ClusterControl to łatwe w użyciu narzędzie do monitorowania wydajności TimescaleDB w czasie rzeczywistym. Udostępnia dziesiątki predefiniowanych wykresów do wyświetlania różnorodnych statystyk wydajności dotyczących na przykład użytkowników, przepustowości, obszarów tabel, dzienników przeróbek, buforów, pamięci podręcznych i operacji we/wy. Dostarcza również informacji w czasie rzeczywistym o obciążeniu bazy danych. Mój kolega Sebastian pisał wcześniej o tym, jak łatwo wdrożyć TimescaleDB. W tym blogu pokażemy, jak monitorować różne aspekty wydajności TimescaleDB za pomocą ClusterControl. Przede wszystkim pozwól, że przedstawię krótkie wprowadzenie na temat TimescaleDB.
TimescaleDB jest zaimplementowany jako rozszerzenie PostgreSQL, co oznacza, że baza danych Timescale działa w ramach instancji PostgreSQL. Model rozszerzenia umożliwia bazie danych korzystanie z wielu atrybutów PostgreSQL, takich jak niezawodność, bezpieczeństwo i łączność z szeroką gamą narzędzi innych firm. Jednocześnie TimescaleDB wykorzystuje wysoki stopień dostosowania dostępny dla rozszerzeń, dodając hooki głęboko do planowania zapytań, modelu danych i silnika wykonawczego PostgreSQL. Jego ekosystem mówi językiem ojczystym PostgreSQL i dodaje wyspecjalizowane funkcje (i optymalizacje zapytań) do pracy z danymi szeregów czasowych. Jedną z zalet TimescaleDB w porównaniu z innymi wyspecjalizowanymi magazynami danych do przechowywania danych IoT lub danych szeregów czasowych jest to, że można używać składni SQL, co oznacza, że można korzystać z funkcji JOIN. Zatem wyszukiwanie różnorodnych metadanych jest łatwiejsze dla programistów – upraszcza to ich stos i eliminuje silosy danych.
TimescaleDB został przetestowany i porównany z setkami miliardów wierszy i skaluje się bardzo dobrze – zwłaszcza z upsertami lub insertami w porównaniu z waniliowym PostgreSQL. Jeśli interesują Cię ich narzędzia do testów porównawczych, możesz rozważyć przyjrzenie się ich pakietowi Time Series Benchmark Suite (TSBS).
Korzystanie z bazy danych TimescaleDB jest dość łatwe, jeśli znasz RDBMS, taki jak MySQL lub PostgreSQL. Musisz określić swoją bazę danych i utworzyć rozszerzenie dla TimescaleDB. Po utworzeniu tworzysz Hypertable, który wirtualnie obsługuje wszystkie interakcje użytkownika z TimescaleDB. Zobacz przykład poniżej:
nyc_data=# CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;
WARNING:
WELCOME TO
_____ _ _ ____________
|_ _(_) | | | _ \ ___ \
| | _ _ __ ___ ___ ___ ___ __ _| | ___| | | | |_/ /
| | | | _ ` _ \ / _ \/ __|/ __/ _` | |/ _ \ | | | ___ \
| | | | | | | | | __/\__ \ (_| (_| | | __/ |/ /| |_/ /
|_| |_|_| |_| |_|\___||___/\___\__,_|_|\___|___/ \____/
Running version 1.2.2
For more information on TimescaleDB, please visit the following links:
1. Getting started: https://docs.timescale.com/getting-started
2. API reference documentation: https://docs.timescale.com/api
3. How TimescaleDB is designed: https://docs.timescale.com/introduction/architecture
Note: TimescaleDB collects anonymous reports to better understand and assist our users.
For more information and how to disable, please see our docs https://docs.timescaledb.com/using-timescaledb/telemetry.
CREATE EXTENSION
nyc_data=# SELECT create_hypertable('rides_count', 'one_hour');
create_hypertable
--------------------------
(1,public,rides_count,t)
(1 row)Proste. Jednak, gdy dane staną się duże, możesz zadać sobie następujące pytanie:„Jak monitorować wydajność TimescaleDB”? Cóż, o to właśnie chodzi w naszym blogu. Zobaczmy, jak możesz to zrobić za pomocą ClusterControl.
Monitorowanie klastrów DB skali czasu
Monitorowanie klastra TimescaleDB w ClusterControl jest prawie takie samo, jak monitorowanie klastra bazy danych PostgreSQL. Mamy wykresy klastrów i węzłów, pulpity nawigacyjne, topologie, monitorowanie zapytań i wydajność. Przyjrzyjmy się każdemu z nich.
Karta „Przegląd”
Wykresy przeglądu można znaleźć, przechodząc do Klaster → Przegląd zakładka.
