Dodanie filtrowanego indeksu może mieć zaskakujące skutki uboczne w istniejących zapytaniach, nawet jeśli wydaje się, że nowy filtrowany indeks jest całkowicie niepowiązany. Ten post dotyczy przykładu wpływającego na instrukcje DELETE, które skutkuje niską wydajnością i zwiększonym ryzykiem zakleszczenia.
Środowisko testowe
Poniższa tabela będzie używana w tym poście:
CREATE TABLE dbo.Data
(
RowID integer IDENTITY NOT NULL,
SomeValue integer NOT NULL,
StartDate date NOT NULL,
CurrentFlag bit NOT NULL,
Padding char(50) NOT NULL DEFAULT REPLICATE('ABCDE', 10),
CONSTRAINT PK_Data_RowID
PRIMARY KEY CLUSTERED (RowID)
); Ta następna instrukcja tworzy 499 999 wierszy przykładowych danych:
INSERT dbo.Data WITH (TABLOCKX)
(SomeValue, StartDate, CurrentFlag)
SELECT
CONVERT(integer, RAND(n) * 1e6) % 1000,
DATEADD(DAY, (N.n - 1) % 31, '20140101'),
CONVERT(bit, 0)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n < 500000; Używa tabeli Numbers jako źródła kolejnych liczb całkowitych od 1 do 499 999. Jeśli nie masz takiego w swoim środowisku testowym, poniższy kod może być użyty do efektywnego utworzenia takiego zawierającego liczby całkowite od 1 do 1 000 000:
WITH
N1 AS (SELECT N1.n FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS N1 (n)),
N2 AS (SELECT L.n FROM N1 AS L CROSS JOIN N1 AS R),
N3 AS (SELECT L.n FROM N2 AS L CROSS JOIN N2 AS R),
N4 AS (SELECT L.n FROM N3 AS L CROSS JOIN N2 AS R),
N AS (SELECT ROW_NUMBER() OVER (ORDER BY n) AS n FROM N4)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM N
OPTION (MAXDOP 1);
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1); Podstawą późniejszych testów będzie usunięcie wierszy z tabeli testowej dla określonej daty rozpoczęcia. Aby proces identyfikowania wierszy do usunięcia był bardziej wydajny, dodaj ten nieklastrowany indeks:
CREATE NONCLUSTERED INDEX
IX_Data_StartDate
ON dbo.Data
(StartDate); Przykładowe dane
Po wykonaniu tych kroków próbka będzie wyglądać tak:
SELECT TOP (100)
D.RowID,
D.SomeValue,
D.StartDate,
D.CurrentFlag,
D.Padding
FROM dbo.Data AS D
ORDER BY
D.RowID;
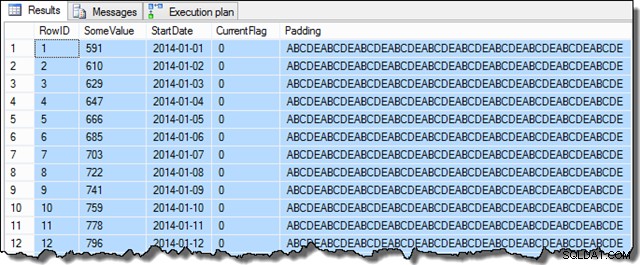
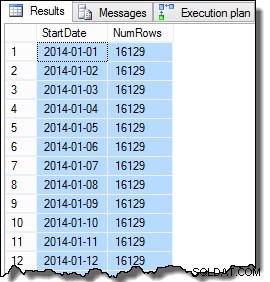
Dane w kolumnie SomeValue mogą się nieznacznie różnić ze względu na pseudolosowe generowanie, ale ta różnica nie jest istotna. Ogólnie rzecz biorąc, przykładowe dane zawierają 16 129 wierszy dla każdej z 31 dat rozpoczęcia w styczniu 2014 r.:
SELECT
D.StartDate,
NumRows = COUNT_BIG(*)
FROM dbo.Data AS D
GROUP BY
D.StartDate
ORDER BY
D.StartDate;
Ostatnim krokiem, jaki musimy wykonać, aby dane były nieco realistyczne, jest ustawienie kolumny CurrentFlag na true dla najwyższego RowID dla każdej daty początkowej. Zadanie to wykonuje następujący skrypt:
WITH LastRowPerDay AS
(
SELECT D.CurrentFlag
FROM dbo.Data AS D
WHERE D.RowID =
(
SELECT MAX(D2.RowID)
FROM dbo.Data AS D2
WHERE D2.StartDate = D.StartDate
)
)
UPDATE LastRowPerDay
SET CurrentFlag = 1; Plan wykonania tej aktualizacji zawiera kombinację segmentu, aby skutecznie zlokalizować najwyższy RowID dziennie:

Zwróć uwagę, że plan wykonania w niewielkim stopniu przypomina pisemną formę zapytania. Jest to doskonały przykład działania optymalizatora na podstawie logicznej specyfikacji SQL, a nie bezpośredniej implementacji SQL. Jeśli się zastanawiasz, szpula stołu Chętna w tym planie jest wymagana do ochrony Halloween.
