Partycjonowanie tabel w SQL Server to zasadniczo sposób na to, aby wiele tabel fizycznych (zestawów wierszy) wyglądało jak jedna tabela. Ta abstrakcja jest wykonywana w całości przez procesor zapytań, projekt, który ułatwia użytkownikom pracę, ale stawia złożone wymagania optymalizatorowi zapytań. W tym poście przyjrzymy się dwóm przykładom, które przekraczają możliwości optymalizatora od SQL Server 2008.
Dołączanie do kolumny ma znaczenie
Ten pierwszy przykład pokazuje, jak kolejność tekstowa ON Warunki klauzuli mogą mieć wpływ na plan zapytania generowany podczas dołączania do tabel partycjonowanych. Na początek potrzebujemy schematu partycjonowania, funkcji partycjonowania i dwóch tabel:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T1
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T1
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
);
CREATE TABLE dbo.T2
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T2
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
); Następnie ładujemy obie tabele 150 000 wierszy. Dane nie mają większego znaczenia; w tym przykładzie jako źródło danych użyto standardowej tabeli Numbers zawierającej wszystkie wartości całkowite od 1 do 150 000. Obie tabele są ładowane tymi samymi danymi.
INSERT dbo.T1 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
INSERT dbo.T2 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
Nasze zapytanie testowe wykonuje proste sprzężenie wewnętrzne tych dwóch tabel. Ponownie, zapytanie nie jest ważne ani nie ma być szczególnie realistyczne, służy do zademonstrowania dziwnego efektu podczas łączenia tabel partycjonowanych. Pierwsza forma zapytania używa ON klauzula napisana w c3, c2, c1 kolejność kolumn:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
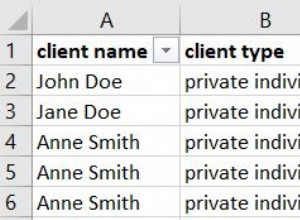
AND t1.c1 = t2.c1; Plan wykonania utworzony dla tego zapytania (w programie SQL Server 2008 i nowszych) obejmuje równoległe sprzężenie haszujące o szacowanym koszcie 2,6953 :
To trochę nieoczekiwane. Obie tabele mają indeks klastrowy w kolejności (c1, c2, c3), podzielony przez c1, więc oczekiwalibyśmy złączenia scalającego, wykorzystującego kolejność indeksów. Spróbujmy napisać ON klauzula w kolejności (c1, c2, c3):
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c1 = t2.c1
AND t1.c2 = t2.c2
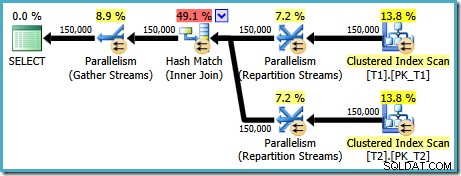
AND t1.c3 = t2.c3; Plan wykonania używa teraz oczekiwanego połączenia scalającego, którego szacowany koszt wynosi 1.64119 (spadek z 2.6953 ). Optymalizator decyduje również, że nie warto używać wykonywania równoległego:
Zauważając, że plan łączenia przez scalanie jest wyraźnie bardziej wydajny, możemy spróbować wymusić łączenie przez scalanie dla oryginalnego ON kolejność klauzul przy użyciu podpowiedzi do zapytania:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
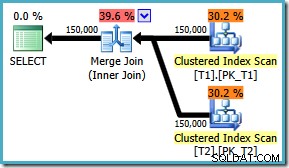
OPTION (MERGE JOIN); Wynikowy plan korzysta z połączenia scalającego zgodnie z żądaniem, ale zawiera również sortowanie na obu danych wejściowych i wraca do korzystania z równoległości. Szacowany koszt tego planu to ogromny 8.71063 :
Oba operatory sortowania mają te same właściwości:
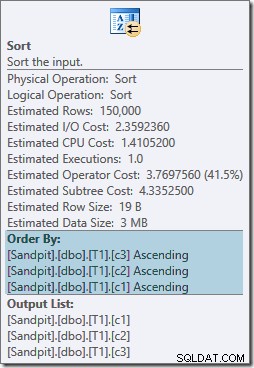
Optymalizator uważa, że łączenie scalające wymaga posortowania danych wejściowych w ścisłej kolejności zapisu ON klauzula, wprowadzając w rezultacie jawne sortowanie. Optymalizator zdaje sobie sprawę, że łączenie scalające wymaga posortowania danych wejściowych w ten sam sposób, ale wie również, że kolejność kolumn nie ma znaczenia. Merge join on (c1, c2, c3) jest równie zadowolony z danych wejściowych posortowanych według (c3, c2, c1), jak z wejściami posortowanymi według (c2, c1, c3) lub dowolnej innej kombinacji.
