla widoku:
CREATE NONCLUSTERED INDEX [IDX_vProductAndDescription_ProductModel] ON [Production].[vProductAndDescription]
(
[ProductModel] ASC
)
GO
Inne często zadawane pytania i satysfakcjonujące odpowiedzi
Jakie są różnice między indeksem klastrowanym a nieklastrowanym?
Na podstawie tego, co widziałeś wcześniej, możesz już tworzyć pomysły na to, jak różnią się indeksy klastrowane i nieklastrowane. Ale postawmy go na stole, aby ułatwić sobie przypomnienie.
| Informacje | Indeks klastrowy | Indeks nieklastrowany |
| Dotyczy | Tabele i widoki | Tabele i widoki |
| Dozwolone na tabelę | 1 | 999 |
| Rozmiar klucza | 900 bajtów | 1700 bajtów |
| Kolumny na klucz indeksu | 32 | 32 |
| Dobre dla | Zapytania o zakres (>,<,>=, <=, BETWEEN) | Dopasowania ścisłe (=) |
| Kolumny bez klucza | Niedozwolone | Dozwolone |
| Filtruj z warunkiem | Niedozwolone | Dozwolone |
Czy klucze podstawowe powinny być indeksem klastrowym czy nieklastrowym?
Klucz podstawowy to ograniczenie. Po ustawieniu kolumny jako klucza podstawowego automatycznie tworzony jest z niej indeks klastrowy, chyba że istniejący indeks klastrowy już istnieje.
Nie myl klucza podstawowego z indeksem klastrowym! Klucz podstawowy może być również kluczem indeksu klastrowego. Ale klucz indeksu klastrowego może być inną kolumną niż klucz podstawowy.
Weźmy inny przykład. W Osobie tabela AdventureWorks201 7, mamy BusinessEntityID klucz podstawowy. Jest to również klucz indeksu klastrowego. Możesz usunąć ten indeks klastrowy. Następnie utwórz indeks klastrowy na podstawie nazwiska , Imię i Drugie imię . Kluczem podstawowym jest nadal BusinessEntityID kolumna.
Ale czy klucze podstawowe powinny być zawsze grupowane?
To zależy. Wróć do pytania, kiedy używać indeksu klastrowego.
Jeśli kolumna lub kolumny pojawiają się w klauzuli WHERE w wielu zapytaniach, jest to kandydat do indeksu klastrowego. Ale inną kwestią jest to, jak szeroki jest klucz indeksu klastrowego. Zbyt szeroki – a rozmiar każdego indeksu nieklastrowanego wzrośnie, jeśli będą istnieć. Pamiętaj, że indeksy nieklastrowe również używają klucza indeksu klastrowego jako wskaźnika. Dlatego trzymaj klucz indeksu klastrowego tak wąski, jak to możliwe.
Jeśli duża liczba zapytań używa klucza podstawowego w klauzuli WHERE, pozostaw go również jako klucz indeksu klastrowego. Jeśli nie, utwórz klucz podstawowy jako indeks nieklastrowy.
Ale co, jeśli nadal nie masz pewności? Następnie można ocenić korzyści związane z wydajnością kolumny, gdy jest ona klastrowana lub nieklastrowana. Więc przejdź do następnej sekcji na ten temat.
Co jest szybsze:indeks klastrowy czy nieklastrowy?
Dobre pytanie. Nie ma ogólnej zasady. Musisz sprawdzić odczyty logiczne i plan wykonania swoich zapytań.
Nasz krótki eksperyment będzie zawierał kopie poniższych tabel z AdventureWorks2017 baza danych:
- Osoba
- Adres podmiotu gospodarczego
- Adres
- Typ adresu
Oto skrypt:
IF NOT EXISTS(SELECT name FROM sys.databases WHERE name = 'TestDatabase')
BEGIN
CREATE DATABASE TestDatabase
END
USE TestDatabase
GO
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkClustered FROM AdventureWorks2017.Person.Person
ALTER TABLE Person_pkClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID2] PRIMARY KEY CLUSTERED (BusinessEntityID)
CREATE NONCLUSTERED INDEX [IX_Person_Name2] ON Person_pkClustered (LastName, FirstName, MiddleName, Suffix)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkNonClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkNonClustered FROM AdventureWorks2017.Person.Person
CREATE CLUSTERED INDEX [IX_Person_Name1] ON Person_pkNonClustered (LastName, FirstName, MiddleName, Suffix)
ALTER TABLE Person_pkNonClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID1] PRIMARY KEY NONCLUSTERED (BusinessEntityID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'AddressType')
BEGIN
SELECT * INTO AddressType FROM AdventureWorks2017.Person.AddressType
ALTER TABLE AddressType
ADD CONSTRAINT [PK_AddressType] PRIMARY KEY CLUSTERED (AddressTypeID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Address')
BEGIN
SELECT * INTO Address FROM AdventureWorks2017.Person.Address
ALTER TABLE Address
ADD CONSTRAINT [PK_Address] PRIMARY KEY CLUSTERED (AddressID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'BusinessEntityAddress')
BEGIN
SELECT * INTO BusinessEntityAddress FROM AdventureWorks2017.Person.BusinessEntityAddress
ALTER TABLE BusinessEntityAddress
ADD CONSTRAINT [PK_BusinessEntityAddress] PRIMARY KEY CLUSTERED (BusinessEntityID, AddressID, AddressTypeID)
END
GO
Korzystając z powyższej struktury, porównamy szybkości zapytań dla indeksów klastrowych i nieklastrowych.
