Czy kiedykolwiek spotkałeś się z sytuacją, w której musisz zarządzać stanem podmiotu, który zmienia się w czasie? Istnieje wiele przykładów. Zacznijmy od prostego:scalania rekordów klientów.
Załóżmy, że łączymy listy klientów z dwóch różnych źródeł. Możemy mieć jeden z następujących stanów:Zidentyfikowano duplikaty – system znalazł dwa potencjalnie zduplikowane podmioty; Potwierdzone duplikaty – użytkownik potwierdza, że te dwa podmioty są rzeczywiście duplikatami; lub Potwierdzone unikatowe – użytkownik decyduje, że te dwa podmioty są unikalne. W każdej z tych sytuacji użytkownik musi podjąć tylko decyzję tak-nie.
Ale co z bardziej złożonymi sytuacjami? Czy istnieje sposób na zdefiniowanie rzeczywistego przepływu pracy między stanami? Czytaj dalej…
Jak sprawy mogą łatwo pójść nie tak
Wiele organizacji musi zarządzać podaniami o pracę. W prostym modelu możesz mieć tabelę o nazwie JOB_APPLICATION , i możesz śledzić stan aplikacji za pomocą referencyjnej tabeli danych zawierającej wartości takie jak:
| Stan aplikacji |
|---|
APPLICATION_RECEIVED |
APPLICATION_UNDER_REVIEW |
APPLICATION_REJECTED |
INVITED_TO_INTERVIEW |
INVITATION_DECLINED |
INVITATION_ACCEPTED |
INTERVIEW_PASSED |
INTERVIEW_FAILED |
REFERENCES_SOUGHT |
REFERENCES_ACCEPTABLE |
REFERENCES_UNACCEPTABLE |
JOB_OFFER_MADE |
JOB_OFFER_ACCEPTED |
JOB_OFFER_DECLINED |
APPLICATION_CLOSED |
Wartości te można wybrać w dowolnej kolejności w dowolnym momencie. Opiera się na użytkownikach końcowych, aby zapewnić logiczny i prawidłowy wybór na każdym etapie. Nic nie zabrania nielogicznej sekwencji stanów.
Załóżmy na przykład, że wniosek został odrzucony. Obecny stan to oczywiście APPLICATION_REJECTED . Na poziomie aplikacji nie można nic zrobić, aby uniemożliwić niedoświadczonemu użytkownikowi wybranie INVITED_TO_INTERVIEW lub inny nielogiczny stan.
Potrzebne jest coś, co poprowadzi użytkownika do wyboru następnego stanu logicznego, coś, co definiuje logiczny przepływ pracy .
A co, jeśli masz różne wymagania dotyczące różnych rodzajów podań o pracę? Na przykład niektóre prace mogą wymagać od kandydata zdania testu umiejętności. Oczywiście, możesz dodać do listy więcej wartości, aby je objąć, ale w obecnym projekcie nie ma nic, co uniemożliwia użytkownikowi końcowemu dokonanie nieprawidłowego wyboru dla danego typu aplikacji. W rzeczywistości istnieją różne przepływy pracy dla różnych kontekstów .
Kolejna kwestia do przemyślenia:czy wymienione opcje to naprawdę wszystkie stany ? A może w rzeczywistości są wyniki ? Na przykład oferta pracy może zostać przyjęta lub odrzucona przez kandydata. Dlatego JOB_OFFER_MADE tak naprawdę ma dwa wyniki:JOB_OFFER_ACCEPTED i JOB_OFFER_DECLINED .
Innym skutkiem może być wycofanie oferty pracy. Możesz zapisać przyczynę wycofania za pomocą kwalifikatora. Jeśli po prostu dodasz te powody do powyższej listy, nic nie skłania użytkownika końcowego do dokonywania logicznych wyborów.
Tak więc im bardziej złożone stają się stany, wyniki i kwalifikatory, tym bardziej trzeba zdefiniować przepływ pracy procesu .
Organizowanie procesów, stanów i wyników
Ważne jest, aby zrozumieć, co się dzieje z Twoimi danymi, zanim spróbujesz je zamodelować. Możesz na początku pomyśleć, że istnieje tu ścisła hierarchia typów:
Kiedy przyjrzymy się bliżej powyższemu przykładowi, zobaczymy, że INVITED_TO_INTERVIEW i JOB_OFFER_MADE stany mają te same możliwe wyniki, a mianowicie ACCEPTED i DECLINED . To mówi nam, że istnieje relacja „wielu do wielu” między stanami i wynikami. Często dotyczy to innych stanów, wyników i kwalifikatorów.
