Informacje są jednym z najcenniejszych zasobów w firmie i jest rzeczą oczywistą, że należy mieć plan odzyskiwania po awarii (DRP), aby zapobiec utracie danych w razie wypadku lub awarii sprzętu. Kopia zapasowa to najprostsza forma DR. Może nie zawsze wystarczyć do zagwarantowania akceptowalnego celu punktu odzyskiwania (RPO), ale jest to dobre pierwsze podejście.
Niezależnie od tego, czy jest to mocno obciążony serwer 24x7, czy środowisko o niskim wolumenie transakcji, będziesz musiał tworzyć kopie zapasowe bezproblemową procedurą bez zakłócania wydajności serwera w środowisku produkcyjnym.
Jeśli mówimy o TimescaleDB, istnieją różne typy kopii zapasowych dla tego nowego silnika dla danych szeregów czasowych. Rodzaj kopii zapasowej, którego powinniśmy użyć, zależy od wielu czynników, takich jak środowisko, infrastruktura, obciążenie itp.
W tym blogu zobaczymy różne typy dostępnych kopii zapasowych oraz sposób, w jaki ClusterControl może pomóc nam scentralizować zarządzanie kopiami zapasowymi dla TimescaleDB.
Typy kopii zapasowych
Istnieją różne typy kopii zapasowych baz danych. Przyjrzyjmy się szczegółowo każdemu z nich.
- Logiczne:kopia zapasowa jest przechowywana w formacie czytelnym dla człowieka, takim jak SQL.
- Fizyczne:kopia zapasowa zawiera dane binarne.
- Pełna/Przyrostowa/Różnicowa:Definicja tych trzech typów kopii zapasowych jest zawarta w nazwie. Pełna kopia zapasowa to pełna kopia wszystkich Twoich danych. Przyrostowa kopia zapasowa tworzy kopie zapasowe tylko tych danych, które uległy zmianie od czasu utworzenia poprzedniej kopii zapasowej, a różnicowa kopia zapasowa zawiera tylko te dane, które uległy zmianie od ostatniego wykonania pełnej kopii zapasowej. Przyrostowe i różnicowe kopie zapasowe zostały wprowadzone jako sposób na zmniejszenie czasu i wykorzystania miejsca na dysku potrzebnego do wykonania pełnej kopii zapasowej.
- Zgodność z odzyskiwaniem punktu w czasie:PITR obejmuje przywracanie bazy danych w dowolnym momencie z przeszłości. Aby móc to zrobić, musimy przywrócić pełną kopię zapasową, a następnie zastosować wszystkie zmiany, które nastąpiły po utworzeniu kopii zapasowej, aż do momentu tuż przed awarią.
Funkcja zarządzania kopiami zapasowymi ClusterControl
Zobaczmy, jak ClusterControl może nam pomóc w zarządzaniu różnymi typami kopii zapasowych.
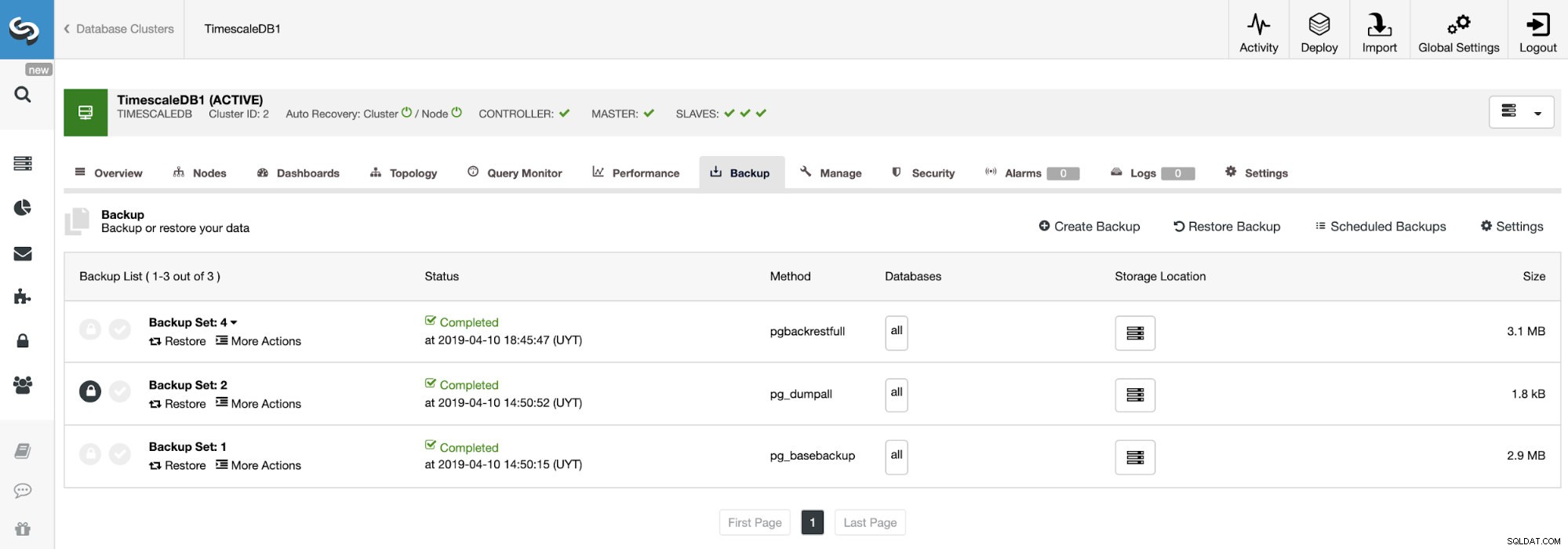
Tworzenie kopii zapasowej
W tym celu przejdź do ClusterControl -> Wybierz klaster TimescaleDB -> Kopia zapasowa -> Utwórz kopię zapasową .