Usuwanie dnia danych
Ok, więc po zakończeniu wstępnych zadań mamy do czynienia z usunięciem wierszy dla określonej daty rozpoczęcia. Jest to rodzaj zapytania, które można rutynowo uruchamiać najwcześniej w tabeli, gdy dane osiągnęły koniec okresu użytkowania.
Biorąc za przykład 1 stycznia 2014 r., testowe zapytanie usuwające jest proste:
DELETE dbo.Data WHERE StartDate = '20140101';
Plan wykonania jest również dość prosty, choć warto przyjrzeć się mu trochę szczegółowo:

Analiza planu
Wyszukiwanie indeksu po prawej stronie korzysta z indeksu nieklastrowanego, aby znaleźć wiersze dla określonej wartości StartDate. Zwraca tylko znalezione wartości RowID, co potwierdza etykietka operatora:
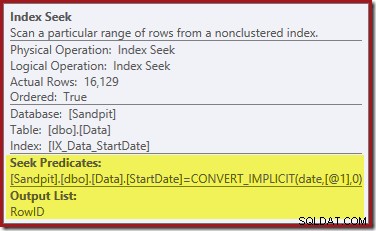
Jeśli zastanawiasz się, w jaki sposób indeks Data rozpoczęcia zwraca RowID, pamiętaj, że RowID jest unikalnym indeksem klastrowym dla tabeli, więc jest on automatycznie uwzględniany w indeksie nieklastrowym Data rozpoczęcia.
Następnym operatorem w planie jest Clustered Index Delete. Wykorzystuje wartość RowID znalezioną przez funkcję Index Seek, aby zlokalizować wiersze do usunięcia.
Ostatnim operatorem w planie jest Index Delete. Spowoduje to usunięcie wierszy z indeksu nieklastrowanego IX_Data_StartDate które są związane z RowID usuniętym przez usuwanie indeksu klastrowego. Aby zlokalizować te wiersze w indeksie nieklastrowym, procesor zapytań potrzebuje daty początkowej (klucz dla indeksu nieklastrowego).
Pamiętaj, że oryginalna funkcja Index Seek nie zwracała daty rozpoczęcia, tylko RowID. Jak więc procesor zapytań uzyskuje datę rozpoczęcia dla usunięcia indeksu? W tym konkretnym przypadku optymalizator mógł zauważyć, że wartość StartDate jest stała i zoptymalizować ją, ale tak się nie stało. Odpowiedź brzmi:operator Clustered Index Delete odczyt wartość StartDate dla bieżącego wiersza i dodaje ją do strumienia. Porównaj listę wyników dla usuwania indeksu klastrowego pokazaną poniżej z listą wyszukiwania indeksu tuż powyżej:
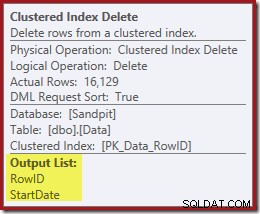
Może wydawać się zaskakujące, że operator Delete odczytuje dane, ale tak to działa. Procesor zapytań wie, że będzie musiał zlokalizować wiersz w indeksie klastrowym, aby go usunąć, więc może równie dobrze odroczyć odczytywanie kolumn potrzebnych do utrzymania indeksów nieklastrowanych do tego czasu, jeśli to możliwe.
Dodawanie filtrowanego indeksu
Teraz wyobraź sobie, że ktoś ma kluczowe zapytanie do tej tabeli, która działa źle. Pomocny administrator danych przeprowadza analizę i dodaje następujący filtrowany indeks:
CREATE NONCLUSTERED INDEX
FIX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue)
INCLUDE (CurrentFlag)
WHERE CurrentFlag = 1; Nowy filtrowany indeks ma pożądany wpływ na problematyczne zapytanie i wszyscy są zadowoleni. Zwróć uwagę, że nowy indeks w ogóle nie odwołuje się do kolumny Data rozpoczęcia, więc nie oczekujemy, że w ogóle wpłynie to na nasze zapytanie usuwające dzień.
