Testowanie to czasochłonne zadanie, ale jest koniecznością przed każdym procesem aktualizacji dowolnej technologii. W zależności od rodzaju aktualizacji może to być trudniejsze lub łatwiejsze, ale zawsze jest to konieczne, jeśli chcesz mieć pewność, że Twoje dane będą bezpieczne. Istnieją różne podejścia do aktualizacji, w zależności od firmy i tolerancji przestojów. Na przykład proces może testować Twoją aplikację w osobnym środowisku z nową wersją, więc będziesz musiał utworzyć w tym celu nowy klaster. Inną opcją jest sklonowanie obecnego środowiska produkcyjnego i zaktualizowanie go, co może być przydatne, ponieważ można emulować cały proces aktualizacji i unikać niespodzianek w przyszłości.
Wykonując cały ten proces testowania ręcznie, istnieje duże prawdopodobieństwo wystąpienia błędu ludzkiego, a proces będzie powolny, co może wpłynąć na docelowy czas odzyskiwania (RTO). W tym blogu zobaczymy, jak zautomatyzować testowanie w celu aktualizacji baz danych PostgreSQL za pomocą ClusterControl.
Typ aktualizacji bazy danych
Istnieją dwa rodzaje uaktualnień:drobne uaktualnienia i duże uaktualnienia.
Drobne aktualizacje
Jest to najczęstsza i najbezpieczniejsza aktualizacja, która w większości przypadków jest wykonywana na miejscu. Ponieważ nic nie jest w 100% bezpieczne, zawsze musisz mieć kopie zapasowe i węzły rezerwowe, więc jeśli coś pójdzie nie tak z aktualizacją, możesz promować węzeł rezerwowy w poprzedniej wersji, a Twoje systemy mogą nadal działać bez przerw.
Możesz przeprowadzić tego rodzaju aktualizację za pomocą ClusterControl. W tym celu przejdź do ClusterControl -> Wybierz swój klaster PostgreSQL -> Zarządzaj -> Aktualizacje.
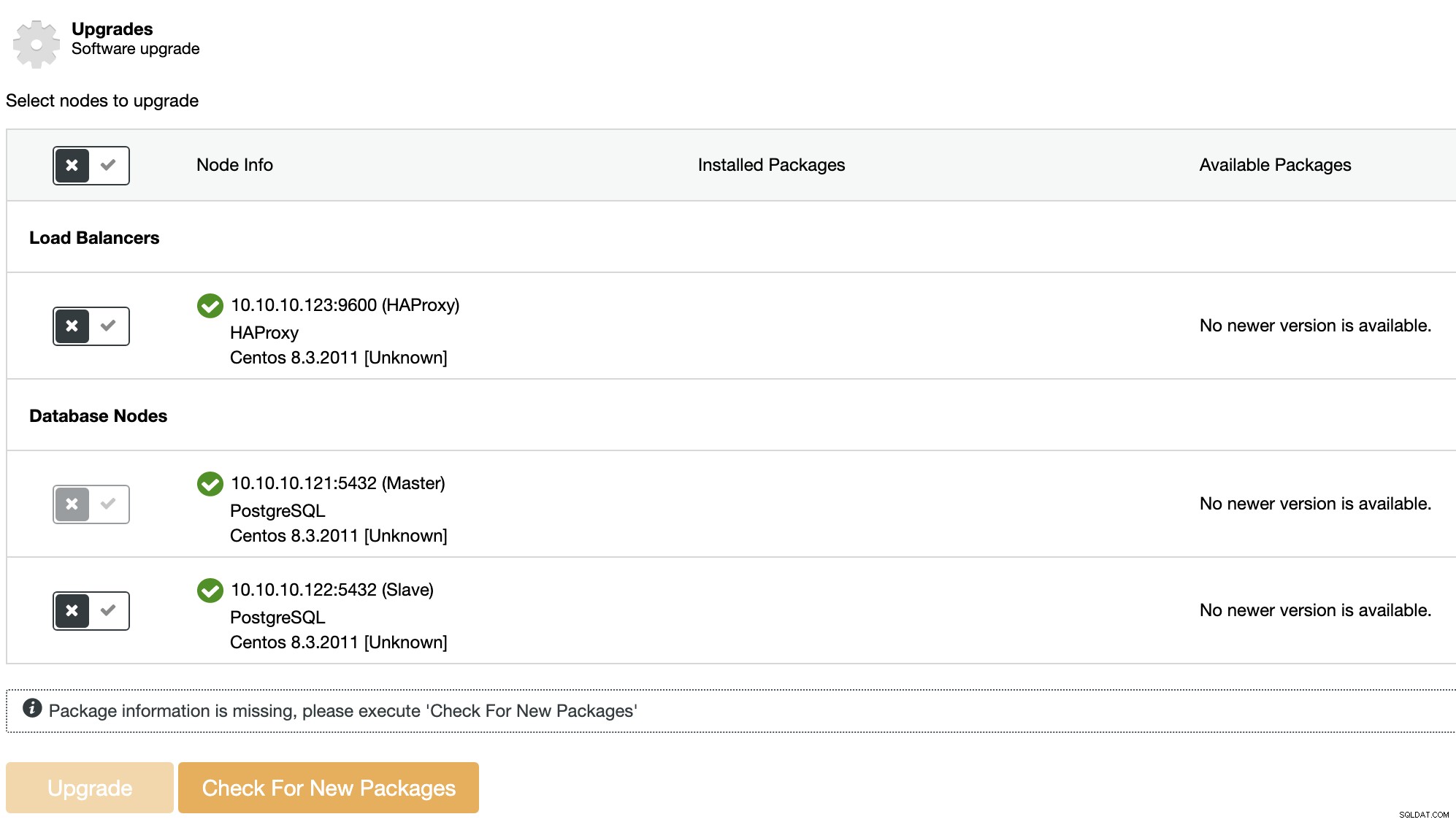
W każdym wybranym węźle procedura aktualizacji:
-
Zatrzymaj węzeł
-
Aktualizuj węzeł
-
Węzeł startowy
Węzeł główny w topologii PostgreSQL nie zostanie zaktualizowany. Aby uaktualnić Master, inny węzeł musi najpierw zostać awansowany na nowego Mastera.
