W tym artykule kontynuuję poszukiwanie rozwiązań w zakresie dopasowania podaży do popytu. Dziękuję Luce, Kamilowi Kosno, Danielowi Brownowi, Brianowi Walkerowi, Joe Obbishowi, Rainerowi Hoffmannowi, Paulowi White'owi, Charliemu, Ianowi i Peterowi Larssonowi za przesłanie swoich rozwiązań.
W zeszłym miesiącu omówiłem rozwiązania oparte na poprawionym podejściu przecięć interwałów w porównaniu do klasycznego. Najszybsze z tych rozwiązań łączyło pomysły Kamila, Luki i Daniela. Ujednolicił dwa zapytania z rozłącznymi predykatami sargable. Rozwiązanie zajęło 1,34 sekundy, aby ukończyć dane wejściowe o wielkości 400 000 wierszy. Nie jest to zbyt nędzne, biorąc pod uwagę, że rozwiązanie oparte na klasycznym podejściu do skrzyżowań interwałów zajęło 931 sekund, aby ukończyć te same dane wejściowe. Przypomnijmy również, że Joe wymyślił genialne rozwiązanie, które opiera się na klasycznym podejściu do przecięcia interwałów, ale optymalizuje logikę dopasowywania, analizując interwały w oparciu o największą długość interwału. Przy tym samym wejściu 400 tys. wierszy rozwiązanie Joe zajęło 0,9 sekundy. Trudną częścią tego rozwiązania jest to, że jego wydajność spada wraz ze wzrostem długości największego interwału.
W tym miesiącu badam fascynujące rozwiązania, które są szybsze niż rozwiązanie zrewidowanych skrzyżowań Kamila/Luki/Daniela i są neutralne dla długości interwału. Rozwiązania zawarte w tym artykule zostały stworzone przez Briana Walkera, Iana, Petera Larssona, Paula White'a i mnie.
Przetestowałem wszystkie rozwiązania w tym artykule z tabelą wejściową Aukcje z wierszami 100K, 200K, 300K i 400K oraz z następującymi indeksami:
-- Indeks do obsługi rozwiązania UTWÓRZ UNIKALNY INDEKS NIESKLASTRAROWANY idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Ilość); -- Włącz agregację okien w trybie wsadowym UTWÓRZ NIESKLASTRAROWANY INDEKS KOLUMNOWY idx_cs ON dbo.Auctions(ID) WHERE ID =-1 AND ID =-2;
Opisując logikę rozwiązań, zakładam, że tabela Aukcje jest wypełniona następującym małym zestawem przykładowych danych:
Kod ID Ilość----------- ---- ---------1 D 5.0000002 D 3.0000003 D 8.0000005 D 2.0000006 D 8.0000007 D 4.0000008 D 2.0000001000 S 8.0000002000 S 6.0000003000 S 2.0000004000 S 2.0000005000 S 4.0000006000 S 3.0000007000 S 2.000000
Poniżej znajduje się pożądany wynik dla tych przykładowych danych:
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5.0000002 1000 3.0000003 2000 6.0000003 3000 2.0000005 4000 2.0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.000000
Rozwiązanie Briana Walkera
Sprzężenia zewnętrzne są dość powszechnie używane w rozwiązaniach zapytań SQL, ale zdecydowanie, gdy ich używasz, używasz złączeń jednostronnych. Kiedy uczę o sprzężeniach zewnętrznych, często otrzymuję pytania z prośbą o przykłady praktycznych przypadków użycia pełnych sprzężeń zewnętrznych, a nie ma ich zbyt wiele. Rozwiązanie Briana jest pięknym przykładem praktycznego przypadku użycia pełnych połączeń zewnętrznych.
Oto kompletny kod rozwiązania Briana:
DROP TABLE, JEŚLI ISTNIEJE #MyPairings; CREATE TABLE #MyPairings( DemandID INT NIE NULL, SupplyID INT NIE NULL, TradeQuantity DECIMAL(19,06) NIE NULL); WITH D AS (WYBIERZ A.ID, SUM(A.Quantity) OVER (PARTYCJA BY A.Code KOLEJNOŚĆ WEDŁUG WIERSZY A.ID BEZ OGRANICZENIA POCZĄTKOWEGO) AS Uruchamianie FROM dbo.Auctions AS A WHERE A.Code ='D'),S AS( SELECT A.ID, SUM(A.Quantity) OVER (PARTITION BY A.Code ORDER BY A.ID ROWERS BEZ OGRANICZENIA POSTĘPOWANIA) AS Running FROM dbo.Auctions AS A WHERE A.Code ='S'),W AS( SELECT D.ID AS DemandID, S.ID AS SupplyID, ISNULL(D.Running, S.Running) AS Running FROM D FULL JOIN S ON D.Running =S.Running),Z AS(SELECT CASE,GDY W.DemandID IS NOT NULL TO W.DemandID ELSE MIN(W.DemandID) PRZEKROCZONE (KOLEJNOŚĆ W.RUNING WIERSZY MIĘDZY OBECNYM RZĘDEM A NIEOGRANICZONYM KOLEJNYM) KONIEC JAKO DemandID, PRZYPADEK GDY W.SupplyID NIE JEST NULL TO W.SupplyID ELSE MIN(W.SupplyID) ) OVER (ORDER W.Running FROM MIĘDZY BIEŻĄCYM RZĄDEM A NIEOGRANICZONYM KOLEJNYM) END AS SupplyID, W.Running FROM W)INSERT #MyPair ings( DemandID, SupplyID, TradeQuantity ) SELECT Z.DemandID, Z.SupplyID, Z.Running - ISNULL(LAG(Z.Running) OVER (ORDER BY Z.Running), 0.0) AS TradeQuantity FROM Z WHERE Z.DemandID IS NOT NULL I Z.SupplyID NIE JEST NULL;
Poprawiłem oryginalne użycie przez Briana tabel pochodnych z CTE dla jasności.
