W pierwszym artykule „Korzystanie z Jenkinsa z Kubernetes AWS, część 1” poświęconym automatyzacji instalacji Kubernetes za pomocą Jenkinsa zainstalowaliśmy Jenkinsa na CoreOS, stworzyliśmy artefakty wymagane do zainstalowania Kubernetesa i utworzyliśmy węzeł Jenkins. W drugim artykule „Korzystanie z Jenkinsa z Kubernetes AWS, część 2” skonfigurowaliśmy plik Jenkins i utworzyliśmy potok Jenkins. W tym artykule uruchomimy potok Jenkins, aby zainstalować Kubernetes, a następnie przetestujemy klaster Kubernetes. Ten artykuł ma następujące sekcje:
- Uruchamianie rurociągu Jenkins
- Testowanie klastra Kubernetes
- Wniosek
Uruchamianie potoku Jenkins
Kliknij Buduj teraz aby uruchomić Jenkins Pipeline, jak pokazano na rysunku 1.
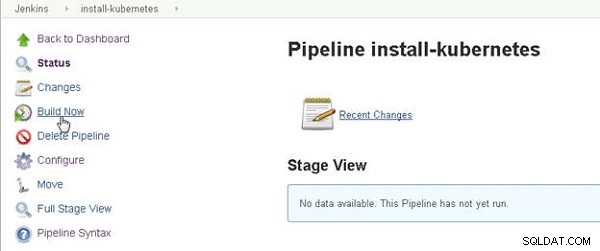
Rysunek 1: Build Now uruchamia rurociąg Jenkins
Potok Jenkinsa zostanie uruchomiony, a pasek postępu wskazuje postęp potoku. Widok sceny dla różnych etapów potoku również zostanie wyświetlony, jak pokazano na rysunku 2. Kube-aws render stage w Stage View ma łącze „paused”, ponieważ zażądaliśmy danych wejściowych użytkownika dla liczby pracowników (i danych wejściowych użytkownika typu instancji, o które zostanie wyświetlony monit) w pliku Jenkinsfile. Kliknij link „wstrzymany”.
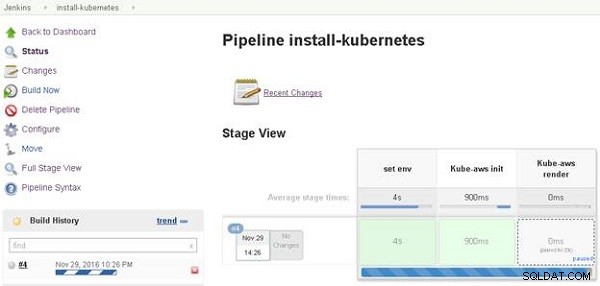
Rysunek 2: Uzyskiwanie publicznego adresu IP
W danych wyjściowych konsoli dla potoku Jenkins kliknij Żądane dane wejściowe link, jak pokazano na rysunku 3.
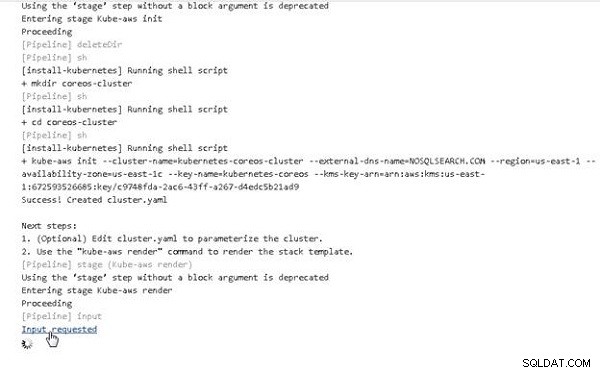
Rysunek 3: Żądanie danych wejściowych dla liczby węzłów
Liczba węzłów zostanie wyświetlone okno dialogowe z monitem o wprowadzenie przez użytkownika liczby węzłów, jak pokazano na rysunku 4. Ustawiona jest również domyślna wartość skonfigurowana w pliku Jenkinsfile. Kliknij Kontynuuj po określeniu wartości.
