Pojedyncze predykaty
Oszacowanie liczby wierszy kwalifikowanych przez pojedynczy predykat zapytania jest często proste. Kiedy predykat dokonuje prostego porównania między kolumną a wartością skalarną, istnieje duże prawdopodobieństwo, że estymator liczności będzie w stanie uzyskać dobre oszacowanie jakości z histogramu statystycznego. Na przykład następujące zapytanie AdventureWorks daje dokładnie poprawne oszacowanie 203 wierszy (przy założeniu, że nie wprowadzono żadnych zmian w danych od czasu utworzenia statystyk):
SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.TransactionDate = '20070903';
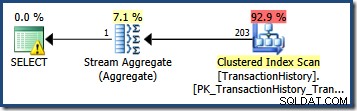
Patrząc na histogram statystyk dla TransactionDate wyraźnie widać, skąd wzięły się te szacunki:
DBCC SHOW_STATISTICS (
'Production.TransactionHistory',
'TransactionDate')
WITH HISTOGRAM;
Jeśli zmienimy zapytanie, aby określić datę, która mieści się w przedziale histogramu, estymator kardynalności zakłada, że wartości są równomiernie rozłożone. Używając daty 2007-09-02 generuje oszacowanie 227 wierszy (z RANGE_ROWS wejście). Jako ciekawą uwagę poboczną, oszacowanie pozostaje w 227 wierszach niezależnie od części czasu, którą możemy dodać do wartości daty (TransactionDate kolumna to datetime typ danych).
Jeśli spróbujemy ponownie wykonać zapytanie z datą 2007-09-05 lub 2007-09-06 (oba mieszczą się w przedziale 2007-09-04 i 2007-09-07 histogramu), estymator kardynalności przyjmuje 466 RANGE_ROWS są równo podzielone między te dwie wartości, co w obu przypadkach szacuje 233 wiersze.
Istnieje wiele innych szczegółów dotyczących szacowania kardynalności dla prostych predykatów, ale powyższe przyda się jako przypomnienie dla naszych obecnych celów.
Problemy wielu predykatów
Gdy zapytanie zawiera więcej niż jeden predykat kolumny, oszacowanie liczności staje się trudniejsze. Rozważ następujące zapytanie z dwoma prostymi predykatami (z których każdy jest łatwy do samodzielnego oszacowania):
SELECT
COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'; Konkretne zakresy wartości w zapytaniu są celowo dobierane tak, aby oba predykaty identyfikowały dokładnie te same wiersze. Możemy łatwo zmodyfikować wartości zapytania, aby uzyskać dowolne nakładanie się, w tym w ogóle nie nakładać się. Wyobraź sobie teraz, że jesteś estymatorem liczności:w jaki sposób możesz uzyskać oszacowanie liczności dla tego zapytania?
Problem jest trudniejszy, niż mogłoby się wydawać na pierwszy rzut oka. Domyślnie SQL Server automatycznie tworzy statystyki jednokolumnowe dla obu kolumn predykatu. Możemy również ręcznie tworzyć statystyki wielokolumnowe. Czy to daje nam wystarczającą ilość informacji, aby uzyskać dobre oszacowanie dla tych konkretnych wartości? A co z bardziej ogólnym przypadkiem, w którym mogą występować dowolne? stopień nakładania się?
Korzystając z dwóch jednokolumnowych obiektów statystycznych, możemy łatwo uzyskać oszacowanie dla każdego predykatu, korzystając z metody histogramu opisanej w poprzedniej sekcji. W przypadku określonych wartości w powyższym zapytaniu histogramy pokazują, że TransactionID oczekuje się, że zakres będzie pasował do 68412.4 wierszy i TransactionDate oczekuje się, że zasięg będzie pasował do 68 413 wydziwianie. (Gdyby histogramy były idealne, te dwie liczby byłyby dokładnie takie same).
Czego histogramy nie mogą powiedz nam, ile z tych dwóch zestawów wierszy będzie tymi samymi wierszami . Wszystko, co możemy powiedzieć na podstawie informacji z histogramu, to to, że nasze oszacowanie powinno mieścić się gdzieś od zera (bez nakładania się) do 68412.4 wierszy (całkowite nakładanie się).
