Zmiany w wewnętrznej reprezentacji tabel partycjonowanych między SQL Server 2005 i SQL Server 2008 spowodowały w większości przypadków poprawę planów zapytań i wydajności (zwłaszcza w przypadku wykonywania równoległego). Niestety te same zmiany spowodowały, że niektóre rzeczy, które działały dobrze w SQL Server 2005, nagle przestały działać tak dobrze w SQL Server 2008 i późniejszych. Ten post dotyczy jednego przykładu, w którym optymalizator zapytań SQL Server 2005 stworzył lepszy plan wykonania w porównaniu z późniejszymi wersjami.
Przykładowa tabela i dane
Przykłady w tym poście wykorzystują następującą podzieloną na partycje tabelę i dane:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T4
(
RowID integer IDENTITY NOT NULL,
SomeData integer NOT NULL,
CONSTRAINT PK_T4
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T4 WITH (TABLOCKX)
(SomeData)
SELECT
ABS(CHECKSUM(NEWID()))
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
CREATE NONCLUSTERED INDEX nc1
ON dbo.T4 (SomeData)
ON PS (RowID); Układ danych partycjonowanych
Nasza tabela ma podzielony na partycje indeks klastrowy. W takim przypadku klucz klastrowania służy również jako klucz partycjonowania (choć generalnie nie jest to wymagane). Partycjonowanie skutkuje osobnymi fizycznymi jednostkami pamięci (zestawami wierszy), które procesor zapytań przedstawia użytkownikom jako pojedynczą jednostkę.
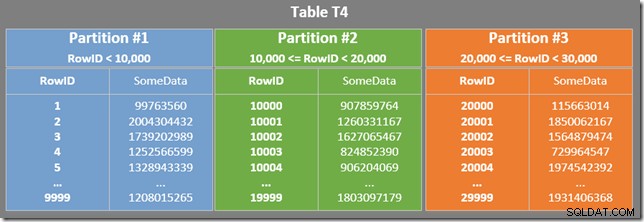
Poniższy diagram pokazuje pierwsze trzy partycje naszej tabeli (kliknij, aby powiększyć):
Indeks nieklastrowy jest podzielony na partycje w ten sam sposób (jest „wyrównany”):

Każda partycja indeksu nieklastrowanego obejmuje zakres wartości RowID. W każdej partycji dane są uporządkowane według SomeData (ale wartości RowID nie będą ogólnie uporządkowane).
Problem MIN/MAX
Dość dobrze wiadomo, że MIN i MAX agregacje nie optymalizują się dobrze w tabelach partycjonowanych (chyba że agregowana kolumna jest również kolumną partycjonującą). O tym ograniczeniu (które nadal występuje w SQL Server 2014 CTP 1) pisano wiele razy na przestrzeni lat; mój ulubiony reportaż znajduje się w tym artykule autorstwa Itzika Ben-Gana. Aby krótko zilustrować problem, rozważ następujące zapytanie:
SELECT MIN(SomeData) FROM dbo.T4;
Plan wykonania na SQL Server 2008 lub nowszym jest następujący:

Ten plan odczytuje wszystkie 150 000 wierszy z indeksu, a Stream Aggregate oblicza wartość minimalną (plan wykonania jest zasadniczo taki sam, jeśli zamiast tego zażądamy wartości maksymalnej). Plan wykonania SQL Server 2005 jest nieco inny (choć nie lepszy):
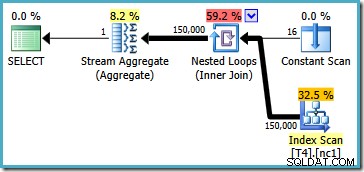
Ten plan iteruje po numerach partycji (wymienionych w Constant Scan) w pełni skanując partycję na raz. Wszystkie 150 000 wierszy jest ostatecznie odczytywanych i przetwarzanych przez Stream Aggregate.
Spójrz wstecz na partycjonowane tabele i diagramy indeksów i zastanów się, jak zapytanie może być bardziej efektywnie przetwarzane w naszym zestawie danych. Indeks nieklastrowy wydaje się dobrym wyborem do rozwiązania zapytania, ponieważ zawiera wartości SomeData w kolejności, która może zostać wykorzystana podczas obliczania agregacji.
Teraz fakt, że indeks jest podzielony na partycje, nieco komplikuje sprawę:każda partycja indeksu jest uporządkowana według kolumny SomeData, ale nie możemy po prostu odczytać najniższej wartości z żadnego konkretnego partycji, aby uzyskać właściwą odpowiedź na całe zapytanie.