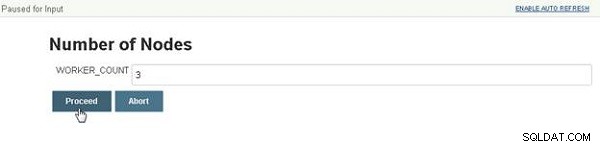
Rysunek 4: Określanie liczby węzłów
Potok kontynuuje działanie i ponownie zostaje wstrzymany przy kolejnym żądaniu wejściowym dla typu wystąpienia. Kliknij Poproszono o wprowadzenie , jak pokazano na rysunku 5.
Rysunek 5: Wymagane dane wejściowe dla typu wystąpienia
Typ wystąpienia zostanie wyświetlone okno dialogowe (patrz Rysunek 6). Wybierz wartość domyślną (lub określ inną) i kliknij Kontynuuj.

Rysunek 6: Określanie typu wystąpienia
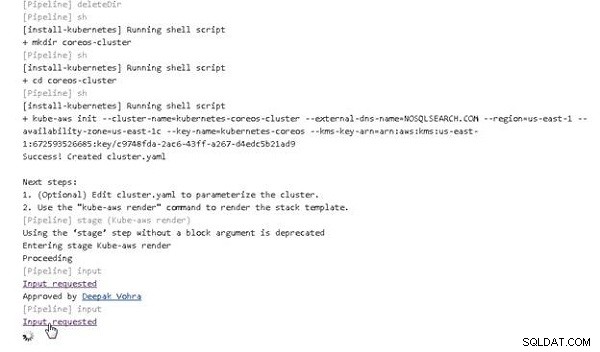
Rurociąg nadal działa. Na etapie wdrażania klastra prezentowane jest kolejne łącze żądania danych wejściowych, jak pokazano na rysunku 7. Kliknij łącze.
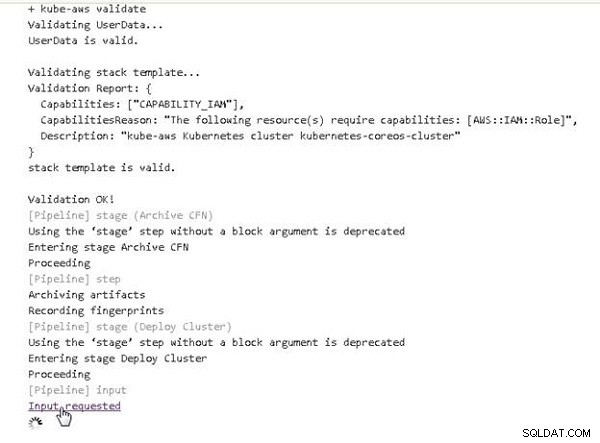
Rysunek 7: Wymagane dane wejściowe dotyczące wdrożenia klastra
W klastrze należy wdrożyć? wybierz domyślną wartość „tak” i kliknij Kontynuuj, jak pokazano na rysunku 8.
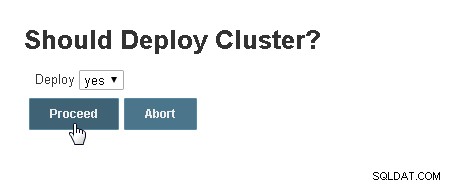
Rysunek 8: Czy należy wdrożyć klaster?
Rurociąg nadal działa. Tworzenie zasobów AWS dla klastra Kubernetes może trochę potrwać, jak wskazuje komunikat w danych wyjściowych konsoli pokazany na rysunku 9.