Większe aktualizacje
W przypadku głównych uaktualnień nie jest zalecane uaktualnienie w miejscu, ponieważ ryzyko wystąpienia błędu jest zbyt wysokie dla środowiska produkcyjnego. Zamiast tego istnieją różne podejścia do przeprowadzania aktualizacji.
Możesz sklonować obecny klaster bazy danych, zaktualizować go i przetestować tam swoją aplikację, a kiedy skończysz, jeśli wszystko pójdzie dobrze, możesz go ponownie utworzyć, aby powtórzyć proces, aby dokonać prawdziwej aktualizacji , lub możesz również utworzyć nowy klaster w nowej wersji, przetestować aplikację i przełączyć ruch, gdy będzie gotowy, a jest więcej opcji... Użycie Load Balancers jest tutaj przydatne, aby poprawić wysoką dostępność. Najlepsze podejście zależy od tolerancji przestojów i docelowego czasu odzyskiwania (RTO).
Nie możesz przeprowadzić głównych aktualizacji bezpośrednio za pomocą ClusterControl, ponieważ, jak wspomnieliśmy, musisz najpierw wszystko przetestować, aby upewnić się, że aktualizacja jest bezpieczna, ale możesz użyć różnych funkcji ClusterControl, aby dokonać to zadanie łatwiejsze. Zobaczmy więc niektóre z tych funkcji.
Wdrażanie środowiska testowego
W tym celu nie musisz tworzyć wszystkiego od zera. Zamiast tego możesz użyć ClusterControl do robienia tego w sposób ręczny lub zautomatyzowany.
Przywróć kopię zapasową na samodzielnym hoście
W sekcji Kopia zapasowa wybierz kopię zapasową, a zobaczysz opcję „Przywróć i zweryfikuj na samodzielnym hoście”, aby przywrócić kopię zapasową w osobnym węźle.
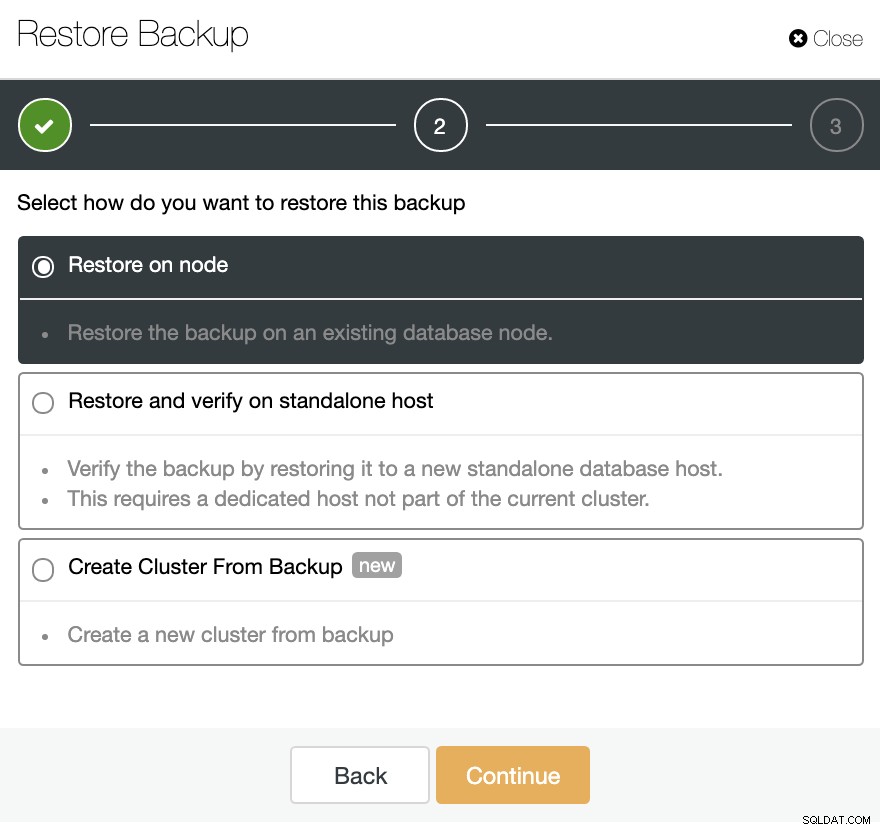
Tutaj możesz określić, czy ClusterControl ma zainstalować oprogramowanie w nowym węzła i wyłącz zaporę lub AppArmor/SELinux (w zależności od systemu operacyjnego). W tym celu potrzebujesz dedykowanego hosta (lub maszyny wirtualnej), który nie jest częścią klastra.
