W tym artykule użyto prostego zapytania, aby zapoznać się z głębokimi informacjami wewnętrznymi dotyczącymi zapytań aktualizujących.
Przykładowe dane i konfiguracja
Poniższy przykładowy skrypt tworzenia danych wymaga tabeli liczb. Jeśli jeszcze takiego nie masz, możesz użyć poniższego skryptu, aby go skutecznie utworzyć. Wynikowa tabela liczb będzie zawierać pojedynczą kolumnę liczb całkowitych z liczbami od jednego do jednego miliona:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Poniższy skrypt tworzy klastrową tabelę przykładowych danych z 10 000 identyfikatorów, z około 100 różnymi datami rozpoczęcia dla każdego identyfikatora. Kolumna daty zakończenia jest początkowo ustawiona na stałą wartość „99991231”.
CREATE TABLE dbo.Example
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
EndDate date NOT NULL
);
GO
INSERT dbo.Example WITH (TABLOCKX)
(SomeID, StartDate, EndDate)
SELECT DISTINCT
1 + (N.n % 10000),
DATEADD(DAY, 50000 * RAND(CHECKSUM(NEWID())), '20010101'),
CONVERT(date, '99991231', 112)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
CREATE CLUSTERED INDEX
CX_Example_SomeID_StartDate
ON dbo.Example
(SomeID, StartDate)
WITH (MAXDOP = 1, SORT_IN_TEMPDB = ON); Chociaż punkty przedstawione w tym artykule dotyczą dość ogólnie wszystkich aktualnych wersji SQL Server, poniższe informacje o konfiguracji można wykorzystać, aby zapewnić, że zobaczysz podobne plany wykonania i efekty wydajności:
- Dodatek Service Pack 3 dla SQL Server 2012 Wersja dla programistów x64
- Maksymalna pamięć serwera ustawiona na 2048 MB
- Cztery procesory logiczne dostępne dla instancji
- Brak włączonych flag śledzenia
- Domyślny poziom izolacji popełnionej odczytu
- Opcje baz danych RCSI i SI wyłączone
Wycieki kruszywa haszującego
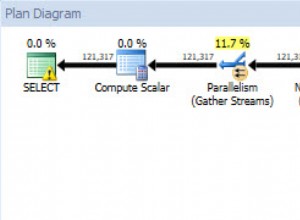
Jeśli uruchomisz powyższy skrypt tworzenia danych z włączonymi rzeczywistymi planami wykonania, agregacja skrótu może rozlać się do tempdb, generując ikonę ostrzeżenia:

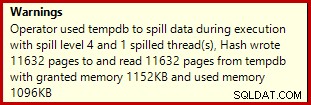
Po uruchomieniu na SQL Server 2012 z dodatkiem Service Pack 3 dodatkowe informacje o rozlaniu są wyświetlane w podpowiedzi:
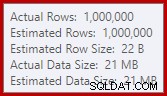
Ten wyciek może być zaskakujący, biorąc pod uwagę, że oszacowania wiersza wejściowego dla Hash Match są dokładnie poprawne:
Jesteśmy przyzwyczajeni do porównywania szacunków na wejściu dla sortowań i złączeń mieszających (tylko dane wejściowe kompilacji), ale gorliwe agregacje mieszające są różne. Agregat mieszający działa, gromadząc zgrupowane wiersze wyników w tabeli mieszającej, więc jest to liczba wyjścia wiersze, które są ważne:
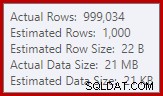
Estymator liczności w SQL Server 2012 dość słabo szacuje liczbę oczekiwanych odrębnych wartości (1000 w porównaniu do 999 034 rzeczywistych); w konsekwencji agregat mieszający rozlewa się rekursywnie do poziomu 4 w czasie wykonywania. „Nowy” estymator liczności dostępny w SQL Server 2014 i nowszych zapewnia dokładniejsze oszacowanie wyniku mieszania w tym zapytaniu, więc w takim przypadku nie zobaczysz rozlania wartości mieszania:

Liczba rzeczywistych wierszy może być nieco inna, biorąc pod uwagę użycie w skrypcie generatora liczb pseudolosowych. Ważną kwestią jest to, że rozlewy Hash Aggregate zależą od liczby unikalnych wartości wyjściowych, a nie od rozmiaru danych wejściowych.