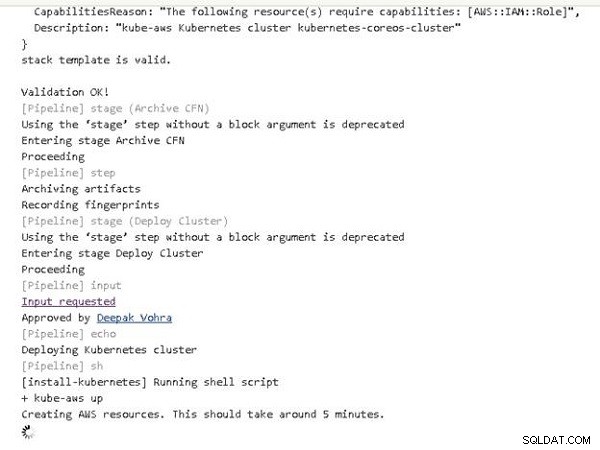
Rysunek 9: Tworzenie zasobów AWS
Rurociąg dobiega końca. Komunikat „SUCCESS” wskazuje, że potok został pomyślnie uruchomiony, jak pokazano na rysunku 10.

Rysunek 10: Jenkins Pipeline Run ukończony pomyślnie
Widok Stage dla potoku Jenkins wyświetla różne etapy ukończenia potoku, jak pokazano na rysunku 11. Widok Stage zawiera łącza dla Ostatniej kompilacji, Ostatniej stabilnej kompilacji, Ostatniej udanej kompilacji i Ostatniej ukończonej kompilacji.

Rysunek 11: Widok sceny
Kliknij Pełny widok sceny, aby osobno wyświetlić pełny widok sceny, jak pokazano na rysunku 12.
Rysunek 12: Wybór pełnego widoku sceny
Zostanie wyświetlony pełny widok sceny, jak pokazano na rysunku 13.
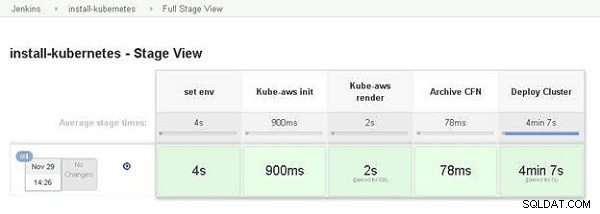
Rysunek 13: Pełny widok sceny
Na pulpicie nawigacyjnym ikona sąsiadująca z rurociągiem Jenkinsa zmienia kolor na zielony, aby wskazać pomyślne zakończenie, jak pokazano na rysunku 14.
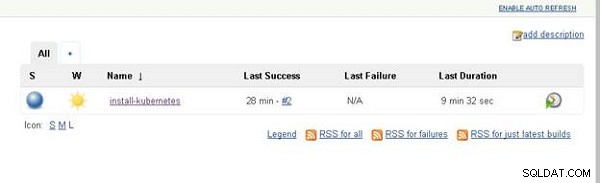
Rysunek 14: Pulpit nawigacyjny Jenkinsa z Jenkins Pipeline wymienionym jako zakończone pomyślnie
Aby wyświetlić dane wyjściowe konsoli, wybierz opcję Wyjście konsoli dla kompilacji, jak pokazano na rysunku 15.
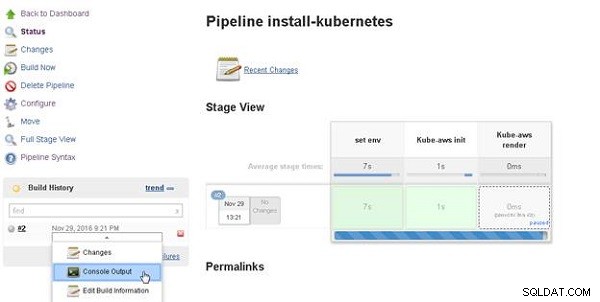
Rysunek 15: Historia kompilacji>Wyjście konsoli
Wyświetlone zostanie wyjście konsoli (patrz Rysunek 16).

Rysunek 16: Wyjście konsoli
Bardziej szczegółowe dane wyjściowe konsoli są wymienione w następującym segmencie kodu:
Started by user Deepak Vohra
[Pipeline] node
Running on jenkins in /var/jenkins/workspace/install-kubernetes
[Pipeline] {
[Pipeline] stage (set env)
Using the 'stage' step without a block argument is deprecated
Entering stage set env
Proceeding
[Pipeline] sh
[install-kubernetes] Running shell script
+ sudo yum install gnupg2
Loaded plugins: priorities, update-motd, upgrade-helper
Package gnupg2-2.0.28-1.30.amzn1.x86_64 already installed and
latest version
Nothing to do
[Pipeline] sh
[install-kubernetes] Running shell script
+ gpg2 --keyserver pgp.mit.edu --recv-key FC8A365E
gpg: directory '/home/ec2-user/.gnupg' created
gpg: new configuration file '/home/ec2-user/.gnupg/gpg.conf'
created
...