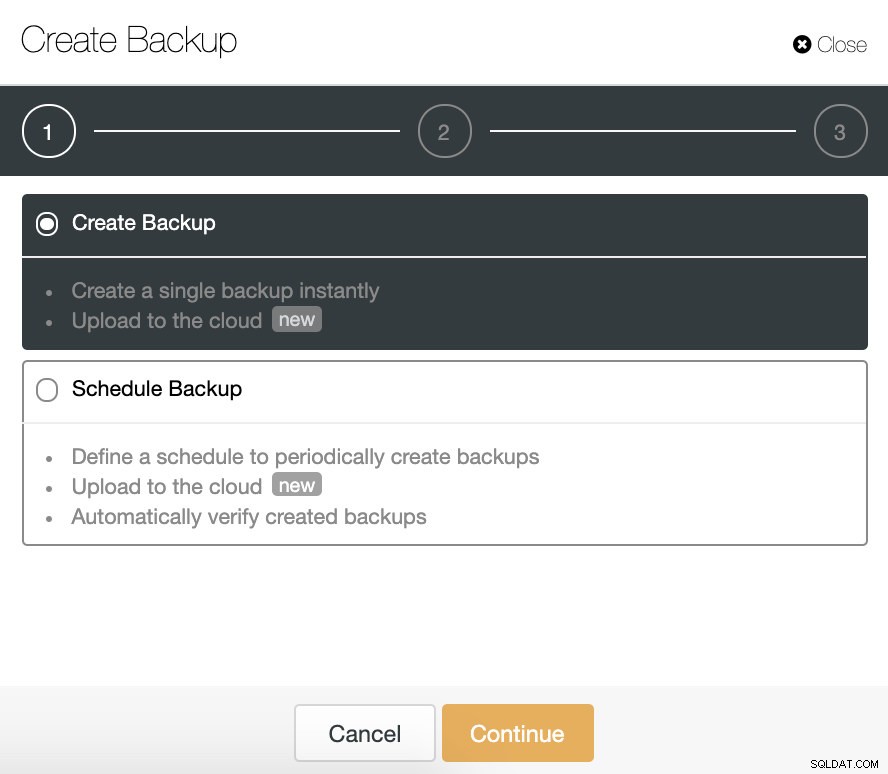
Możemy stworzyć nową kopię zapasową lub skonfigurować zaplanowaną. W naszym przykładzie natychmiast utworzymy pojedynczą kopię zapasową.
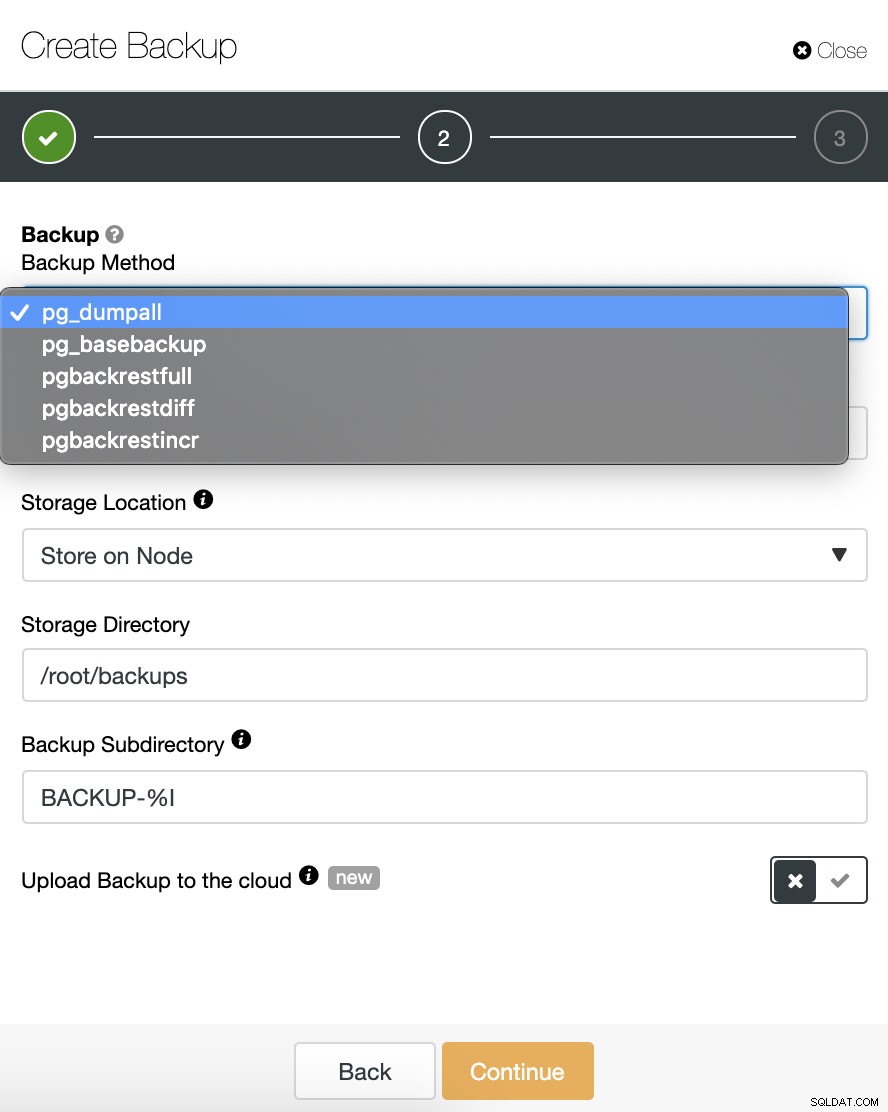
Tutaj mamy jedną metodę dla każdego typu kopii zapasowej, o której wspominaliśmy wcześniej.
| Typ kopii zapasowej | Narzędzie | Definicja |
|---|---|---|
| logiczne | pg_dumpall | Jest to narzędzie do zapisywania wszystkich baz danych TimescaleDB klastra w jednym pliku skryptu. Plik skryptu zawiera polecenia SQL, których można użyć do przywrócenia baz danych. |
| Fizyczne | pg_basebackup | Służy do tworzenia binarnej kopii plików klastra bazy danych, przy jednoczesnym upewnieniu się, że system jest automatycznie włączany i wyłączany z trybu tworzenia kopii zapasowej. Kopie zapasowe są zawsze wykonywane z całego klastra bazy danych działającego klastra bazy danych TimescaleDB. Są one pobierane bez wpływu na innych klientów w bazie danych. |
| Pełny/Przyrost/Różnica | pgbackrest | Jest to proste, niezawodne rozwiązanie do tworzenia kopii zapasowych i przywracania danych, które można bezproblemowo skalować do największych baz danych i obciążeń dzięki wykorzystaniu algorytmów zoptymalizowanych pod kątem wymagań specyficznych dla bazy danych. Jedną z najważniejszych funkcji jest obsługa pełnych, przyrostowych i różnicowych kopii zapasowych. |
| PITR | pg_basebackup+WAL | Aby utworzyć kopię zapasową zgodną z PITR, ClusterControl użyje pg_basebackup i plików WAL, aby móc przywrócić bazę danych w dowolnym momencie w przeszłości. |
Musimy wybrać jedną metodę, serwer, z którego zostanie pobrana kopia zapasowa i gdzie chcemy przechowywać kopię zapasową. Możemy również przesłać naszą kopię zapasową do chmury (AWS, Google lub Azure), włączając odpowiedni przycisk.