Specyfikacja aktualizacji
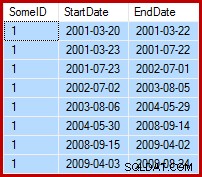
Bieżącym zadaniem jest aktualizacja przykładowych danych w taki sposób, aby daty końcowe były ustawione na dzień przed następną datą początkową (według SomeID). Na przykład kilka pierwszych wierszy przykładowych danych może wyglądać tak przed aktualizacją (wszystkie daty zakończenia ustawione na 9999-12-31):

Następnie tak po aktualizacji:
1. Zapytanie o aktualizację linii bazowej
Jeden dość naturalny sposób wyrażenia wymaganej aktualizacji w T-SQL jest następujący:
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate =
ISNULL
(
(
SELECT TOP (1)
DATEADD(DAY, -1, E2.StartDate)
FROM dbo.Example AS E2 WITH (TABLOCK)
WHERE
E2.SomeID = dbo.Example.SomeID
AND E2.StartDate > dbo.Example.StartDate
ORDER BY
E2.StartDate ASC
),
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); Powykonawczy (rzeczywisty) plan wykonania to:
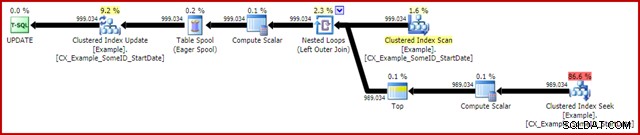
Najbardziej godną uwagi funkcją jest użycie szpuli stołu Chętnej, aby zapewnić ochronę Halloween. Jest to wymagane do poprawnego działania w tym miejscu ze względu na samoprzyłączanie tabeli docelowej aktualizacji. W efekcie wszystko po prawej stronie bufora jest uruchamiane do końca, przechowując wszystkie informacje potrzebne do wprowadzenia zmian w tabeli roboczej tempdb. Po zakończeniu operacji odczytu zawartość tabeli roboczej jest odtwarzana w celu zastosowania zmian w iteratorze aktualizacji indeksu klastrowego.
Wydajność
Aby skupić się na maksymalnym potencjale wydajności tego planu wykonania, możemy wielokrotnie uruchomić to samo zapytanie aktualizacyjne. Oczywiście tylko pierwsze uruchomienie spowoduje jakiekolwiek zmiany w danych, ale okazuje się, że jest to drobna uwaga. Jeśli Ci to przeszkadza, możesz zresetować kolumnę daty zakończenia przed każdym uruchomieniem, używając poniższego kodu. Ogólne kwestie, które przedstawię, nie zależą od liczby faktycznie dokonanych zmian danych.
UPDATE dbo.Example WITH (TABLOCKX) SET EndDate = CONVERT(date, '99991231', 112);
Gdy zbieranie planu wykonania jest wyłączone, wszystkie wymagane strony w puli buforów i nie ma resetowania wartości dat zakończenia między uruchomieniami, to zapytanie jest zwykle wykonywane w ciągu około 5700 ms na moim laptopie. Dane wyjściowe statystyk we/wy są następujące:(odczyty odczytu z wyprzedzeniem i liczniki LOB wyniosły zero i są pomijane ze względu na spację)
Table 'Example'. Scan count 999035, logical reads 6186219, physical reads 0 Table 'Worktable'. Scan count 1, logical reads 2895875, physical reads 0
Licznik skanów reprezentuje liczbę uruchomień operacji skanowania. W przypadku tabeli Przykład jest to 1 dla skanowania indeksu klastrowego i 999 034 dla każdego odbicia skorelowanego wyszukiwania indeksu klastrowego. Stół roboczy używany przez Chętny bufor ma operację skanowania rozpoczętą tylko raz.
Odczyty logiczne
Bardziej interesującą informacją w wyjściu IO jest liczba odczytów logicznych:ponad 6 milionów dla tabeli Przykład i prawie 3 miliony do stołu roboczego.