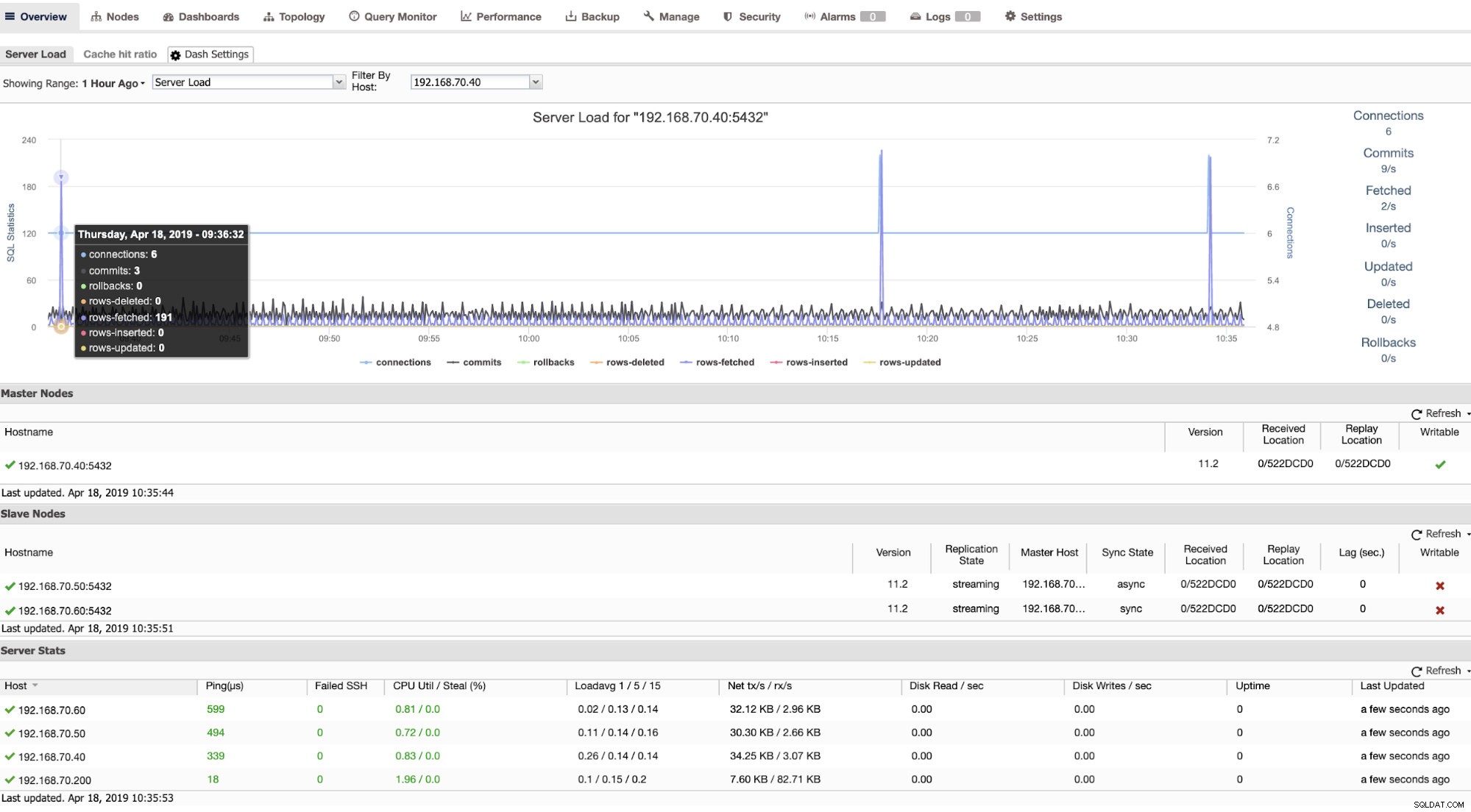
W tym widoku możesz zobaczyć obciążenie serwera, współczynnik trafień w pamięci podręcznej lub filtrować według innych metryk - trafienie bloków, odczytanie bloków, zatwierdzenia lub liczba połączeń.
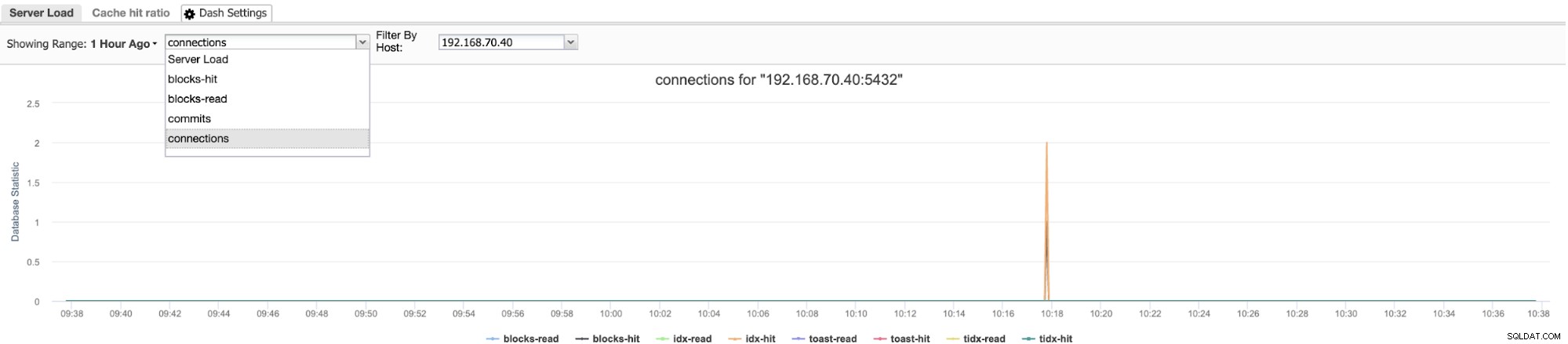
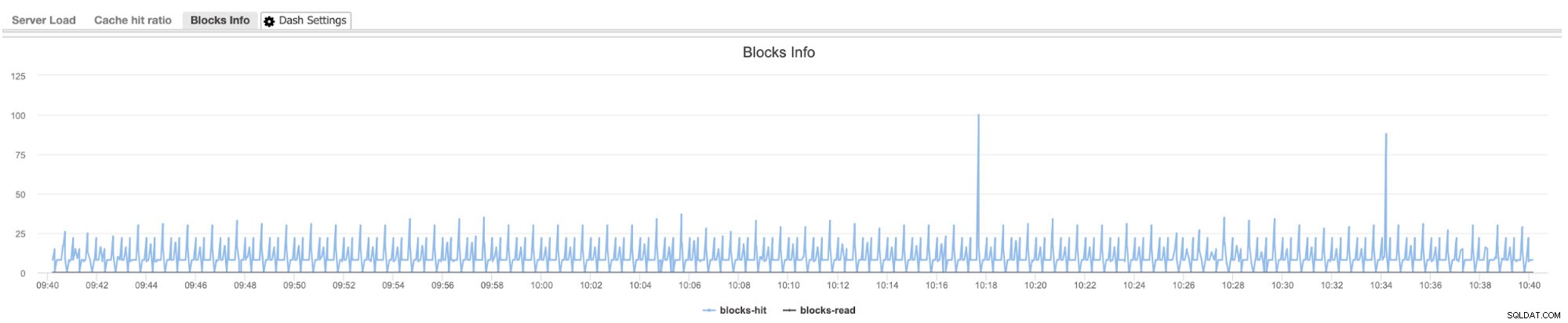
Możesz także utworzyć tutaj niestandardowe ustawienia pulpitu nawigacyjnego, tak jak mój przykład poniżej, który pobiera bloki trafienia i bloki odczytu.