Pamiętaj, że jeśli chcesz utworzyć kopię zapasową zgodną z PITR, musimy w tym kroku użyć pg_basebackup i pobrać kopię zapasową z węzła głównego.
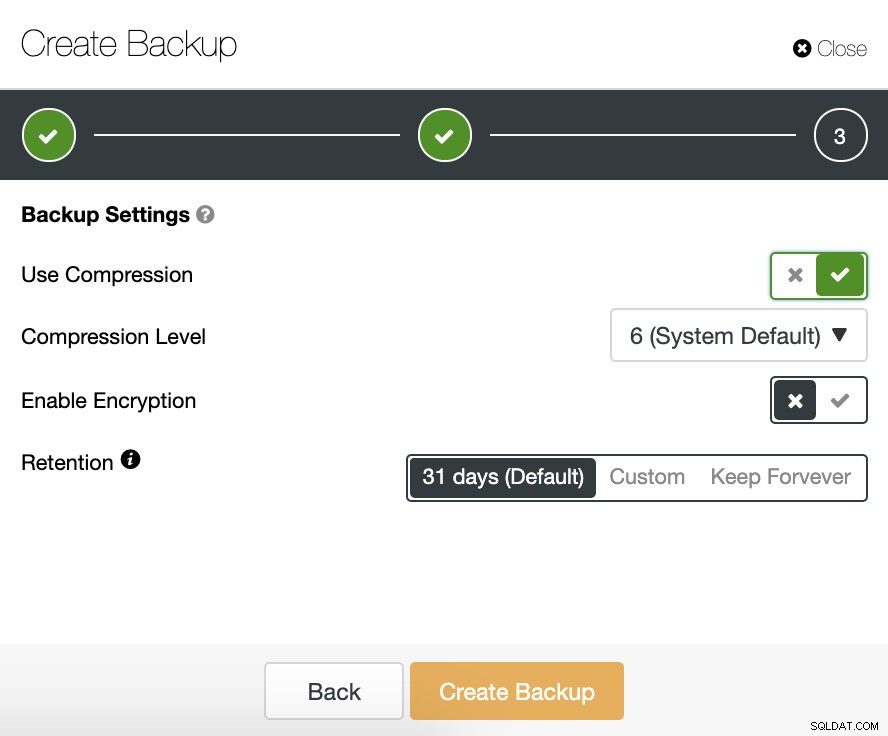
Następnie określamy użycie kompresji, szyfrowania i przechowywania naszej kopii zapasowej.
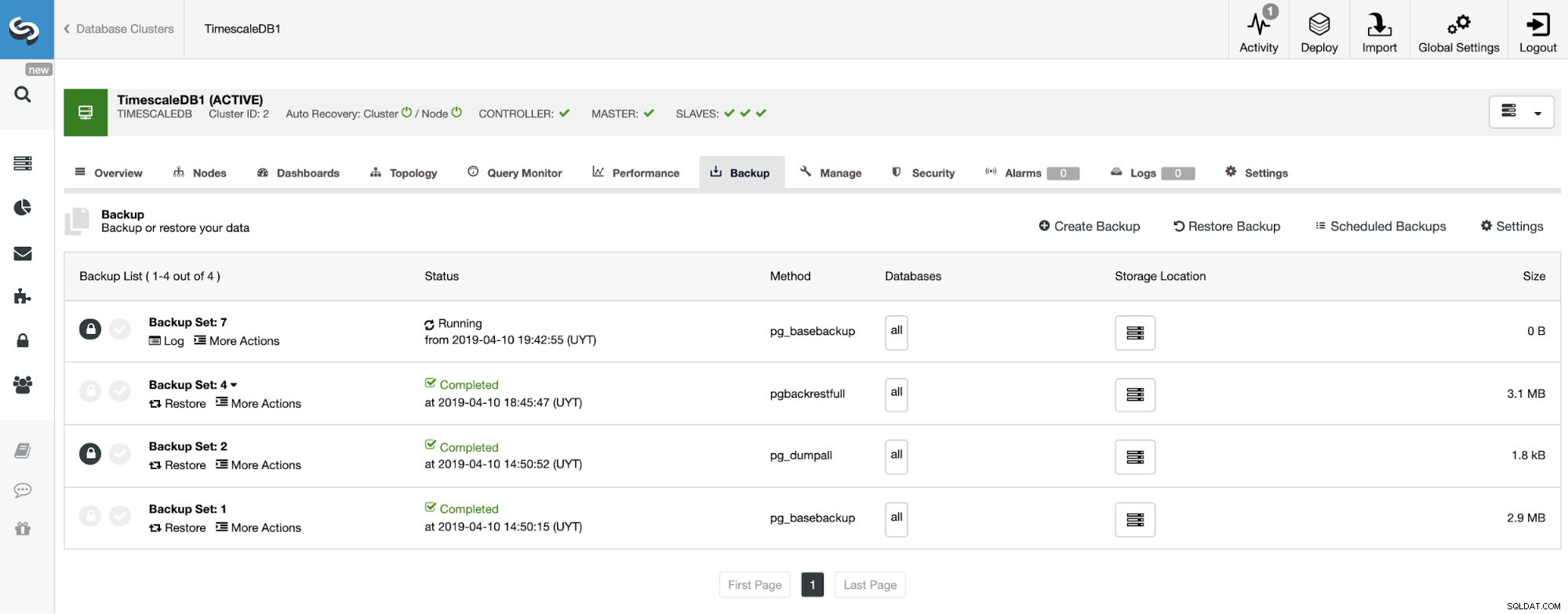
W sekcji kopii zapasowej możemy zobaczyć postęp tworzenia kopii zapasowej oraz informacje, takie jak metoda, rozmiar, lokalizacja i inne.