Tworzenie statystyk wielokolumnowych nie zapewnia żadnej pomocy dla tego zapytania (ani ogólnie dla zapytań zakresowych). Statystyki wielokolumnowe nadal tworzą histogram tylko nad pierwszą nazwaną kolumną, zasadniczo powielając histogram powiązany z jedną z automatycznie tworzonych statystyk. Dodatkowa gęstość informacje dostarczane przez statystykę wielokolumnową mogą być przydatne do dostarczania informacji o średniej wielkości dla zapytań, które zawierają wiele predykatów równości, ale tutaj nie są one dla nas pomocne.
Aby uzyskać oszacowanie z wysokim stopniem pewności, potrzebowalibyśmy SQL Server, aby zapewnić lepsze informacje o dystrybucji danych — coś w rodzaju wielowymiarowego histogram statystyki. O ile mi wiadomo, żaden komercyjny silnik bazy danych nie oferuje obecnie takiej możliwości, chociaż na ten temat opublikowano kilka artykułów technicznych (w tym Microsoft Research, który wykorzystał wewnętrzny rozwój SQL Server 2000).
Nie wiedząc nic o korelacjach danych i nakładaniu się danych dla poszczególnych zakresów wartości, nie jest jasne, jak powinniśmy postępować, aby uzyskać dobre oszacowanie dla naszego zapytania. Co więc robi tutaj SQL Server?
Serwer SQL 7 – 2012
Estymator liczności w tych wersjach SQL Server zazwyczaj zakłada, że wartości różnych atrybutów w tabeli są dystrybuowane całkowicie niezależnie od siebie. To założenie o niezależności rzadko jest dokładnym odzwierciedleniem rzeczywistych danych, ale ma tę zaletę, że ułatwia obliczenia.
ORAZ Selektywność
Stosując założenie niezależności, dwa predykaty połączone przez AND (znany jako spójnik ) z selektywnościami S1 i S2 , w wyniku połączonej selektywności:
(S1 * S2)
Jeśli termin jest Ci nieznany, selektywność to liczba z zakresu od 0 do 1, reprezentująca ułamek wierszy w tabeli, które przekazują predykat. Na przykład, jeśli predykat wybiera 12 wierszy z tabeli zawierającej 100 wierszy, selektywność wynosi (12/100) =0,12.
W naszym przykładzie TransactionHistory tabela zawiera łącznie 113 443 wierszy. Predykat TransactionID jest szacowany (z histogramu), aby zakwalifikować 68 412,4 wierszy, więc selektywność wynosi (68 412,4 / 113 443) lub z grubsza 0,603055 . Predykat TransactionDate podobnie szacuje się, że ma selektywność (68 413 / 113 443) =w przybliżeniu 0,603061 .
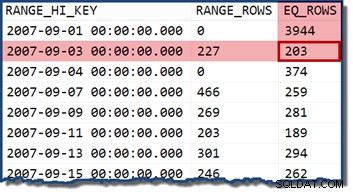
Pomnożenie dwóch selektywności (przy użyciu powyższego wzoru) daje łączne oszacowanie selektywności 0,363679 . Pomnożenie tej selektywności przez liczność tabeli (113,443) daje ostateczne oszacowanie 41 256,8 wiersze:
LUB Selektywność
Dwa predykaty połączone przez OR (rozłączenie ) z selektywnościami S1 i S2 , daje łączną selektywność:
(S1 + S2) – (S1 * S2)
Intuicja kryjąca się za formułą polega na dodaniu dwóch selektywności, a następnie odjęciu oszacowania ich koniunkcji (przy użyciu poprzedniego wzoru). Oczywiście moglibyśmy mieć dwa predykaty, każdy o selektywności 0,8, ale proste dodanie ich razem dałoby niemożliwą połączoną selektywność 1,6. Pomimo założenia o niezależności musimy uznać, że te dwa predykaty mogą się nakładać, więc aby uniknąć podwójnego liczenia, odejmuje się szacowaną selektywność koniunkcji.
Możemy łatwo zmodyfikować nasz działający przykład, aby używał OR :
SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
OR TH.TransactionDate BETWEEN '20070901' AND '20080313';
Podstawianie selektywności predykatów do OR formuła daje łączną selektywność:
(0.603055 + 0.603061) - (0.603055 * 0.603061) = 0.842437
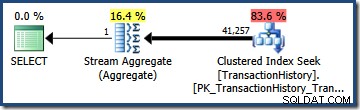
Pomnożona przez liczbę wierszy w tabeli, ta selektywność daje nam ostateczną wartość szacunkową kardynalności wynoszącą 95 568,6 :
Żadne szacunki (41 257 dla AND zapytanie; 95 569 dla OR zapytanie) jest szczególnie dobre, ponieważ oba są oparte na założeniu modelowania, które nie pasuje zbyt dobrze do rozkładu danych. Oba zapytania faktycznie zwracają 68 413 wiersze (ponieważ predykaty identyfikują dokładnie te same wiersze).
