Spark rozpoczął działalność w 2009 roku jako projekt w ramach AMPLab na Uniwersytecie Kalifornijskim w Berkeley. Dokładniej, zrodził się z konieczności udowodnienia koncepcji Mesosa, który również powstał w AMPLabie. Spark został po raz pierwszy omówiony w białej księdze Mesos zatytułowanej Mesos:platforma do precyzyjnego udostępniania zasobów w centrum danych, napisanej w szczególności przez Benjamina Hindmana i Matei Zaharię.
Okazało się, że jest szybkim i wygodnym rozwiązaniem do przeprowadzania złożonej analizy danych o dużej skali. Spark ewoluował jako nowa platforma przetwarzania danych big data, która rozwiązuje wiele niedociągnięć w modelu MapReduce. Obsługuje analizę danych na dużą skalę, a dane mogą pochodzić z różnych źródeł, takich jak czas rzeczywisty, przetwarzanie wsadowe w różnych formatach, takich jak obrazy, teksty, wykresy i wiele innych. Oprócz rdzenia Apache Spark zapewnia również przydatny zestaw bibliotek do analizy dużych zbiorów danych.
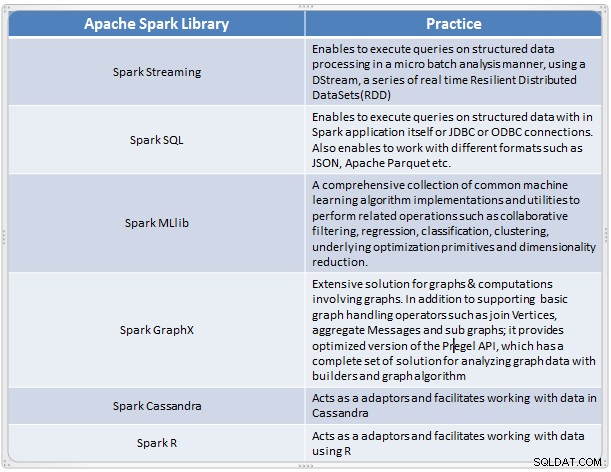
Przegląd komponentów Spark
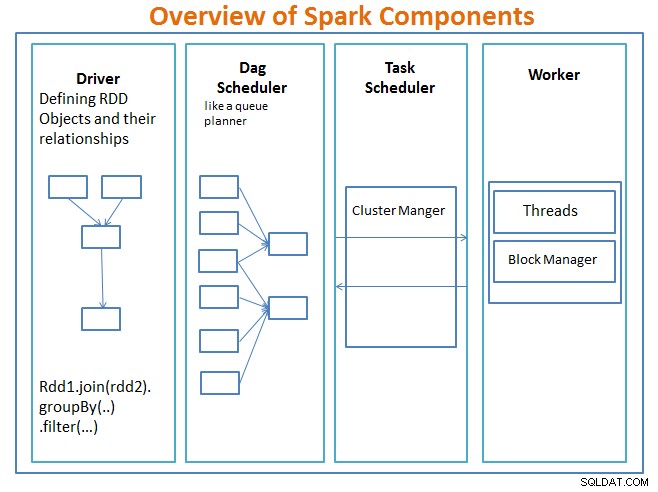
Kierowca to kod, który zawiera główną funkcję i definiuje odporne rozproszone zestawy danych (RDD) oraz ich przekształcenia. RDD to główne struktury danych, które będą używane w naszych programach Spark.
Operacje równoległe na RDD są wysyłane do programatora DAG , który zoptymalizuje kod i dotrze do wydajnego DAG, który reprezentuje etapy przetwarzania danych w aplikacji.
Wynikowy DAG jest wysyłany do menedżera klastra a menedżer klastra ma informacje o pracownikach, przydzielonych wątkach i lokalizacji bloków danych oraz jest odpowiedzialny za przypisywanie pracownikom określonych zadań przetwarzania. Zajmuje się również zwrotem kosztów w przypadku awarii pracownika. Menedżerem klastra może być YARN, Mesos, menedżer klastra Spark.
Pracownik otrzymuje jednostki pracy i dane do zarządzania, a pracownik wykonuje swoje określone zadanie bez znajomości całego DAG, a jego wyniki są wysyłane z powrotem do aplikacji kierowcy.
Spark, podobnie jak inne narzędzia Big Data, jest potężny, wydajny i dobrze nadaje się do radzenia sobie z różnymi wyzwaniami związanymi z danymi. Spark, podobnie jak inne technologie big data, niekoniecznie jest najlepszym wyborem dla każdego zadania przetwarzania danych.
W części 2 – omówimy podstawy pojęć Sparka, takie jak odporne rozproszone zestawy danych, zmienne współdzielone, SparkContext, transformacje, działanie , oraz Zalety używania Sparka wraz z przykładami i kiedy używać Sparka.
Odniesienie:
Naucz się Spark w jeden dzień dzięki architekturze aplikacji Acodemy i Hadoop.