Na poziomie koncepcyjnym tak naprawdę dzieje się z naszymi metadanymi:
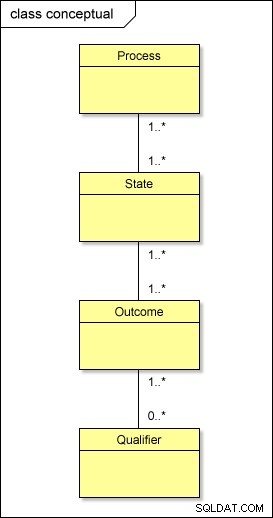
Gdybyś miał przekształcić ten model do świata fizycznego przy użyciu standardowego podejścia, miałbyś tabele o nazwie PROCESS , STATE , OUTCOME i QUALIFIER; potrzebujesz także tabeli pośrednich między nimi – PROCESS_STATE , STATE_OUTCOME i OUTCOME_QUALIFIER – rozwiązać relacje wiele-do-wielu . To komplikuje projekt.
Chociaż logiczna hierarchia poziomów (proces → stan → wynik → kwalifikator) musi być zachowana, istnieje prostszy sposób na fizyczne uporządkowanie naszych metadanych.
Wzorzec przepływu pracy
Poniższy diagram definiuje główne elementy modelu bazy danych przepływu pracy:
Żółte tabele po lewej stronie zawierają metadane przepływu pracy, a niebieskie tabele po prawej zawierają dane biznesowe.
Pierwszą rzeczą, na którą należy zwrócić uwagę, jest to, że każdy podmiot może być zarządzany bez konieczności wprowadzania większych zmian w tym modelu. YOUR_ENTITIY_TO_MANAGE tabela to ta pod zarządzaniem przepływem pracy. W naszym przykładzie byłby to JOB_APPLICATION stół.
Następnie wystarczy dodać wf_state_type_process_id kolumny do dowolnej tabeli, którą chcemy zarządzać. Ta kolumna wskazuje rzeczywisty proces przepływu pracy wykorzystywane do zarządzania jednostką. To nie jest wyłącznie kolumna klucza obcego, ale umożliwia nam szybkie zapytanie WORKFLOW_STATE_TYPE dla prawidłowego procesu. Tabela, która będzie zawierać historię stanu to MANAGED_ENTITY_STATE . Ponownie, możesz wybrać tutaj swoją własną nazwę tabeli i zmodyfikować ją zgodnie z własnymi wymaganiami.
Metadane
Różne poziomy przepływu pracy są zdefiniowane w WORKFLOW_LEVEL_TYPE . Ta tabela zawiera następujące informacje:
| Klucz typu | Opis |
|---|---|
| PROCES | Proces przepływu pracy na wysokim poziomie. |
| STAN | Stan w procesie. |
| WYNIK | Jak kończy się stan, jego wynik. |
| KWALIFIKATOR | Opcjonalny, bardziej szczegółowy kwalifikator wyniku. |
WORKFLOW_STATE_TYPE i WORKFLOW_STATE_HIERARCHY utworzyć klasyczną strukturę zestawienia komponentów (BOM) . Ta struktura, która bardzo opisuje rzeczywisty wykaz materiałów produkcyjnych, jest dość powszechna w modelowaniu danych. Może definiować hierarchie lub być stosowany do wielu sytuacji rekurencyjnych. Wykorzystamy to tutaj, aby zdefiniować naszą logiczną hierarchię procesów, stanów, wyników i opcjonalnych kwalifikatorów.
Zanim będziemy mogli zdefiniować hierarchię, musimy zdefiniować poszczególne składniki. To są nasze podstawowe elementy konstrukcyjne. Odwołam się do nich za pomocą TYPE_KEY (co jest wyjątkowe) ze względu na zwięzłość. W naszym przykładzie mamy:
| Typ poziomu przepływu pracy | Klucz Type.Type stanu przepływu pracy |
|---|---|
| WYNIK | ZALICZONE |
| WYNIK | NIEUDAŁO SIĘ |
| WYNIK | ZAAKCEPTOWANE |
| WYNIK | ODRZUCONY |
| WYNIK | CANDIDATE_CANCELLED |
| WYNIK | EMPLOYER_CANCELLED |
| WYNIK | ODRZUCONE |
| WYNIK | EMPLOYER_WITDRAWN |
| WYNIK | NIE_POKAŻ |
| WYNIK | ZATRUDNIONY |
| WYNIK | NOT_HIRED |
| STAN | APPLICATION_RECEIVED |
| STAN | APPLICATION_REVIEW |
| STAN | INVITED_TO_INTERVIEW |
| STAN | WYWIAD |
| STAN | TEST_APTITUDE |
| STAN | SEEK_REFERENCES |
| STAN | MAKE_OFFER |
| STAN | APPLICATION_CLOSED |
| PROCES | STANDARD_JOB_APPLICATION |
| PROCES | TECHNICAL_JOB_APPLICATION |