To dobre miejsce do rozpoczęcia, a także monitorowania aktywności sieciowej, sprawdzania przesyłania i odbierania pakietów.
Karta „Węzły”
Wykresy węzłów można zlokalizować, przechodząc do Klaster → Węzły patka. Zawiera szczegółowy widok węzłów wraz z metrykami na poziomie hosta i bazy danych. Zobacz poniższy wykres:
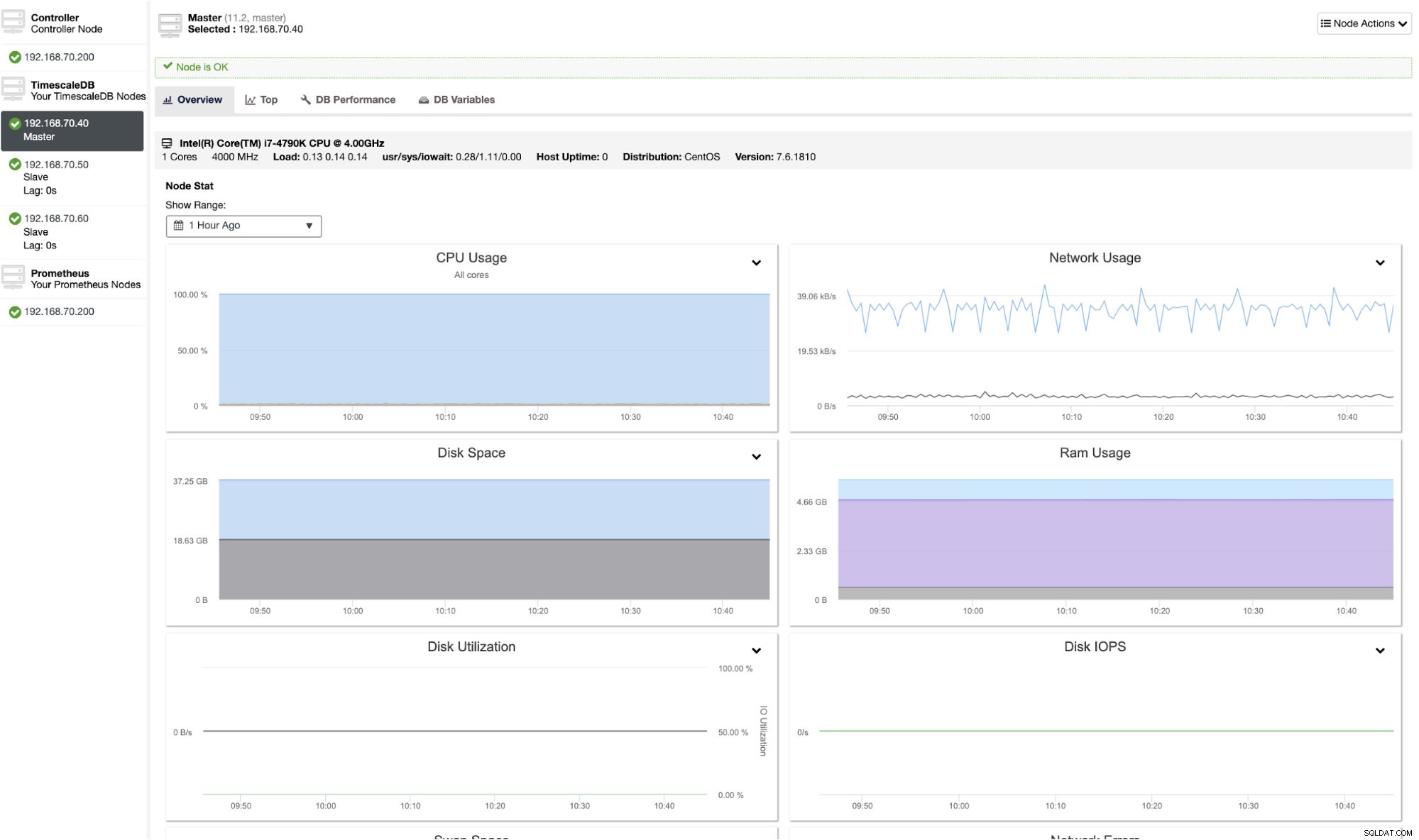
Możesz również sprawdzić najważniejsze procesy działające w systemie hosta, klikając „Najwyższe ". Zobacz przykładowy zrzut ekranu poniżej:
Istnieje również kilka funkcji po kliknięciu prawym przyciskiem myszy węzła, w których można włączyć archiwizację WAL lub zrestartować demona PostgreSQL lub zrestartować hosta. Zobacz obrazek, jak pokazano poniżej:
Może to być pomocne, jeśli chcesz zaplanować konserwację słabego węzła.
