Kilka dni temu została wydana nowa wersja ClusterControl, 1.7.2, w której możemy zobaczyć kilka nowych funkcji, jedną z głównych jest obsługa TimescaleDB.
TimescaleDB to baza danych szeregów czasowych typu open source zoptymalizowana pod kątem szybkiego pozyskiwania i złożonych zapytań, która obsługuje pełny SQL. Jest oparty na PostgreSQL i oferuje to, co najlepsze ze światów NoSQL i relacyjnych dla danych szeregów czasowych. TimescaleDB obsługuje replikację strumieniową jako podstawową metodę replikacji, która może być używana w konfiguracji wysokiej dostępności. Jednak PostgreSQL nie jest wyposażony w automatyczne przełączanie awaryjne i jest to problem w środowisku produkcyjnym o wysokiej dostępności. Ręczne przełączanie awaryjne zwykle oznacza, że człowiek jest przywołany i musi znaleźć komputer, zalogować się do systemów, zrozumieć, co się dzieje, zanim rozpocznie procedurę przełączania awaryjnego. Przekłada się to na długi okres przestoju. Na szczęście istnieje sposób na zautomatyzowanie przełączania awaryjnego za pomocą ClusterControl, który teraz obsługuje TimescaleDB.
W tym blogu zobaczymy, jak za pomocą kilku kliknięć za pomocą ClusterControl wdrożyć zreplikowaną konfigurację TimescaleDB z automatycznym przełączaniem awaryjnym. Zobaczymy również, jak dodać pojedynczy punkt końcowy bazy danych dla aplikacji za pośrednictwem HAProxy. Jako warunek wstępny należy zainstalować wersję 1.7.2 ClusterControl na dedykowanym hoście lub maszynie wirtualnej.
Wdrażanie bazy danych skali czasu
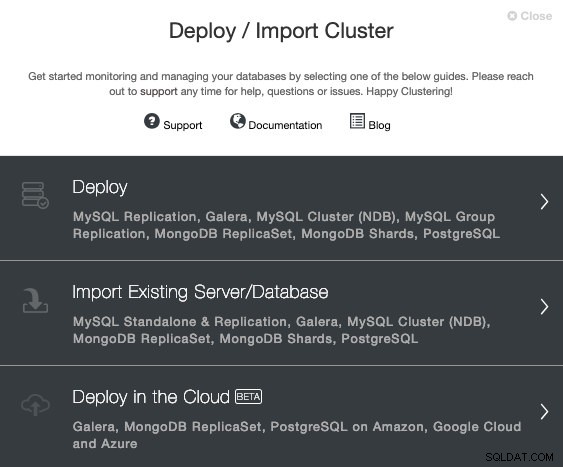
Aby wykonać nową instalację TimescaleDB z ClusterControl, po prostu wybierz opcję „Wdróż” i postępuj zgodnie z wyświetlanymi instrukcjami. Pamiętaj, że jeśli masz już uruchomioną instancję TimescaleDB, musisz zamiast tego wybrać opcję „Importuj istniejący serwer/bazę danych”.
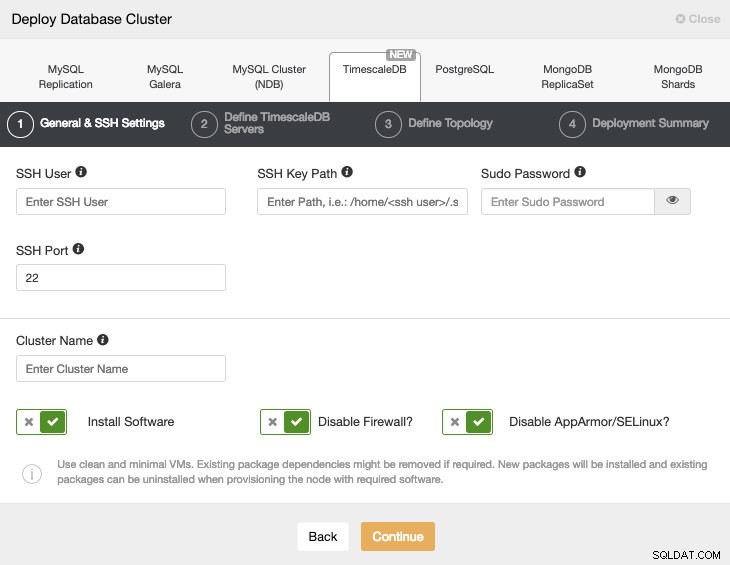
Wybierając TimescaleDB, musimy określić użytkownika, klucz lub hasło i port, aby połączyć się przez SSH z naszymi hostami TimescaleDB. Potrzebujemy również nazwy dla naszego nowego klastra i jeśli chcemy, aby ClusterControl zainstalował dla nas odpowiednie oprogramowanie i konfiguracje.