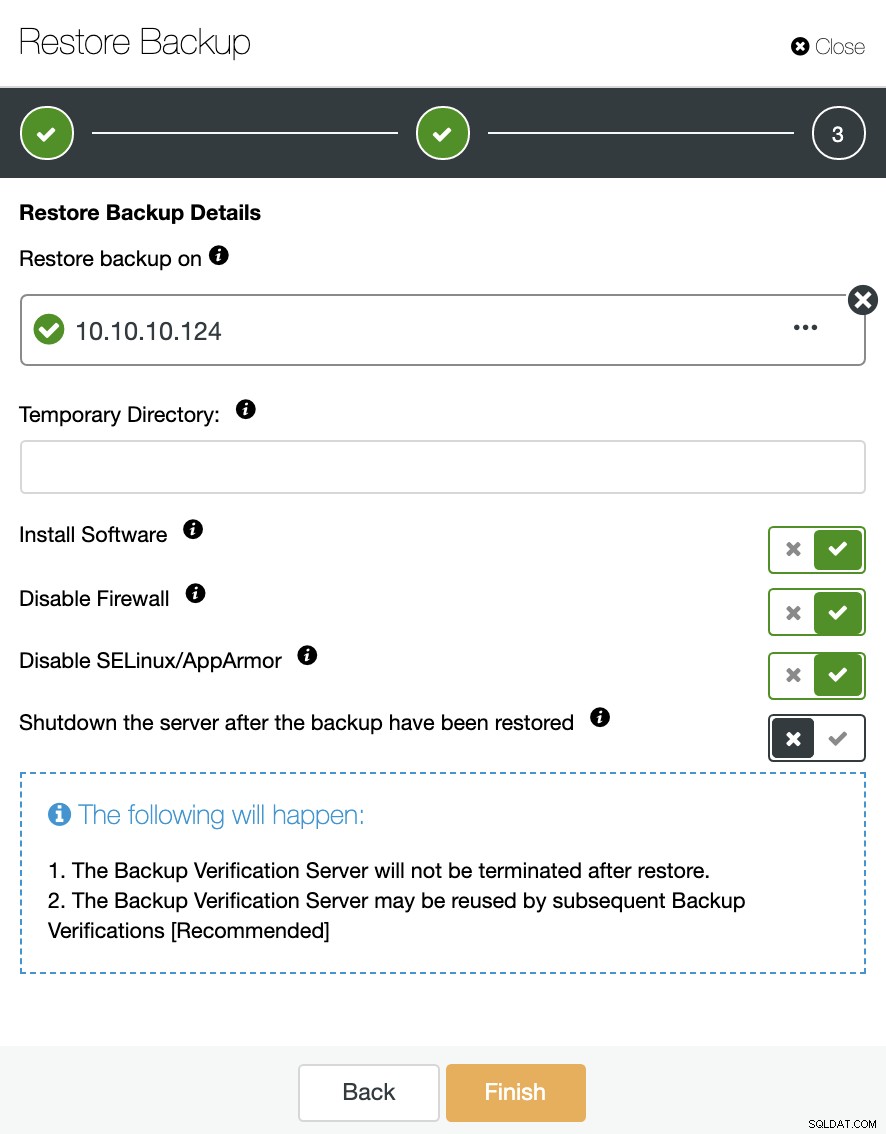
Możesz utrzymać i działać węzeł lub ClusterControl może wyłączyć bazę danych serwis do następnego zadania przywracania. Po zakończeniu zobaczysz przywróconą/zweryfikowaną kopię zapasową na liście kopii zapasowych oznaczoną haczykiem.
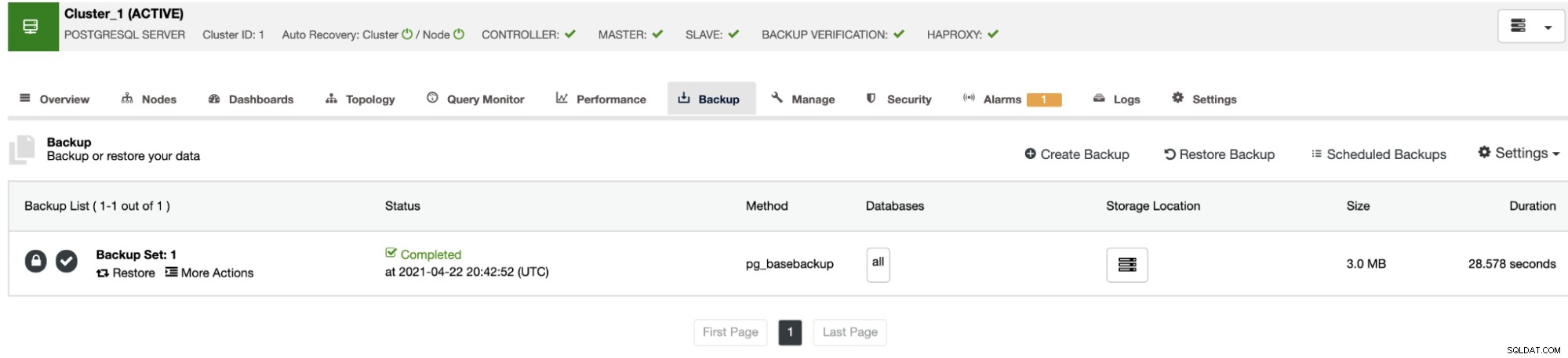
Jeśli nie chcesz wykonywać tego zadania ręcznie, możesz zaplanować ten proces za pomocą funkcji Sprawdź kopię zapasową, aby okresowo powtarzać to zadanie w zadaniu kopii zapasowej. Zobaczymy, jak to zrobić w następnej sekcji.