Karta „Panele informacyjne”
Pulpity nawigacyjne zostały wydane właśnie w zeszłym roku i dzięki obsłudze pulpitów nawigacyjnych PostgreSQL możesz skorzystać z tych wykresów. Na przykład wstawiłem 1M wierszy w bazie danych nyc_data. Zobacz poniżej, jak to odzwierciedla się w panelu informacyjnym PostgreSQL:
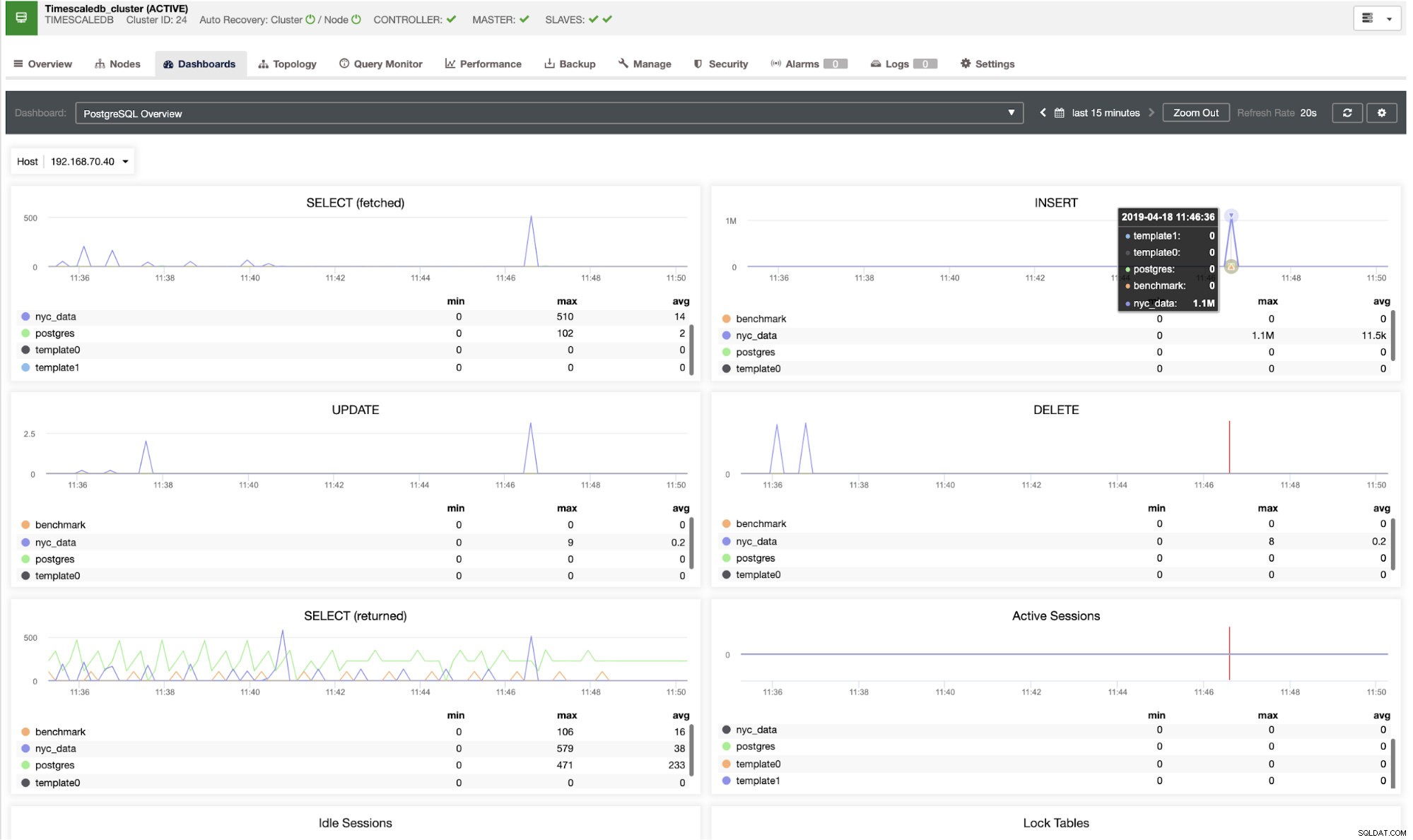
Po wstawieniu wierszy 1,1 M widzimy, że węzeł 192.168.70.40 jest nadal wydajny i nie ma oznak dużego obciążenia procesora i dysku. Zobacz następujący pulpit nawigacyjny, gdy monitorujemy jego wydajność:
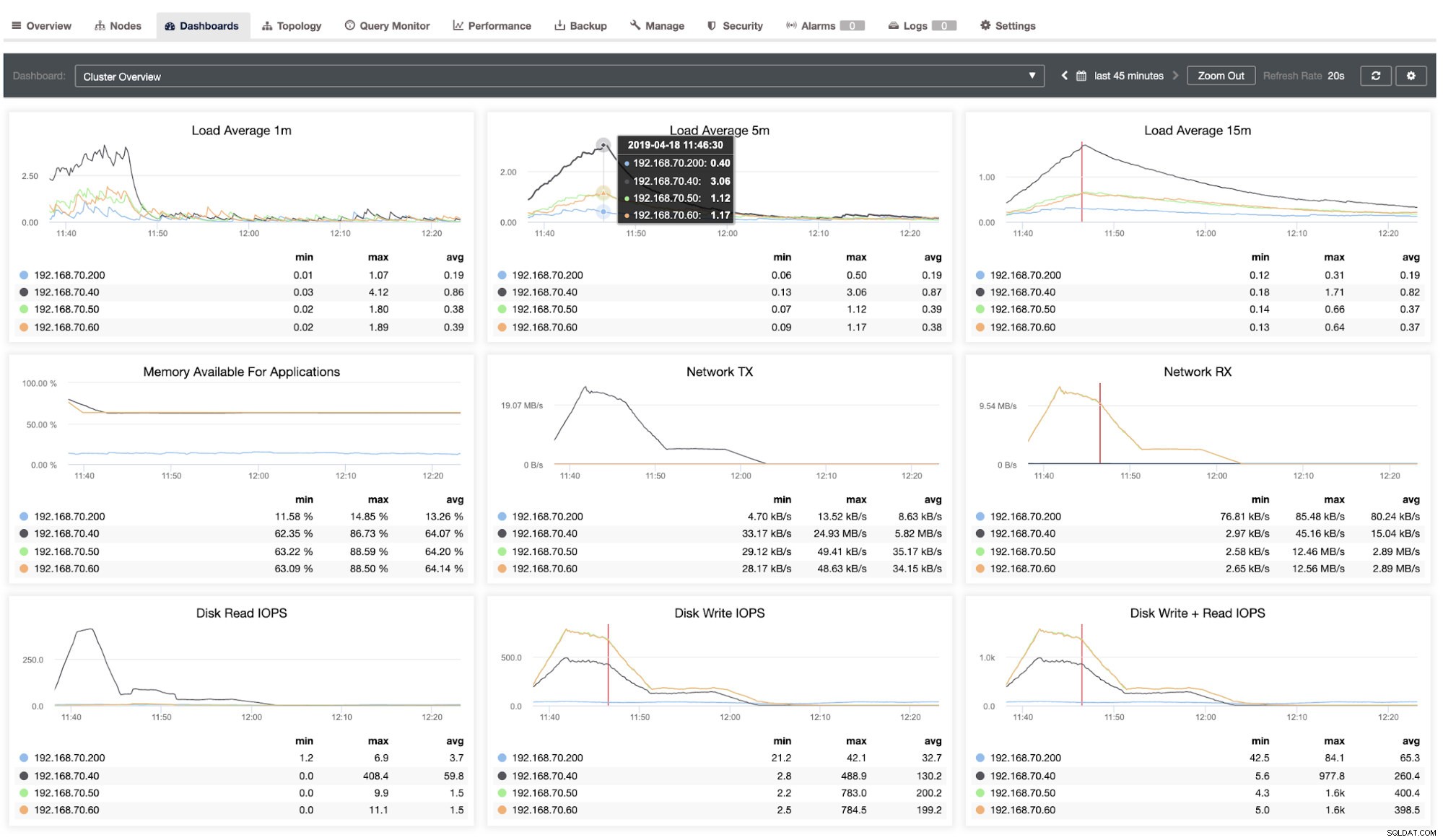
Oprócz pulpitu nawigacyjnego przeglądu klastrów możesz również uzyskać szczegółowy widok wydajności systemu. Zobacz obrazek poniżej:
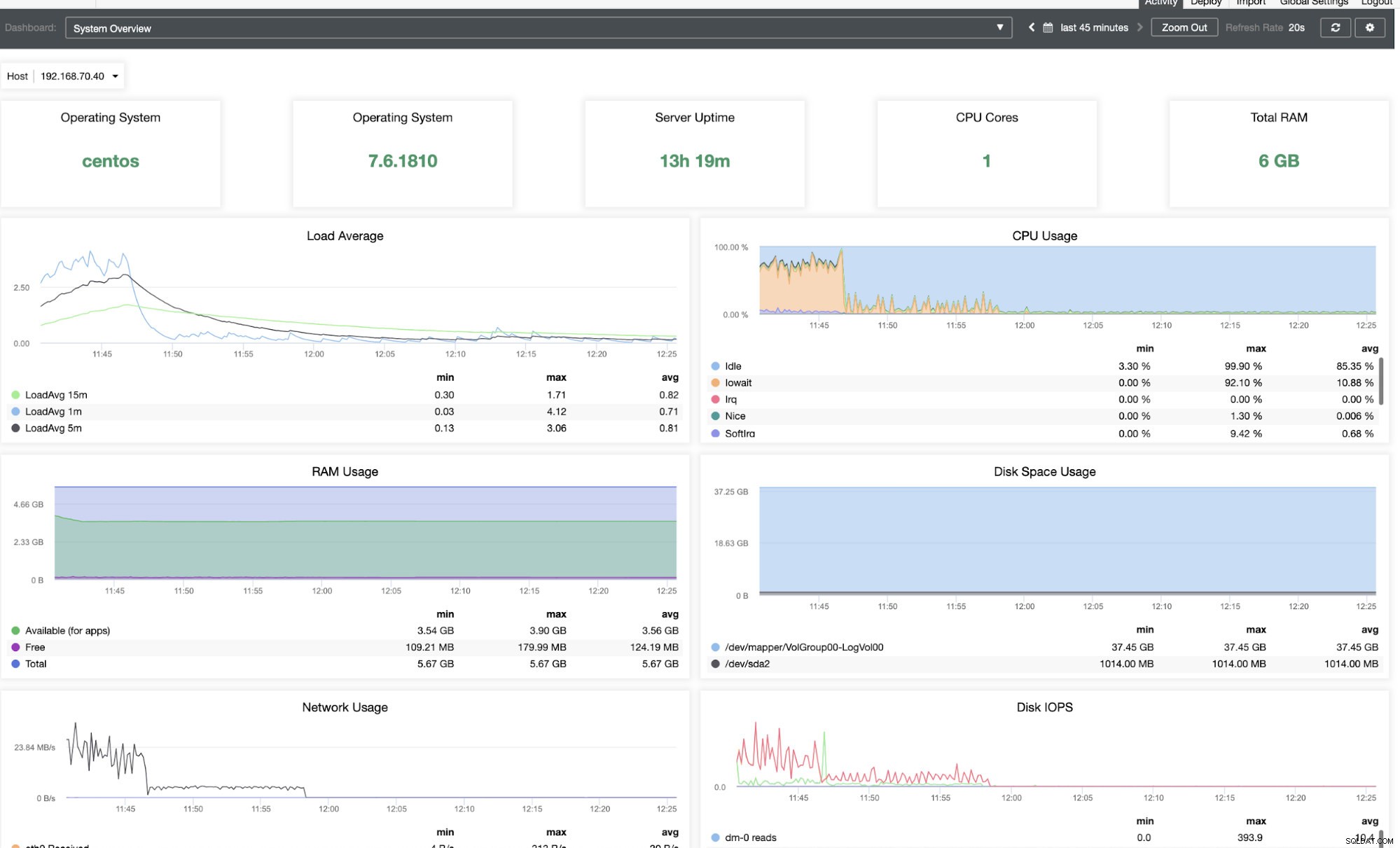
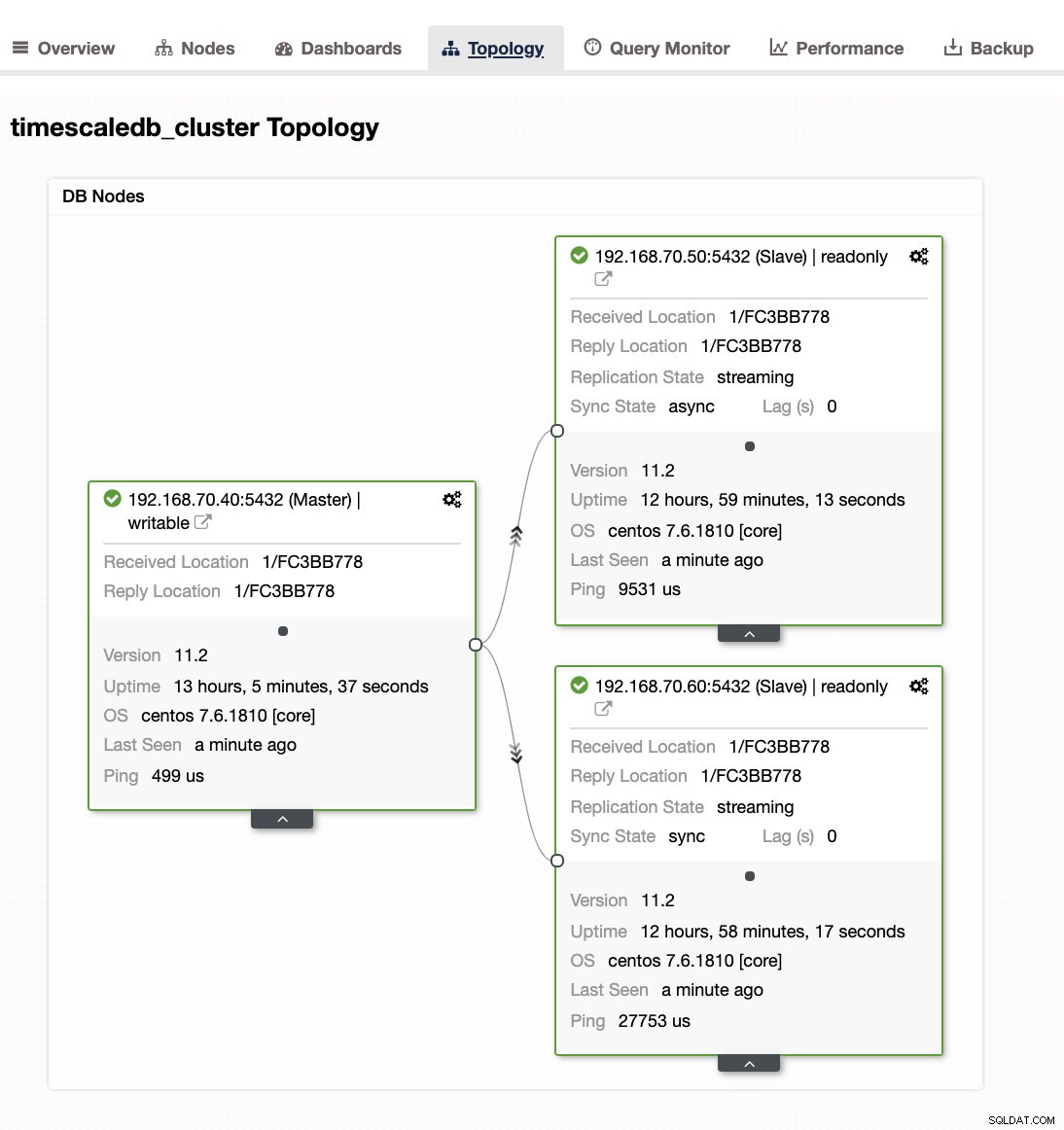
Zakładka „Topologia”
Ta karta jest prosta, ale oferuje widok topologii replikacji typu master-slave. Zawiera krótkie, ale zwięzłe informacje o tym, jak radzi sobie twój pan i niewolnicy. Zobacz obrazek poniżej:
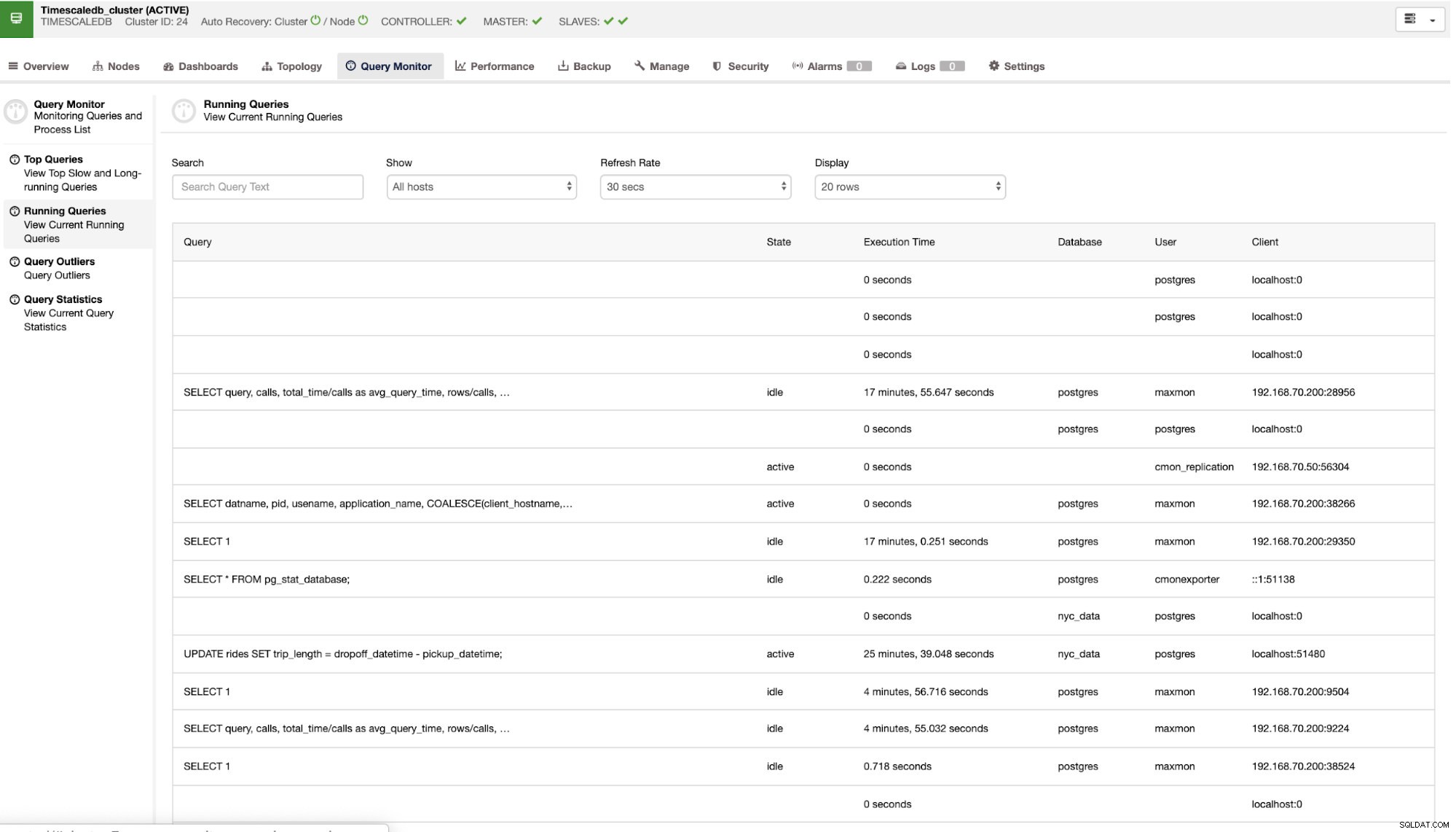
