W moich postach w tym roku omawiałem odruchowe reakcje na różne typy oczekiwania, a w tym poście zamierzam kontynuować temat statystyk oczekiwania i omówić PAGEIOLATCH_XX czekać. Mówię „czekaj”, ale jest naprawdę wiele rodzajów PAGEIOLATCH czeka, co oznaczyłem na końcu XX. Najczęstsze przykłady to:
PAGEIOLATCH_SH– (SH są) czekają na przeniesienie strony pliku danych z dysku do puli buforów, aby można było odczytać jej zawartośćPAGEIOLATCH_EXlubPAGEIOLATCH_UP– (EX łączny lub W GÓRĘ data) oczekiwanie na przeniesienie strony pliku danych z dysku do puli buforów, aby można było zmodyfikować jej zawartość
Spośród nich zdecydowanie najpopularniejszym typem jest PAGEIOLATCH_SH .
Kiedy ten typ oczekiwania jest najbardziej rozpowszechniony na serwerze, odruchową reakcją jest to, że podsystem I/O musi mieć problem i na tym należy skoncentrować się dochodzenia.
Pierwszą rzeczą do zrobienia jest porównanie PAGEIOLATCH_SH liczba oczekiwania i czas trwania w stosunku do linii bazowej. Jeśli liczba oczekiwania jest mniej więcej taka sama, ale czas trwania każdego oczekiwania na odczyt stał się znacznie dłuższy, byłbym zaniepokojony problemem z podsystemem we/wy, takim jak:
- Błędna konfiguracja/wadliwe działanie na poziomie podsystemu I/O
- Opóźnienie sieci
- Kolejne obciążenie we/wy powodujące konflikt z naszym obciążeniem
- Konfiguracja synchronicznej replikacji/odbicia lustrzanego podsystemów we/wy
Z mojego doświadczenia wynika, że często jest to liczba PAGEIOLATCH_SH oczekiwania znacznie wzrosły w stosunku do wartości bazowej (normalnej), a czas oczekiwania również wzrósł (tj. zwiększył się czas odczytu I/O), ponieważ duża liczba odczytów przeciąża podsystem I/O. To nie jest problem podsystemu we/wy — to SQL Server napędzający więcej operacji we/wy niż powinien. Należy teraz przełączyć się na SQL Server, aby zidentyfikować przyczynę dodatkowych operacji we/wy.
Przyczyny dużej liczby odczytów we/wy
SQL Server ma dwa typy odczytów:logiczne wejścia/wyjścia i fizyczne wejścia/wyjścia. Gdy część mechanizmu pamięci masowej o metodach dostępu musi uzyskać dostęp do strony, prosi pulę buforów o wskaźnik do strony w pamięci (nazywaną logicznym we/wy), a pula buforów sprawdza metadane, aby sprawdzić, czy ta strona jest już w pamięci.
Jeśli strona znajduje się w pamięci, pula buforów daje wskaźnik metodom dostępu, a we/wy pozostaje logicznym we/wy. Jeśli strona nie znajduje się w pamięci, pula buforów wydaje „prawdziwe” we/wy (nazywane fizycznym we/wy), a wątek musi czekać na jego zakończenie — powołując PAGEIOLATCH_XX czekać. Po zakończeniu operacji we/wy i udostępnieniu wskaźnika wątek zostaje powiadomiony i może kontynuować działanie.
W idealnym świecie całe obciążenie zmieściłoby się w pamięci, więc gdy pula buforów „rozgrzeje się” i przechowa całe obciążenie, nie są wymagane żadne dalsze odczyty, a jedynie zapisy zaktualizowanych danych. Nie jest to jednak idealny świat, a większość z was nie ma takiego luksusu, więc niektóre lektury są nieuniknione. Dopóki liczba odczytów utrzymuje się na poziomie bazowym, nie ma problemu.
Gdy nagle i nieoczekiwanie wymagana jest duża liczba odczytów, oznacza to, że nastąpiła znacząca zmiana w obciążeniu, ilości pamięci puli buforów dostępnej do przechowywania kopii stron w pamięci lub obu.