...
[Pipeline] sh
[install-kubernetes] Running shell script
+ gpg2 --fingerprint FC8A365E
pub 4096R/FC8A365E 2016-03-02 [expires: 2021-03-01]
Key fingerprint = 18AD 5014 C99E F7E3 BA5F 6CE9 50BD
D3E0 FC8A 365E
uid [ unknown] CoreOS Application Signing Key
<example@sqldat.com>
sub 2048R/3F1B2C87 2016-03-02 [expires: 2019-03-02]
sub 2048R/BEDDBA18 2016-03-08 [expires: 2019-03-08]
sub 2048R/7EF48FD3 2016-03-08 [expires: 2019-03-08]
[Pipeline] sh
[install-kubernetes] Running shell script
+ wget https://github.com/coreos/coreos-kubernetes/releases/
download/v0.7.1/kube-aws-linux-amd64.tar.gz
--2016-11-29 21:22:04-- https://github.com/coreos/
coreos-kubernetes/releases/download/v0.7.1/
kube-aws-linux-amd64.tar.gz
Resolving github.com (github.com)... 192.30.253.112,
192.30.253.113
Connecting to github.com (github.com)|192.30.253.112|:443...
connected.
HTTP request sent, awaiting response... 302 Found
Location: https://github-cloud.s3.amazonaws.com/releases/
41458519/309e294a-29b1-
...
...
2016-11-29 21:22:05 (62.5 MB/s) - 'kube-aws-linux-amd64.tar.gz'
saved [4655969/4655969]
[Pipeline] sh
[install-kubernetes] Running shell script
+ wget https://github.com/coreos/coreos-kubernetes/releases/
download/v0.7.1/kube-aws-linux-amd64.tar.gz.sig
--2016-11-29 21:22:05-- https://github.com/coreos/
coreos-kubernetes/releases/download/v0.7.1/kube-aws-linux-
amd64.tar.gz.sig
Resolving github.com (github.com)... 192.30.253.113,
192.30.253.112
Connecting to github.com (github.com)|192.30.253.113|:443...
connected.
HTTP request sent, awaiting response... 302 Found
Location: https://github-cloud.s3.amazonaws.com/releases/
41458519/0543b716-2bf4-
...
...
Saving to: 'kube-aws-linux-amd64.tar.gz.sig'
0K 100% 9.21M=0s
2016-11-29 21:22:05 (9.21 MB/s) -
'kube-aws-linux-amd64.tar.gz.sig' saved [287/287]
[Pipeline] sh
[install-kubernetes] Running shell script
+ gpg2 --verify kube-aws-linux-amd64.tar.gz.sig kube-aws-
linux-amd64.tar.gz
gpg: Signature made Mon 06 Jun 2016 09:32:47 PM UTC using RSA
key ID BEDDBA18
gpg: Good signature from "CoreOS Application Signing Key
<example@sqldat.com>" [unknown]
gpg: WARNING: This key is not certified with a trusted
signature!
gpg: There is no indication that the signature belongs to the
owner.
Primary key fingerprint: 18AD 5014 C99E F7E3 BA5F 6CE9 50BD
D3E0 FC8A 365E
Subkey fingerprint: 55DB DA91 BBE1 849E A27F E733 A6F7
1EE5 BEDD BA18
[Pipeline] sh
[install-kubernetes] Running shell script
+ tar zxvf kube-aws-linux-amd64.tar.gz
linux-amd64/
linux-amd64/kube-aws
[Pipeline] sh
[install-kubernetes] Running shell script
+ sudo mv linux-amd64/kube-aws /usr/local/bin
[Pipeline] sh
[install-kubernetes] Running shell script
...
...