Karta „Monitor zapytań”
Monitorowanie zapytań w TimescaleDB jest bardzo ważne zarówno dla DBA, jak i dla programistów obsługujących logikę aplikacji. Ta karta jest bardzo ważna, aby zrozumieć, jak działają zapytania. Tutaj możesz wyświetlić najpopularniejsze zapytania, uruchomione zapytania, wartości odstające zapytań i statystyki zapytań. Na przykład możesz wyświetlić zapytania działające na wszystkich hostach lub możesz filtrować na podstawie węzła, który próbujesz monitorować. Poniższy przykład pokazuje, jak to wygląda w Monitorze zapytań.
Jeśli chcesz zbierać statystyki porcji/indeksów TimescaleDB, możesz skorzystać tutaj w obszarze Statystyka zapytań. Pokazuje listę indeksów używanych przez TimescaleDB. Zobacz obrazek poniżej:
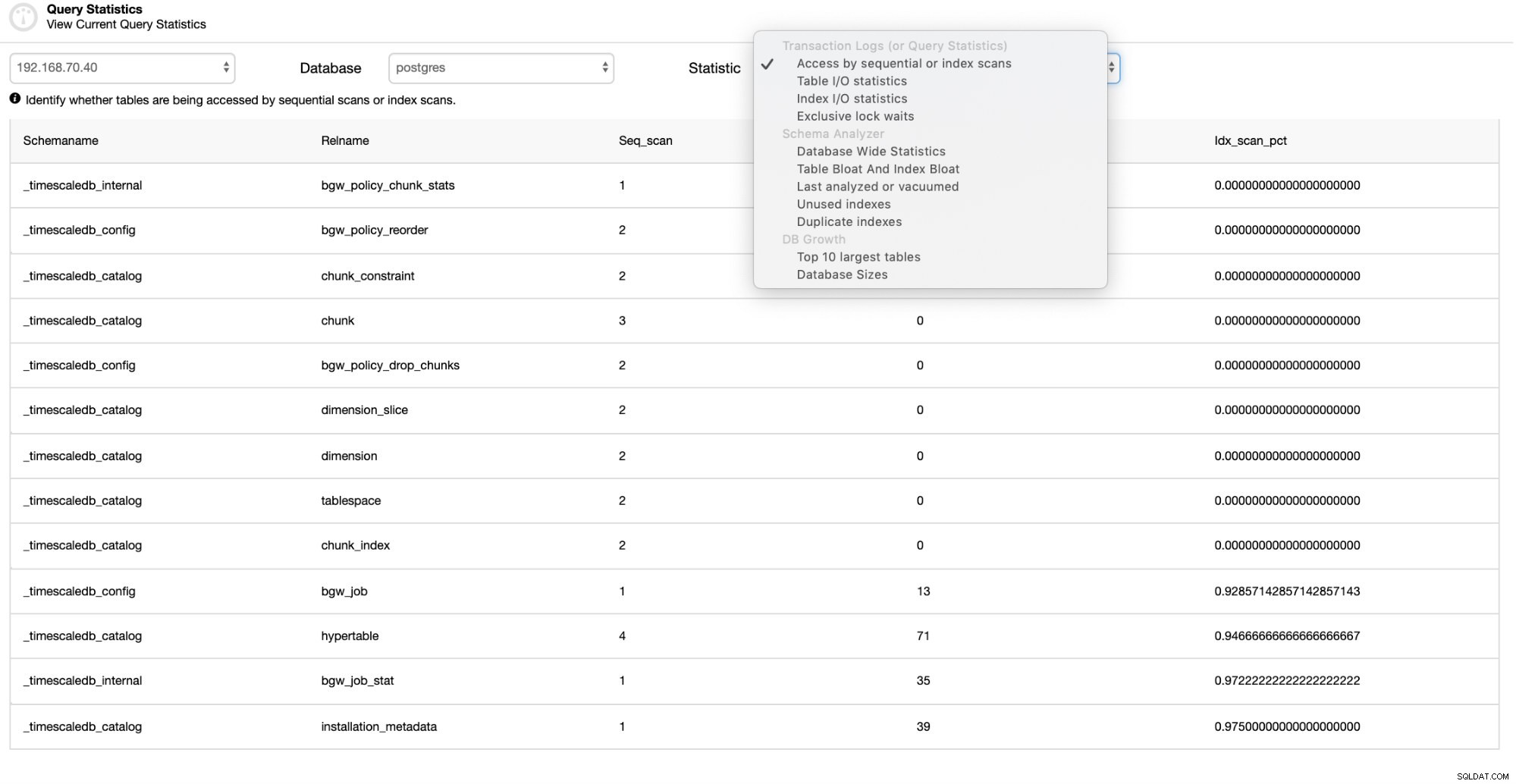
Możesz nie tylko przeglądać statystyki określonych indeksów, ale także filtrować je według statystyk we/wy tabeli, statystyk we/wy indeksów lub wyłącznych czasów oczekiwania na blokadę. Dlatego możesz sprawdzić inne pozycje na liście „Statystyki”, które wolisz monitorować.