Po zrozumieniu istoty problemu człowiek może zauważyć, że skuteczną strategią byłoby znalezienie pojedynczej najniższej wartości SomeData w każdej partycji indeksu, a następnie pobierz najniższą wartość z wyników na partycję.
Jest to zasadniczo obejście, które Itzik przedstawia w swoim artykule; przepisz zapytanie, aby obliczyć agregację na partycję (za pomocą APPLY składni), a następnie ponownie zagregować te wyniki dla partycji. Stosując to podejście, przepisany MIN zapytanie generuje ten plan wykonania (dokładną składnię można znaleźć w artykule Itzika):
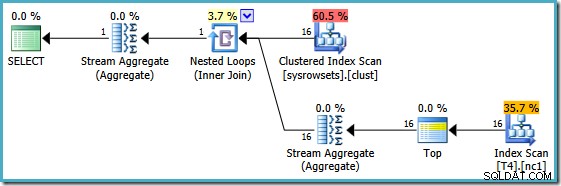
Ten plan odczytuje numery partycji z tabeli systemowej i pobiera najniższą wartość SomeData w każdej partycji. Ostateczna agregacja strumienia po prostu oblicza minimum na podstawie wyników na partycję.
Ważną cechą tego planu jest to, że odczytuje pojedynczy wiersz z każdej partycji (wykorzystując porządek sortowania indeksu w każdej partycji). Jest znacznie bardziej wydajny niż plan optymalizatora, który przetworzył wszystkie 150 000 wierszy w tabeli.
MIN i MAX w jednej partycji
Rozważmy teraz następujące zapytanie, aby znaleźć minimalną wartość w kolumnie SomeData dla zakresu wartości RowID, które są zawarte w pojedynczej partycji :
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 18000;
Widzieliśmy, że optymalizator ma problem z MIN i MAX na wielu partycjach, ale spodziewalibyśmy się, że te ograniczenia nie będą miały zastosowania do pojedynczego zapytania o partycję.
Pojedyncza partycja to partycja ograniczona wartościami RowID 10 000 i 20 000 (odwołaj się do definicji funkcji partycjonowania). Funkcja partycjonowania została zdefiniowana jako RANGE RIGHT , więc wartość graniczna 10 000 należy do partycji 2, a granica 20 000 należy do partycji nr 3. Zakres wartości RowID określony przez nasze nowe zapytanie jest zatem zawarty w samej partycji 2.
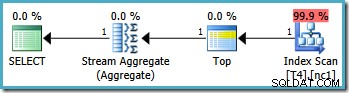
Graficzne plany wykonania tego zapytania wyglądają tak samo we wszystkich wersjach SQL Server od 2005 roku:
Analiza planu
Optymalizator przyjął zakres RowID określony w WHERE klauzuli i porównał ją z definicją funkcji partycji, aby określić, że potrzebny jest dostęp tylko do partycji 2 indeksu nieklastrowanego. Właściwości planu SQL Server 2005 dla skanowania indeksu wyraźnie pokazują dostęp do pojedynczej partycji:
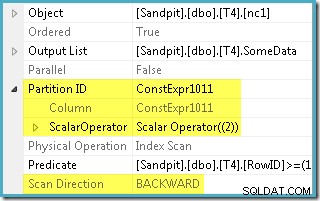
Drugą podświetloną właściwością jest Kierunek skanowania. Kolejność skanowania różni się w zależności od tego, czy zapytanie szuka minimalnej czy maksymalnej wartości SomeData. Indeks nieklastrowany jest uporządkowany (na partycję, pamiętaj) według rosnących wartości SomeData, więc kierunek skanowania indeksu to FORWARD jeśli zapytanie prosi o minimalną wartość, a BACKWARD jeśli wymagana jest maksymalna wartość (powyższy zrzut ekranu pochodzi z MAX plan zapytań).