CTE D oblicza bieżące całkowite ilości popytu w kolumnie wyników o nazwie D.Running, a CTE S oblicza bieżące całkowite ilości podaży w kolumnie wyników o nazwie S.Running. CTE W następnie wykonuje pełne połączenie zewnętrzne pomiędzy D i S, dopasowując D.Running do S.Running i zwraca pierwszy nie-NULL spośród D.Running i S.Running jako W.Running. Oto wynik, który otrzymasz, jeśli zapytasz wszystkie wiersze z W uporządkowane według Uruchomione:
DemandID SupplyID Running----------- ----------- ----------1 NULL 5.0000002 1000 8.000000NULL 2000 14.0000003 3000 16.0000005 4000 18.000000 NULL 5000 22.000000 NULL 6000 25.0000006 NULL 26.000000 NULL 7000 27.0000007 NULL 30.0000008 NULL 32.000000
Pomysł, aby użyć pełnego sprzężenia zewnętrznego w oparciu o predykat porównujący sumy bieżące popytu i podaży, jest genialny! Większość wierszy w tym wyniku — w naszym przypadku pierwszych 9 — reprezentuje pary wyników, w których brakuje odrobiny dodatkowych obliczeń. Wiersze z końcowymi identyfikatorami NULL jednego z rodzajów reprezentują wpisy, których nie można dopasować. W naszym przypadku ostatnie dwa wiersze reprezentują wpisy popytu, których nie można dopasować do wpisów podaży. Pozostaje więc obliczenie DemandID, SupplyID i TradeQuantity par wyników oraz odfiltrowanie wpisów, których nie można dopasować.
Logika, która oblicza wynik DemandID i SupplyID, jest wykonywana w CTE Z w następujący sposób (przy założeniu porządkowania w W przez uruchomienie):
- DemandID:jeśli DemandID nie jest NULL, to DemandID, w przeciwnym razie minimalne DemandID zaczynające się od bieżącego wiersza
- SupplyID:jeśli SupplyID nie jest NULL, to SupplyID, w przeciwnym razie minimalne SupplyID zaczynające się od bieżącego wiersza
Oto wynik, który otrzymasz, jeśli zapytasz Z i uporządkujesz wiersze, uruchamiając:
DemandID SupplyID Running----------- ----------- ----------1 1000 5.0000002 1000 8.0000003 2000 14.0000003 3000 16.0000005 4000 18.0000006 5000 22.0000006 6000 25.0000006 7000 26.0000007 7000 27.0000007 NULL 30.0000008 NULL 32.000000
Zapytanie zewnętrzne odfiltrowuje wiersze z Z reprezentujące wpisy jednego rodzaju, których nie można dopasować do wpisów innego rodzaju, zapewniając, że zarówno DemandID, jak i SupplyID nie mają wartości NULL. Wielkość transakcji par wynikowych jest obliczana jako bieżąca wartość bieżąca minus poprzednia bieżąca wartość przy użyciu funkcji LAG.
Oto, co zostanie zapisane w tabeli #MyPairings, co jest pożądanym wynikiem:
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5.0000002 1000 3.0000003 2000 6.0000003 3000 2.0000005 4000 2.0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.000000
Plan tego rozwiązania pokazano na rysunku 1.