Włączanie odzyskiwania do punktu w czasie
Jeśli chcemy skorzystać z funkcji PITR, musimy mieć włączoną archiwizację WAL. W tym celu możemy przejść do ClusterControl -> Wybierz klaster TimescaleDB -> Akcje węzła -> Włącz archiwizację WAL lub po prostu przejdź do ClusterControl -> Wybierz klaster TimescaleDB -> Kopia zapasowa -> Ustawienia i włącz opcję „Włącz odzyskiwanie do określonego momentu (archiwizacja WAL) ” jak zobaczymy na poniższym obrazku.
Musimy pamiętać, że aby włączyć Archiwizację WAL, musimy zrestartować naszą bazę danych. ClusterControl może to zrobić również za nas.
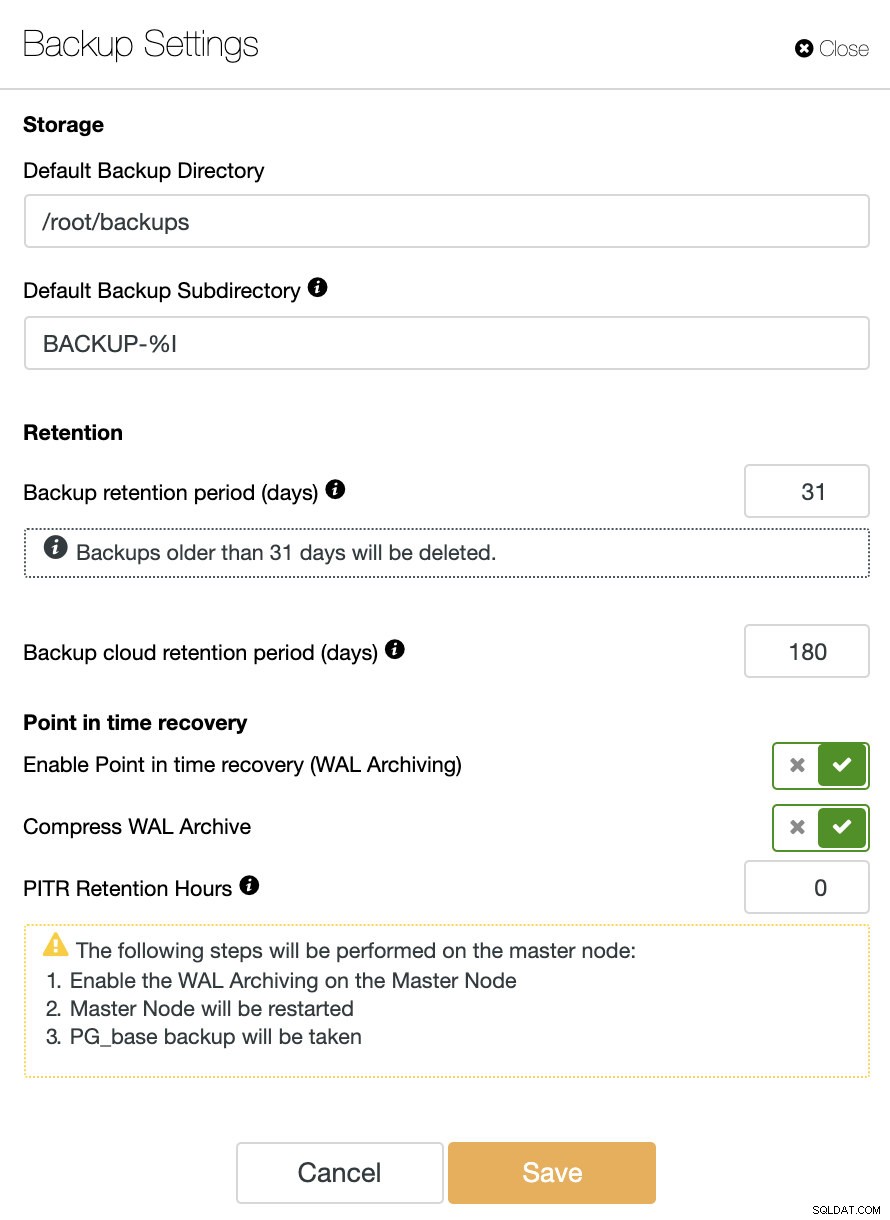
Oprócz opcji wspólnych dla wszystkich kopii zapasowych, takich jak „Katalog kopii zapasowych ” i „Okres przechowywania kopii zapasowych ”, tutaj możemy również określić Okres przechowywania WAL. Domyślnie jest to 0, co oznacza na zawsze.
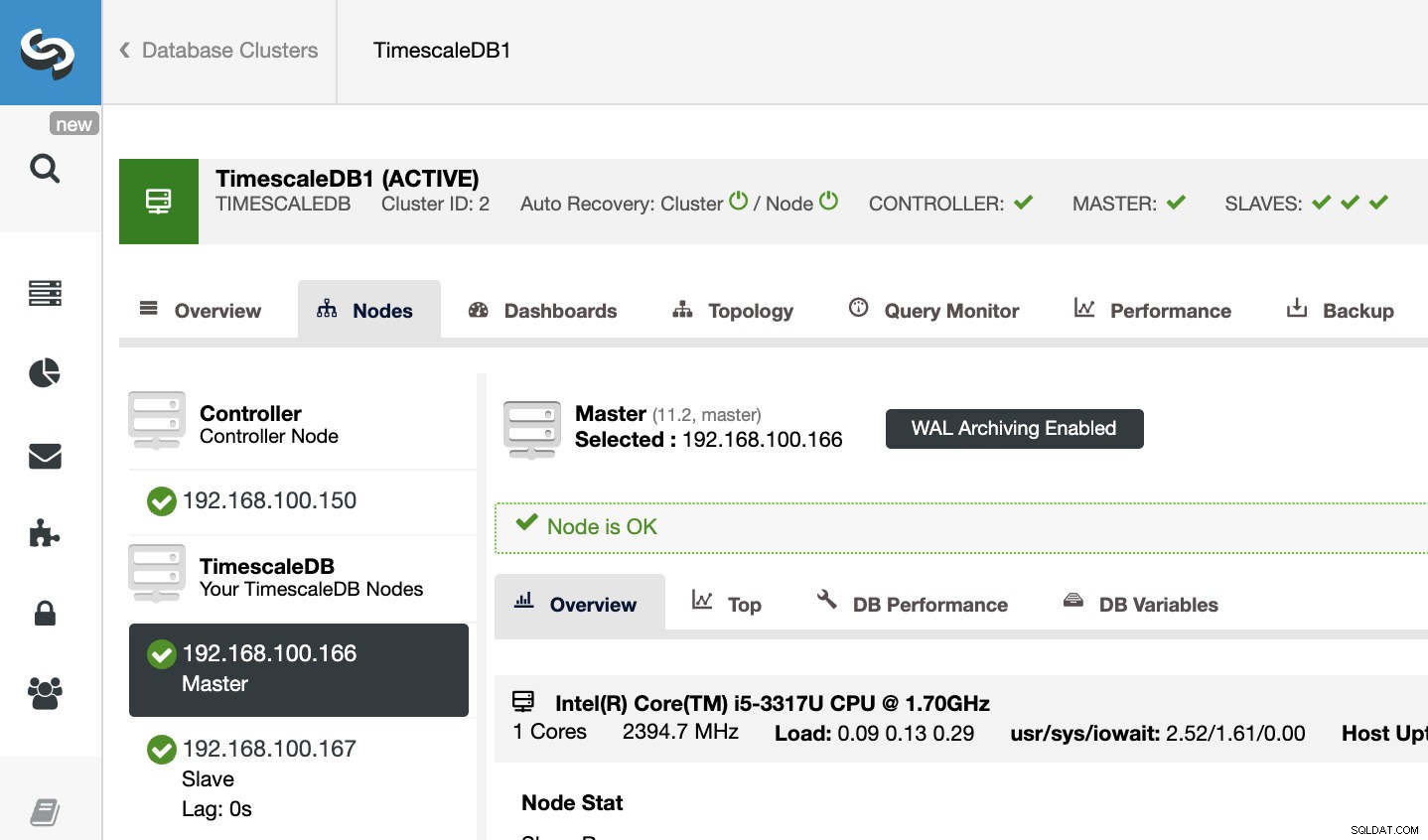
