Extraction Transformation Load (ETL) jest podstawą każdej hurtowni danych. W świecie hurtowni danych danymi zarządza proces ETL, który składa się z trzech procesów:ekstrakcji-pobierania/pobierania danych ze źródeł, przekształcania-zmiany danych w wymaganym formacie i ładowania-wypychania danych do miejsca docelowego, ogólnie do hurtowni danych lub hurtownia danych.
Naucz się SSIS i rozpocznij bezpłatny okres próbny już dziś!
SQL Server Integration Services (SSIS) to narzędzie z rodziny ETL, które jest przydatne do tworzenia hurtowni danych przedsiębiorstwa i zarządzania nią. Hurtownia danych dzięki własnej charakterystyce działa na ogromnej ilości danych, a wydajność jest dużym wyzwaniem przy zarządzaniu ogromną ilością danych dla dowolnego architekta lub DBA.
Uwagi dotyczące ulepszenia ETL
Dzisiaj omówię, jak łatwo można poprawić wydajność ETL lub zaprojektować wysokowydajny system ETL za pomocą SSIS. Dla lepszego zrozumienia podzielę dziesięć metod na dwie różne kategorie; po pierwsze, rozważania dotyczące czasu projektowania pakietu SSIS, a po drugie konfigurowanie różnych wartości właściwości składników dostępnych w pakiecie SSIS.
Zagadnienia dotyczące czasu projektowania pakietu SSIS
#1 Wyodrębnij dane równolegle:SSIS umożliwia równoległe pobieranie danych przy użyciu kontenerów Sequence w przepływie kontroli. Możesz zaprojektować pakiet w taki sposób, aby mógł równolegle pobierać dane z niezależnych tabel lub plików, co pomoże skrócić całkowity czas wykonania ETL.
#2 Wyodrębnij wymagane dane:pobierz tylko wymagany zestaw danych z dowolnej tabeli lub pliku. Musisz na razie unikać tendencji do ściągania wszystkiego, co jest dostępne ze źródła, z czego będziesz korzystać w przyszłości; zużywa przepustowość sieci, zużywa zasoby systemowe (we/wy i procesor), wymaga dodatkowej pamięci masowej i obniża ogólną wydajność systemu ETL.
Jeśli Twój system ETL ma naprawdę dynamiczny charakter, a Twoje wymagania często się zmieniają, lepiej byłoby rozważyć inne podejścia projektowe, takie jak ETL oparte na Meta Data itp., zamiast projektować tak, aby wszystko było jednorazowo.
#3 Unikaj używania komponentów transformacji asynchronicznej:SSIS to bogate narzędzie z zestawem komponentów transformacji do wykonywania złożonych zadań podczas wykonywania ETL, ale jednocześnie dużo kosztuje, jeśli te komponenty nie są używane prawidłowo.
W SSIS dostępne są dwie kategorie komponentów transformacji:Synchroniczne i asynchroniczne .
Transformacje synchroniczne to te komponenty, które przetwarzają każdy wiersz i przesuwają w dół do następnego komponentu/miejsca docelowego, wykorzystują przydzieloną pamięć buforową i nie wymagają dodatkowej pamięci, ponieważ jest to bezpośrednia relacja między wierszem danych wejściowych/wyjściowych, który całkowicie mieści się w przydzielonej pamięci. Komponenty takie jak wyszukiwanie, kolumny pochodne i konwersja danych itp. należą do tej kategorii.
Transformacje asynchroniczne to te komponenty, które najpierw przechowują dane w pamięci buforowej, a następnie przetwarzają operacje, takie jak sortowanie i agregacja. Do wykonania zadania wymagana jest dodatkowa pamięć buforowa i dopóki nie będzie dostępna pamięć buforowa, przechowuje ona wszystkie dane w pamięci i blokuje transakcję, zwaną również transformacją blokującą. Aby wykonać zadanie, silnik SSIS (silnik potoku przepływu danych) przydzieli dodatkową pamięć buforową, co ponownie jest obciążeniem systemu ETL. Komponenty takie jak sortowanie, agregowanie, scalanie, łączenie itp. należą do tej kategorii.
Ogólnie rzecz biorąc, powinieneś unikać transformacji asynchronicznych, ale nadal, jeśli znajdziesz się w sytuacji, w której nie masz innego wyboru, musisz wiedzieć, jak radzić sobie z dostępnymi wartościami właściwości tych komponentów. Omówię je w dalszej części tego artykułu.
#4 Optymalne wykorzystanie zdarzenia w procedurach obsługi zdarzeń:aby śledzić postęp wykonywania pakietu lub podejmować inne odpowiednie działania na określonym zdarzeniu, SSIS udostępnia zestaw zdarzeń. Zdarzenia są bardzo przydatne, ale nadmierne wykorzystanie zdarzeń będzie kosztować dodatkowe koszty wykonania ETL.