Oto kilka możliwych przyczyn (nie jest to wyczerpująca lista):
- Ciśnienie pamięci zewnętrznej systemu Windows na serwerze SQL Server powodujące zmniejszenie rozmiaru puli buforów przez menedżera pamięci
- Planuj rozdęcie pamięci podręcznej powodujące wypożyczenie dodatkowej pamięci z puli buforów
- Plan zapytania wykonujący skanowanie tabeli/indeksu klastrowego (zamiast wyszukiwania indeksu) z powodu:
- wzrost ilości pracy
- problem z podsłuchiwaniem parametrów
- wymagany indeks nieklastrowy, który został usunięty lub zmieniony
- ukryta konwersja
Jeden wzorzec do wyszukania sugerowałby, że przyczyną jest skanowanie tabeli/indeksu klastrowego, w którym pojawia się również duża liczba CXPACKET czeka wraz z PAGEIOLATCH_SH czeka. Jest to powszechny wzorzec, który wskazuje na występowanie dużych, równoległych skanów tabel/indeksów klastrowych.
We wszystkich przypadkach możesz sprawdzić, jaki plan zapytania powoduje PAGEIOLATCH_SH czeka za pomocą sys.dm_os_waiting_tasks i inne DMV, a kod do tego można uzyskać w moim poście na blogu tutaj. Jeśli masz dostępne narzędzie do monitorowania innej firmy, może ono pomóc Ci zidentyfikować sprawcę bez brudzenia sobie rąk.
Przykładowy przepływ pracy z SQL Sentry i Eksploratorem planów
W prostym (oczywiście wymyślonym) przykładzie załóżmy, że korzystam z systemu klienckiego korzystającego z zestawu narzędzi SQL Sentry i widzę skok oczekiwania we/wy w widoku pulpitu nawigacyjnego SQL Sentry, jak pokazano poniżej:
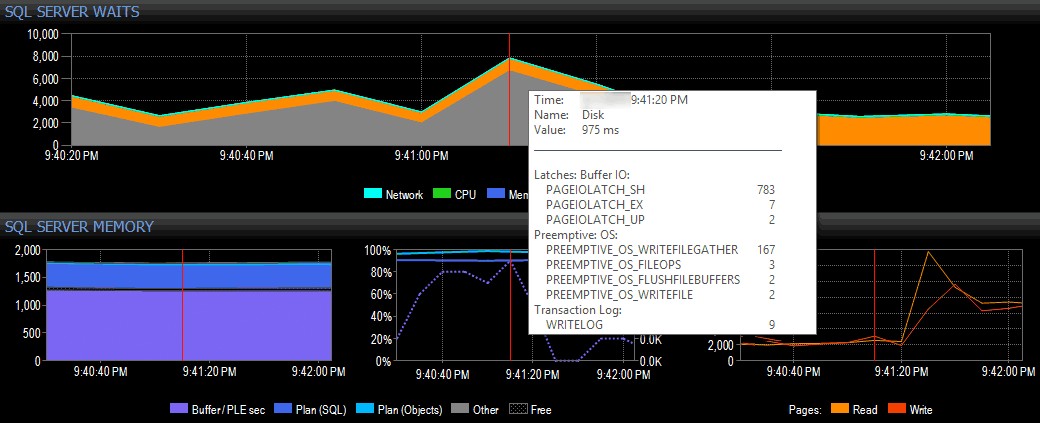
Wykrywanie skoku oczekiwania we/wy w SQL Sentry