Aby potwierdzić, że mamy włączoną archiwizację WAL, możemy wybrać nasz węzeł główny w ClusterControl -> Wybierz klaster TimescaleDB -> Węzły i powinniśmy zobaczyć komunikat WAL Archiwizacja włączona, jak widać na poniższym obrazku.
Przywracanie kopii zapasowej
Po zakończeniu tworzenia kopii zapasowej możemy ją przywrócić za pomocą ClusterControl. W tym celu w naszej sekcji kopii zapasowej (ClusterControl -> Wybierz klaster TimescaleDB -> Kopia zapasowa) ), możemy wybrać „Przywróć kopię zapasową” lub bezpośrednio „Przywróć” w kopii zapasowej, którą chcemy przywrócić.
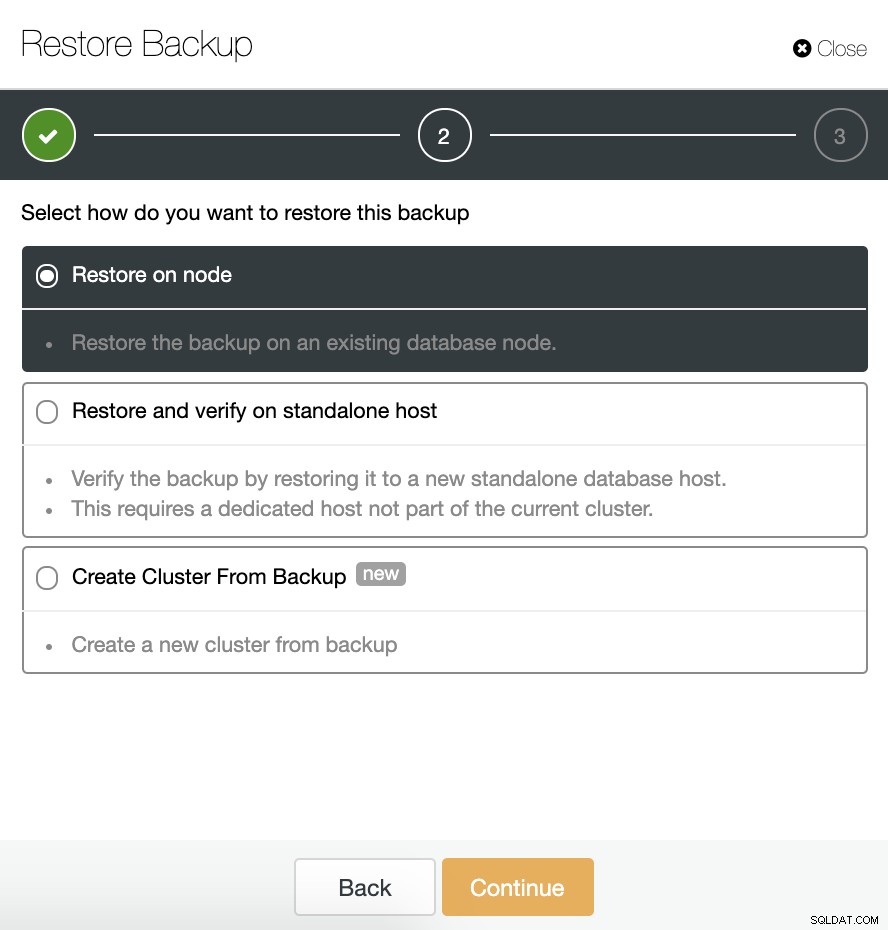
Mamy trzy opcje przywrócenia kopii zapasowej. Możemy przywrócić kopię zapasową w istniejącym węźle bazy danych, przywrócić i zweryfikować kopię zapasową na samodzielnym hoście lub utworzyć nowy klaster z kopii zapasowej.
Jeśli próbujemy przywrócić kopię zapasową zgodną z PITR, musimy również określić czas.