[Pipeline] sh
[install-kubernetes] Running shell script
+ aws ec2 create-volume --availability-zone us-east-1c
--size 10 --volume-type gp2
{
"AvailabilityZone": "us-east-1c",
"Encrypted": false,
"VolumeType": "gp2",
"VolumeId": "vol-b325332f",
"State": "creating",
"Iops": 100,
"SnapshotId": "",
"CreateTime": "2016-11-29T21:22:07.949Z",
"Size": 10
}
[Pipeline] sh
[install-kubernetes] Running shell script
+ aws ec2 create-key-pair --key-name kubernetes-coreos
--query KeyMaterial --output text
[Pipeline] sh
[install-kubernetes] Running shell script
+ chmod 400 kubernetes-coreos.pem
[Pipeline] stage (Kube-aws init)
Using the 'stage' step without a block argument is deprecated
Entering stage Kube-aws init
Proceeding
[Pipeline] deleteDir
[Pipeline] sh
[install-kubernetes] Running shell script
+ mkdir coreos-cluster
[Pipeline] sh
[install-kubernetes] Running shell script
+ cd coreos-cluster
[Pipeline] sh
[install-kubernetes] Running shell script
+ kube-aws init --cluster-name=kubernetes-coreos-cluster
--external-dns-name=NOSQLSEARCH.COM --region=us-east-1
--availability-zone=us-east-1c --key-name=kubernetes-coreos
--kms-key-arn=arn:aws:kms:us-east-1:672593526685:key/
c9748fda-2ac6-43ff-a267-d4edc5b21ad9
Success! Created cluster.yaml
Next steps:
1. (Optional) Edit cluster.yaml to parameterize the cluster.
2. Use the "kube-aws render" command to render the stack
template.
[Pipeline] stage (Kube-aws render)
Using the 'stage' step without a block argument is deprecated
Entering stage Kube-aws render
Proceeding
[Pipeline] input
Input requested
Approved by Deepak Vohra
[Pipeline] input
Input requested
Approved by Deepak Vohra
[Pipeline] sh
[install-kubernetes] Running shell script
+ kube-aws render
Success! Stack rendered to stack-template.json.
Next steps:
1. (Optional) Validate your changes to cluster.yaml with
"kube-aws validate"
2. (Optional) Further customize the cluster by modifying
stack-template.json or files in ./userdata.
3. Start the cluster with "kube-aws up".
[Pipeline] sh
[install-kubernetes] Running shell script
+ sed -i 's/#workerCount: 1/workerCount: 3/' cluster.yaml
[Pipeline] sh
[install-kubernetes] Running shell script
+ sed -i 's/#workerInstanceType: m3.medium/
workerInstanceType: t2.micro/' cluster.yaml
[Pipeline] sh
[install-kubernetes] Running shell script
+ kube-aws validate
Validating UserData...
UserData is valid.
Validating stack template...
Validation Report: {
Capabilities: ["CAPABILITY_IAM"],
CapabilitiesReason: "The following resource(s) require
capabilities: [AWS::IAM::Role]",
Description: "kube-aws Kubernetes cluster
kubernetes-coreos-cluster"
}
stack template is valid.
Validation OK!
[Pipeline] stage (Archive CFN)
Using the 'stage' step without a block argument is deprecated
Entering stage Archive CFN
Proceeding
[Pipeline] step
Archiving artifacts
Recording fingerprints
[Pipeline] stage (Deploy Cluster)
Using the 'stage' step without a block argument is deprecated
Entering stage Deploy Cluster
Proceeding
[Pipeline] input
Input requested
Approved by Deepak Vohra
[Pipeline] echo
Deploying Kubernetes cluster
[Pipeline] sh
[install-kubernetes] Running shell script
+ kube-aws up
Creating AWS resources. This should take around 5 minutes.
Success! Your AWS resources have been created:
Cluster Name: kubernetes-coreos-cluster
Controller IP: 34.193.183.134
The containers that power your cluster are now being downloaded.
You should be able to access the Kubernetes API once the
containers finish downloading.