Odczyty logiczne tabeli Przykład są głównie związane z Poszukiwaniem i Aktualizacją. Seek powoduje 3 logiczne odczyty dla każdej iteracji:po 1 dla poziomu głównego, pośredniego i liścia indeksu. Aktualizacja kosztuje również 3 odczyty za każdym wierszem jest aktualizowany, gdy silnik nawiguje w dół drzewa b, aby zlokalizować wiersz docelowy. Skanowanie indeksu klastrowego odpowiada tylko za kilka tysięcy odczytów, po jednym na stronę przeczytaj.
Stół roboczy Spool jest również wewnętrznie skonstruowany jako b-drzewo i zlicza wielokrotne odczyty, gdy szpula lokalizuje pozycję wstawiania, jednocześnie zużywając dane wejściowe. Być może wbrew intuicji bufor nie liczy odczytów logicznych podczas odczytu w celu przeprowadzenia aktualizacji indeksu klastrowego. Jest to po prostu konsekwencja implementacji:odczyt logiczny jest liczony za każdym razem, gdy kod wykonuje BPool::Get metoda. Zapis do buforu wywołuje tę metodę na każdym poziomie indeksu; odczytywanie ze szpuli następuje po innej ścieżce kodu, która nie wywołuje funkcji BPool::Get w ogóle.
Zwróć również uwagę, że dane wyjściowe statystyk we/wy zgłaszają pojedynczą sumę dla tabeli Przykład, mimo że dostęp do niej uzyskują trzy różne iteratory w planie wykonania (skanowanie, wyszukiwanie i aktualizacja). Ten ostatni fakt utrudnia skorelowanie odczytów logicznych z iteratorem, który je spowodował. Mam nadzieję, że to ograniczenie zostanie rozwiązane w przyszłej wersji produktu.
2. Zaktualizuj za pomocą numerów wierszy
Innym sposobem wyrażenia zapytania o aktualizację jest numerowanie wierszy według identyfikatora i łączenie:
WITH Numbered AS
(
SELECT
E.SomeID,
E.StartDate,
E.EndDate,
rn = ROW_NUMBER() OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate ASC)
FROM dbo.Example AS E
)
UPDATE This WITH (TABLOCKX)
SET EndDate =
ISNULL
(
DATEADD(DAY, -1, NextRow.StartDate),
CONVERT(date, '99991231', 112)
)
FROM Numbered AS This
LEFT JOIN Numbered AS NextRow WITH (TABLOCK)
ON NextRow.SomeID = This.SomeID
AND NextRow.rn = This.rn + 1
OPTION (MAXDOP 1, MERGE JOIN); Plan powykonawczy jest następujący:
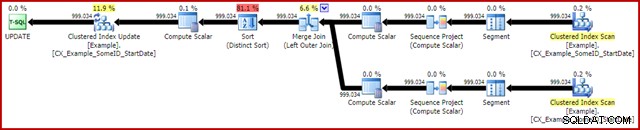
To zapytanie zwykle trwa 2950 ms na moim laptopie, co wypada korzystnie w porównaniu z 5700ms (w tych samych okolicznościach) widzianym w oryginalnym oświadczeniu o aktualizacji. Dane wyjściowe statystyk we/wy to:
Table 'Example'. Scan count 2, logical reads 3001808, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Pokazuje to dwa skanowania rozpoczęte dla tabeli Przykład (po jednym dla każdego iteratora skanowania indeksu klastrowego). Odczyty logiczne są ponownie agregacją wszystkich iteratorów, które uzyskują dostęp do tej tabeli w planie kwerend. Tak jak poprzednio, brak podziału uniemożliwia ustalenie, który iterator (z dwóch skanów i aktualizacji) odpowiadał za 3 miliony odczytów.
Niemniej jednak mogę powiedzieć, że skanowanie indeksu klastrowego liczą tylko kilka tysięcy odczytów logicznych. Zdecydowana większość odczytów logicznych jest spowodowana przez aktualizację indeksu klastrowego, przechodzącą w dół drzewa indeksu b w celu znalezienia pozycji aktualizacji dla każdego przetwarzanego wiersza. Na razie będziesz musiał uwierzyć mi na słowo; więcej wyjaśnień pojawi się wkrótce.
Wady
To już prawie koniec dobrych wiadomości dla tej formy zapytania. Działa znacznie lepiej niż oryginał, ale jest znacznie mniej zadowalający z wielu innych powodów. Główny problem jest spowodowany ograniczeniem optymalizatora, co oznacza, że nie rozpoznaje on, że operacja numerowania wierszy daje unikalny numer dla każdego wiersza w partycji SomeID.