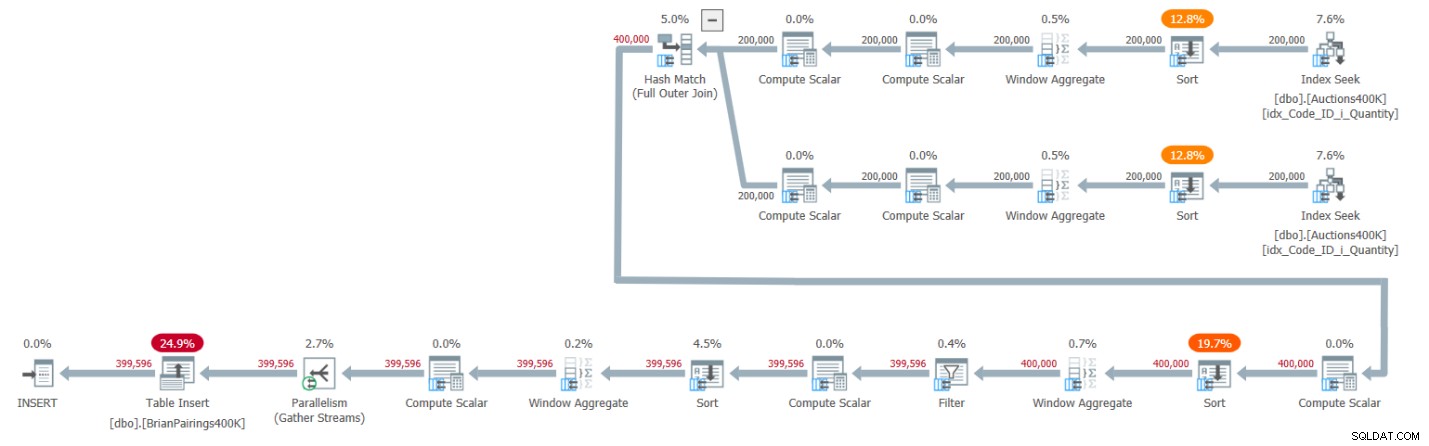 Rysunek 1:Plan zapytań dla rozwiązania Briana
Rysunek 1:Plan zapytań dla rozwiązania Briana
Dwie górne gałęzie planu obliczają sumy bieżące popytu i podaży za pomocą operatora agregatu okiennego działającego w trybie wsadowym, każda po pobraniu odpowiednich wpisów z indeksu pomocniczego. Jak wyjaśniłem we wcześniejszych artykułach z tej serii, ponieważ indeks ma już wiersze uporządkowane tak, jak potrzebują ich operatory Window Aggregate, można by pomyśleć, że jawne operatory sortowania nie powinny być wymagane. Ale SQL Server nie obsługuje obecnie wydajnej kombinacji równoległej operacji indeksowania z zachowaniem kolejności przed równoległym operatorem Window Aggregate w trybie wsadowym, więc w rezultacie jawny równoległy operator Sort poprzedza każdy z równoległych operatorów Window Aggregate.
Plan używa sprzężenia mieszającego w trybie wsadowym do obsługi pełnego sprzężenia zewnętrznego. Plan wykorzystuje również dwa dodatkowe operatory agregacji okien w trybie wsadowym poprzedzone jawnymi operatorami sortowania w celu obliczenia funkcji okna MIN i LAG.
To całkiem skuteczny plan!
Oto czasy działania, które otrzymałem dla tego rozwiązania dla rozmiarów wejściowych od 100K do 400K wierszy, w kilka sekund:
100K:0,368200K:0,845300K:1,255400K:1,315
Rozwiązanie Itzika
Kolejnym rozwiązaniem wyzwania jest jedna z moich prób jego rozwiązania. Oto kompletny kod rozwiązania:
DROP TABLE, JEŚLI ISTNIEJE #MyPairings; WITH C1 AS( SELECT *, SUM(Ilość) OVER(PARTYCJA WG KODU ORDER BY ID WIERSZE BEZ POSTĘPOWANIA) AS SumQty FROM dbo.Auctions),C2 AS(SELECT *, SUM(Ilość * Kod przypadku WHEN 'D' THEN -1 GDY 'S' THEN 1 END) OVER(ORDER BY SumQty, Code ROWS UNBOUNDED PRECEDING) AS StockLevel, LAG(SumQty, 1, 0.0) OVER(ORDER BY SumQty, Code) AS PrevSumQty, MAX(CASE WHEN Code ='D' THEN ID END) OVER(ORDER BY SumQty, Code ROWERS UNBOUNDED PRECEDING) AS PrevDemandID, MAX(CASE WHEN Code ='S' THEN ID END) OVER(ORDER BY SumQty, Code ROWERS UNBOUNDED PRECEDING) AS PrevSupplyID, MIN(CASE WHEN ='D' THEN ID END) OVER(ORDER BY SumQty, Code ROWS POMIĘDZY BIEŻĄCYM WIERSZEM I UNBOUNDED FOLLOWING) AS NextDemandID, MIN(CASE WHEN Code ='S' THEN ID END) OVER(ORDER BY SumQty, Code ROWS BETWEEN CURROR ROWS) I NIEOGRANICZONE NASTĘPUJĄCE) AS NextSupplyID FROM C1),C3 AS( SELECT *, CASE Code WHEN 'D ' THEN ID WHEN 'S' THEN CASE WEN 'D' THEN CASE WEN StockLevel> 0 THEN NextDemandID ELSE PrevDemandID END END AS DemandID, CASE Code WHEN 'S' THEN ID WHEN 'D' THEN CASE WEN StockLevel <=0 THEN NextSupplyID ELSE PrevEND END ASUPPLYID . SumQty - PrevSumQty AS TradeQuantity FROM C2)SELECT DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM C3WHERE TradeQuantity> 0.0 I DemandID NIE JEST NULL I SupplyID NIE JEST NULL;
CTE C1 wysyła zapytanie do tabeli Aukcje i używa funkcji okna do obliczenia bieżących całkowitych ilości popytu i podaży, wywołując kolumnę wyników SumQty.