Karta „Wydajność”
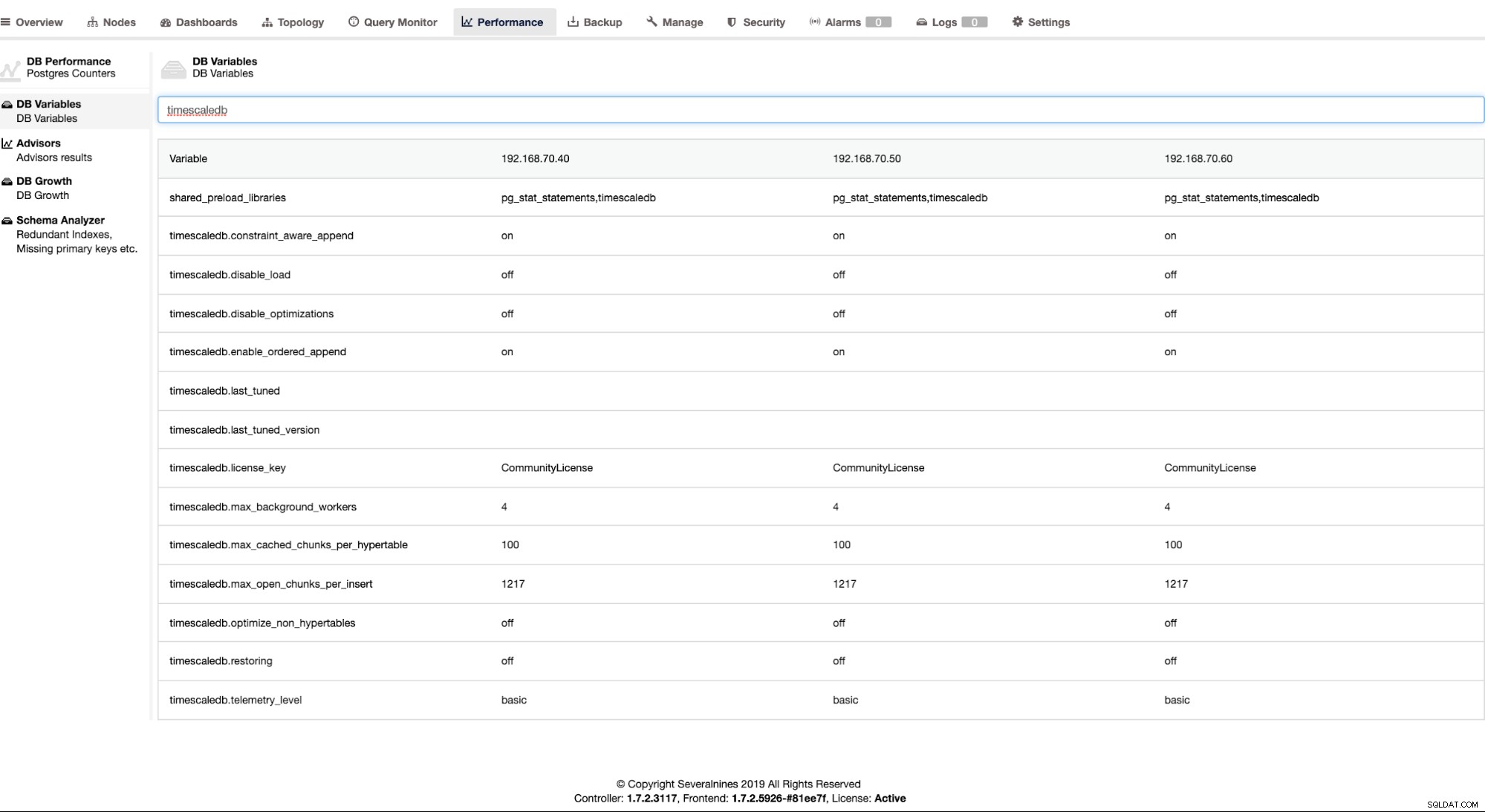
W tej zakładce możesz przejrzeć zmienne ustawione do optymalizacji i dostrajania, skonfigurować doradców, sprawdzić wzrost bazy danych i wygenerować analizę schematu w celu zebrania tabel bez kluczy podstawowych.
Na przykład możesz wyświetlić obok siebie dostępne węzły w konfiguracji i porównać zmienne. Zobacz zakładkę poniżej:
To wszystko na teraz. Byłoby wspaniale usłyszeć Twoją opinię, a zwłaszcza poinformować nas, czego nam brakuje.