Mamy 2 kopie Osoby stół. Pierwszy użyje BusinessEntityID jako klucz indeksu podstawowego i klastrowego. Drugi nadal używa BusinessEntityID jako klucz podstawowy. Indeks klastrowy jest oparty na nazwisku , Imię , Drugie imię i sufiks .
Zacznijmy.
ZAPYTAJ DOKŁADNE DOPASOWANIA NA PODSTAWIE NAZWISKO
Najpierw zróbmy proste zapytanie. Musisz także włączyć STATISTICS IO. Następnie wklejamy wyniki w Statisticsparser.com w celu prezentacji tabelarycznej.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, p.Title
FROM Person_pkClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SET STATISTICS IO OFF
GO
Oczekuje się, że pierwszy SELECT będzie wolniejszy, ponieważ klauzula WHERE nie pasuje do klucza indeksu klastrowego. Sprawdźmy jednak odczyty logiczne.
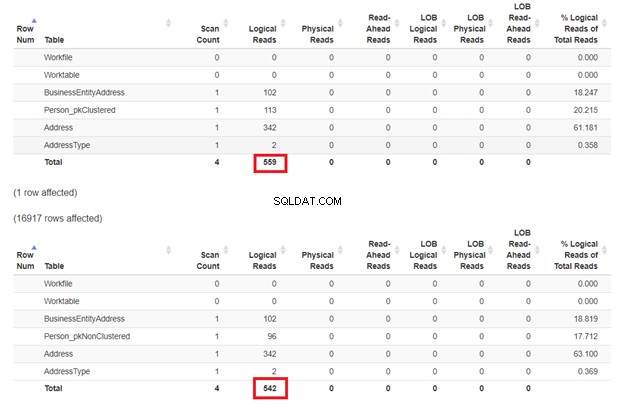
Zgodnie z oczekiwaniami na rysunku 3, Person_pkClustered miał więcej logicznych odczytów. Dlatego zapytanie wymaga więcej operacji we/wy. Powód? Tabela jest posortowana według BusinessEntityID . Jednak druga tabela ma indeks klastrowy oparty na nazwie. Ponieważ zapytanie wymaga wyniku na podstawie nazwy, Person_pkNonClustered wygrywa. Im mniej logiczne odczyty, tym szybsze zapytanie.
Co jeszcze się dzieje? Sprawdź rysunek 4.
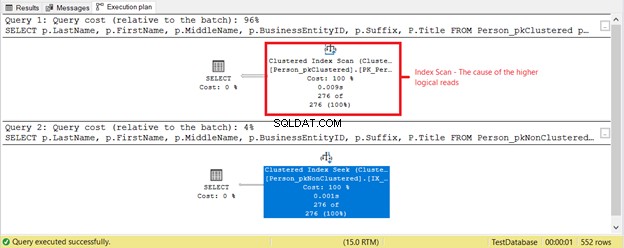
Coś innego wydarzyło się w oparciu o plan wykonania przedstawiony na rysunku 4. Dlaczego skanowanie indeksu klastrowego znajduje się w pierwszym SELECT, a nie w wyszukiwaniu indeksu? Sprawcą jest Tytuł kolumna w WYBIERZ. Nie jest objęty żadnym z istniejących indeksów. Optymalizator SQL Server uznał, że szybsze jest użycie indeksu klastrowego opartego na BusinessEntityID. Następnie SQL Server przeskanował go w poszukiwaniu właściwych nazwisk i uzyskał imię, drugie imię i tytuł.