Usuwanie dnia z filtrowanym indeksem
Możemy przetestować to oczekiwanie, usuwając dane po raz drugi:
DELETE dbo.Data WHERE StartDate = '20140102';
Nagle plan wykonania zmienił się na równoległe skanowanie indeksu klastrowego:

Zwróć uwagę, że dla nowego filtrowanego indeksu nie ma oddzielnego operatora Index Delete. Optymalizator wybrał utrzymanie tego indeksu wewnątrz operatora Clustered Index Delete. Jest to wyróżnione w Eksploratorze planów SQL Sentry, jak pokazano powyżej („+1 nieklastrowane indeksy”), z pełnymi szczegółami w podpowiedzi:
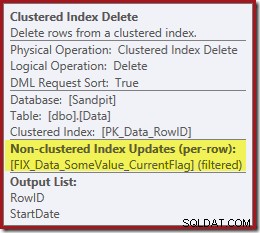
Jeśli tabela jest duża (pomyśl o hurtowni danych), ta zmiana na skanowanie równoległe może być bardzo istotna. Co się stało z fajnym wyszukiwaniem indeksu w dniu rozpoczęcia i dlaczego zupełnie niepowiązany filtrowany indeks zmienił sytuację tak drastycznie?
Znajdowanie problemu
Pierwsza wskazówka pochodzi z przyjrzenia się właściwościom klastrowego skanowania indeksu:
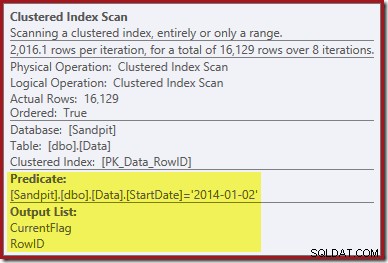
Oprócz znajdowania wartości RowID dla operatora Clustered Index Delete do usunięcia, ten operator odczytuje teraz wartości CurrentFlag. Zapotrzebowanie na tę kolumnę jest niejasne, ale przynajmniej zaczyna wyjaśniać decyzję o skanowaniu:kolumna CurrentFlag nie jest częścią naszego nieklastrowego indeksu Data rozpoczęcia.
Możemy to potwierdzić, przepisując zapytanie usuwające, aby wymusić użycie nieklastrowanego indeksu Data rozpoczęcia:
DELETE D
FROM dbo.Data AS D
WITH (INDEX(IX_Data_StartDate))
WHERE StartDate = '20140103'; Plan wykonania jest bliższy pierwotnej formie, ale zawiera teraz funkcję Key Lookup:
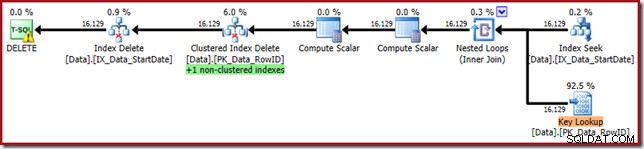
Właściwości Key Lookup potwierdzają, że ten operator pobiera wartości CurrentFlag:
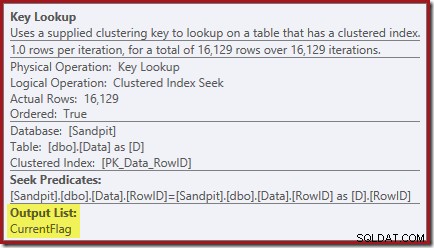
Być może zauważyłeś również trójkąty ostrzegawcze w ostatnich dwóch planach. Są to ostrzeżenia o braku indeksu:
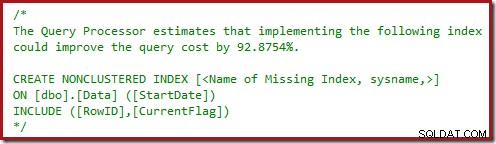
Jest to dalsze potwierdzenie, że SQL Server chciałby widzieć kolumnę CurrentFlag uwzględnioną w indeksie nieklastrowanym. Powód zmiany na równoległe skanowanie indeksu klastrowego jest teraz jasny:procesor zapytań decyduje, że skanowanie tabeli będzie tańsze niż wykonywanie wyszukiwania kluczy.
Tak, ale dlaczego?
To wszystko jest bardzo dziwne. W pierwotnym planie wykonania SQL Server mógł czytać dodatkowe dane kolumnowe potrzebne do utrzymania indeksów nieklastrowanych w operatorze Clustered Index Delete. Wartość kolumny CurrentFlag jest potrzebna do utrzymania filtrowanego indeksu, więc dlaczego SQL Server nie obsługuje go po prostu w ten sam sposób?