Sprawdź wymagania użytkownika ClusterControl dla tego zadania tutaj.
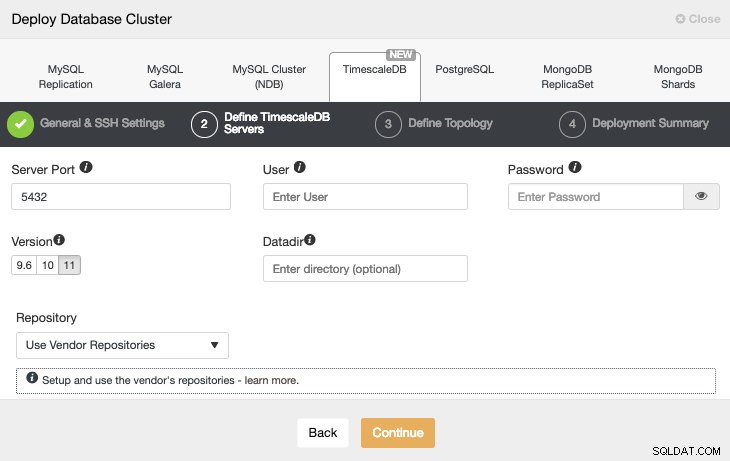
Po skonfigurowaniu informacji dostępowych SSH musimy zdefiniować użytkownika bazy danych, wersję i datadir (opcjonalnie). Możemy również określić, którego repozytorium użyć.
W następnym kroku musimy dodać nasze serwery do klastra, który zamierzamy utworzyć.
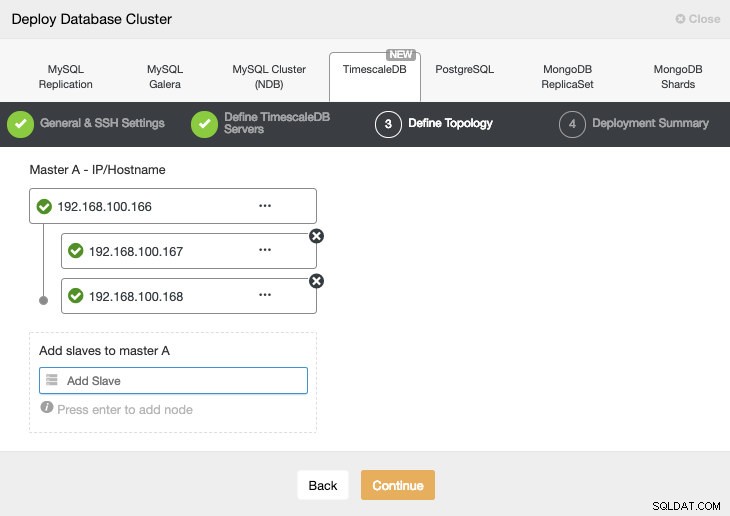
Podczas dodawania naszych serwerów możemy wprowadzić adres IP lub nazwę hosta.
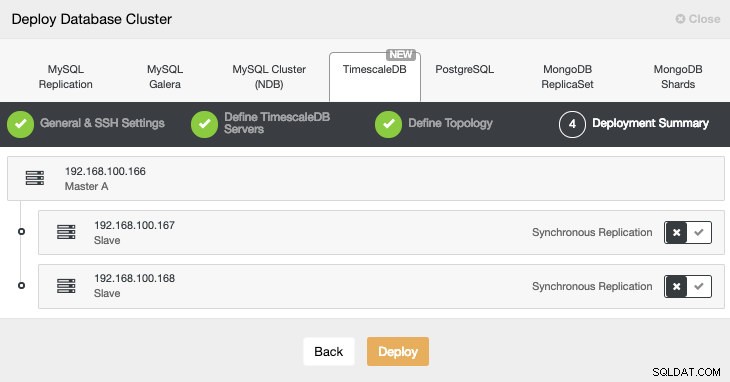
W ostatnim kroku możemy wybrać, czy nasza replikacja będzie synchroniczna czy asynchroniczna.