CTE C2 wysyła zapytania do C1 i oblicza szereg atrybutów przy użyciu funkcji okna w oparciu o kolejność SumQty i kodu:
- Poziom zapasów:Bieżący poziom zapasów po przetworzeniu każdego wpisu. Jest to obliczane przez przypisanie znaku ujemnego do ilości popytu i znaku dodatniego do ilości podaży i zsumowanie tych ilości do bieżącego wpisu włącznie.
- PrevSumQty:Wartość SumQty poprzedniego wiersza.
- PrevDemandID:Ostatni niezerowy identyfikator żądania.
- PrevSupplyID:ostatni identyfikator dostawy inny niż NULL.
- NextDemandID:Następny niezerowy identyfikator żądania.
- NextSupplyID:Następny identyfikator dostawy inny niż NULL.
Oto zawartość C2 uporządkowana przez SumQty i Code:
CTE C3 wysyła zapytanie do C2 i oblicza pary wyników DemandID, SupplyID i TradeQuantity, przed usunięciem niektórych zbędnych wierszy.
Kolumna wynikowa C3.DemandID jest obliczana w następujący sposób:
- Jeśli bieżący wpis jest wpisem na żądanie, zwróć DemandID.
- Jeśli bieżący wpis jest wpisem podaży, a bieżący poziom zapasów jest dodatni, zwróć NextDemandID.
- Jeśli bieżący wpis jest wpisem podaży, a bieżący poziom zapasów jest niedodatni, zwróć PrevDemandID.
Wynikowa kolumna C3.SupplyID jest obliczana w następujący sposób:
- Jeśli bieżący wpis jest wpisem zaopatrzenia, zwróć SupplyID.
- Jeśli bieżący wpis jest wpisem popytu, a bieżący poziom zapasów jest niedodatni, zwróć NextSupplyID.
- Jeśli bieżący wpis jest wpisem popytu, a bieżący poziom zapasów jest dodatni, zwróć PrevSupplyID.
Wynik TradeQuantity jest obliczany jako SumQty bieżącego wiersza minus PrevSumQty.
Oto zawartość kolumn odnoszących się do wyniku z C3:
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5.0000002 1000 3.0000002 1000 0.0000003 2000 6.0000003 3000 2.0000003 3000 0.0000005 4000 2.0000005 4000 0.0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.0000007 NULL 3.0000008 NULL 2.000000
To, co pozostało do wykonania zewnętrznemu zapytaniu, to odfiltrowanie zbędnych wierszy z C3. Obejmują one dwa przypadki:
- Gdy sumy bieżące obu rodzajów są takie same, pozycja podaży ma zerową wartość handlową. Pamiętaj, że zamawianie jest oparte na SumQty i Code, więc gdy sumy bieżące są takie same, wpis popytu pojawia się przed wpisem podaży.
- Wpisy końcowe jednego rodzaju, których nie można dopasować do wpisów innego rodzaju. Takie wpisy są reprezentowane przez wiersze w C3, gdzie DemandID ma wartość NULL lub SupplyID ma wartość NULL.
Plan tego rozwiązania pokazano na rysunku 2.