Krótka odpowiedź brzmi, że może, ale tylko wtedy, gdy filtrowany indeks jest utrzymywany w osobnym operatorze Index Delete. Możemy wymusić to dla bieżącego zapytania za pomocą flagi 8790 nieudokumentowanego śledzenia. Bez tej flagi optymalizator decyduje, czy każdy indeks ma być utrzymywany w oddzielnym operatorze, czy jako część operacji na tabeli bazowej.
-- Forced wide update plan DELETE dbo.Data WHERE StartDate = '20140105' OPTION (QUERYTRACEON 8790);
Plan wykonania powraca do szukania nieklastrowanego indeksu Data rozpoczęcia:
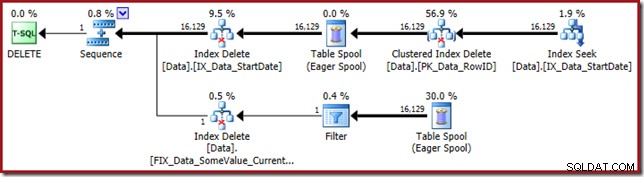
Wyszukiwanie indeksu zwraca tylko wartości RowID (bez CurrentFlag):
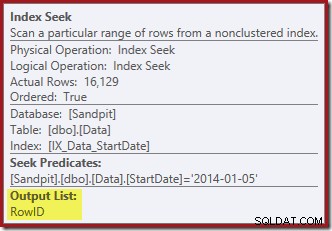
A Clustered Index Delete odczyty kolumny potrzebne do utrzymania indeksów nieklastrowanych, w tym CurrentFlag:
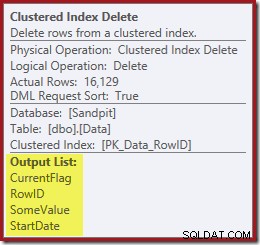
Te dane są chętnie zapisywane w szpuli tabeli, która jest odtwarzana dla każdego indeksu, który wymaga konserwacji. Zwróć także uwagę na wyraźny operator Filter przed operatorem Index Delete dla filtrowanego indeksu.
Kolejny wzór, na który trzeba uważać
Ten problem nie zawsze powoduje skanowanie tabeli zamiast wyszukiwania indeksu. Aby zobaczyć przykład, dodaj kolejny indeks do tabeli testowej:
CREATE NONCLUSTERED INDEX
IX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue, CurrentFlag); Pamiętaj, że ten indeks nie filtrowane i nie obejmuje kolumny Data rozpoczęcia. Teraz spróbuj ponownie wykonać zapytanie z usuwaniem dnia:
DELETE dbo.Data WHERE StartDate = '20140104';
Optymalizator wymyśla teraz tego potwora:
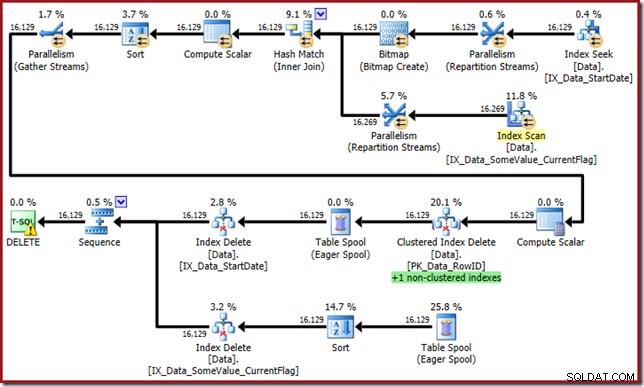
Ten plan zapytań ma wysoki czynnik zaskoczenia, ale główna przyczyna jest taka sama. Kolumna CurrentFlag jest nadal potrzebna, ale teraz optymalizator wybiera strategię przecięcia indeksu, aby uzyskać ją zamiast skanowania tabeli. Użycie flagi śledzenia wymusza plan konserwacji dla poszczególnych indeksów, a normalność zostaje przywrócona ponownie (jedyną różnicą jest dodatkowa powtórka buforowania w celu utrzymania nowego indeksu):
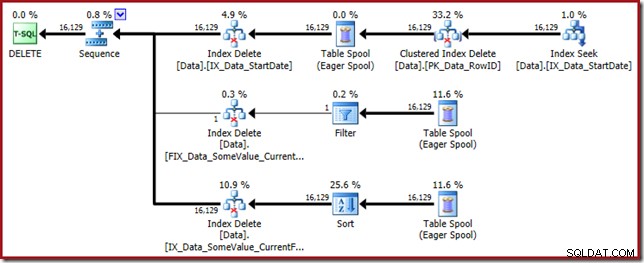
Tylko filtrowane indeksy powodują to
Ten problem występuje tylko wtedy, gdy optymalizator zdecyduje się zachować filtrowany indeks w operatorze Clustered Index Delete. Jak pokazano w poniższym przykładzie, nie ma to wpływu na indeksy niefiltrowane. Pierwszym krokiem jest upuszczenie przefiltrowanego indeksu:
DROP INDEX FIX_Data_SomeValue_CurrentFlag ON dbo.Data;
Teraz musimy napisać zapytanie w sposób, który przekona optymalizator do utrzymania wszystkich indeksów w Clustered Index Delete. Moim wyborem jest użycie zmiennej i podpowiedzi, aby obniżyć oczekiwania optymalizatora dotyczące liczby wierszy:
-- All qualifying rows will be deleted
DECLARE @Rows bigint = 9223372036854775807;
-- Optimize the plan for deleting 100 rows
DELETE TOP (@Rows)
FROM dbo.Data
OUTPUT
Deleted.RowID,
Deleted.SomeValue,
Deleted.StartDate,
Deleted.CurrentFlag
WHERE StartDate = '20140106'
OPTION (OPTIMIZE FOR (@Rows = 100)); Plan wykonania to:
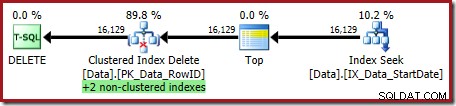
Oba indeksy nieklastrowane są obsługiwane przez funkcję Clustered Index Delete:
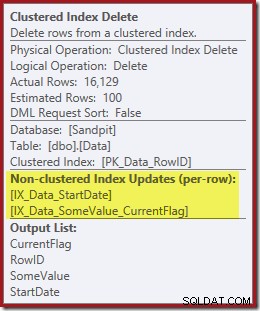
Wyszukiwanie indeksu zwraca tylko RowID:
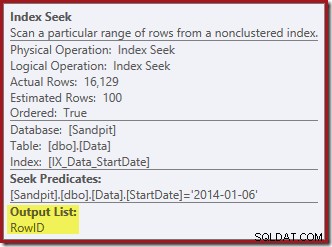
Kolumny potrzebne do utrzymania indeksu są pobierane wewnętrznie przez operatora usuwania; te szczegóły nie są widoczne w danych wyjściowych planu pokazu (więc lista wyników operatora usuwania byłaby pusta). Dodałem OUTPUT klauzula do zapytania, aby ponownie wyświetlić Clustered Index Delete zwracając dane, których nie otrzymał na wejściu:
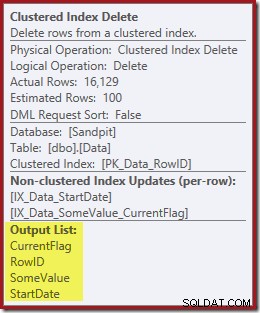
Ostateczne myśli
Jest to trudne ograniczenie do obejścia. Z jednej strony generalnie nie chcemy używać nieudokumentowanych flag śledzenia w systemach produkcyjnych.
Naturalną „poprawką” jest dodanie kolumn potrzebnych do utrzymania filtrowanego indeksu do wszystkich indeksy nieklastrowane, które mogą służyć do lokalizowania wierszy do usunięcia. Nie jest to zbyt atrakcyjna propozycja z wielu punktów widzenia. Inną alternatywą jest po prostu nieużywanie w ogóle filtrowanych indeksów, ale to też nie jest idealne.
Wydaje mi się, że optymalizator zapytań powinien automatycznie rozważyć alternatywę konserwacji według indeksu dla filtrowanych indeksów, ale jego rozumowanie wydaje się obecnie niekompletne w tym obszarze (i oparte na prostej heurystyce, a nie na odpowiednim wycenie według indeksu/wiersza alternatywy).
Aby umieścić kilka liczb wokół tego stwierdzenia, plan równoległego skanowania indeksów klastrowych wybrany przez optymalizator uzyskał wynik 5,5 jednostki w moich testach. To samo zapytanie z flagą śledzenia szacuje koszt 1,4 jednostki. Po wprowadzeniu trzeciego indeksu równoległy plan przecięcia indeksów wybrany przez optymalizatora miał szacunkowy koszt 4,9 , podczas gdy plan flagi śledzenia pojawił się w 2,7 jednostki (wszystkie testy na SQL Server 2014 RTM CU1 kompilacja 12.0.2342 w ramach modelu szacowania kardynalności 120 i z włączoną flagą śledzenia 4199).
Uważam to za zachowanie, które należy poprawić. Możesz głosować, czy zgadzam się ze mną lub nie zgadzam się ze mną na ten element Connect.