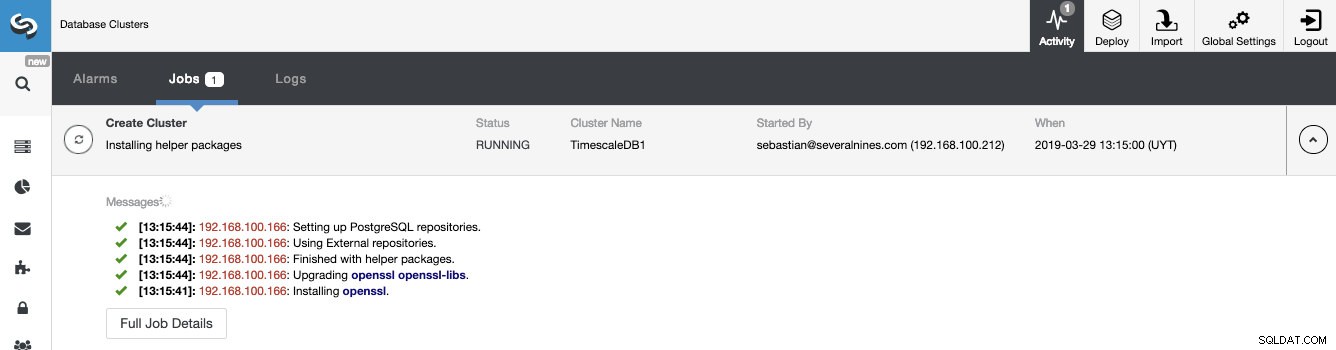
Możemy monitorować stan tworzenia naszego nowego klastra z monitora aktywności ClusterControl.
Po zakończeniu zadania możemy zobaczyć nasz nowy klaster TimescaleDB na głównym ekranie ClusterControl.

Po utworzeniu naszego klastra możemy wykonać na nim kilka zadań, takich jak dodanie modułu równoważenia obciążenia (HAProxy) lub nowej repliki.
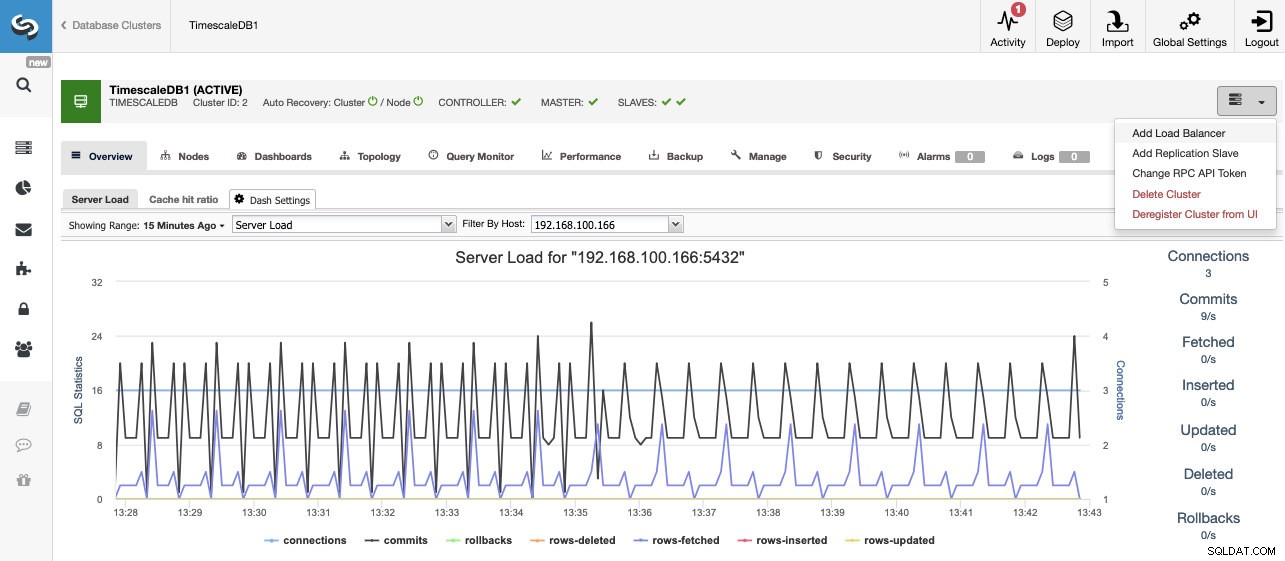
Skalowanie bazy danych skali czasu
Jeśli przejdziemy do działań klastrowych i wybierzemy „Dodaj niewolnik replikacji”, możemy albo utworzyć nową replikę od zera, albo dodać istniejącą bazę danych TimescaleDB jako replikę.
Zobaczmy, jak dodanie nowego urządzenia podrzędnego replikacji może być naprawdę łatwym zadaniem.