[Pipeline] sh
[install-kubernetes] Running shell script
+ kube-aws status
Cluster Name: kubernetes-coreos-cluster
Controller IP: 34.193.183.134
[Pipeline] step
Archiving artifacts
Recording fingerprints
[Pipeline] }
[Pipeline] // Node
[Pipeline] End of Pipeline
Finished: SUCCESS
Testowanie klastra Kubernetes
Po zainstalowaniu Kubernetes, następnie przetestujemy klaster uruchamiając jakąś aplikację. Najpierw musimy skonfigurować adres IP kontrolera w publicznej nazwie DNS (nosqlsearch.com domena). Skopiuj adres IP kontrolera z wyjścia konsoli, jak pokazano na rysunku 17.
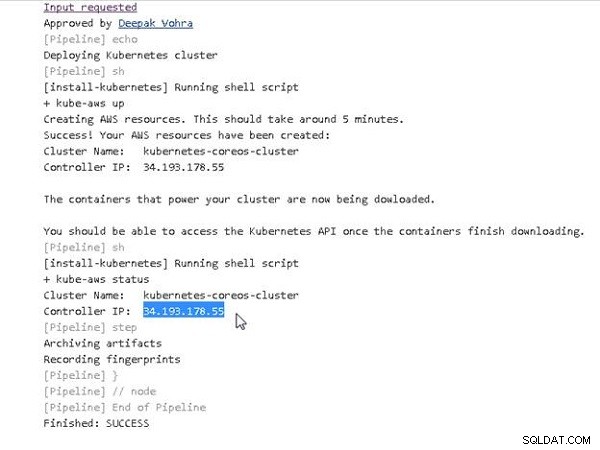
Rysunek 17: Uzyskiwanie publicznego adresu IP
Adres IP kontrolera Kubernetes można również uzyskać z konsoli EC2, jak pokazano na rysunku 18.
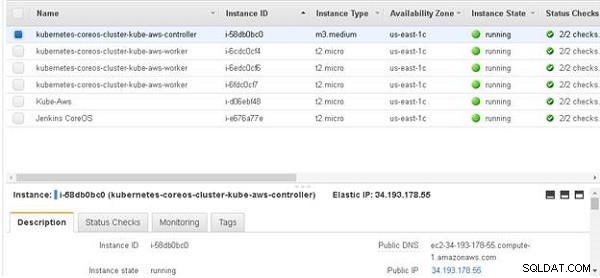
Rysunek 18: Uzyskiwanie adresu IP kontrolera Kubernetes
Dodaj wpis A (Host) do pliku strefy DNS dla domeny nosqlsearch.com u dostawcy hostingu, jak pokazano na rysunku 19. Dodanie rekordu A byłoby nieco inne dla różnych dostawców hostingu.
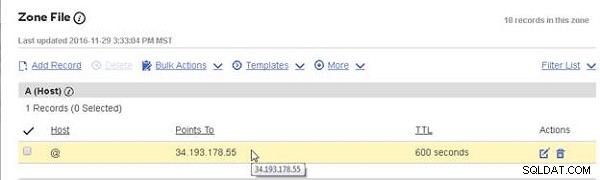
Rysunek 19: Uzyskiwanie publicznego adresu IP
SSH Zaloguj się do Kubernetes Master przy użyciu adresu IP Master.
ssh -i "kubernetes-coreos.pem" example@sqldat.com
Zostanie wyświetlony wiersz poleceń CoreOS, jak pokazano na rysunku 20.
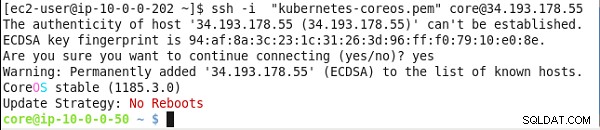
Rysunek 20: Uzyskiwanie publicznego adresu IP
Zainstaluj kubectl pliki binarne:
sudo wget https://storage.googleapis.com/kubernetes-release/ release/v1.3.0/bin/linux/amd64/./kubectl sudo chmod +x ./kubectl
Wymień węzły:
./kubectl get nodes
Węzły klastra Kubernetes zostaną wyświetlone (patrz Rysunek 21).