Automatyczna weryfikacja kopii zapasowej ClusterControl
Aby zautomatyzować to zadanie, przejdź do ClusterControl -> Wybierz swój klaster PostgreSQL -> Kopia zapasowa -> Utwórz kopię zapasową i wybierz opcję Zaplanowana kopia zapasowa. Funkcja automatycznej weryfikacji kopii zapasowej jest dostępna tylko dla zaplanowanych kopii zapasowych.
W drugim kroku upewnij się, że masz włączoną opcję Zweryfikuj kopię zapasową, i uzupełnij wymagane informacje.
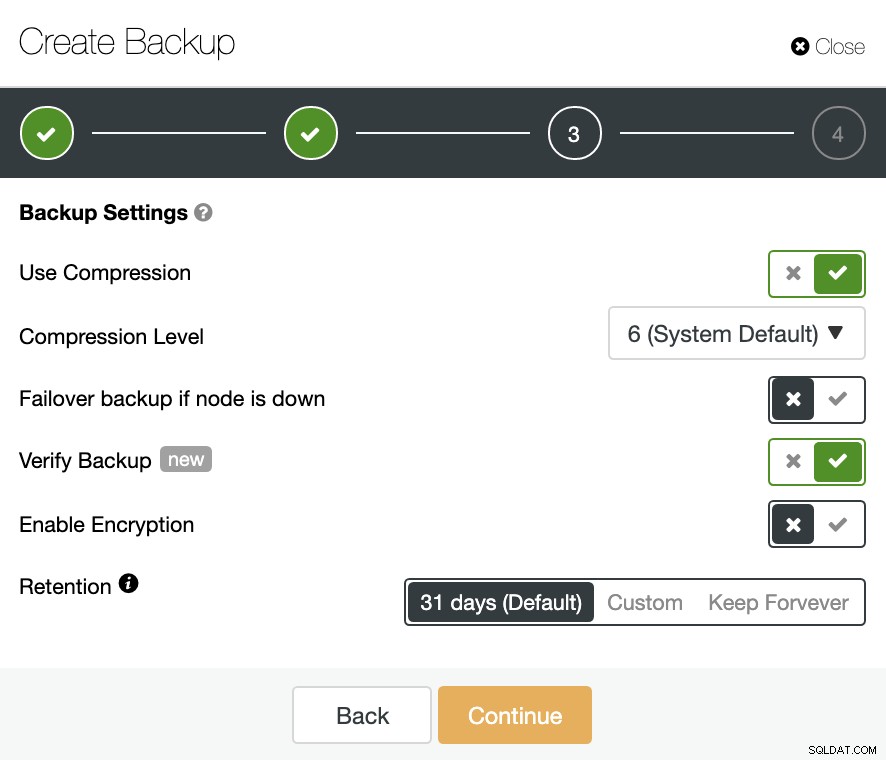
Po zakończeniu zadania zobaczysz ikonę weryfikacji w ClusterControl Sekcja kopii zapasowej, ta sama, którą będziesz mieć wykonując weryfikację w sposób ręczny, z tą różnicą, że nie musisz się martwić o zadanie przywracania. ClusterControl przywróci kopię zapasową za każdym razem automatycznie i możesz przetestować swoją aplikację z najnowszymi danymi.
Utwórz klaster z kopii zapasowej
Innym sposobem utworzenia środowiska testowego jest utworzenie nowego klastra z kopii zapasowej klastra podstawowego. W tym celu przejdź do ClusterControl -> Wybierz swój klaster PostgreSQL -> Kopia zapasowa. Tam wybierz z listy kopię zapasową do przywrócenia i wybierz Przywróć -> Utwórz klaster z kopii zapasowej.
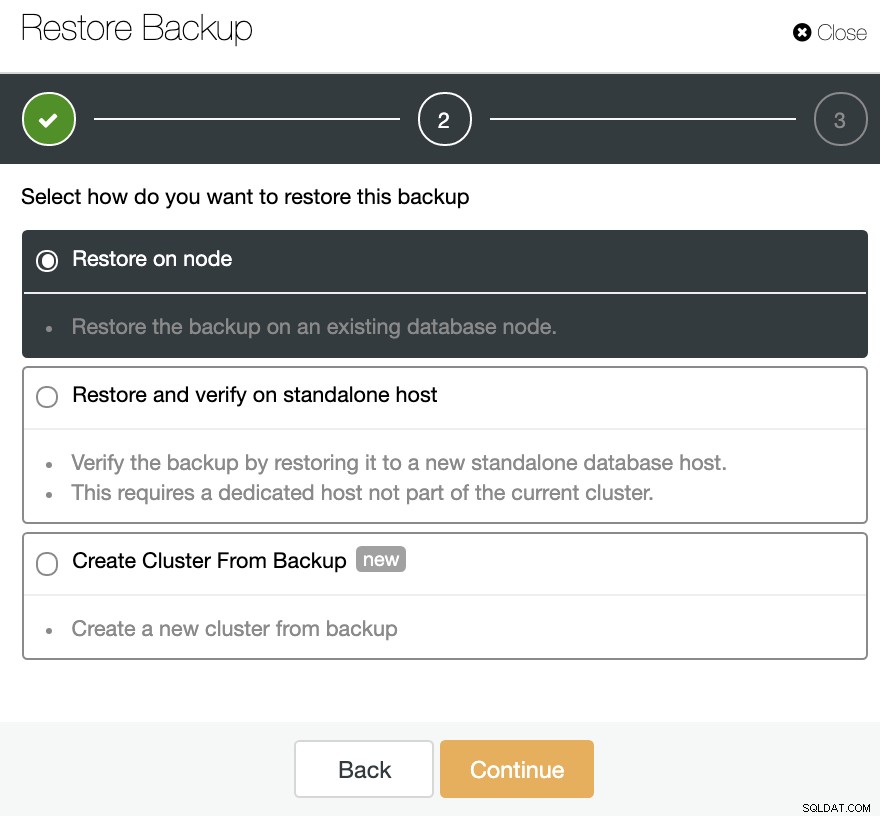
Ta opcja utworzy nowy klaster PostgreSQL z wybranej kopii zapasowej.