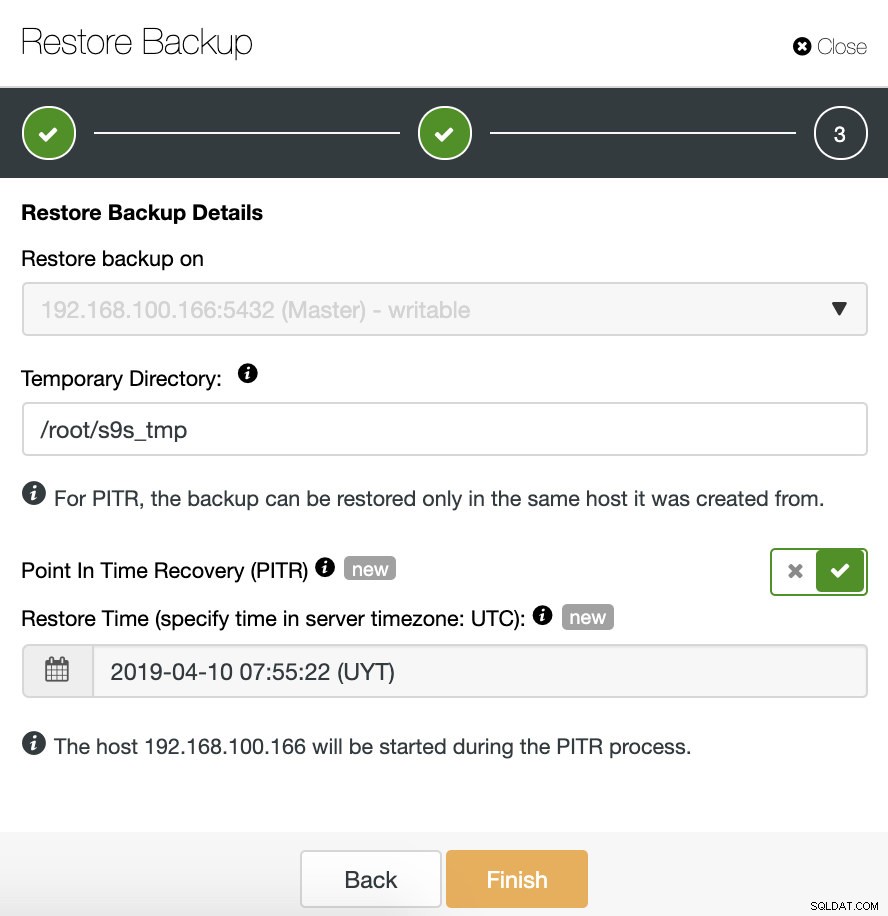
Dane zostaną przywrócone tak, jak w określonym czasie. Weź pod uwagę, że używana jest strefa czasowa UTC i że nasza usługa TimescaleDB w systemie głównym zostanie ponownie uruchomiona.
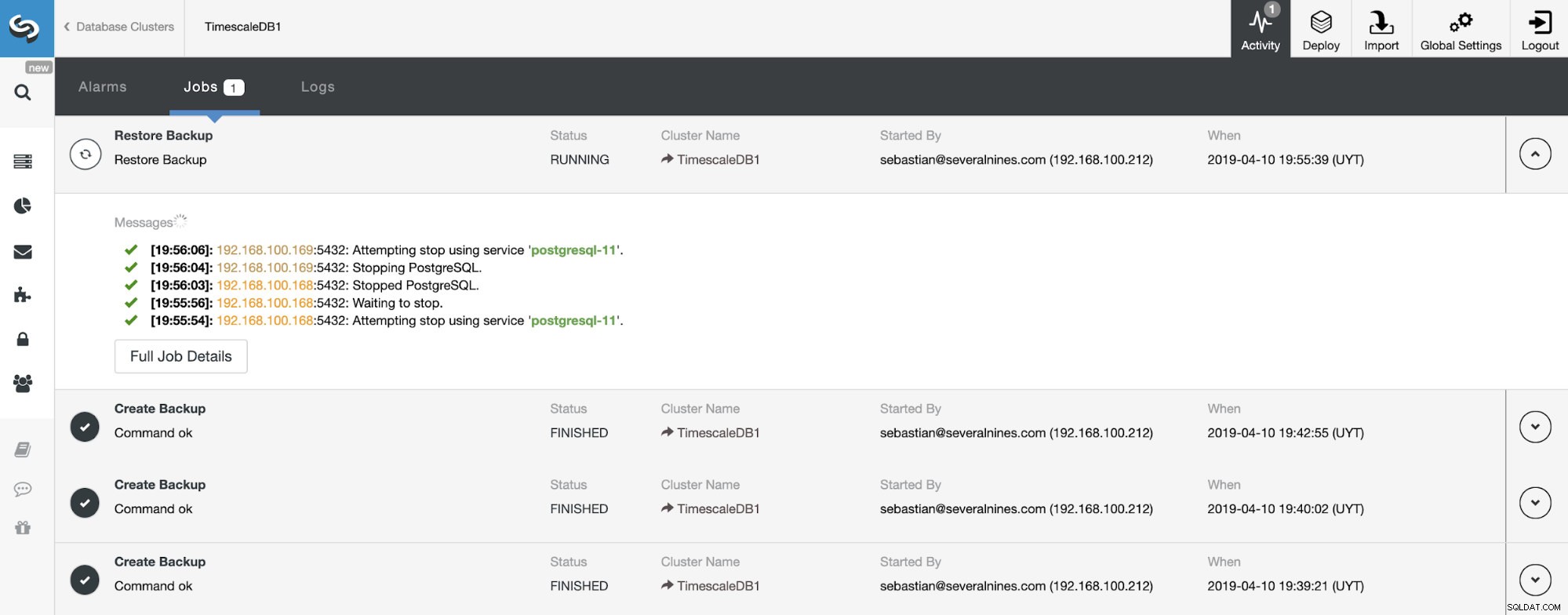
Możemy monitorować postęp naszego przywracania w sekcji Aktywność w naszym ClusterControl.
Automatyczna weryfikacja kopii zapasowej
Kopia zapasowa nie jest kopią zapasową, jeśli nie można jej przywrócić. Weryfikowanie kopii zapasowych to coś, co zwykle jest przez wielu zaniedbywane. Zobaczmy, jak ClusterControl może zautomatyzować weryfikację kopii zapasowych TimescaleDB i pomóc uniknąć niespodzianek.
W ClusterControl wybierz swój klaster i przejdź do „Kopia zapasowa ”, a następnie wybierz „Utwórz kopię zapasową ”.