Usuń Tytuł kolumna, a użytym operatorem będzie Przeszukiwanie indeksu . Czemu? Ponieważ pozostałe pola są objęte indeksem nieklastrowym opartym na nazwisku , Imię , Drugie imię i sufiks . Zawiera również BusinessEntityID jako lokalizator kluczy indeksu klastrowego.
ZAPYTANIE O ZAKRES W OPARCIU O ID PODMIOTU BIZNESOWEGO
Indeksy klastrowe mogą być dobre dla zapytań o zakres. Czy zawsze tak jest? Dowiedzmy się, korzystając z poniższego kodu.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SET STATISTICS IO OFF
GO
Wizytówka musi zawierać wiersze na podstawie zakresu BusinessEntityID od 285 do 290. Ponownie, klastrowe i nieklastrowe indeksy obu tabel są nienaruszone. Teraz przyjrzyjmy się logicznym odczytom na rysunku 5. Oczekiwanym zwycięzcą jest Person_pkClustered ponieważ klucz podstawowy jest również kluczem indeksu klastrowego.

Czy widzisz niższe odczyty logiczne w Person_pkClustered? ? Indeksy klastrowe sprawdziły się w zapytaniach zakresowych w tym scenariuszu. Zobaczmy, co jeszcze ujawni plan wykonania na rysunku 6.
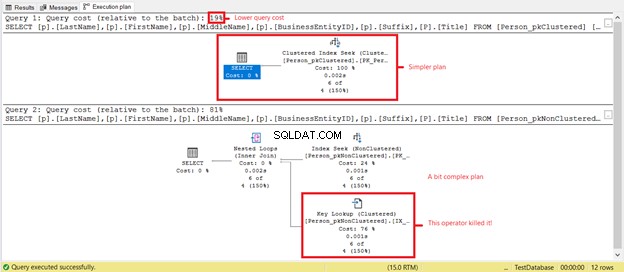
Pierwszy SELECT ma prostszy plan i niższy koszt zapytań, jak pokazano na rysunku 7. Obsługuje to również niższe odczyty logiczne. Tymczasem drugi SELECT ma operator Key Lookup, który spowalnia zapytanie. Sprawca? Ponownie jest to Tytuł kolumna. Usuń kolumnę w zapytaniu lub dodaj ją jako kolumnę Uwzględnioną w indeksie nieklastrowanym. Wtedy będziesz mieć lepszy plan i niższe odczyty logiczne.
ZAPYTAJ DOKŁADNE DOPASOWANIA Z DOŁĄCZENIEM
Wiele instrukcji SELECT zawiera sprzężenia. Zróbmy kilka testów. Tutaj zaczynamy od dokładnych dopasowań:
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SET STATISTICS IO OFF
GO
Spodziewamy się, że drugi SELECT z Person_pkNonClustered z indeksem klastrowym na nazwie będzie miał mniej odczytów logicznych. Ale czy tak jest? Zobacz rysunek 7.
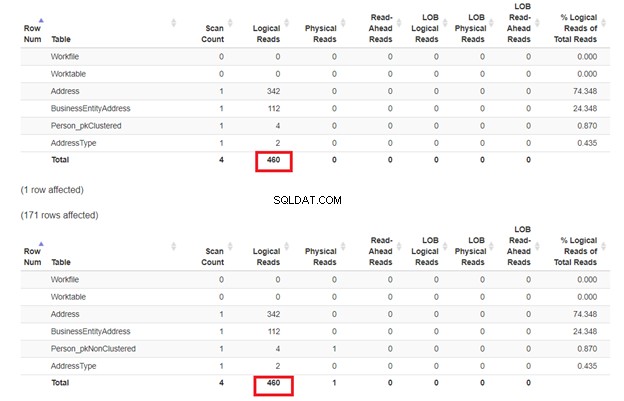
Wygląda na to, że indeks nieklastrowy na nazwie działał dobrze. Odczyty logiczne są takie same. Jeśli sprawdzisz plan wykonania, różnica między operatorami to Clustered Index Seek na Person_pkNonClustered , a wyszukiwanie indeksu w Person_pkClustered .
Dlatego musimy sprawdzić odczyty logiczne i plan wykonania, aby mieć pewność.
ZAPYTANIE ZAKRESU Z POŁĄCZENIAMI
Ponieważ nasze oczekiwania mogą różnić się od rzeczywistości, wypróbujmy to z zapytaniami zakresowymi. Indeksy klastrowe są z tym ogólnie dobre. Ale co, jeśli dołączysz dołączenie?