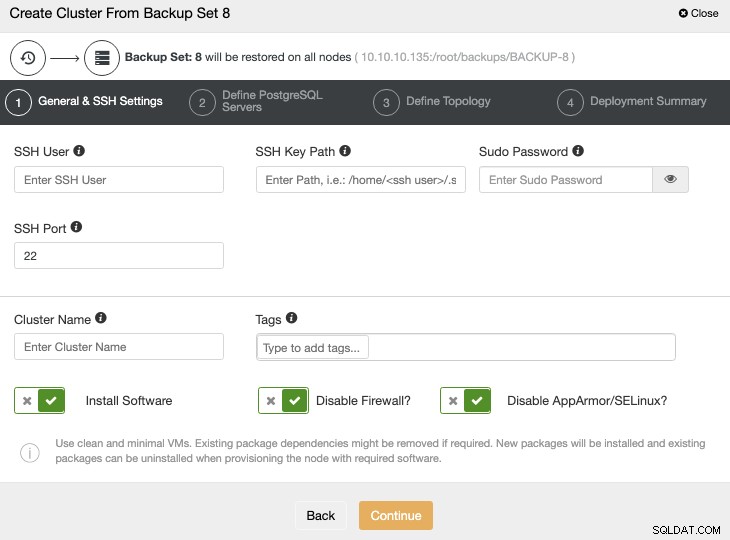
Musisz dodać poświadczenia systemu operacyjnego i bazy danych oraz informacje, aby wdrożyć nowy klaster. Po zakończeniu tego zadania zobaczysz nowy klaster w interfejsie użytkownika ClusterControl.
Replikacja między klastrami
Od wersji ClusterControl 1.7.4 istnieje funkcja o nazwie Cluster-to-Cluster Replication. Pozwala na uruchomienie replikacji między dwoma autonomicznymi klastrami.
Tworzenie replikacji między klastrami
Przejdź do ClusterControl -> Wybierz swój klaster PostgreSQL -> Akcje klastra -> Utwórz klaster Slave.
Klaster Slave zostanie utworzony przez strumieniowe przesyłanie danych z bieżącego klastra głównego.
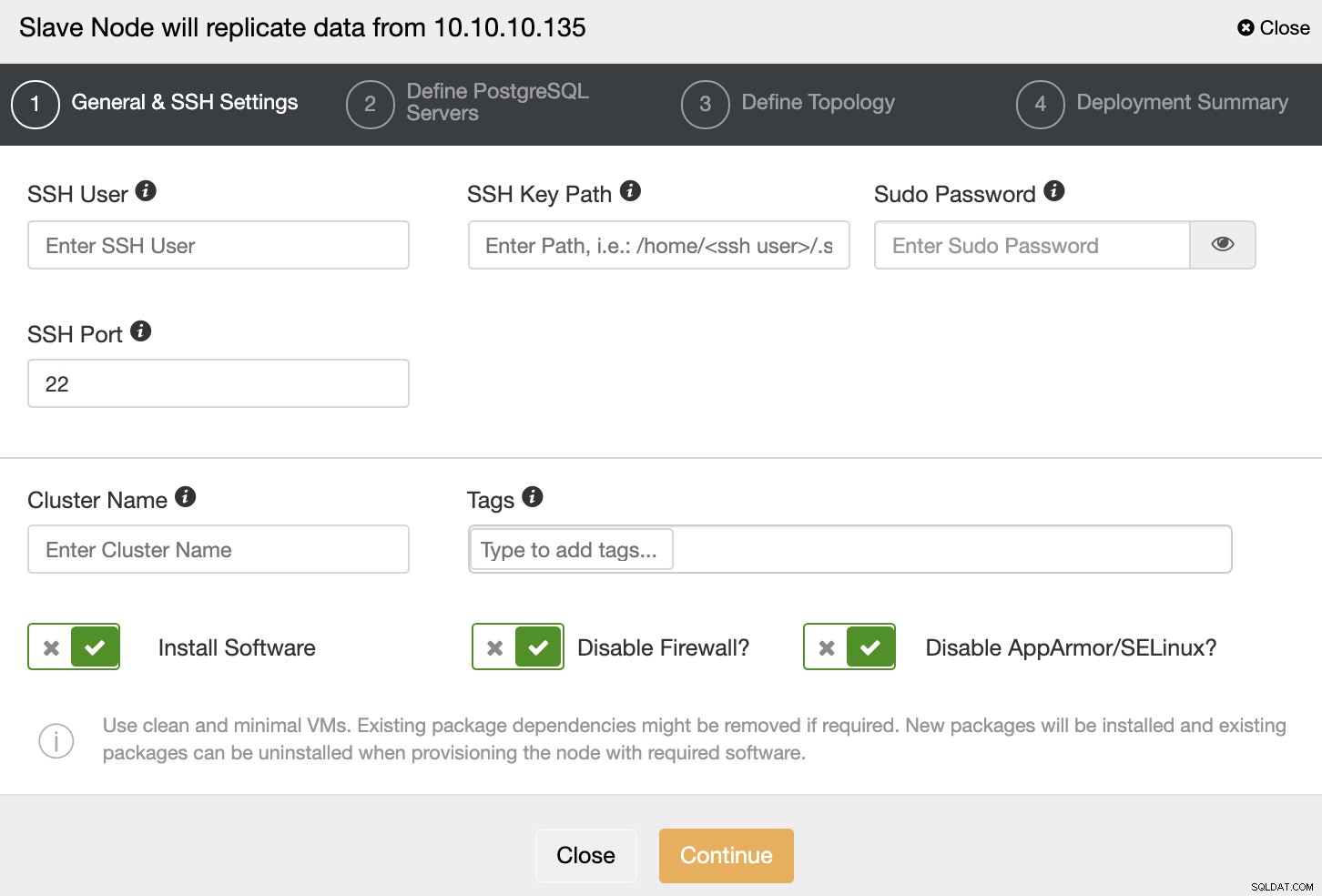
Musisz podać poświadczenia SSH i port, nazwę swojego klastra Slave, i jeśli chcesz, aby ClusterControl zainstalował dla Ciebie odpowiednie oprogramowanie i konfiguracje.