Ten prosty fakt prowadzi do szeregu niepożądanych konsekwencji. Po pierwsze, łączenie scalające jest skonfigurowane do działania w trybie łączenia wielu do wielu. Jest to powód, dla którego (nieużywana) tabela robocza w statystykach we/wy (scalanie wiele do wielu wymaga tabeli roboczej dla zduplikowanych cofnięć klucza łączenia). Oczekiwanie złączenia wiele-do-wielu oznacza również, że oszacowanie kardynalności dla wyjścia złączenia jest beznadziejnie błędne:
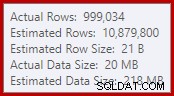
W konsekwencji sortowanie żąda zbyt dużej ilości pamięci. Właściwości węzła głównego pokazują, że sortowanie polubiłoby 812,752 KB pamięci, chociaż przyznano mu tylko 379 440 KB ze względu na ograniczone ustawienie maksymalnej pamięci serwera (2048 MB). W rzeczywistości sortowanie wykorzystywało maksymalnie 58 968 KB w czasie wykonywania:
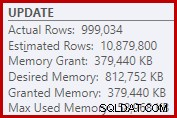
Nadmiar pamięci zapewnia kradzież pamięci z innych produktywnych zastosowań i może prowadzić do zapytań oczekujących, aż pamięć stanie się dostępna. Pod wieloma względami nadmierne przyznanie pamięci może być większym problemem niż niedocenianie.
Ograniczenie optymalizatora wyjaśnia również, dlaczego wskazówka dotycząca łączenia scalającego była konieczna w zapytaniu w celu uzyskania najlepszej wydajności. Bez tej wskazówki optymalizator błędnie ocenia, że łączenie haszujące byłoby tańsze niż łączenie scalające wiele-do-wielu. Plan łączenia haszującego trwa średnio 3350 ms.
Jako ostateczną negatywną konsekwencję zauważ, że sortowanie w planie jest sortowaniem odrębnym. Teraz istnieje kilka powodów takiego sortowania (nie tylko dlatego, że zapewnia wymaganą ochronę Halloween), ale jest to tylko Różne Sortuj, ponieważ optymalizator pomija informacje o unikalności. Ogólnie rzecz biorąc, trudno jest lubić ten plan wykonania poza wydajnością.
3. Aktualizacja za pomocą funkcji analizy LEAD
Ponieważ ten artykuł dotyczy głównie programu SQL Server 2012 i nowszych wersji, zapytanie o aktualizację możemy w sposób naturalny wyrazić za pomocą funkcji analitycznej LEAD. W idealnym świecie moglibyśmy użyć bardzo zwartej składni, takiej jak:
-- Not allowed
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate = LEAD(StartDate) OVER (
PARTITION BY SomeID ORDER BY StartDate); Niestety nie jest to legalne. Powoduje to komunikat o błędzie 4108, „Funkcje okienkowe mogą pojawiać się tylko w klauzulach SELECT lub ORDER BY”. To trochę frustrujące, ponieważ mieliśmy nadzieję na plan wykonania, który pozwoli uniknąć samodołączenia (i związanej z nim aktualizacji Ochrona Halloween).
Dobrą wiadomością jest to, że nadal możemy uniknąć samodzielnego łączenia przy użyciu wspólnego wyrażenia tabelowego lub tabeli pochodnej. Składnia jest nieco bardziej szczegółowa, ale idea jest prawie taka sama:
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); Plan powykonawczy to:

Zwykle trwa to około 3400 ms na moim laptopie, który jest wolniejszy niż rozwiązanie z liczbą wierszy (2950 ms), ale wciąż znacznie szybsze niż oryginał (5700 ms). Jedną rzeczą, która wyróżnia się na planie wykonania, jest rozlew sortowania (ponownie, dodatkowe informacje o rozlaniu dzięki ulepszeniom w SP3):
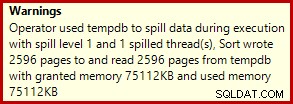
To dość mały wyciek, ale nadal może w pewnym stopniu wpływać na wydajność. Dziwne jest to, że oszacowanie danych wejściowych do sortowania jest dokładnie poprawne:
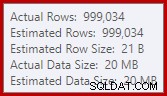
Na szczęście istnieje „poprawka” dla tego konkretnego warunku w SQL Server 2012 SP2 CU8 (i innych wydaniach — zobacz artykuł KB, aby uzyskać szczegółowe informacje). Uruchomienie zapytania z włączoną poprawką i wymaganą flagą śledzenia 7470 oznacza, że sortowanie żąda wystarczającej ilości pamięci, aby zapewnić, że nigdy nie rozleje się na dysk, jeśli szacowany rozmiar sortowania danych wejściowych nie zostanie przekroczony.