Flaga śledzenia 4137 — Minimalna selektywność
W przypadku SQL Server 2008 (R1) do 2012 włącznie firma Microsoft wydała poprawkę, która zmienia sposób obliczania selektywności dla AND tylko przypadek (predykaty spójnik). Artykuł z bazy wiedzy w tym łączu nie zawiera wielu szczegółów, ale okazuje się, że poprawka zmienia zastosowaną formułę selektywności. Zamiast mnożyć indywidualne selektywności, szacowanie kardynalności dla predykatów spójnych wykorzystuje teraz samą najniższą selektywność.
Aby aktywować zmienione zachowanie, wymagana jest obsługiwana flaga śledzenia 4137. Oddzielny artykuł z bazy wiedzy dokumentuje, że ta flaga śledzenia jest również obsługiwana do użycia na zapytanie za pośrednictwem QUERYTRACEON wskazówka:
SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'
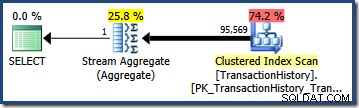
OPTION (QUERYTRACEON 4137); Gdy ta flaga jest aktywna, oszacowanie kardynalności wykorzystuje minimalną selektywność dwóch predykatów, co daje oszacowanie 68 412,4 wiersze:
Tak się składa, że jest to prawie idealne dla naszego zapytania, ponieważ nasze predykaty testowe są dokładnie skorelowane (a szacunki pochodzące z histogramów bazowych są również bardzo dobre).
Rzadko zdarza się, aby predykaty były tak doskonale skorelowane z rzeczywistymi danymi, ale flaga śledzenia może mimo wszystko pomóc w niektórych przypadkach. Zwróć uwagę, że zachowanie minimalnej selektywności będzie miało zastosowanie do wszystkich koniunkcji (AND ) predykaty w zapytaniu; nie ma możliwości określenia zachowania na bardziej szczegółowym poziomie.
Nie ma odpowiedniej flagi śledzenia do oszacowania rozłączności (OR ) predykaty przy użyciu minimalnej selektywności.
Serwer SQL 2014
Obliczenia selektywności w programie SQL Server 2014 zachowują się tak samo jak w poprzednich wersjach (a flaga śledzenia 4137 działa jak poprzednio), jeśli poziom zgodności bazy danych jest ustawiony na niższy niż 120 lub jeśli flaga śledzenia 9481 jest aktywny. Ustawienie poziomu zgodności bazy danych jest oficjalne sposób użycia estymatora kardynalności sprzed 2014 r. w SQL Server 2014. Flaga śledzenia 9481 skutecznie robi to samo, co w momencie pisania, a także działa z QUERYTRACEON , chociaż nie jest to udokumentowane. Nie ma sposobu, aby dowiedzieć się, jakie będzie zachowanie RTM tej flagi.
Jeśli nowy estymator kardynalności jest aktywny, SQL Server 2014 używa innej domyślnej formuły do łączenia predykatów łączących i rozłącznych. Chociaż nieudokumentowana, formuła selektywności dla spójników została już kilkakrotnie odkryta i udokumentowana. Pierwszy, który pamiętam, znajduje się w tym portugalskim poście na blogu, a część druga ukazała się kilka tygodni później. Podsumowując, podejście 2014 do predykatów spójnych polega na użyciu wykładniczego odczekiwania: podano tabelę z licznością C i selektywnościami predykatów S1 , S2 , S3 … Sn , gdzie S1 jest najbardziej selektywny i Sn najmniej:
Estimate = C * S1 * SQRT(S2) * SQRT(SQRT(S3)) * SQRT(SQRT(SQRT(S4))) …
Oszacowanie jest obliczane przez najbardziej selektywny predykat pomnożony przez liczność tabeli, pomnożony przez pierwiastek kwadratowy następnego najbardziej selektywnego predykatu i tak dalej, z każdą nową selektywnością zyskuje dodatkowy pierwiastek kwadratowy.
Przypominając, że selektywność jest liczbą z zakresu od 0 do 1, jasne jest, że zastosowanie pierwiastka kwadratowego przesuwa tę liczbę bliżej do 1. Efektem jest uwzględnienie wszystkich predykatów w ostatecznym oszacowaniu, ale zmniejszenie wpływu mniej selektywnych predykatów wykładniczo. Ten pomysł jest prawdopodobnie bardziej logiczny niż w przypadku założenia o niezależności , ale nadal jest to ustalony wzór – nie zmienia się w zależności od rzeczywistego stopnia korelacji danych.