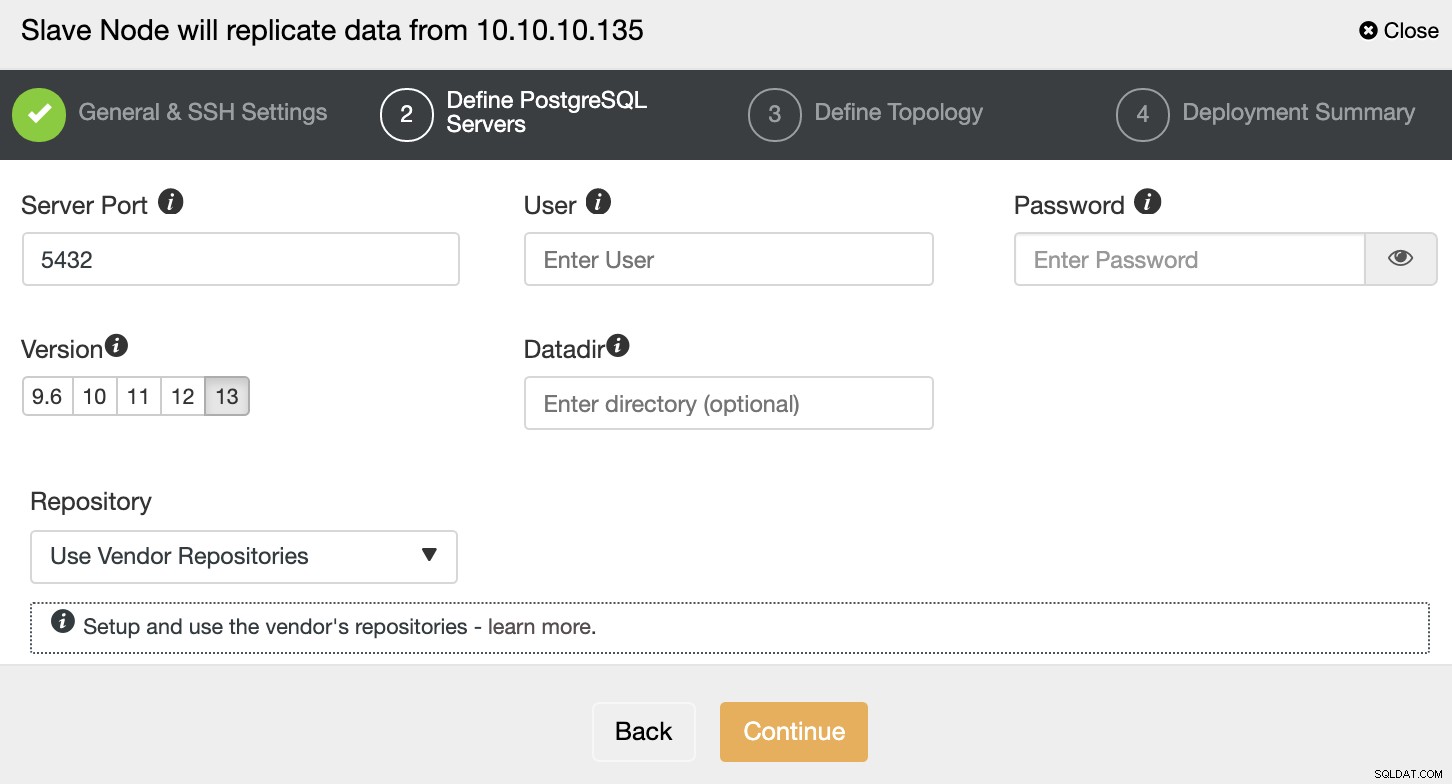
Po skonfigurowaniu informacji dostępowych SSH należy zdefiniować wersję bazy danych, datadir, port i poświadczenia administratora. Ponieważ będzie korzystać z replikacji strumieniowej, upewnij się, że używasz tej samej wersji bazy danych, a poświadczenia muszą być takie same, jak używane przez klaster podstawowy.