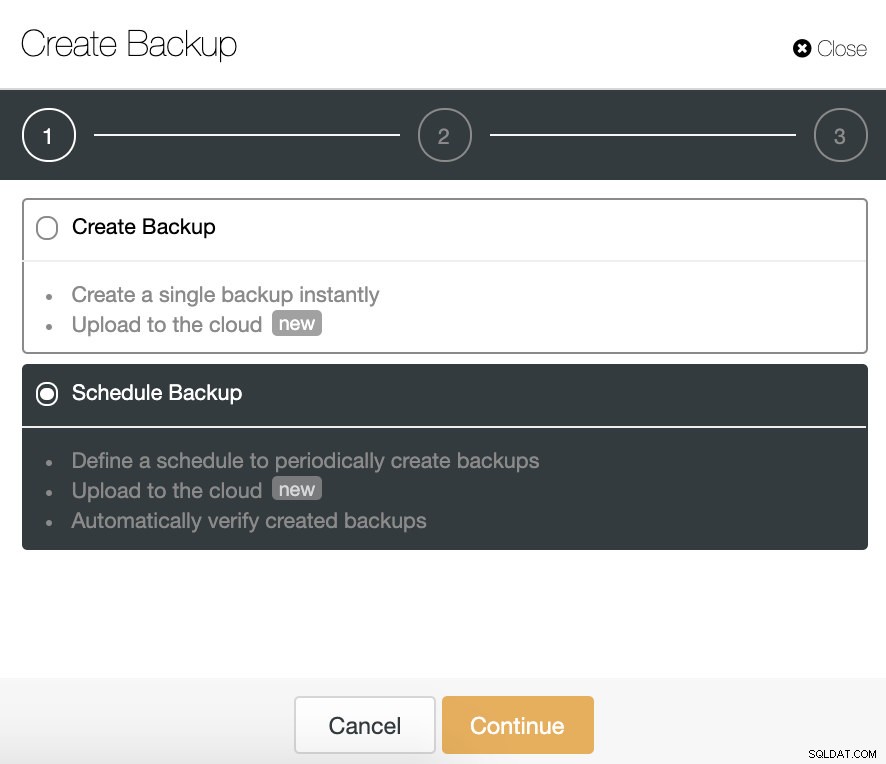
Funkcja automatycznej weryfikacji kopii zapasowej jest dostępna dla zaplanowanych kopii zapasowych. Wybierzmy więc „Zaplanuj tworzenie kopii zapasowych ” opcja.
Podczas planowania kopii zapasowej, oprócz wybrania typowych opcji, takich jak metoda lub pamięć, musimy również określić harmonogram/częstotliwość.
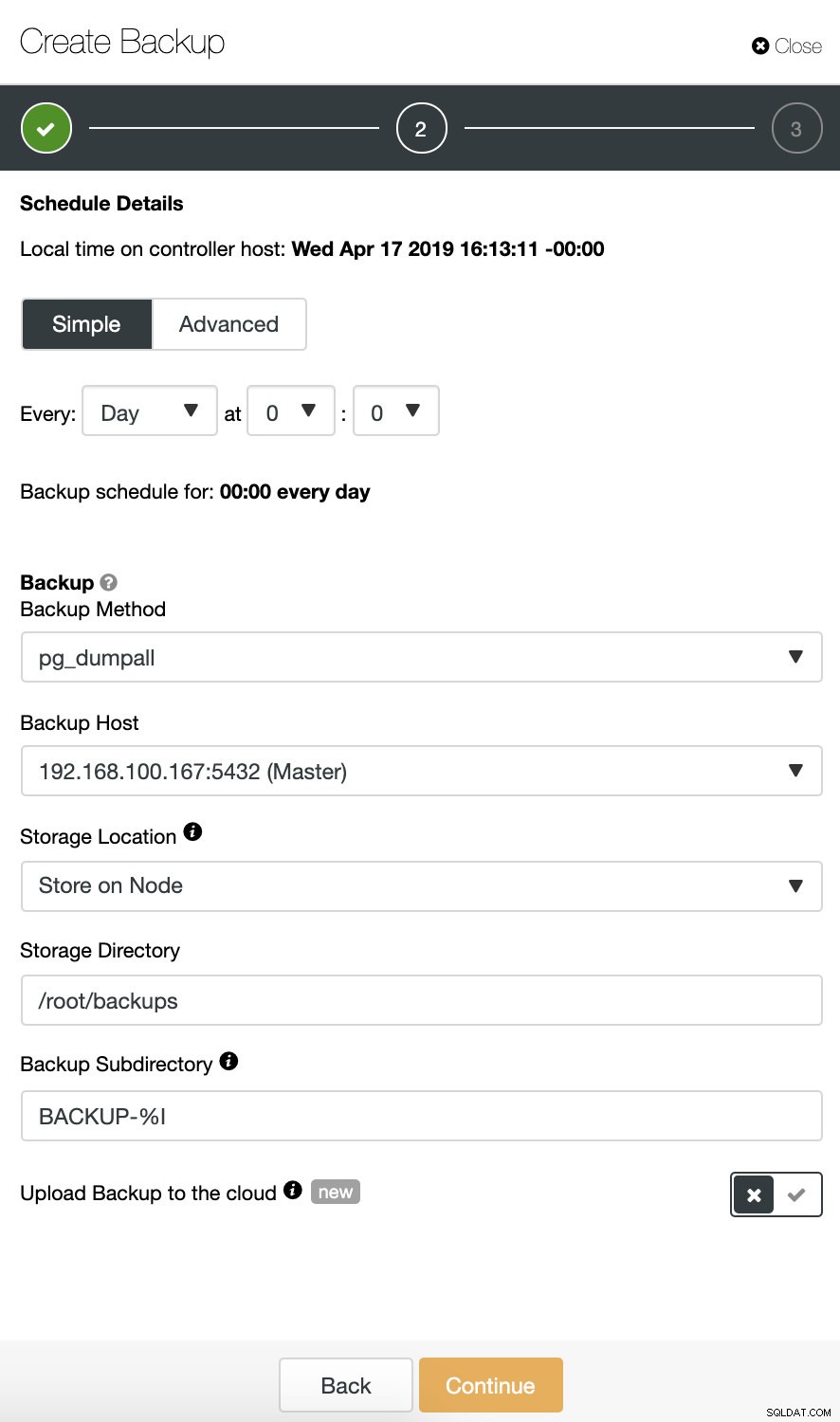
W kolejnym kroku możemy skompresować i zaszyfrować naszą kopię zapasową oraz określić okres przechowywania. Tutaj mamy również opcję „Zweryfikuj kopię zapasową ” funkcja.