Teraz możemy zacząć definiować naszą hierarchię. To tutaj bierzemy nasze cegiełki i definiujemy naszą strukturę. Dla każdego stanu określamy możliwe wyniki. W rzeczywistości zasadą tego systemu przepływu pracy jest to, że każdy stan musi się zakończyć z wynikiem:
| Typ nadrzędny – STANY | Typ dziecka – WYNIKI |
|---|---|
| APPLICATION_RECEIVED | ZAAKCEPTOWANE |
| APPLICATION_RECEIVED | ODRZUCONE |
| APPLICATION_REVIEW | ZALICZONE |
| APPLICATION_REVIEW | NIEUDAŁO SIĘ |
| INVITED_TO_INTERVIEW | ZAAKCEPTOWANE |
| INVITED_TO_INTERVIEW | ODRZUCONY |
| WYWIAD | ZALICZONE |
| WYWIAD | NIEUDAŁO SIĘ |
| WYWIAD | CANDIDATE_CANCELLED |
| WYWIAD | NIE_POKAŻ |
| MAKE_OFFER | ZAAKCEPTOWANE |
| MAKE_OFFER | ODRZUCONY |
| SEEK_REFERENCES | ZALICZONE |
| SEEK_REFERENCES | NIEUDAŁO SIĘ |
| APPLICATION_CLOSED | ZATRUDNIONY |
| APPLICATION_CLOSED | NOT_HIRED |
| TEST_APTITUDE | ZALICZONE |
| TEST_APTITUDE | NIEUDAŁO SIĘ |
Nasze procesy to po prostu zbiór stanów, z których każdy istnieje przez pewien czas. W poniższej tabeli są one przedstawione w logicznej kolejności, ale to nie definiuje faktycznej kolejności przetwarzania.
| Typ nadrzędny – PROCESY | Typ dziecka – STANY |
|---|---|
| STANDARD_JOB_APPLICATION | APPLICATION_RECEIVED |
| STANDARD_JOB_APPLICATION | APPLICATION_REVIEW |
| STANDARD_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| STANDARD_JOB_APPLICATION | WYWIAD |
| STANDARD_JOB_APPLICATION | MAKE_OFFER |
| STANDARD_JOB_APPLICATION | SEEK_REFERENCES |
| STANDARD_JOB_APPLICATION | APPLICATION_CLOSED |
| TECHNICAL_JOB_APPLICATION | APPLICATION_RECEIVED |
| TECHNICAL_JOB_APPLICATION | APPLICATION_REVIEW |
| TECHNICAL_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| TECHNICAL_JOB_APPLICATION | TEST_APTITUDE |
| TECHNICAL_JOB_APPLICATION | WYWIAD |
| TECHNICAL_JOB_APPLICATION | MAKE_OFFER |
| TECHNICAL_JOB_APPLICATION | SEEK_REFERENCES |
| TECHNICAL_JOB_APPLICATION | APPLICATION_CLOSED |
Jest ważny punkt dotyczący hierarchii BOM. Podobnie jak fizyczne zestawienie materiałów definiuje zespoły i podzespoły aż do najmniejszych komponentów, mamy podobny układ w naszej hierarchii. Oznacza to, że możemy ponownie wykorzystać „zespoły” i „podzespoły”.
Na przykład:Zarówno STANDARD_JOB_APPLICATION i TECHNICAL_JOB_APPLICATION procesy mieć INTERVIEW stan . Z kolei INTERVIEW stan ma PASSED , FAILED , CANDIDATE_CANCELLED i NO_SHOW wyniki zdefiniowany dla niego.
Kiedy używasz stanu w procesie, automatycznie otrzymujesz z nim jego wyniki potomne, ponieważ jest to już asembler. Oznacza to, że te same wyniki istnieją dla obu rodzajów podania o pracę w INTERVIEW scena. Jeśli chcesz uzyskać różne wyniki rozmów kwalifikacyjnych dla różnych typów aplikacji o pracę, musisz zdefiniować, powiedzmy, TECHNICAL_INTERVIEW i STANDARD_INTERVIEW stwierdza, że każdy ma swoje własne, specyficzne wyniki.
W tym przykładzie jedyną różnicą między tymi dwoma typami podania o pracę jest to, że podanie o pracę o charakterze technicznym zawiera test umiejętności.
Zanim wyruszysz
W części 1 tego dwuczęściowego artykułu przedstawiono wzorzec bazy danych przepływu pracy. Pokazał, jak można go włączyć do zarządzania cyklem życia dowolnego podmiotu w bazie danych.
Część 2 pokaże Ci jak zdefiniować rzeczywisty przepływ pracy przy użyciu dodatkowych tabel konfiguracyjnych. W tym miejscu użytkownik zostanie przedstawiony z dopuszczalnymi kolejnymi krokami. Zademonstrujemy również technikę obejścia ścisłego ponownego użycia „zespołów” i „podzespołów” w zestawieniach komponentów.