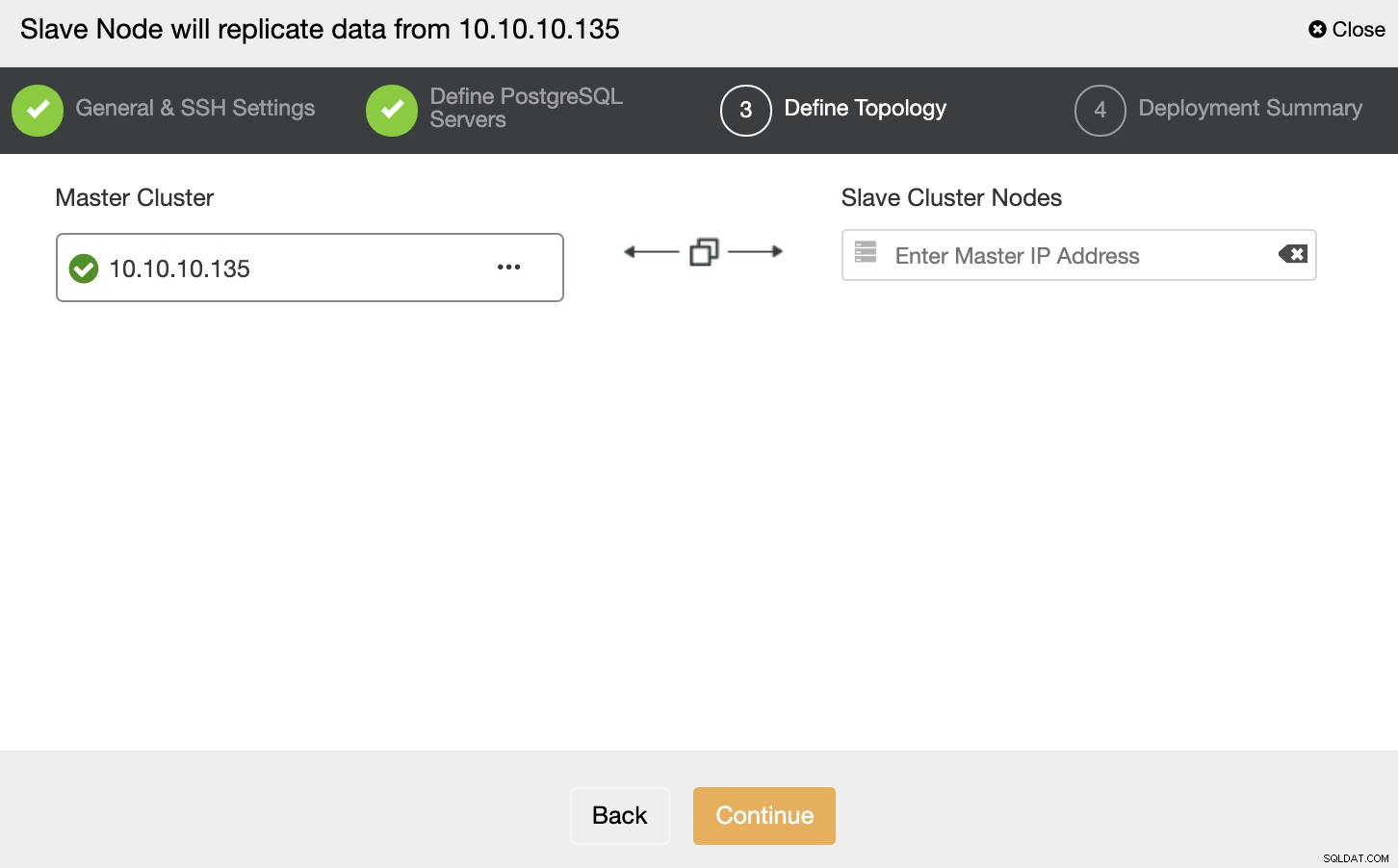
W tym kroku musisz dodać serwer do nowego klastra Slave . W tym zadaniu możesz wprowadzić adres IP lub nazwę hosta węzła bazy danych.
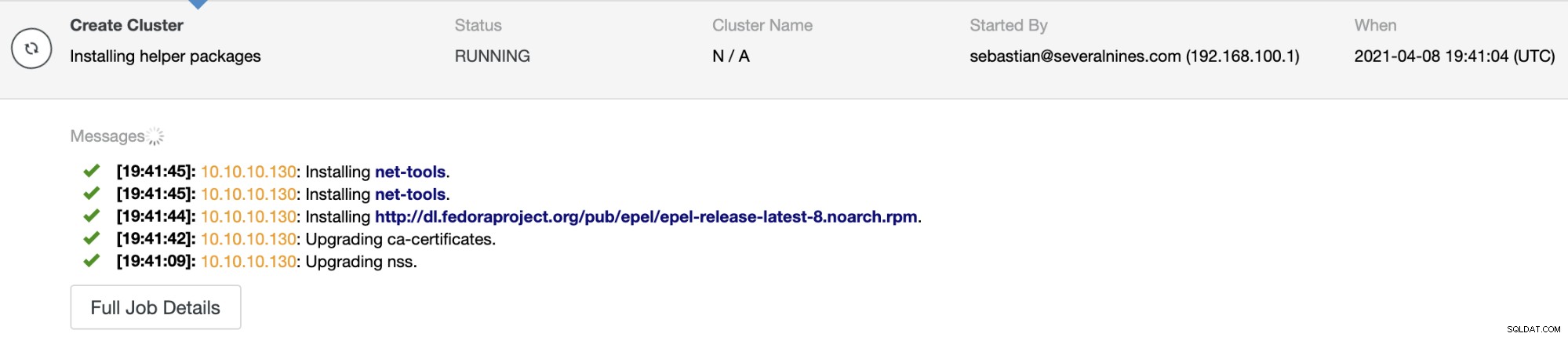
Możesz monitorować stan zadania w monitorze aktywności ClusterControl. Po zakończeniu zadania możesz zobaczyć klaster na głównym ekranie ClusterControl.