Niestety, to rozumowanie jest zepsute w optymalizatorze zapytań, gdy w grę wchodzi partycjonowanie. To jest błąd optymalizatora to zostało naprawione w SQL Server 2008 R2 i nowszych wersjach, chociaż flaga śledzenia 4199 jest wymagane do aktywacji poprawki:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (QUERYTRACEON 4199);
Normalnie można włączyć tę flagę śledzenia za pomocą DBCC TRACEON lub jako opcja startowa, ponieważ QUERYTRACEON wskazówka nie jest udokumentowana do użytku z 4199. Flaga śledzenia jest wymagana w SQL Server 2008 R2, SQL Server 2012 i SQL Server 2014 CTP1.
W każdym razie, jakkolwiek flaga jest włączona, zapytanie generuje teraz optymalne połączenie scalające niezależnie od ON porządkowanie klauzul:
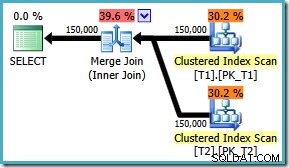
Nie ma braku poprawki dla SQL Server 2008 , obejściem jest napisanie ON klauzula w „właściwej” kolejności! Jeśli napotkasz takie zapytanie w SQL Server 2008, spróbuj wymusić sprzężenie scalające i spójrz na sortowanie, aby określić „poprawny” sposób zapisania ON zapytania klauzula.
Ten problem nie występuje w programie SQL Server 2005, ponieważ ta wersja zaimplementowała zapytania partycjonowane przy użyciu APPLY model:

Plan kwerend SQL Server 2005 łączy po jednej partycji z każdej tabeli na raz, używając tabeli w pamięci (Constant Scan) zawierającej numery partycji do przetworzenia. Każda partycja jest łączona przez scalenie osobno po wewnętrznej stronie łączenia, a optymalizator 2005 jest wystarczająco inteligentny, aby zobaczyć, że ON kolejność kolumn klauzuli nie ma znaczenia.
Ten najnowszy plan jest przykładem połączonego połączenia scalającego , funkcja, która została utracona po przejściu z SQL Server 2005 na nową implementację partycjonowania w SQL Server 2008. Sugestia dotycząca ponownego włączenia kolokowanych połączeń scalających została zamknięta, ponieważ nie da się naprawić.