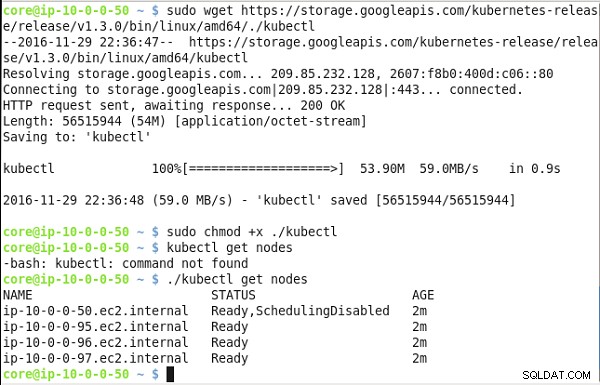
Rysunek 21: Uzyskiwanie publicznego adresu IP
Aby przetestować klaster, utwórz wdrożenie dla nginx składający się z trzech replik.
kubectl run nginx --image=nginx --replicas=3
Następnie wymień wdrożenia:
kubectl get deployments
Wdrożenie „nginx” powinno znaleźć się na liście, jak pokazano na rysunku 22.

Rysunek 22: Uzyskiwanie publicznego adresu IP
Wymień pody obejmujące cały klaster:
kubectl get pods -o wide
Utwórz usługę typu LoadBalancer z nginx wdrożenie:
kubectl expose deployment nginx --port=80 --type=LoadBalancer
Wymień usługi:
kubectl get services
Pody obejmujące cały klaster są wyświetlane na liście, jak pokazano na rysunku 23. Usługa „nginx” zostaje utworzona i wyświetlona wraz z adresem IP klastra i adresem IP zewnętrznym.
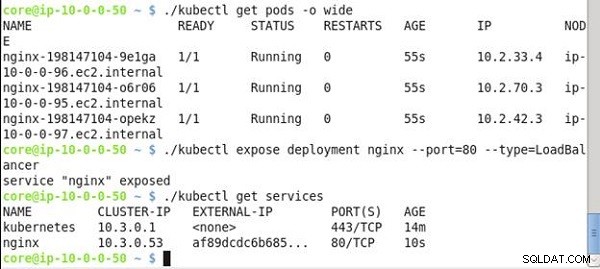
Rysunek 23: Uzyskiwanie publicznego adresu IP
Wywołaj nginx usługa na ip klastra. nginx Wyświetlany jest znacznik HTML wyjścia usługi, jak pokazano na rysunku 24.
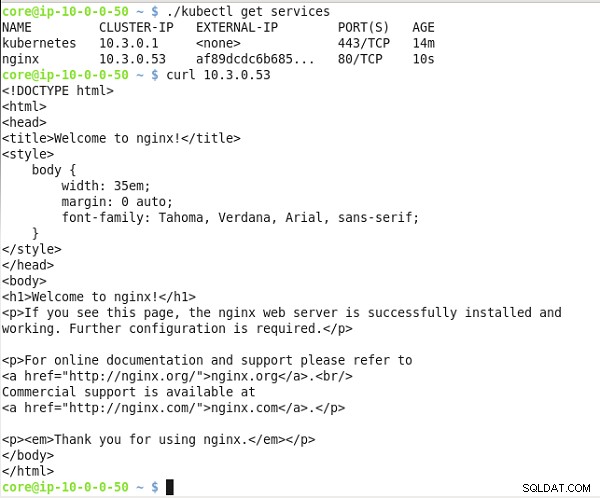
Rysunek 24: Uzyskiwanie publicznego adresu IP
Wniosek
W trzech artykułach omówiliśmy instalację klastra Kubernetes przy użyciu projektu Jenkins. Utworzyliśmy projekt Jenkins Pipeline z plikiem Jenkinsfile, aby zainstalować klaster. Potok Jenkins automatyzuje instalację Kubernetes, a ten sam potok Jenkins może zostać zmodyfikowany zgodnie z wymaganiami i ponownie uruchomiony, aby utworzyć wiele klastrów Kubernetes.