W 2013 roku pisałem o błędzie w optymalizatorze, w którym 2 i 3 argumenty funkcji DATEDIFF() można zamienić – co może prowadzić do nieprawidłowych szacunków liczby wierszy, a co za tym idzie do złego wyboru planu wykonania:
- Niespodzianki i założenia dotyczące wydajności:DATEDIFF
W miniony weekend dowiedziałem się o podobnej sytuacji i od razu założyłem, że to ten sam problem. W końcu objawy wydawały się prawie identyczne:
- Istniała funkcja daty/czasu w
WHEREklauzula.- Tym razem było to
DATEADD()zamiastDATEDIFF().
- Tym razem było to
- Istnieje oczywiście niepoprawna szacunkowa liczba wierszy wynosząca 1 w porównaniu z rzeczywistą liczbą wierszy przekraczającą 3 miliony.
- W rzeczywistości było to oszacowanie równe 0, ale SQL Server zawsze zaokrągla takie szacunki do 1.
- Dokonano złego wyboru planu (w tym przypadku wybrano połączenie w pętli) ze względu na niskie oszacowanie.
Obraźliwy wzór wyglądał tak:
WHERE [datetime2(7) column] >= DATEADD(DAY, -365, SYSUTCDATETIME());
Użytkownik wypróbował kilka wariantów, ale nic się nie zmieniło; w końcu udało im się obejść problem, zmieniając predykat na:
WHERE DATEDIFF(DAY, [column], SYSUTCDATETIME()) <= 365;
Otrzymano lepsze oszacowanie (typowe 30% nierówności); więc nie do końca w porządku. I chociaż wyeliminowano łączenie w pętli, istnieją dwa główne problemy z tym predykatem:
- To nie to samo zapytanie, ponieważ teraz szuka granic 365 dni, które zostały przekroczone, w przeciwieństwie do przekroczenia określonego punktu w czasie 365 dni temu. Statystycznie istotny? Może nie. Ale technicznie rzecz biorąc to nie to samo.
- Zastosowanie funkcji do kolumny sprawia, że całe wyrażenie nie jest argowalne – co prowadzi do pełnego skanowania. Gdy tabela zawiera tylko nieco ponad rok danych, nie jest to wielka sprawa, ale gdy tabela się powiększa lub predykat staje się węższy, staje się to problemem.
Ponownie doszedłem do wniosku, że DATEADD() operacja była problemem i zaleciłem podejście, które nie opierało się na DATEADD() – budowanie datetime ze wszystkich części bieżącego czasu, co pozwala mi odjąć rok bez użycia DATEADD() :
WHERE [column] >= DATETIMEFROMPARTS(
DATEPART(YEAR, SYSUTCDATETIME())-1,
DATEPART(MONTH, SYSUTCDATETIME()),
DATEPART(DAY, SYSUTCDATETIME()),
DATEPART(HOUR, SYSUTCDATETIME()),
DATEPART(MINUTE, SYSUTCDATETIME()),
DATEPART(SECOND, SYSUTCDATETIME()), 0); Oprócz tego, że było to nieporęczne, miało to swoje własne problemy, a mianowicie, że trzeba było dodać trochę logiki, aby prawidłowo uwzględnić lata przestępne. Po pierwsze, aby nie zawieść, jeśli zdarzy się, że zostanie uruchomiony 29 lutego, a po drugie, aby we wszystkich przypadkach uwzględnić dokładnie 365 dni (zamiast 366 w ciągu roku następującego po dniu przestępnym). Oczywiście proste poprawki, ale sprawiają, że logika jest znacznie brzydsza – zwłaszcza, że zapytanie musiało istnieć w widoku, w którym zmienne pośrednie i wiele kroków nie są możliwe.