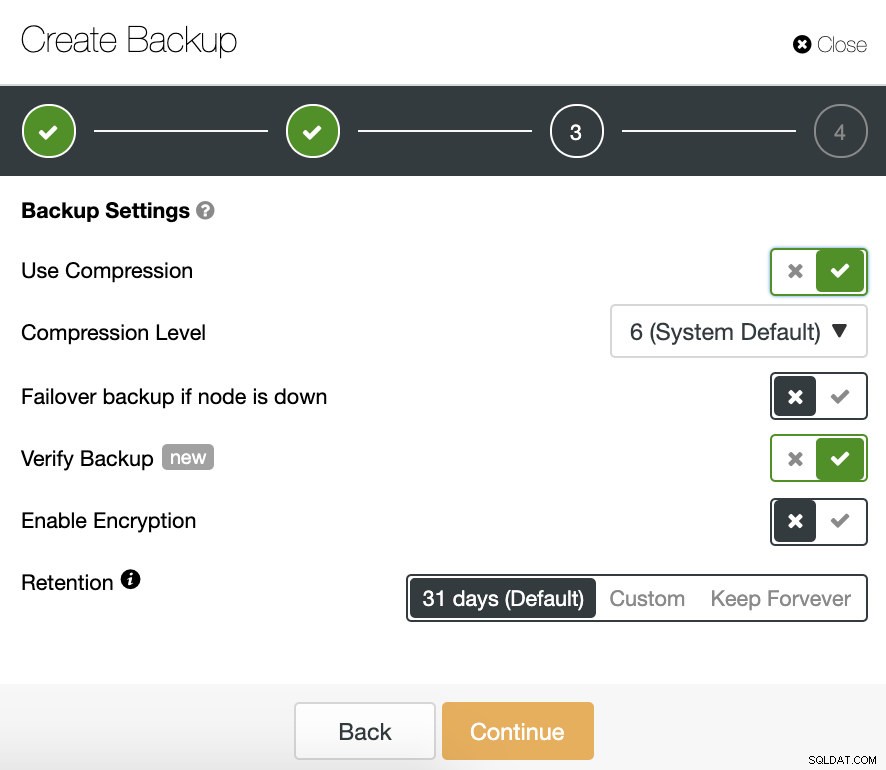
Aby korzystać z tej funkcji, potrzebujemy dedykowanego hosta (lub maszyny wirtualnej), który nie jest częścią klastra.
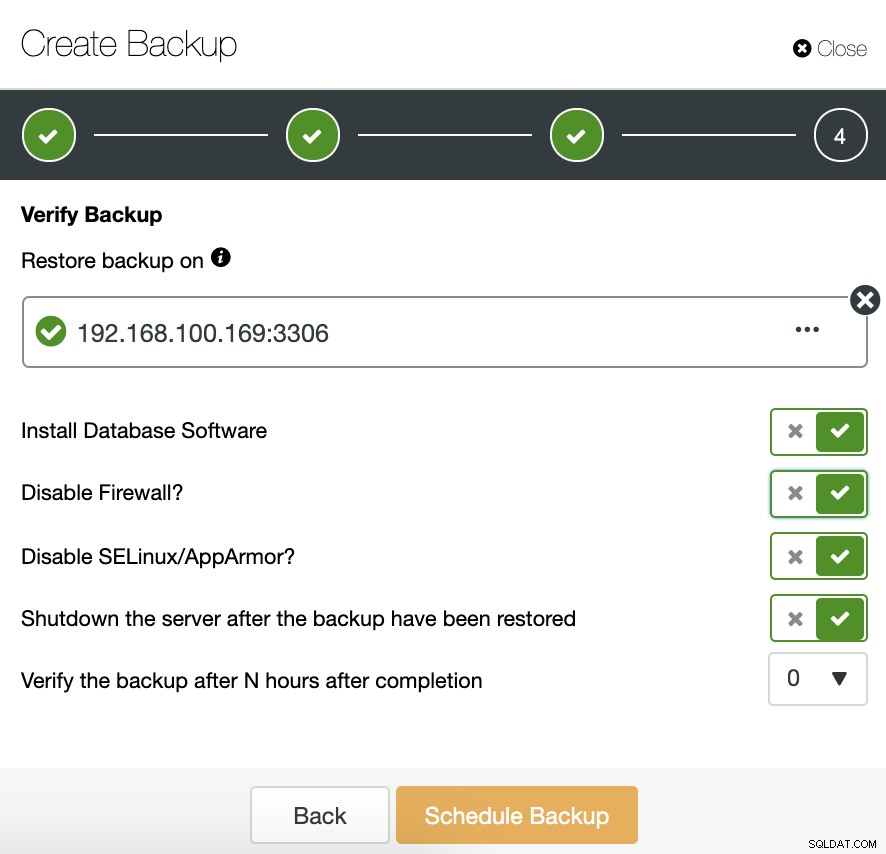
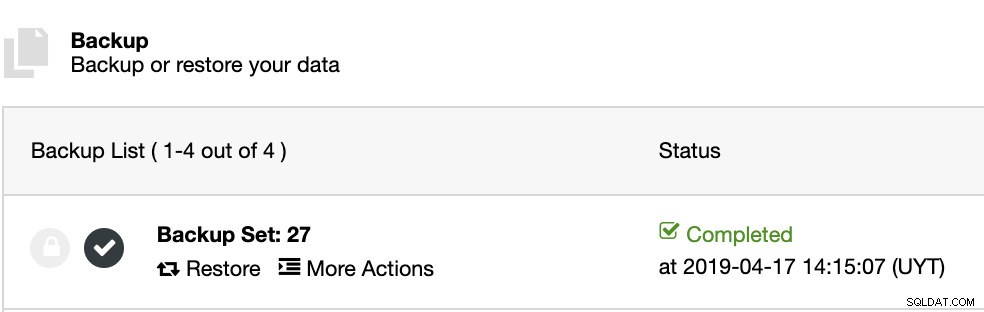
ClusterControl zainstaluje oprogramowanie i przywróci kopię zapasową na tym hoście. Po przywróceniu widzimy ikonę weryfikacji w sekcji ClusterControl Backup.
Wniosek
W dzisiejszych czasach tworzenie kopii zapasowych jest obowiązkowe w każdym środowisku. Pomagają chronić Twoje dane. Przyrostowe kopie zapasowe mogą pomóc w skróceniu czasu i przestrzeni dyskowej używanej w procesie tworzenia kopii zapasowej. Dzienniki transakcji są ważne dla odzyskiwania punktu w czasie. ClusterControl może pomóc zautomatyzować proces tworzenia kopii zapasowej baz danych TimescaleDB, a w przypadku awarii przywrócić go kilkoma kliknięciami. Możesz także zminimalizować RPO, korzystając z kopii zapasowej zgodnej z PITR i ulepszyć swój plan odzyskiwania po awarii.