Estymator kardynalności z 2014 r. wykorzystuje wykładniczą formułę wycofywania dla obu predykaty conjunctive i disjunctive, chociaż formuła użyta w dysjunctive (OR ) sprawa nie została jeszcze udokumentowana (oficjalnie lub w inny sposób).
Flagi śledzenia selektywności SQL Server 2014
Flaga śledzenia 4137 (aby użyć minimalnej selektywności) nie działają w SQL Server 2014, jeśli nowy estymator liczności jest używany podczas kompilowania zapytania. Zamiast tego pojawiła się nowa flaga śledzenia 9471 . Gdy ta flaga jest aktywna, minimalna selektywność jest używana do oszacowania wielu spójnych i rozłącznych predykaty. Jest to zmiana w stosunku do zachowania 4137, które dotyczyło tylko predykatów spójnych.
Podobnie flaga śledzenia 9472 można określić, aby zakładać niezależność dla wielu predykatów, tak jak w poprzednich wersjach. Ta flaga różni się od 9481 (aby użyć estymatora kardynalności sprzed 2014 r.), ponieważ pod 9472 nadal będzie używany nowy estymator kardynalności, ma to wpływ tylko na wzór selektywności dla wielu predykatów.
Ani 9471, ani 9472 nie są udokumentowane w momencie pisania (chociaż mogą znajdować się w RTM).
Wygodnym sposobem sprawdzenia, które założenie selektywności jest używane w SQL Server 2014 (z aktywnym nowym estymatorem liczności) jest zbadanie danych wyjściowych debugowania obliczeń selektywności generowanych, gdy flagi śledzenia 2363 i 3604 są aktywne. Sekcja, której należy szukać, dotyczy kalkulatora selektywności, który łączy filtry, w którym zobaczysz jedno z poniższych, w zależności od przyjętego założenia:
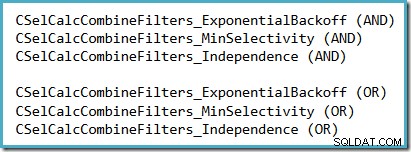
Nie ma realistycznych perspektyw, że 2363 będzie udokumentowane lub obsługiwane.
Ostateczne myśli
Nie ma nic magicznego w wykładniczym wycofywaniu się, minimalnej selektywności czy niezależności. Każde podejście reprezentuje (ogromnie) uproszczone założenie, które może, ale nie musi dawać akceptowalnych szacunków dla dowolnego konkretnego zapytania lub dystrybucji danych.
Pod pewnymi względami wykładniczy wycofywanie reprezentuje kompromis między dwoma skrajnościami niepodległości i minimalną selektywność . Mimo to ważne jest, aby nie mieć wobec tego nierozsądnych oczekiwań. Dopóki nie zostanie znaleziony dokładniejszy sposób oszacowania selektywności dla wielu predykatów (o rozsądnej charakterystyce wydajności), ważne jest, aby zdawać sobie sprawę z ograniczeń modelu i odpowiednio uważać na (potencjalne) błędy oszacowania.
Różne flagi śledzenia zapewniają pewną kontrolę nad tym, które założenie jest używane, ale sytuacja jest daleka od ideału. Po pierwsze, największą szczegółowością, z jaką można zastosować flagę, jest pojedyncze zapytanie — nie można określić zachowania szacowania na poziomie predykatu. Jeśli masz zapytanie, w którym niektóre predykaty są skorelowane, a inne niezależne, flagi śledzenia mogą nie pomóc bez refaktoryzacji zapytania w taki czy inny sposób. Podobnie problematyczne zapytanie może mieć korelacje predykatów, które nie są dobrze modelowane przez żadną z dostępnych opcji.
Użycie ad hoc flag śledzenia wymaga tych samych uprawnień co DBCC TRACEON – czyli sysadmin . To prawdopodobnie jest w porządku w przypadku osobistych testów, ale w przypadku produkcji użyj przewodnika po planie za pomocą QUERYTRACEON wskazówka jest lepszą opcją. W przypadku przewodnika po planie nie są wymagane żadne dodatkowe uprawnienia do wykonania zapytania (chociaż do utworzenia przewodnika po planie wymagane są oczywiście podwyższone uprawnienia).