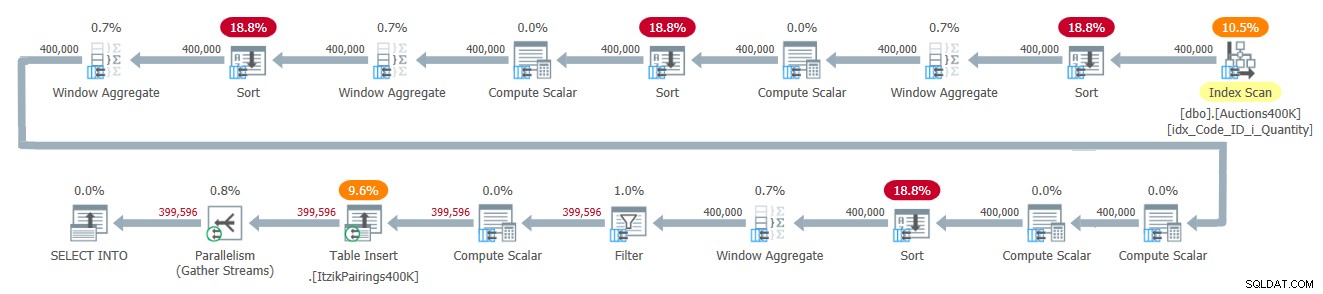 Rysunek 2:Plan zapytań dla rozwiązania Itzika
Rysunek 2:Plan zapytań dla rozwiązania Itzika
Plan stosuje jedno przejście nad danymi wejściowymi i używa czterech operatorów Window Aggregate w trybie wsadowym do obsługi różnych obliczeń okienkowych. Wszystkie operatory Window Aggregate są poprzedzone jawnymi operatorami sortowania, chociaż tylko dwa z nich są tutaj nieuniknione. Pozostałe dwa mają związek z obecną implementacją równoległego operatora Window Aggregate działającego w trybie wsadowym, który nie może polegać na równoległych danych wejściowych z zachowaniem kolejności. Prostym sposobem sprawdzenia, którzy operatorzy sortowania są z tego powodu, jest wymuszenie planu szeregowego i zobaczenie, którzy operatorzy sortowania znikają. Kiedy wymuszam plan szeregowy z tym rozwiązaniem, pierwszy i trzeci operator sortowania znikają.
Oto czasy działania w sekundach, które uzyskałem dla tego rozwiązania:
100K:0,246200K:0,427300K:0,616400K:0,841>
Rozwiązanie Iana
Rozwiązanie Iana jest krótkie i wydajne. Oto kompletny kod rozwiązania:
DROP TABLE, JEŚLI ISTNIEJE #MyPairings; WITH A AS ( SELECT *, SUM(Ilość) OVER (PARTITION BY Code ORDER BY ID ROWERS BEZ POSTĘPOWANIA) AS CumulativeQuantity FROM dbo.Auctions), B AS (SELECT CumulativeQuantity, CumulativeQuantity - LAG(CumulativeQuantity, 1, 0) OVER (ORDER BY CumulativeQuantity) AS TradeQuantity, MAX(CASE WHEN Code ='D' THEN ID END) AS DemandID, MAX(CASE WHEN Code ='S' THEN ID END) AS SupplyID Z GRUPY BY CumulativeQuantity, ID/ID -- grupowanie fałszywe aby poprawić oszacowanie wierszy -- (liczba wierszy aukcji zamiast 2 wierszy)), C AS ( -- wypełnij NULL następną podażą / popytem -- FIRST_VALUE (ID) IGNORE NULLS OVER ... -- byłoby lepiej, ale to zadziała, ponieważ identyfikatory są w kolejności CumulativeQuantity SELECT MIN(DemandID) OVER (ORDER BY CumulativeQuantity ROWS POMIĘDZY OBECNYM WIERSZEM I UNBOUNDED FOLLOWING) AS DemandID, MIN(SupplyID) OVER (ORDER BY CumulativeQ ilość WIERSZE POMIĘDZY OBECNYM WIERSZEM A NIEOBJĘTYMI NASTĘPUJĄCYMI) AS SupplyID, TradeQuantity FROM B)SELECT DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM CWHERE SupplyID NIE JEST NULL -- przyciąć niespełnione żądania I DemandID NIE JEST NULL; -- przyciąć nieużywane materiały eksploatacyjne
Kod w CTE A wysyła zapytanie do tabeli Aukcje i oblicza bieżące całkowite ilości popytu i podaży za pomocą funkcji okna, nazywając kolumnę wyników CumulativeQuantity.
Kod w CTE B wysyła zapytanie o CTE A i grupuje wiersze według CumulativeQuantity. To grupowanie osiąga podobny efekt do zewnętrznego sprzężenia Briana w oparciu o bieżące sumy popytu i podaży. Ian dodał również fikcyjny identyfikator/identyfikator wyrażenia do zestawu grupowania, aby poprawić szacowaną oryginalną kardynalność grupowania. Na moim komputerze spowodowało to również użycie planu równoległego zamiast szeregowego.
Na liście SELECT kod oblicza DemandID i SupplyID, pobierając identyfikator odpowiedniego typu wpisu w grupie przy użyciu agregacji MAX i wyrażenia CASE. Jeśli identyfikator nie występuje w grupie, wynikiem jest NULL. Kod oblicza również kolumnę wyników o nazwie TradeQuantity jako bieżącą skumulowaną ilość minus poprzednią, pobraną za pomocą funkcji okna LAG.
Oto zawartość B:
CumulativeQuantity TradeQuantity DemandId SupplyId------- -------------- --------- - -------- 5.000000 5.000000 1 NULL 8.000000 3.000000 2 100014.000000 6.000000 NULL 200016.000000 2.000000 3 300018.000000 2.000000 5 400022.000000 4.000000 NULL 500025.000000 3.000000 NULL 600026.000000 1.000000 6 NULL27.000000 1.000000 NULL 700030.000000 3.000000 7 NULL32.000000 2.000000 8>Kod w CTE C następnie wysyła zapytanie do CTE B i wypełnia NULL identyfikatory popytu i podaży kolejnymi niezerowymi identyfikatorami popytu i podaży, używając funkcji okna MIN z ramką ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING.