Kwerenda aktualizacji LEAD bez wycieku sortowania
Dla urozmaicenia, poniższe zapytanie z obsługą poprawek używa składni tabeli pochodnej zamiast CTE:
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate, CONVERT(date, '99991231', 112)
)
FROM
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
) AS CED
OPTION (MAXDOP 1, QUERYTRACEON 7470); Nowy plan powykonawczy to:

Wyeliminowanie małego rozlania poprawia wydajność z 3400 ms do 3250 ms . Dane wyjściowe statystyk we/wy to:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Jeśli porównasz to z odczytami logicznymi dla zapytania o numerze wierszy, zobaczysz, że odczyty logiczne zmniejszyły się z 3001808 do 2999455 — różnica 2353 odczytów. Odpowiada to dokładnie usunięciu pojedynczego klastrowego skanowania indeksu (jeden odczyt na stronę).
Być może pamiętasz, jak wspomniałem, że zdecydowana większość logicznych odczytów dla tych zapytań aktualizacyjnych jest powiązana z aktualizacją klastrowego indeksu, a Skanowania były skojarzone z „tylko kilkoma tysiącami odczytów”. Możemy teraz zobaczyć to nieco bardziej bezpośrednio, uruchamiając proste zapytanie zliczające wiersze w tabeli Przykład:
SET STATISTICS IO ON; SELECT COUNT(*) FROM dbo.Example WITH (TABLOCK); SET STATISTICS IO OFF;
Wyjście IO pokazuje dokładnie 2353 logiczną różnicę odczytu między numerem wiersza a aktualizacjami potencjalnych klientów:
Table 'Example'. Scan count 1, logical reads 2353, physical reads 0
Dalsze ulepszenia?
Zapytanie wiodące z rozlaniem (3250 ms) jest nadal nieco wolniejsze niż zapytanie o numerach dwuwierszowych (2950 ms), co może być nieco zaskakujące. Intuicyjnie można by oczekiwać, że pojedynczy skan i funkcja analityczna (buforowanie okien i agregacja strumienia) będą szybsze niż dwa skany, dwa zestawy numeracji wierszy i łączenie.
Niezależnie od tego, rzeczą, która wyskakuje z planu wykonania zapytania wiodącego, jest Sort. Był również obecny w zapytaniu z numerami wierszy, gdzie przyczynił się do ochrony Halloween, a także zoptymalizowanej kolejności sortowania dla aktualizacji indeksu klastrowego (która ma ustawioną właściwość DMLRequestSort).
Chodzi o to, że sortowanie jest całkowicie niepotrzebne w planie zapytania wiodącego. Nie jest to potrzebne do ochrony przed Halloween, ponieważ samo-sprzężenie zniknęło. Nie jest to również potrzebne do zoptymalizowanej kolejności sortowania wstawiania:wiersze są odczytywane w kolejności kluczy klastrowych i nie ma w planie nic, co mogłoby zakłócić tę kolejność. Prawdziwy problem można zobaczyć, patrząc na właściwości sortowania:

Zwróć uwagę na sekcję Order By tam. Sortowanie jest uporządkowane według SomeID i StartDate (klucze indeksu klastrowego), ale także według [Uniq1002], który jest uniquifier. Jest to konsekwencją niezadeklarowania indeksu klastrowego jako unikalnego, mimo że podjęliśmy kroki w zapytaniu o populację danych, aby upewnić się, że kombinacja SomeID i StartDate będzie rzeczywiście unikalna. (To było celowe, więc mogłem o tym porozmawiać.)