Postanawiam to zbadać, klikając prawym przyciskiem myszy wybrany przedział czasu wokół czasu szczytu, a następnie przeskakując do widoku Top SQL, który pokaże mi najdroższe zapytania, które zostały wykonane:
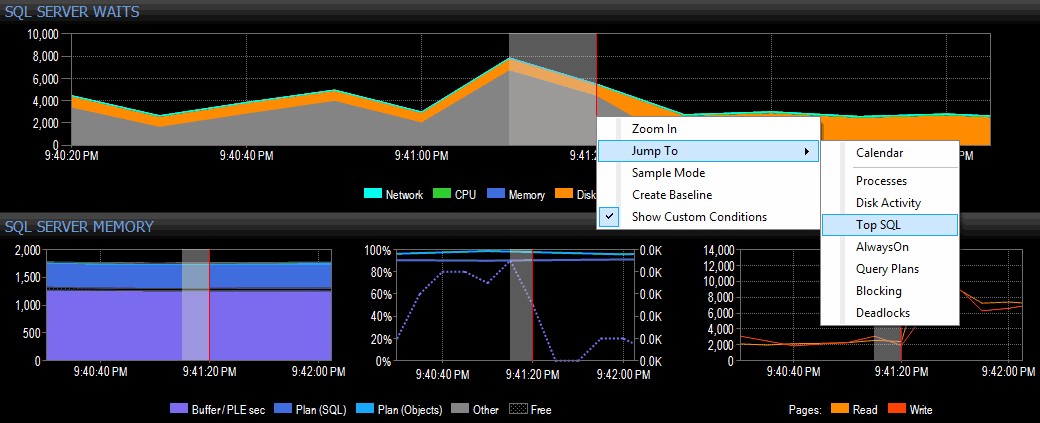
Podświetlanie zakresu czasu i przechodzenie do Top SQL
W tym widoku mogę zobaczyć, które długoterminowe lub wysokie zapytania I/O były uruchomione w momencie wystąpienia szczytu, a następnie wybrać drążenie ich planów zapytań (w tym przypadku jest tylko jedno długotrwałe zapytanie, który trwał prawie minutę):
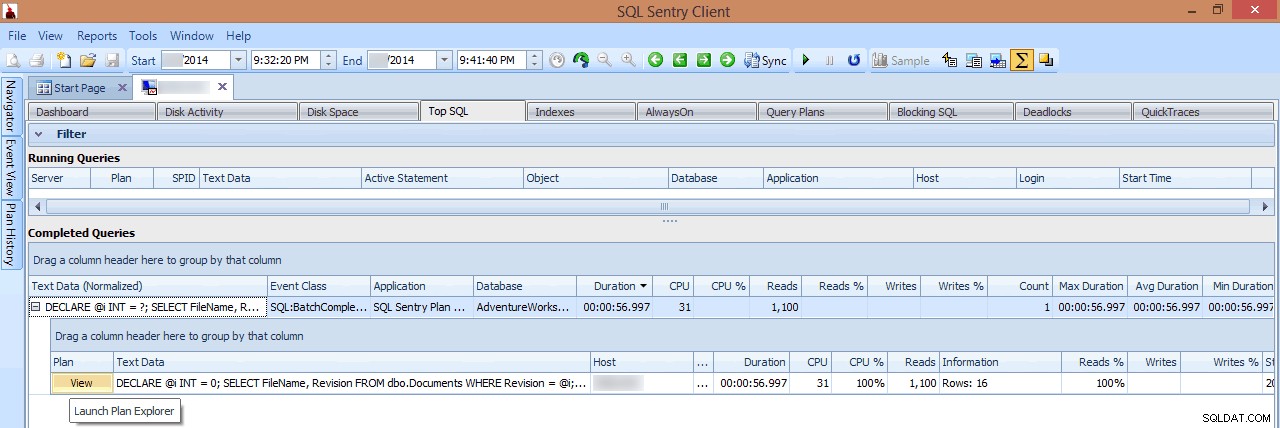
Przeglądanie długo działającego zapytania w Top SQL
Jeśli spojrzę na plan w kliencie SQL Sentry lub otworzę go w Eksploratorze planów SQL Sentry, od razu widzę wiele problemów. Liczba odczytów wymaganych do zwrócenia 7 wierszy wydaje się zbyt wysoka, różnica między wierszami szacowanymi i rzeczywistymi jest duża, a plan pokazuje skanowanie indeksu występujące w miejscu, w którym spodziewałbym się wyszukiwania:
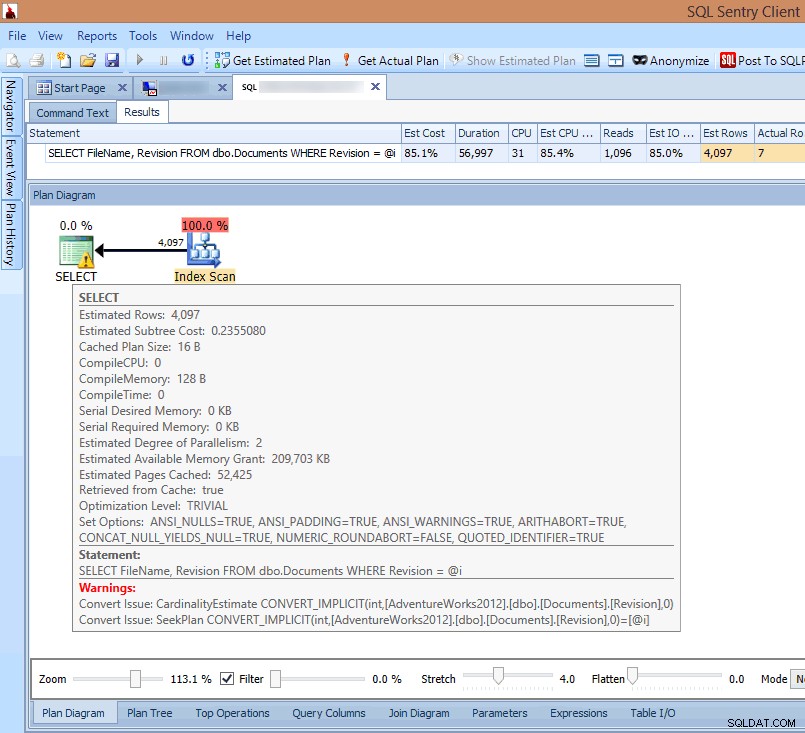
Wyświetlanie ostrzeżeń o niejawnej konwersji w planie zapytań
Przyczyną tego wszystkiego jest ostrzeżenie w SELECT operator:To niejawna konwersja!
Konwersje niejawne to podstępny problem spowodowany niezgodnością między typem danych predykatu wyszukiwania a typem danych przeszukiwanej kolumny lub obliczeniami wykonywanymi na kolumnie tabeli, a nie na predykacie wyszukiwania. W obu przypadkach SQL Server nie może użyć wyszukiwania indeksu w kolumnie tabeli i zamiast tego musi użyć skanowania.
Może się to pojawić w pozornie niewinnym kodzie, a częstym przykładem jest użycie obliczania dat. Jeśli masz tabelę przechowującą wiek klientów i chcesz wykonać obliczenia, aby zobaczyć, ile osób ma obecnie 21 lat lub więcej, możesz napisać następujący kod:
WHERE DATEADD (YEAR, 21, [MyTable].[BirthDate]) <= @today;
W przypadku tego kodu obliczenie odbywa się w kolumnie tabeli, dlatego nie można użyć wyszukiwania indeksu, co skutkuje niemożliwym do wyszukania wyrażeniem (technicznie znanym jako wyrażenie niepodlegające SARG) i skanowaniem indeksu tabeli/klastrowanego. Można to rozwiązać, przenosząc obliczenia na drugą stronę operatora:
WHERE [MyTable].[BirthDate] <= DATEADD (YEAR, -21, @today);
Jeśli chodzi o to, kiedy podstawowe porównanie kolumn wymaga konwersji typu danych, która może spowodować niejawną konwersję, mój kolega Jonathan Kehayias napisał doskonały wpis na blogu, w którym porównuje każdą kombinację typów danych i notatki, kiedy wymagana będzie niejawna konwersja.
Podsumowanie
Nie wpadaj w pułapkę myślenia, że nadmierne PAGEIOLATCH_XX oczekiwania są powodowane przez podsystem we/wy. Z mojego doświadczenia wynika, że są one zwykle spowodowane czymś, co ma związek z SQL Server i od tego zaczynam rozwiązywanie problemów.
Jeśli chodzi o ogólne statystyki oczekiwania, więcej informacji na temat ich używania do rozwiązywania problemów z wydajnością znajdziesz w:
- Moja seria wpisów na blogu SQLskills, zaczynająca się od statystyk Wait lub proszę powiedz mi, gdzie to boli
- Moja biblioteka typów Wait Types i Latch Classes tutaj
- Mój kurs szkoleniowy online Pluralsight SQL Server:Rozwiązywanie problemów z wydajnością za pomocą statystyk oczekiwania
- Wartość SQL
W następnym artykule z tej serii omówię inny typ oczekiwania, który jest częstą przyczyną odruchowych reakcji. Do tego czasu życzę miłego rozwiązywania problemów!