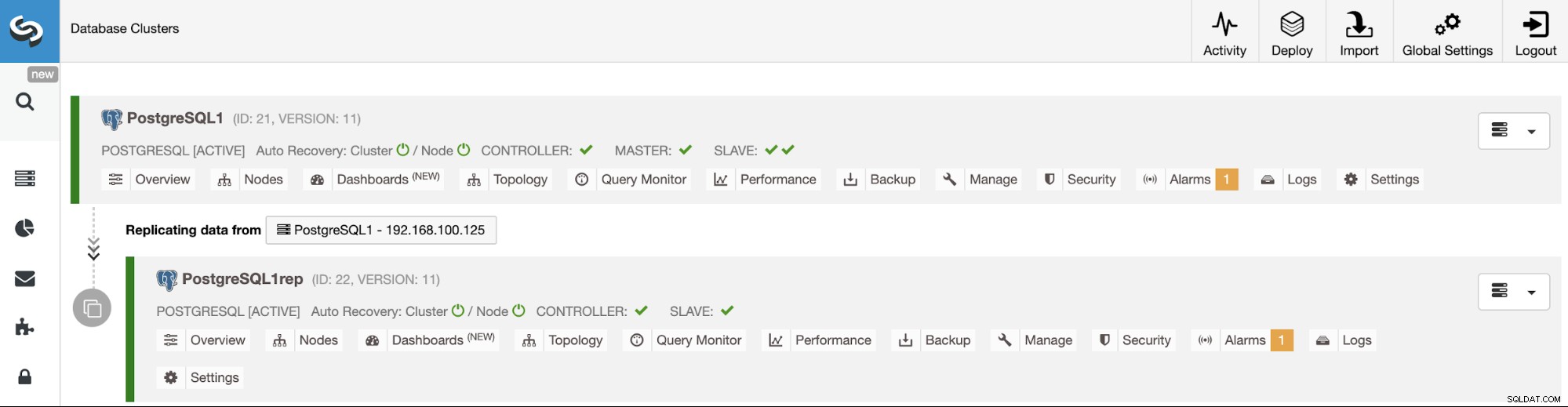
Autoodzyskiwanie i przełączanie awaryjne
Po włączeniu funkcji Autoodzyskiwania, w przypadku awarii, ClusterControl przeniesie najbardziej zaawansowany węzeł rezerwowy do podstawowego, a także powiadomi Cię o problemie. Replikuje również pozostałe węzły rezerwowe z nowego serwera głównego.
Jeśli w topologii znajdują się Load Balancery, ClusterControl skonfiguruje je ponownie, aby zastosować zmiany topologii.
W razie potrzeby można również uruchomić przełączanie awaryjne ręcznie. Przejdź do ClusterControl -> Wybierz swój klaster PostgreSQL -> Węzły -> Wybierz węzeł do promowania -> Akcje węzła -> Promuj urządzenie podrzędne.
W ten sposób, jeśli coś pójdzie nie tak podczas aktualizacji, możesz użyć ClusterControl, aby to naprawić JAK NAJSZYBCIEJ.
Automatyzacja za pomocą ClusterControl CLI
ClusterControl CLI, znany również jako s9s, to narzędzie wiersza poleceń wprowadzone w ClusterControl w wersji 1.4.1 do interakcji, kontroli i zarządzania klastrami baz danych za pomocą systemu ClusterControl. ClusterControl CLI otwiera drzwi do automatyzacji klastra, gdzie można go łatwo zintegrować z istniejącymi narzędziami do automatyzacji wdrażania, takimi jak Ansible, Puppet, Chef itp. Zobaczmy teraz kilka przykładów tego narzędzia.
Aktualizacja
$ s9s cluster --cluster-id=9 \
--check-pkg-upgrades \
--log
$ s9s cluster --cluster-id=9 \
--available-upgrades \
--nodes=10.10.10.122 \
--log \
--print-json
$ s9s cluster --cluster-id=9 \
--upgrade-cluster \
--nodes=10.10.10.122 \
--logWeryfikuj kopie zapasowe
$ s9s backup --verify \
--backup-id=2 \
--test-server=10.10.10.124 \
--cluster-id=9 \
--logReplikacja między klastrami
$ s9s cluster --create \
--cluster-name=PostgreSQL-c2c \
--cluster-type=postgresql \
--provider-version=13 \
--nodes=10.10.10.125 \
--os-user=root \
--os-key-file=/root/.ssh/id_rsa \
--db-admin=admin \
--db-admin-passwd=********* \
--vendor=postgres \
--remote-cluster-id=9 \
--logPromuj węzeł podrzędny
$ s9s cluster --promote-slave \
--cluster-id=9 \
--nodes='10.10.10.122' \
--logWnioski
Aktualizacje są niezbędnymi, ale czasochłonnymi zadaniami, ponieważ musisz przetestować swoją aplikację, aby uniknąć problemów podczas procesu. Wdrażanie środowiska testowego za każdym razem, gdy zachodzi potrzeba aktualizacji i utrzymywania go na bieżąco bez żadnego narzędzia do automatyzacji, może być trudne.
ClusterControl umożliwia wykonywanie drobnych aktualizacji z interfejsu użytkownika lub CLI ClusterControl, a nawet wdrażanie środowiska testowego, aby zadanie aktualizacji było łatwiejsze i bezpieczniejsze. Możesz również zintegrować go z różnymi narzędziami automatyzacji, takimi jak Ansible, Puppet i nie tylko.