Mimo to jest to ograniczenie. Wiersze są odczytywane z indeksu klastrowego w kolejności i istnieją niezbędne gwarancje wewnętrzne, tak aby optymalizator mógł bezpiecznie uniknąć tego sortowania. Jest to po prostu przeoczenie, że optymalizator nie rozpoznaje, że strumień przychodzący jest sortowany według uniquifier oraz SomeID i StartDate. Rozpoznaje, że kolejność (SomeID, StartDate) może zostać zachowana, ale nie (SomeID, StartDate, uniquifier). Ponownie mam nadzieję, że zostanie to rozwiązane w przyszłej wersji.
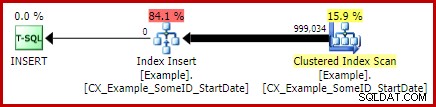
Aby obejść ten problem, możemy zrobić to, co powinniśmy zrobić w pierwszej kolejności:zbudować indeks klastrowy jako unikalny:
CREATE UNIQUE CLUSTERED INDEX CX_Example_SomeID_StartDate ON dbo.Example (SomeID, StartDate) WITH (DROP_EXISTING = ON, MAXDOP = 1);
Zostawię to jako ćwiczenie dla czytelnika, aby pokazać, że pierwsze dwa zapytania (nie LEAD) nie korzystają z tej zmiany indeksowania (pominięto wyłącznie ze względu na brak miejsca – jest wiele do omówienia).
Ostateczna forma zapytania o aktualizację leada
Dzięki unikalnemu indeks klastrowy w miejscu, dokładnie to samo zapytanie LEAD (CTE lub tabela pochodna, jak sobie życzysz) generuje szacowany plan (przed wykonaniem), którego oczekujemy:

Wydaje się to całkiem optymalne. Pojedyncza operacja odczytu i zapisu z minimalną liczbą operatorów pomiędzy nimi. Z pewnością wydaje się znacznie lepszy niż poprzednia wersja z niepotrzebnym sortowaniem, które wykonywało się w 3250 ms po usunięciu możliwego do uniknięcia rozlania (kosztem nieznacznego zwiększenia przyznanej pamięci).
Plan powykonawczy (rzeczywisty) jest prawie taki sam jak plan przedegzekucyjny:

Wszystkie szacunki są dokładnie poprawne, z wyjątkiem danych wyjściowych funkcji Window Spool, które są przesunięte o 2 wiersze. Informacje o statystykach IO są dokładnie takie same, jak przed usunięciem sortowania, jak można się spodziewać:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Podsumowując krótko, jedyną widoczną różnicą między tym nowym planem a bezpośrednio poprzednim planem jest to, że Sort (z szacowanym udziałem w kosztach wynoszącym prawie 80%) został usunięty.
Niespodzianką może więc być informacja, że nowe zapytanie – bez sortowania – wykonuje się w 5000 ms . Jest to znacznie gorsze niż 3250 ms z sortowaniem i prawie tak długo, jak oryginalne zapytanie sprzężenia z pętlą 5700 ms. Rozwiązanie numeracji dwurzędowej jest wciąż o wiele do przodu przy 2950 ms.
Wyjaśnienie
Wyjaśnienie jest nieco ezoteryczne i odnosi się do sposobu obsługi zatrzasków w przypadku najnowszego zapytania. Możemy pokazać ten efekt na kilka sposobów, ale najprostszym jest prawdopodobnie przyjrzenie się statystykom oczekiwania i zatrzasku za pomocą DMV:
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
DBCC SQLPERF('sys.dm_os_latch_stats', CLEAR);
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1);
SELECT * FROM sys.dm_os_latch_stats AS DOLS
WHERE DOLS.waiting_requests_count > 0
ORDER BY DOLS.latch_class;
SELECT * FROM sys.dm_os_wait_stats AS DOWS
WHERE DOWS.waiting_tasks_count > 0
ORDER BY DOWS.waiting_tasks_count DESC; Gdy indeks klastrowy nie jest unikalny, a w planie jest sortowanie, nie ma znaczących oczekiwań, tylko kilka PAGEIOLATCH_UP i oczekiwane wartości SOS_SCHEDULER_YIELD.