Grupuj według zamówień
Druga osobliwość, na którą chcę się przyjrzeć, ma podobny motyw, ale dotyczy kolejności kolumn w GROUP BY klauzula zamiast ON klauzula sprzężenia wewnętrznego. Będziemy potrzebować nowej tabeli, aby zademonstrować:
CREATE TABLE dbo.T3
(
RowID integer IDENTITY NOT NULL,
UserID integer NOT NULL,
SessionID integer NOT NULL,
LocationID integer NOT NULL,
CONSTRAINT PK_T3
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T3 WITH (TABLOCKX)
(UserID, SessionID, LocationID)
SELECT
ABS(CHECKSUM(NEWID())) % 50,
ABS(CHECKSUM(NEWID())) % 30,
ABS(CHECKSUM(NEWID())) % 10
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000; Tabela ma wyrównany indeks nieklastrowy, gdzie „wyrównany” oznacza po prostu, że jest podzielony na partycje w taki sam sposób, jak indeks klastrowy (lub sterta):
CREATE NONCLUSTERED INDEX nc1 ON dbo.T3 (UserID, SessionID, LocationID) ON PS (RowID);
Nasze zapytanie testowe grupuje dane w trzech kolumnach indeksu nieklastrowanego i zwraca liczbę dla każdej grupy:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 GROUP BY LocationID, UserID, SessionID;
Plan zapytań skanuje indeks nieklastrowany i używa Hash Match Aggregate do zliczania wierszy w każdej grupie:
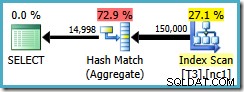
Z Hash Aggregate występują dwa problemy:
- Jest to operator blokujący. Żadne wiersze nie są zwracane do klienta, dopóki wszystkie wiersze nie zostaną zagregowane.
- Wymaga przyznania pamięci do przechowywania tablicy mieszającej.
W wielu rzeczywistych scenariuszach wolelibyśmy tutaj agregację strumienia, ponieważ ten operator blokuje tylko na grupę i nie wymaga przyznania pamięci. Korzystając z tej opcji, aplikacja kliencka zaczęłaby wcześniej otrzymywać dane, nie musiałaby czekać na przyznanie pamięci, a SQL Server może wykorzystać pamięć do innych celów.
Możemy wymagać, aby optymalizator zapytań używał Stream Aggregate dla tego zapytania, dodając OPTION (ORDER GROUP) wskazówka zapytania. Skutkuje to następującym planem wykonania:

Operator Sort jest w pełni blokujący, a także wymaga przyznania pamięci, więc ten plan wydaje się być gorszy niż zwykłe użycie agregacji skrótu. Ale dlaczego ten rodzaj jest potrzebny? Właściwości pokazują, że wiersze są sortowane w kolejności określonej przez naszą GROUP BY klauzula:
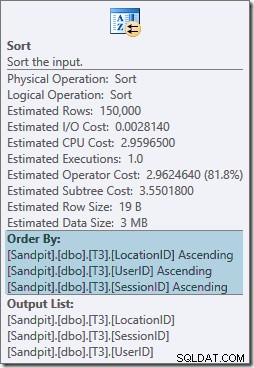
Ten rodzaj jest oczekiwany ponieważ wyrównywanie partycji indeksu (w SQL Server 2008 i nowsze) oznacza, że numer partycji jest dodawany jako wiodąca kolumna indeksu. W efekcie klucze indeksu nieklastrowego to (partycja, użytkownik, sesja, lokalizacja) ze względu na partycjonowanie. Wiersze w indeksie są nadal sortowane według użytkownika, sesji i lokalizacji, ale tylko w obrębie każdej partycji.
Jeśli ograniczymy zapytanie do pojedynczej partycji, optymalizator powinien mieć możliwość użycia indeksu do zasilania Stream Aggregate bez sortowania. W przypadku, gdy wymaga to wyjaśnienia, określenie pojedynczej partycji oznacza, że plan zapytania może wyeliminować wszystkie inne partycje ze skanowania indeksu nieklastrowanego, co skutkuje strumieniem wierszy uporządkowanym według (użytkownika, sesji, lokalizacji).
Możemy osiągnąć tę eliminację partycji jawnie za pomocą $PARTITION funkcja:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID;
Niestety, to zapytanie nadal używa agregatu haszującego, którego szacowany koszt planu wynosi 0,287878 :
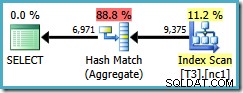
Skanowanie obejmuje teraz tylko jedną partycję, ale kolejność (użytkownik, sesja, lokalizacja) nie pomogła optymalizatorowi w użyciu Stream Aggregate. Możesz sprzeciwić się, że zamawianie (użytkownik, sesja, lokalizacja) nie jest pomocne, ponieważ GROUP BY klauzula to (lokalizacja, użytkownik, sesja), ale kolejność kluczy nie ma znaczenia dla operacji grupowania.