Oto zawartość C:
DemandID SupplyID TradeQuantity --------- --------- --------------1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000 7 BRAK 3.000000 8 BRAK 2.000000Ostatnim krokiem obsługiwanym przez zewnętrzne zapytanie względem C jest usunięcie wpisów jednego rodzaju, których nie można dopasować do wpisów innego rodzaju. Odbywa się to poprzez odfiltrowanie wierszy, w których SupplyID ma wartość NULL lub DemandID ma wartość NULL.
Plan tego rozwiązania pokazano na rysunku 3.
Rysunek 3:Plan zapytań dla rozwiązania Iana
Ten plan wykonuje jedno skanowanie danych wejściowych i używa trzech równoległych operatorów agregujących okien w trybie wsadowym do obliczenia różnych funkcji okien, wszystkie poprzedzone równoległymi operatorami sortowania. Dwa z nich są nieuniknione, co można zweryfikować, wymuszając plan seryjny. Plan wykorzystuje również operator Hash Aggregate do obsługi grupowania i agregacji w CTE B.
Oto czasy działania w sekundach, które uzyskałem dla tego rozwiązania:
100K:0,214200K:0,363300K:0,546400K:0,701
Rozwiązanie Petera Larssona
Rozwiązanie Petera Larssona jest zadziwiająco krótkie, słodkie i bardzo wydajne. Oto kompletny kod rozwiązania Petera:
DROP TABLE, JEŚLI ISTNIEJE #MyPairings; WITH cteSource (ID, Code, RunningQuantity)AS( SELECT ID, Code, SUM(Ilość) OVER (PARTITION BY Code ORDER BY ID) AS RunningQuantity FROM dbo.Auctions)SELECT DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM ( SELECT MIN (CASE WHEN) Kod ='D' TO ID INACZEJ 2147483648 END) OVER (ORDER WEDŁUG RunningQuantity, WIERSZE KODU MIĘDZY BIEŻĄCYM WIERSZEM I NIEOGRANICZONYM KOLEJNYM) AS DemandID, MIN (CASE WEN Code ='S' THEN ID ELSE 2147483648 END) OVER (ORDER BY RunningQuantity) Kod WIERSZE MIĘDZY BIEŻĄCYM WIERSZEM A NIEOGRANICZONYMI NASTĘPUJĄCYMI) AS SupplyID, RunningQuantity - COALESCE(LAG(RunningQuantity) OVER (ORDER BYRunningQuantity, Code), 0.0) AS TradeQuantity FROM cteSource ) AS dWHERE DemandID <2147483648 AND 0.048; SupplyID <21473648CTE cteSource wysyła zapytanie do tabeli Auctions i używa funkcji okna do obliczenia bieżącego całkowitego zapotrzebowania i podaży, wywołując kolumnę wyników RunningQuantity.
Kod definiujący tabelę pochodną d wysyła zapytanie do cteSource i oblicza pary wyników DemandID, SupplyID i TradeQuantity, przed usunięciem niektórych zbędnych wierszy. Wszystkie funkcje okna używane w tych obliczeniach są oparte na kolejności RunningQuantity i Code.
Kolumna wyników d.DemandID jest obliczana jako minimalny identyfikator zapotrzebowania, zaczynając od bieżącego lub 2147483648, jeśli nie znaleziono żadnego.
Kolumna wyników d.SupplyID jest obliczana jako minimalny identyfikator dostawy, zaczynając od bieżącego lub 2147483648, jeśli nie znaleziono żadnego.
Wynik TradeQuantity jest obliczany jako wartość RunningQuantity bieżącego wiersza minus wartość RunningQuantity poprzedniego wiersza.
Oto zawartość d:
DemandID SupplyID TradeQuantity--------- ----------- --------------1 1000 5.0000002 1000 3.0000003 1000 0.0000003 2000 6.0000003 3000 2.0000005 3000 0.0000005 4000 2.0000006 4000 0.0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.0000007 2147483648 3.0000008 2147483648 2.000000To, co pozostało do wykonania zewnętrznego zapytania, to odfiltrowanie zbędnych wierszy z d. Są to przypadki, w których ilość handlowa wynosi zero lub wpisy jednego rodzaju, których nie można dopasować do wpisów innego rodzaju (o identyfikatorze 2147483648).
Plan tego rozwiązania pokazano na rysunku 4.