Gdy indeks klastrowy jest unikalny, a sortowanie jest usuwane, oczekiwania są następujące:
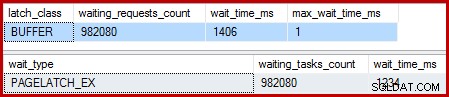
Jest tam 982 080 ekskluzywnych zatrzasków stron, z czasem oczekiwania, który wyjaśnia prawie cały dodatkowy czas wykonania. Aby podkreślić, jest to prawie jeden zaktualizowany czas oczekiwania na zatrzask na wiersz! Możemy spodziewać się zmiany zatrzasku na wiersz, ale nie zatrzasku czekaj , zwłaszcza gdy zapytanie testowe jest jedynym działaniem w instancji. Oczekiwanie na zatrzask jest krótkie, ale jest ich bardzo dużo.
Leniwe zatrzaski
Po wykonaniu zapytania z dołączonym debugerem i analizatorem wyjaśnienie jest następujące.
Skanowanie indeksu klastrowego wykorzystuje leniwe zatrzaski – optymalizacja polegająca na tym, że zatrzaski są zwalniane tylko wtedy, gdy inny wątek wymaga dostępu do strony. Zwykle zatrzaski są zwalniane natychmiast po przeczytaniu lub napisaniu. Leniwe zatrzaski optymalizują przypadek, w którym skanowanie całej strony spowodowałoby uzyskanie i zwolnienie tego samego zatrzasku strony dla każdego wiersza. Gdy leniwe zatrzaskiwanie jest używane bez rywalizacji, dla całej strony pobierany jest tylko jeden zatrzask.
Problem polega na tym, że potokowy charakter planu wykonania (brak operatorów blokujących) oznacza, że odczyty nakładają się na zapisy. Gdy aktualizacja indeksu klastrowego próbuje uzyskać zatrzask EX w celu zmodyfikowania wiersza, prawie zawsze stwierdzi, że strona jest już zatrzaśnięta SH (leniwy zatrzask pobrany przez skanowanie indeksu klastrowego). Ta sytuacja powoduje oczekiwanie na zatrzask.
W ramach przygotowań do oczekiwania i przełączenia się na następny element, który można uruchomić w harmonogramie, kod stara się zwolnić wszelkie leniwe zatrzaski. Zwolnienie leniwego zatrzasku sygnalizuje pierwszemu uprawnionemu kelnerowi, którym akurat jest nim samym. Mamy więc dziwną sytuację, w której wątek blokuje się, zwalnia leniwy zatrzask, a następnie sygnalizuje sobie, że można go ponownie uruchomić. Wątek ponownie się uruchamia i kontynuuje, ale dopiero po wykonaniu wszystkich zmarnowanych prac w trybie wstrzymania i przełączenia, sygnalizowania i wznawiania. Jak powiedziałem wcześniej, czas oczekiwania jest krótki, ale jest ich dużo.
Z tego, co wiem, ta dziwna sekwencja wydarzeń jest zaplanowana i ma dobre wewnętrzne powody. Mimo to nie można uciec od faktu, że ma to dość dramatyczny wpływ na wydajność tutaj. Zrobię kilka pytań na ten temat i zaktualizuję artykuł, jeśli będzie publiczne oświadczenie do złożenia. W międzyczasie nadmierne oczekiwanie na samoblokujące może być czymś, na co należy uważać w przypadku zapytań o aktualizację potokową, chociaż nie jest jasne, co należy z tym zrobić z punktu widzenia autora zapytania.
Czy to oznacza, że podejście polegające na podwójnej numeracji wierszy jest najlepszym, co możemy zrobić dla tego zapytania? Niezupełnie.
4. Ręczna ochrona Halloween
Ta ostatnia opcja może brzmieć i wyglądać trochę szalenie. Ogólną ideą jest zapisanie wszystkich informacji potrzebnych do wprowadzenia zmian w zmiennej tabeli, a następnie wykonanie aktualizacji w osobnym kroku.
Z braku lepszego opisu nazywam to podejściem „ręcznego HP”, ponieważ jest ono koncepcyjnie podobne do zapisywania wszystkich informacji o zmianach w buforze tabeli Chętni (jak widać w pierwszym zapytaniu) przed uruchomieniem aktualizacji z tego bufora.