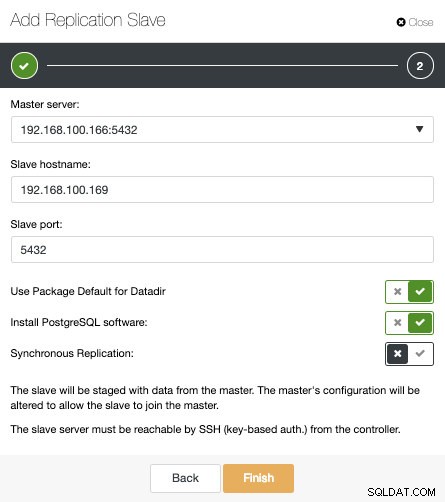
Jak widać na obrazku, wystarczy wybrać nasz serwer główny, wpisać adres IP naszego nowego serwera podrzędnego i port bazy danych. Następnie możemy wybrać, czy chcemy, aby ClusterControl zainstalował oprogramowanie za nas i czy urządzenie podrzędne replikacji powinno być synchroniczne czy asynchroniczne.
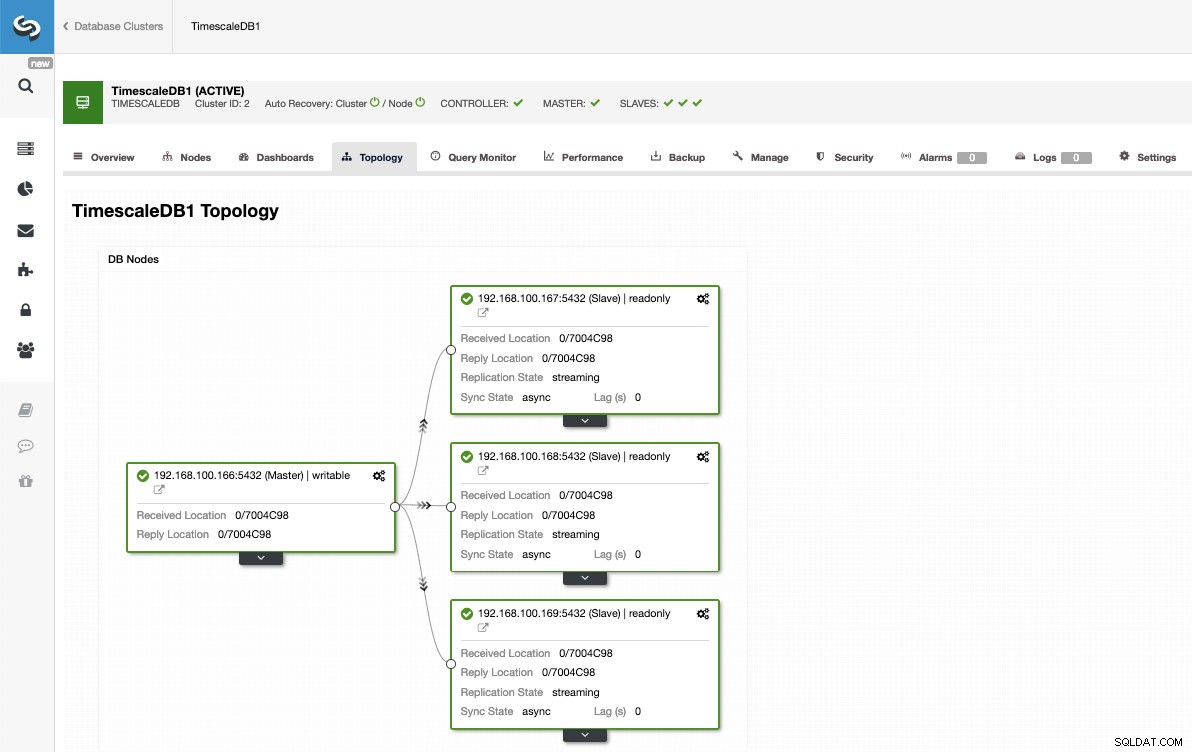
W ten sposób możemy dodać dowolną liczbę replik i rozłożyć między nimi ruch odczytu za pomocą load balancera, który możemy również zaimplementować za pomocą ClusterControl.
Z ClusterControl możesz również jednym kliknięciem wykonywać różne zadania zarządzania, takie jak Reboot Host, Rebuild Replication Slave lub Prome Slave.
Wniosek
Jak widzieliśmy powyżej, możesz teraz wdrożyć TimescaleDB za pomocą ClusterControl. Po wdrożeniu ClusterControl zapewnia całą gamę funkcji, od monitorowania, alarmowania, automatycznego przełączania awaryjnego, tworzenia kopii zapasowych, przywracania do określonego punktu w czasie, weryfikacji kopii zapasowych, po skalowanie replik do odczytu. Może to pomóc w zarządzaniu TimescaleDB w przyjazny i intuicyjny sposób.