Rysunek 4:Plan zapytania dla rozwiązania Petera
Podobnie jak plan Iana, plan Petera opiera się na jednym skanie danych wejściowych i używa trzech równoległych operatorów agregujących okna w trybie wsadowym do obliczenia różnych funkcji okna, poprzedzonych równoległymi operatorami sortowania. Dwa z nich są nieuniknione, co można zweryfikować, wymuszając plan seryjny. W planie Petera nie ma potrzeby stosowania operatora agregacji grupowych, jak w planie Iana.
Krytycznym spostrzeżeniem Petera, które pozwoliło na tak krótkie rozwiązanie, było uświadomienie sobie, że dla odpowiedniego wpisu jednego z rodzajów, pasujący identyfikator drugiego rodzaju zawsze pojawi się później (na podstawie RunningQuantity i kolejności kodu). Po obejrzeniu rozwiązania Petera z pewnością poczułem się, jakbym zbyt skomplikował swoje rzeczy!
Oto czasy działania w sekundach, które uzyskałem dla tego rozwiązania:
100K:0,197200K:0,412300K:0,558400K:0,696
Rozwiązanie Paula White'a
Nasze ostatnie rozwiązanie stworzył Paul White. Oto kompletny kod rozwiązania:
DROP TABLE, JEŚLI ISTNIEJE #MyPairings; CREATE TABLE #MyPairings( DemandID integer NOT NULL, SupplyID integer NOT NULL, TradeQuantity decimal(19, 6) NOT NULL);GO INSERT #MyPairings WITH (TABLOCK)( DemandID, SupplyID, TradeQuantity)SELECT Q3.DemandID, Q3.SupplyID, Q3.TradeQuantityFROM ( SELECT Q2.DemandID, Q2.SupplyID, TradeQuantity =-- Nakładanie się przedziałów CASE WHEN Q2.Code ='S' THEN CASE WHEN Q2.CumDemand>=Q2.IntEnd THEN Q2.IntLength WHEN Q2.CumDemand> Q2. IntStart TO Q2.CumDemand - Q2.IntStart ELSE 0.0 KONIEC GDY Q2.Kod ='D' TO PRZYPADEK GDY Q2.CumSupply>=Q2.IntEnd THEN Q2.IntLength KIEDY Q2.CumSupply> Q2.IntStart TO Q2.CumSupply - Q2. IntStart ELSE 0.0 KONIEC KONIEC Z ( WYBIERZ P1.Code, P1.IntStart, P1.IntEnd, P1.IntLength, DemandID =MAX(IIF(Q1.Code ='D', Q1.ID, 0)) OVER ( ZAMÓWIENIE WEDŁUG K1.IntStart, P1.ID WIERSZE BEZ OGRANICZEŃ PRECEDING), SupplyID =MAX(IIF(Q1.Code ='S', Q1.ID, 0)) OVER ( ORDER BY Q1.IntStart, Q1.ID ROWERS UNBOUNDED POSTĘPOWANIE), CumSupply =SUM(IIF(Q1.Code ='S', P1.IntLength, 0)) OVER ( ZAMÓWIENIE WEDŁUG P1.IntStart, P1.ID WIERSZE BEZ OGRANICZENIA POSTĘPOWANIA), CumDemand =SUM(IIF(Q1.Code ='D', Q1.IntLength, 0)) OVER ( ZAMÓW WEDŁUG KW1.IntStart, P1.ID WIERSZE BEZ OGRANICZEŃ Z POSTĘPEM) OD ( -- Przedziały zapotrzebowania WYBIERZ A.ID, A.Code, IntStart =SUM(A.Ilość) OVER ( KOLEJNOŚĆ WEDŁUG WIERSZÓW A.ID BEZ OGRANICZENIA POSTĘPOWANIA) - A. Ilość, IntEnd =SUM(A.Quantity) OVER ( ZAMÓWIENIE WEDŁUG WIERSZY A.ID BEZ OGRANICZENIA POCZĄTKUJĄCE), IntLength =A.Quantity FROM dbo.Auctions AS A WHERE A.Code ='D' UNION ALL -- Przedziały dostaw SELECT A.ID, A.Code, IntStart =SUM(A.Quantity) OVER ( ZAMÓWIENIE WEDŁUG WIERSZY A.ID BEZ POSTĘPOWANIA) - A.Quantity, IntEnd =SUM(A.Quantity) OVER ( ZAMÓWIENIE WEDŁUG WIERSZÓW A.ID BEZ POSTĘPOWANIA), IntLength =A.Ilość Z dbo.Aukcje JAK GDZIE A.Kod ='S' ) JAK Q1 ) AS Q2) JAK Q3GDZIE Q3.TradeQuantity> 0;Kod definiujący tabelę pochodną Q1 używa dwóch oddzielnych zapytań do obliczania interwałów popytu i podaży na podstawie bieżących sum i ujednolica je. Dla każdego interwału kod oblicza jego początek (IntStart), koniec (IntEnd) i długość (IntLength). Oto zawartość Q1 uporządkowana przez IntStart i ID:
Kod ID IntStart IntEnd IntLength----- ---- ---------- ---------- ----------1 D 0,000000 5.000000 5.0000001000 S 0.000000 8.000000 8.0000002 D 5.000000 8.000000 3.0000003 D 8.000000 16.000000 8.0000002000 S 8.000000 14.000000 6.0000003000 S 14.000000 16.000000 2.0000005 D 16.000000 18.000000 2.0000004000 S 16.000000 18.000000 2.0000006 D 18.000000 26.000000 8.0000005000 S 18.000000 2.00000000 6.0000003000 S 14.000000 16.000000 2.0000005 D 16.000000 18.000000 2.0000004000 D 30.000000 32.000000 2.000000Kod definiujący tabelę pochodną Q2 wysyła zapytania do Q1 i oblicza kolumny wyników o nazwach DemandID, SupplyID, CumSupply i CumDemand. Wszystkie funkcje okna używane przez ten kod są oparte na kolejności IntStart i ID oraz ramce ROWS UNBOUNDED PRECEDING (wszystkie rzędy do bieżącego).