Tutaj musisz zweryfikować wszystkie cechy przed włączeniem zdarzenia w pakiecie SSIS.
#5 Musisz być świadomy schematu tabeli docelowej podczas pracy na ogromnej ilości danych. Musisz zastanowić się dwa razy, kiedy musisz pobrać ogromne ilości danych ze źródła i umieścić je w hurtowni danych lub hurtowni danych. Podczas próby wypychania dużych ilości danych do miejsca docelowego za pomocą kombinacji operacji wstawiania, aktualizowania i usuwania (DML) mogą wystąpić problemy z wydajnością, ponieważ może to spowodować, że tabela docelowa będzie miała indeksy klastrowe lub nieklastrowe, co może spowodować dużo danych tasuje się w pamięci z powodu operacji DML.
Jeśli ETL ma problemy z wydajnością z powodu dużej liczby operacji DML na tabeli, która ma indeks, należy wprowadzić odpowiednie zmiany w projekcie ETL, takie jak usunięcie istniejących indeksów klastrowanych w fazie przed wykonaniem i ponowne utworzenie wszystkich indeksów w fazie powykonawczej. Możesz znaleźć inne lepsze alternatywy, aby rozwiązać problem w zależności od Twojej sytuacji.
Konfiguruj właściwości komponentów
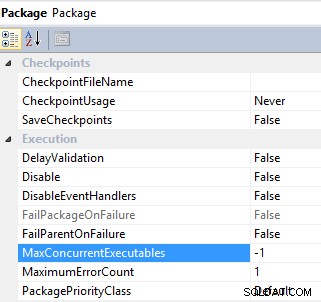
#6 Kontroluj równoległe wykonywanie zadania, konfigurując MaxConcurrentExecutables i EngineThreads własność. Zadania pakietu SSIS i przepływu danych mają właściwość do kontrolowania równoległego wykonywania zadania:MaxConcurrentExecutables jest właściwością na poziomie pakietu i ma domyślną wartość -1 , co oznacza, że maksymalna liczba zadań, które można wykonać, jest równa całkowitej liczbie procesorów na maszynie plus dwa;
Pakiet
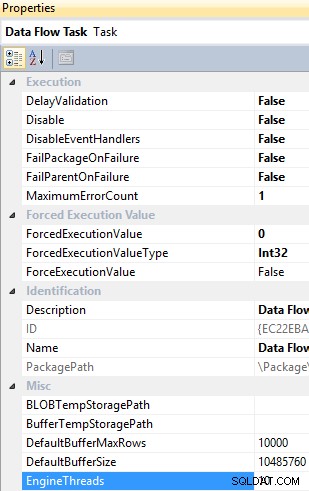
EngineThreads jest właściwością na poziomie zadania przepływu danych i ma domyślną wartość 10, która określa całkowitą liczbę wątków, które można utworzyć w celu wykonania zadania przepływu danych.
Zadanie przepływu danych
Możesz zmienić domyślne wartości tych właściwości zgodnie z potrzebami ETL i dostępnością zasobów.
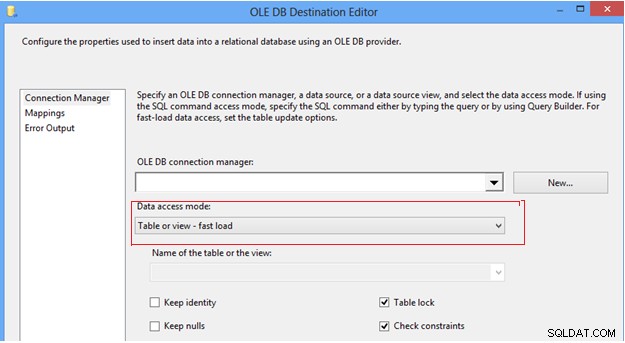
#7 Skonfiguruj opcję trybu dostępu do danych w miejscu docelowym OLEDB. W zadaniu przepływu danych SSIS możemy znaleźć miejsce docelowe OLEDB, które zapewnia kilka opcji przesyłania danych do tabeli docelowej w trybie dostępu do danych; najpierw opcja „Tabela lub widok”, która wstawia po jednym wierszu na raz; po drugie, opcja „Szybkie ładowanie tabeli lub widoku”, która wewnętrznie wykorzystuje instrukcję zbiorczego wstawiania do wysyłania danych do tabeli docelowej, co zawsze zapewnia lepszą wydajność w porównaniu z innymi opcjami. Po wybraniu opcji „szybkie ładowanie” daje to większą kontrolę nad zachowaniem tabeli docelowej podczas operacji wypychania danych, np. Zachowaj tożsamość, Zachowaj wartości null, Blokada tabeli i Ograniczenia sprawdzania.
Edytor miejsca docelowego OLE DB
Zdecydowanie zaleca się korzystanie z opcji szybkiego ładowania w celu wypychania danych do tabeli docelowej w celu poprawy wydajności ETL.