Dodajmy ORDER BY klauzula w kolejności kluczy indeksu, aby udowodnić ten punkt:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID ORDER BY UserID, SessionID, LocationID;
Zauważ, że ORDER BY klauzula pasuje do kolejności kluczy indeksu nieklastrowanego, chociaż GROUP BY klauzula nie. Plan wykonania dla tego zapytania to:
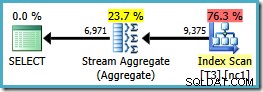
Teraz mamy agregat Stream, którego szukaliśmy, z szacowanym kosztem planu wynoszącym 0,0423925 (w porównaniu z 0,287878 dla planu Hash Aggregate – prawie 7 razy więcej).
Innym sposobem uzyskania Stream Aggregate tutaj jest zmiana kolejności GROUP BY kolumny pasujące do nieklastrowych kluczy indeksu:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1 GROUP BY UserID, SessionID, LocationID;
To zapytanie generuje ten sam plan Stream Aggregate pokazany bezpośrednio powyżej, z dokładnie tym samym kosztem. Ta wrażliwość na GROUP BY kolejność kolumn jest specyficzna dla zapytań dotyczących tabel partycjonowanych w SQL Server 2008 i nowszych.
Możesz rozpoznać, że główna przyczyna problemu jest podobna do poprzedniego przypadku dotyczącego łączenia scalającego. Zarówno Merge Join, jak i Stream Aggregate wymagają danych wejściowych posortowanych według kluczy sprzężenia lub agregacji, ale żaden z nich nie dba o kolejność tych kluczy. Połączenie scalające na (x, y, z) jest tak samo szczęśliwym odbieraniem wierszy uporządkowanych według (y, z, x) lub (z, y, x) i to samo dotyczy Stream Aggregate.
To ograniczenie optymalizatora dotyczy również DISTINCT w tych samych okolicznościach. Następujące zapytanie daje w wyniku plan Hash Aggregate z szacowanym kosztem 0,286539 :
SELECT DISTINCT LocationID, UserID, SessionID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
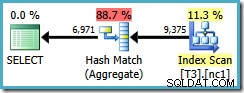
Jeśli napiszemy DISTINCT kolumny w kolejności nieklastrowanych kluczy indeksowych…
SELECT DISTINCT UserID, SessionID, LocationID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
…jesteśmy nagradzani planem Stream Aggregate o koszcie 0,041455 :

Podsumowując, jest to ograniczenie optymalizatora zapytań w SQL Server 2008 i nowszych (w tym SQL Server 2014 CTP 1), które nie jest rozwiązane przy użyciu flagi śledzenia 4199 tak jak w przypadku przykładu Merge Join. Problem występuje tylko w przypadku tabel partycjonowanych z GROUP BY lub DISTINCT ponad trzy lub więcej kolumn przy użyciu wyrównanego indeksu partycjonowanego, w którym przetwarzana jest pojedyncza partycja.
Podobnie jak w przykładzie Merge Join, reprezentuje to krok wstecz w stosunku do zachowania SQL Server 2005. SQL Server 2005 nie dodał domyślnego klucza wiodącego do indeksów partycjonowanych za pomocą APPLY technika zamiast. W SQL Server 2005 wszystkie zapytania przedstawione tutaj przy użyciu $PARTITION aby określić pojedynczy wynik partycji w planach zapytań, które przeprowadzają eliminację partycji i używają Stream Aggregates bez zmiany kolejności tekstu zapytania.
Zmiany w przetwarzaniu tabel partycjonowanych w SQL Server 2008 poprawiły wydajność w kilku ważnych obszarach, głównie związanych z wydajnym przetwarzaniem równoległym partycji. Niestety te zmiany miały skutki uboczne, które nie zostały rozwiązane w późniejszych wersjach.