DemandID to maksymalny identyfikator zapotrzebowania do bieżącego wiersza lub 0, jeśli żaden nie istnieje.
SupplyID to maksymalny identyfikator podaży do bieżącego wiersza lub 0, jeśli żaden nie istnieje.
CumSupply to skumulowane ilości dostaw (długości interwałów dostaw) do bieżącego wiersza.
CumDemand to skumulowane ilości zapotrzebowania (długości interwałów zapotrzebowania) do bieżącego wiersza.
Oto zawartość Q2:
Kod IntStart IntEnd IntLength ZapotrzebowanieID SupplyID CumSupply CumZapotrzebowanie---- ---------- ---------- ---------- ----- ---- --------- ---------- ----------D 0.000000 5.000000 5.000000 1 0 0.000000 5.000000S 0.000000 8.000000 8.000000 1 1000 8.000000 5.000000D 5.000000 8.000000 3.000000 2 1000 8.000000 8.000000D 8.000000 16.000000 8.000000 3 1000 8.000000 16.000000S 8.000000 14.000000 6.000000 3 2000 14.000000 16.000000S 14.000000 16.000000 2.000000 3 3000 16.000000 16.000000D 16.000000 18.000000 2.000000 5 3000 16.000000 18.000000S 16.008.00000 18.000000 18.000000 18.000000 8.000000 6 4000 18.000000 26.000000S 18.000000 22.000000 4.000000 6 5000 22.000000 26.000000S 22.000000 25.000000 3.000000 6 6000 25.000000 26.000000S 25.000000 27.000000 2.000000 6 7000 27.000000 26.000000D 26.000000 30.000000 4.000000 7 7000 27.000000 30.000000D 30.000000 32.000000 2.000000 8 7000 27.000000 32.000000Q2 already has the final result pairings’ correct DemandID and SupplyID values. The code defining the derived table Q3 queries Q2 and computes the result pairings’ TradeQuantity values as the overlapping segments of the demand and supply intervals. Finally, the outer query against Q3 filters only the relevant pairings where TradeQuantity is positive.
The plan for this solution is shown in Figure 5.
Figure 5:Query plan for Paul’s solution
The top two branches of the plan are responsible for computing the demand and supply intervals. Both rely on Index Seek operators to get the relevant rows based on index order, and then use parallel batch-mode Window Aggregate operators, preceded by Sort operators that theoretically could have been avoided. The plan concatenates the two inputs, sorts the rows by IntStart and ID to support the subsequent remaining Window Aggregate operator. Only this Sort operator is unavoidable in this plan. The rest of the plan handles the needed scalar computations and the final filter. That’s a very efficient plan!
Here are the run times in seconds I got for this solution:
100K:0.187200K:0.331300K:0.369400K:0.425These numbers are pretty impressive!
Performance Comparison
Figure 6 has a performance comparison between all solutions covered in this article.
Figure 6:Performance comparison
At this point, we can add the fastest solutions I covered in previous articles. Those are Joe’s and Kamil/Luca/Daniel’s solutions. The complete comparison is shown in Figure 7.
Figure 7:Performance comparison including earlier solutions
These are all impressively fast solutions, with the fastest being Paul’s and Peter’s.
Wniosek
When I originally introduced Peter’s puzzle, I showed a straightforward cursor-based solution that took 11.81 seconds to complete against a 400K-row input. The challenge was to come up with an efficient set-based solution. It’s so inspiring to see all the solutions people sent. I always learn so much from such puzzles both from my own attempts and by analyzing others’ solutions. It’s impressive to see several sub-second solutions, with Paul’s being less than half a second!
It's great to have multiple efficient techniques to handle such a classic need of matching supply with demand. Well done everyone!
[ Jump to:Original challenge | Solutions:Part 1 | Part 2 | Part 3 ]