#8, Skonfiguruj wiersze na partię i maksymalny rozmiar zatwierdzenia wstawiania w miejscu docelowym OLEDB. Te dwa ustawienia są ważne, aby kontrolować wydajność tempdb i dziennika transakcji, ponieważ przy podanych wartościach domyślnych tych właściwości dane zostaną wypchnięte do tabeli docelowej w ramach jednej partii i jednej transakcji. Będzie to wymagało nadmiernego użycia tembdb i dziennika transakcji, co przeradza się w problem z wydajnością ETL z powodu nadmiernego zużycia pamięci i miejsca na dysku.
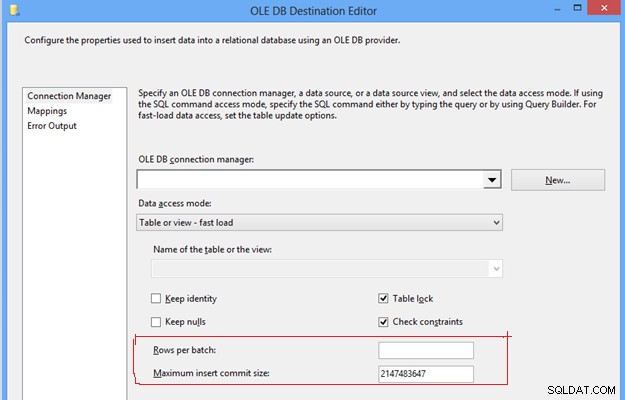
Edytor miejsca docelowego OLE DB
Aby poprawić wydajność ETL, możesz umieścić dodatnią liczbę całkowitą w obu właściwościach w oparciu o przewidywaną ilość danych, co pomoże podzielić całą wiązkę danych na wiele wiązek, a dane w paczce mogą ponownie zostać przekazane do tabeli docelowej w zależności od określona wartość. Pozwoli to uniknąć nadmiernego używania tempdb i dziennika transakcji, co pomoże poprawić wydajność ETL.
9. Użycie lokalizacji docelowej serwera SQL w zadaniu przepływu danych. Jeśli chcesz przesłać dane do lokalnej bazy danych SQL Server, zdecydowanie zaleca się użycie lokalizacji docelowej SQL Server, ponieważ zapewnia ona wiele korzyści w celu przezwyciężenia ograniczeń innych opcji, co pomaga poprawić wydajność ETL. Na przykład używa funkcji wstawiania zbiorczego, która jest wbudowana w SQL Server, ale daje możliwość zastosowania transformacji przed załadowaniem danych do tabeli docelowej. Poza tym daje możliwość włączenia/wyłączenia wyzwalacza, który ma być uruchamiany podczas ładowania danych, co również pomaga zmniejszyć obciążenie ETL.
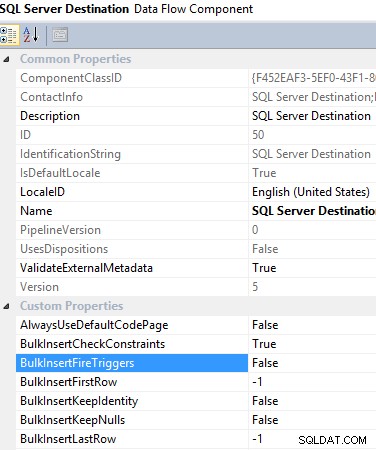
Składnik docelowego przepływu danych programu SQL Server
#10 Unikaj niejawnego rzutowania typu. Gdy dane pochodzą z pliku prostego, Menedżer połączeń pliku prostego traktuje wszystkie kolumny jako typ danych ciągu (DS_STR), w tym kolumny liczbowe. Jak wiadomo, SSIS używa pamięci buforowej do przechowywania całego zestawu danych i stosuje wymaganą transformację przed wypchnięciem danych do tabeli docelowej. Teraz, gdy wszystkie kolumny są danymi typu string, będzie to wymagać więcej miejsca w buforze, co zmniejszy wydajność ETL.
Aby poprawić wydajność ETL, należy przekonwertować wszystkie kolumny liczbowe na odpowiedni typ danych i unikać niejawnej konwersji, która pomoże silnikowi SSIS pomieścić więcej wierszy w jednym buforze.
Podsumowanie ulepszeń wydajności ETL
W tym artykule zbadaliśmy, jak łatwo można kontrolować wydajność ETL w dowolnym momencie. Oto 10 typowych sposobów na poprawę wydajności ETL. Może istnieć więcej metod opartych na różnych scenariuszach, dzięki którym można poprawić wydajność.
Ogólnie rzecz biorąc, za pomocą kategoryzacji możesz określić, jak poradzić sobie z sytuacją. Jeśli jesteś w fazie projektowania hurtowni danych, być może będziesz musiał skoncentrować się na obu kategoriach, ale jeśli obsługujesz dowolny starszy system, najpierw ściśle pracuj nad drugą kategorią.