W międzyczasie OP złożył element Connect, przerażony szacunkiem dla jednego wiersza:
- Połącz #2567628:Ograniczenie z DateAdd() nie zapewnia dobrych szacunków
Wtedy pojawił się Paul White (@SQL_Kiwi) i, jak wiele razy wcześniej, rzucił dodatkowe światło na problem. Udostępnił powiązany element Connect złożony przez Erlanda Sommarskoga w 2011 roku:
- Połącz #685903:Nieprawidłowe oszacowanie, gdy sysdatetime pojawia się w wyrażeniu dateadd()
Zasadniczo problem polega na tym, że złego oszacowania można dokonać nie tylko wtedy, gdy SYSDATETIME() (lub SYSUTCDATETIME() ) pojawia się, jak pierwotnie poinformował Erland, ale gdy jakikolwiek datetime2 wyrażenie jest zaangażowane w predykat (i być może tylko wtedy, gdy DATEADD() jest również używany). I może działać w obie strony – jeśli zamienimy >= dla <= , oszacowanie staje się całą tabelą, więc wydaje się, że optymalizator patrzy na SYSDATETIME() wartość jako stałą i całkowicie ignorując wszelkie operacje, takie jak DATEADD() które są wykonywane przeciwko niemu.
Paul powiedział, że obejście tego problemu polega po prostu na użyciu datetime równoważne podczas obliczania daty, przed konwersją na odpowiedni typ danych. W takim przypadku możemy zamienić SYSUTCDATETIME() i zmień go na GETUTCDATE() :
WHERE [column] >= CONVERT(datetime2(7), DATEADD(DAY, -365, GETUTCDATE()));
Tak, powoduje to niewielką utratę precyzji, ale cząsteczka kurzu może spowalniać palec w drodze do naciśnięcia

Odczyty są podobne, ponieważ tabela zawiera dane prawie wyłącznie z ostatniego roku, więc nawet wyszukiwanie staje się skanowaniem zasięgu większości tabeli. Liczby wierszy nie są identyczne, ponieważ (a) drugie zapytanie kończy się o północy i (b) trzecie zapytanie zawiera dodatkowy dzień danych ze względu na dzień przestępny na początku tego roku. W każdym razie to nadal pokazuje, jak możemy zbliżyć się do właściwych szacunków, eliminując DATEADD() , ale właściwym rozwiązaniem jest usunięcie bezpośredniej kombinacji z DATEADD() i datetime2 .
Aby dodatkowo zilustrować, w jaki sposób szacunki są błędne, możesz zobaczyć, że jeśli przekażemy różne argumenty i wskazówki do oryginalnego zapytania i przepisania przez Paula, liczba szacowanych wierszy dla pierwszego jest zawsze oparta na bieżącym czasie – nie nie zmienia się wraz z liczbą dni, które minęły (podczas gdy Paul jest za każdym razem stosunkowo dokładny):
