Po moim wpisie w zeszłym tygodniu pojawiło się wiele komentarzy na temat dzielenia ciągów. Myślę, że sens tego artykułu nie był tak oczywisty, jak mogłoby być:poświęcenie dużej ilości czasu i wysiłku na „udoskonalenie” z natury powolnej funkcji dzielenia opartej na T-SQL nie byłoby korzystne. Od tego czasu zebrałem najnowszą wersję funkcji dzielenia ciągów Jeffa Modena i porównałem ją z innymi:
ALTER FUNCTION [dbo].[DelimitedSplitN4K]
(@pString NVARCHAR(4000), @pDelimiter NCHAR(1))
RETURNS TABLE WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS (
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
cteTally(N) AS (SELECT TOP (ISNULL(DATALENGTH(@pString)/2,0))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4),
cteStart(N1) AS (SELECT 1 UNION ALL
SELECT t.N+1 FROM cteTally t WHERE SUBSTRING(@pString,t.N,1) = @pDelimiter
),
cteLen(N1,L1) AS(SELECT s.N1,
ISNULL(NULLIF(CHARINDEX(@pDelimiter,@pString,s.N1),0)-s.N1,4000)
FROM cteStart s
)
SELECT ItemNumber = ROW_NUMBER() OVER(ORDER BY l.N1),
Item = SUBSTRING(@pString, l.N1, l.L1)
FROM cteLen l;
GO (Jedyne zmiany, jakie wprowadziłem:sformatowałem go do wyświetlania i usunąłem komentarze. Możesz pobrać oryginalne źródło tutaj.)
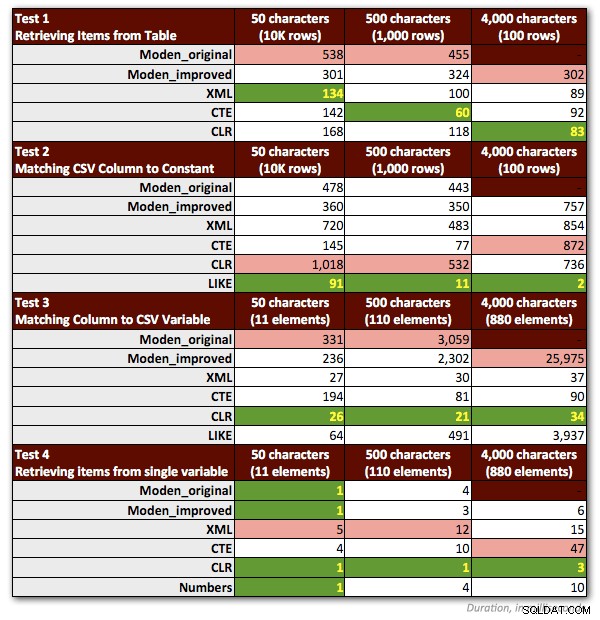
Musiałem dokonać kilku poprawek w moich testach, aby uczciwie przedstawić funkcję Jeffa. Co najważniejsze:musiałem odrzucić wszystkie próbki, które zawierały jakiekolwiek ciągi> 4000 znaków. Zmieniłem więc ciągi 5000 znaków w tabeli dbo.strings na 4000 znaków i skupiłem się tylko na pierwszych trzech scenariuszach innych niż MAX (zachowując poprzednie wyniki dla pierwszych dwóch i ponownie przeprowadzając trzecie testy dla nowego długości ciągów 4000 znaków). Pominąłem również tabelę Liczby we wszystkich testach z wyjątkiem jednego, ponieważ było jasne, że tam wydajność zawsze była gorsza co najmniej 10 razy. Poniższa tabela pokazuje wydajność funkcji w każdym z czterech testów, ponownie uśredniona z 10 przebiegów i zawsze z zimną pamięcią podręczną i czystymi buforami.
Oto moje nieco zmienione preferowane metody dla każdego rodzaju zadania:
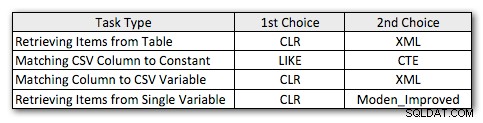
Zauważysz, że CLR pozostało moją wybraną metodą, z wyjątkiem jednego przypadku, w którym dzielenie nie ma sensu. A w przypadkach, w których CLR nie wchodzi w grę, metody XML i CTE są ogólnie bardziej wydajne, z wyjątkiem przypadku dzielenia jednej zmiennej, gdzie funkcja Jeffa może być najlepszą opcją. Ale biorąc pod uwagę, że mogę potrzebować obsługiwać więcej niż 4000 znaków, rozwiązanie tabeli liczb może po prostu wrócić na moją listę w określonych sytuacjach, w których nie mogę używać CLR.
Obiecuję, że mój następny post dotyczący list nie będzie w ogóle mówił o dzieleniu za pomocą T-SQL lub CLR i pokażę, jak uprościć ten problem niezależnie od typu danych.
Na marginesie zauważyłem ten komentarz w jednej z wersji funkcji Jeffa, która została zamieszczona w komentarzach:Dziękuję również temu, kto napisał pierwszy artykuł, jaki kiedykolwiek widziałem na „tablicach liczbowych”, który znajduje się pod następującym adresem URL i Adamowi Machanici za doprowadzenie mnie do tego wiele lat temu.https://web.archive.org/web/20150411042510/https://sqlserver2000.databases.aspfaq.com/why-should-i-consider-using-an -tabela-liczb-pomocniczych.html
Ten artykuł został napisany przeze mnie w 2004 roku. Więc ktokolwiek dodał komentarz do funkcji, zapraszamy. :-)