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SET STATISTICS IO OFF
GO
Teraz sprawdź odczyty logiczne tych 2 zapytań na rysunku 8:
Co się stało? Na rysunku 9 rzeczywistość gryzie w Person_pkClustered . Zaobserwowano w nim większe koszty we/wy w porównaniu z Person_pkNonClustered . To różni się od tego, czego oczekujemy. Jednak w oparciu o tę odpowiedź z forum, wyszukiwanie indeksu nieklastrowego może być szybsze niż wyszukiwanie indeksu klastrowego, gdy wszystkie kolumny w zapytaniu są w 100% objęte indeksem. W naszym przypadku zapytanie o Person_pkNonClustered pokrył kolumny za pomocą indeksu nieklastrowego (BusinessEntityID - klucz; Nazwisko , Imię , Drugie imię , Przyrostek – wskaźnik do klucza indeksu klastrowego).
WSTAW WYDAJNOŚĆ
Następnie spróbuj przetestować wydajność INSERT w tych samych tabelach.
SET STATISTICS IO ON
GO
INSERT INTO Person_pkClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
INSERT INTO Person_pkNonClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
SET STATISTICS IO OFF
GO
Rysunek 9 pokazuje logiczne odczyty INSERT:

Oba wygenerowały to samo I/O. W ten sposób obaj wykonali to samo.
USUŃ WYSTĘP
Nasz ostatni test obejmuje USUŃ:
SET STATISTICS IO ON
GO
DELETE FROM Person_pkClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
DELETE FROM Person_pkNonClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
SET STATISTICS IO OFF
GO
Rysunek 10 przedstawia odczyty logiczne. Zwróć uwagę na różnicę.

Dlaczego mamy wyższe odczyty logiczne w Person_pkClustered ? Chodzi o to, że warunek instrukcji DELETE jest oparty na dokładnym dopasowaniu nazwy. Optymalizator będzie musiał najpierw skorzystać z indeksu nieklastrowego. Oznacza to więcej we/wy. Potwierdźmy, korzystając z planu wykonania na rysunku 11.
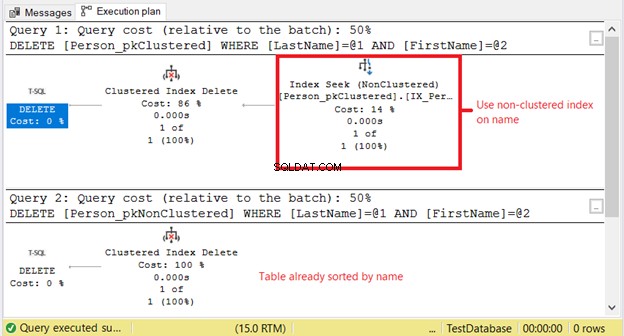
Pierwszy SELECT wymaga wyszukiwania indeksu w indeksie nieklastrowym. Powodem jest klauzula WHERE w nazwisku i Imię . Tymczasem Person_pkNonClustered jest już fizycznie posortowany według nazwy ze względu na indeks klastrowy.
Na wynos
W tworzeniu zapytań o wysokiej skuteczności nie chodzi o szczęście. Nie można po prostu umieścić indeksu klastrowego i nieklastrowego, a nagle Twoje zapytania nabierają szybkości. Musisz nadal używać narzędzi jako obiektywu, aby skupić się na drobnych szczegółach innych niż zestaw wyników.
Ale czasami po prostu nie masz czasu na to wszystko. Myślę, że to normalne. Ale tak długo, jak nie zepsujesz tak bardzo, następnego dnia masz pracę i możesz ją rozpracować. Na początku nie będzie to łatwe. W rzeczywistości będzie to mylące. Będziesz mieć również wiele pytań. Ale dzięki ciągłej praktyce możesz to osiągnąć. Więc trzymaj brodę do góry.
Pamiętaj, że zarówno indeksy klastrowane, jak i nieklastrowane służą do zwiększania zapytań. Znajomość kluczowych różnic, scenariuszy użytkowania i narzędzi pomoże Ci w dążeniu do kodowania zapytań o wysokiej wydajności.
Mam nadzieję, że ten post odpowiada na najpilniejsze pytania dotyczące indeksów klastrowych i nieklastrowanych. Czy masz coś jeszcze do dodania dla naszych czytelników? Sekcja komentarzy jest otwarta.
A jeśli uznasz ten post za pouczający, udostępnij go na swoich ulubionych platformach społecznościowych.
Więcej informacji na temat indeksów i wydajności zapytań znajduje się w poniższych artykułach:
- 22 fajne przykłady indeksów SQL, które przyspieszają Twoje zapytania
- Optymalizacja zapytań SQL:5 podstawowych faktów, aby zwiększyć liczbę zapytań