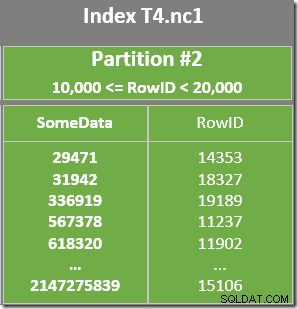
Istnieje również predykat rezydualny na skanowaniu indeksu, aby sprawdzić, czy wartości RowID zeskanowane z partycji 2 pasują do WHERE predykat klauzuli. Optymalizator zakłada, że wartości RowID są rozmieszczone dość losowo w indeksie nieklastrowym, więc oczekuje, że znajdzie pierwszy wiersz, który pasuje do WHERE orzeczenie klauzuli dość szybko. Diagram układu danych partycjonowanych pokazuje, że wartości RowID są rzeczywiście dość losowo rozmieszczone w indeksie (co jest uporządkowane według kolumny SomeData, pamiętaj):
Operator Top w planie zapytania ogranicza skanowanie indeksu do jednego wiersza (od najniższego lub wyższego końca indeksu, w zależności od kierunku skanowania). Skanowanie indeksu może być problematyczne w planach zapytań, ale operator Top sprawia, że jest to wydajna opcja:skanowanie może wygenerować tylko jeden wiersz, a następnie zatrzymuje się. Kombinacja Top i uporządkowanego skanowania indeksu skutecznie wykonuje wyszukiwanie do najwyższej lub najniższej wartości w indeksie, która również pasuje do WHERE predykaty klauzul. W planie pojawia się również Stream Aggregate, aby zapewnić, że NULL jest generowany w przypadku, gdy skanowanie indeksu nie zwraca żadnych wierszy. Skalarny MIN i MAX agregaty są zdefiniowane tak, aby zwracały NULL gdy wejście jest pustym zestawem.
Ogólnie rzecz biorąc, jest to bardzo skuteczna strategia, a szacunkowy koszt planów wynosi zaledwie 0,0032921 w rezultacie jednostki. Jak dotąd tak dobrze.
Problem z wartością graniczną
Następny przykład modyfikuje górny koniec zakresu RowID:
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000;
Zauważ, że zapytanie wyklucza wartość 20 000 za pomocą operatora „mniej niż”. Przypomnij sobie, że wartość 20 000 należy do partycji 3 (nie do partycji 2), ponieważ funkcja partycji jest zdefiniowana jako RANGE RIGHT . Serwer SQL2005 optymalizator poprawnie radzi sobie z tą sytuacją, tworząc optymalny plan zapytań z pojedynczą partycją o szacowanym koszcie 0,0032878 :
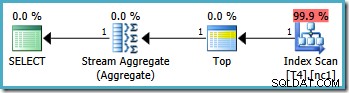
Jednak to samo zapytanie generuje inny plan w programie SQL Server 2008 i nowsze (w tym SQL Server 2014 CTP 1):
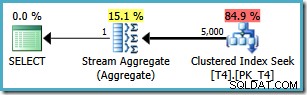
Teraz mamy Clustered Index Seek (zamiast żądanej kombinacji Index Scan i Top operator). Wszystkie 5000 wierszy pasujących do WHERE klauzula są przetwarzane za pośrednictwem Stream Aggregate w tym nowym planie wykonania. Szacowany koszt tego planu to 0,0199319 jednostki – ponad sześć razy koszt planu SQL Server 2005.
Przyczyna
Optymalizatory SQL Server 2008 (i nowsze) nie do końca rozumieją wewnętrzną logikę, gdy interwał odwołuje się, ale wyklucza , wartość graniczna należąca do innej partycji. Optymalizator błędnie uważa, że będzie można uzyskać dostęp do wielu partycji i stwierdza, że nie może użyć optymalizacji pojedynczej partycji dla MIN i MAX agregaty.
Obejścia
Jedną z opcji jest przepisanie zapytania przy użyciu operatorów>=i <=, dzięki czemu nie odwołujemy się do wartości granicznej z innej partycji (nawet w celu jej wykluczenia!):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID <= 19999;
Daje to optymalny plan, dotykając pojedynczej partycji:
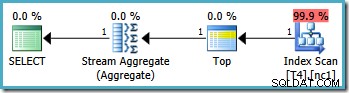
Niestety nie zawsze jest możliwe określenie w ten sposób poprawnych wartości granicznych (w zależności od typu kolumny partycjonującej). Przykładem tego są typy daty i godziny, w których najlepiej jest używać półotwartych interwałów. Kolejny zarzut dotyczący tego obejścia jest bardziej subiektywny:funkcja partycjonowania wyklucza jedną granicę z zakresu, więc najbardziej naturalne wydaje się napisanie zapytania również przy użyciu składni półotwartego przedziału.
Drugim obejściem jest jawne określenie numeru partycji (i zachowanie interwału półotwartego):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000 AND $PARTITION.PF(RowID) = 2;
Daje to optymalny plan, kosztowny wymagający dodatkowego predykatu i polegający na tym, że użytkownik ustali, jaki powinien być numer partycji.
Oczywiście byłoby lepiej, gdyby optymalizatory z lat 2008 i później stworzyły ten sam optymalny plan, co SQL Server 2005. W idealnym świecie bardziej kompleksowe rozwiązanie również rozwiąże przypadek wielu partycji, dzięki czemu obejście, które opisuje Itzik, jest również niepotrzebne.