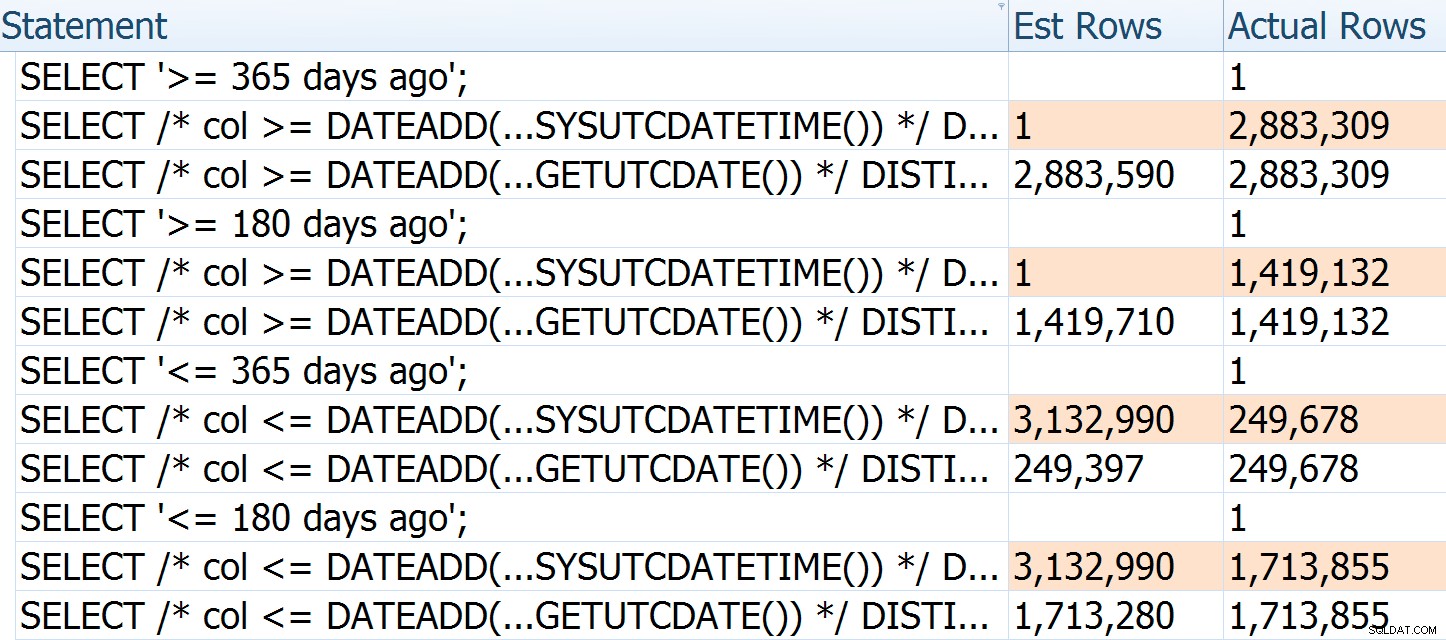 Rzeczywiste wiersze dla pierwszego zapytania są nieco niższe, ponieważ zostało to wykonane po długiej drzemce
Rzeczywiste wiersze dla pierwszego zapytania są nieco niższe, ponieważ zostało to wykonane po długiej drzemce
Szacunki nie zawsze będą tak dobre; mój stół ma po prostu stosunkowo stabilną dystrybucję. Wypełniłem je następującym zapytaniem, a następnie zaktualizowałem statystyki za pomocą pełnego skanowania, na wypadek gdybyś chciał sam wypróbować to:
-- OP's table definition:
CREATE TABLE dbo.DateaddRepro
(
SessionId int IDENTITY(1, 1) NOT NULL PRIMARY KEY,
CreatedUtc datetime2(7) NOT NULL DEFAULT SYSUTCDATETIME()
);
GO
CREATE NONCLUSTERED INDEX [IX_User_Session_CreatedUtc]
ON dbo.DateaddRepro(CreatedUtc) INCLUDE (SessionId);
GO
INSERT dbo.DateaddRepro(CreatedUtc)
SELECT dt FROM
(
SELECT TOP (3150000) dt = DATEADD(HOUR, (s1.[precision]-ROW_NUMBER()
OVER (PARTITION BY s1.[object_id] ORDER BY s2.[object_id])) / 15, GETUTCDATE())
FROM sys.all_columns AS s1 CROSS JOIN sys.all_objects AS s2
) AS x;
UPDATE STATISTICS dbo.DateaddRepro WITH FULLSCAN;
SELECT DISTINCT SessionId FROM dbo.DateaddRepro
WHERE /* pick your WHERE clause to test */; Skomentowałem nowy element Connect i prawdopodobnie wrócę i poprawię moją odpowiedź na Stack Exchange.
Moralność tej historii
Staraj się unikać łączenia DATEADD() z wyrażeniami, które dają datetime2 , zwłaszcza w starszych wersjach SQL Server (tak było w SQL Server 2012). Może to również stanowić problem, nawet w programie SQL Server 2016, podczas korzystania ze starszego modelu szacowania kardynalności (ze względu na niższy poziom zgodności lub jawne użycie flagi śledzenia 9481). Takie problemy są subtelne i nie zawsze od razu oczywiste, więc miejmy nadzieję, że służy to jako przypomnienie (może nawet dla mnie następnym razem, gdy natknę się na podobny scenariusz). Tak jak sugerowałem w poprzednim poście, jeśli masz takie wzorce zapytań, sprawdź, czy otrzymujesz poprawne szacunki, i zanotuj je gdzieś, aby sprawdzić je ponownie za każdym razem, gdy w systemie zajdzie jakaś poważna zmiana (np. aktualizacja lub dodatek Service Pack).