W każdym razie kod wygląda następująco:
DECLARE @U AS table
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
NewEndDate date NULL,
PRIMARY KEY CLUSTERED (SomeID, StartDate)
);
INSERT @U
(SomeID, StartDate, NewEndDate)
SELECT
E.SomeID,
E.StartDate,
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E WITH (TABLOCK)
OPTION (MAXDOP 1);
UPDATE E WITH (TABLOCKX)
SET E.EndDate =
ISNULL
(
U.NewEndDate, CONVERT(date, '99991231', 112)
)
FROM dbo.Example AS E
JOIN @U AS U
ON U.SomeID = E.SomeID
AND U.StartDate = E.StartDate
OPTION (MAXDOP 1, MERGE JOIN); Ten kod celowo używa zmiennej tabeli aby uniknąć kosztów automatycznie tworzonych statystyk, które poniosłoby użycie tabeli tymczasowej. To jest w porządku, ponieważ znam pożądany kształt planu i nie zależy to od oszacowań kosztów ani informacji statystycznych.
Jedyną wadą zmiennej tabeli (bez flagi śledzenia) jest to, że optymalizator zazwyczaj szacuje pojedynczy wiersz i wybiera zagnieżdżone pętle do aktualizacji. Aby temu zapobiec, użyłem podpowiedzi łączenia przez scalenie. Ponownie, jest to spowodowane dokładnym poznaniem kształtu planu, który ma zostać osiągnięty.
Plan po wykonaniu dla zmiennej tabeli insert wygląda dokładnie tak samo, jak zapytanie, w którym wystąpił problem z zatrzaskiem czeka:

Zaletą tego planu jest to, że nie zmienia on tej samej tabeli, z której czyta. Ochrona przed Halloween nie jest wymagana i nie ma szans na ingerencję zatrzasku. Ponadto istnieją znaczące optymalizacje wewnętrzne dla obiektów tempdb (blokowanie i rejestrowanie), a także stosowane są inne normalne optymalizacje ładowania zbiorczego. Pamiętaj, że optymalizacje zbiorcze są dostępne tylko w przypadku wstawiania, a nie aktualizacji lub usuwania.
Plan powykonawczy dla oświadczenia aktualizującego to:
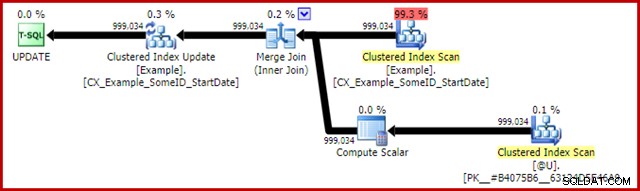
Połączenie scalające tutaj jest wydajnym typem jeden-do-wielu. Co więcej, ten plan kwalifikuje się do specjalnej optymalizacji, co oznacza, że skanowanie indeksu klastrowego i aktualizacja indeksu klastrowego współużytkują ten sam zestaw wierszy. Ważną konsekwencją jest to, że Update nie musi już lokalizować wiersza do aktualizacji – jest on już poprawnie pozycjonowany przez odczyt. Oszczędza to strasznie dużo logicznych odczytów (i innej aktywności) podczas aktualizacji.
W normalnych planach wykonania nie ma nic, aby pokazać, gdzie jest stosowana ta optymalizacja udostępnionego zestawu wierszy, ale włączenie nieudokumentowanej flagi śledzenia 8666 uwidacznia dodatkowe właściwości aktualizacji i skanowania, które pokazują, że udostępnianie zestawu wierszy jest w użyciu, i że podejmowane są kroki w celu zapewnienia, że aktualizacja jest bezpieczna z Halloweenowego Problemu.
Statystyczne dane wyjściowe IO dla dwóch zapytań są następujące:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0 Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 (999034 row(s) affected) Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 Table '#B9C034B8'. Scan count 1, logical reads 2353, physical reads 0
Oba odczyty tabeli Przykład obejmują pojedyncze skanowanie i jeden odczyt logiczny na stronę (zobacz wcześniej proste zapytanie zliczające wiersze). Tabela #B9C034B8 to nazwa wewnętrznego obiektu tempdb obsługującego zmienną tabeli. Łączna liczba odczytów logicznych dla obu zapytań wynosi 3 * 2353 =7059. Tabela robocza jest wewnętrzną pamięcią masową używaną przez bufor okna.
Typowy czas wykonania tego zapytania to 2300 ms . Wreszcie mamy coś, co pokonuje zapytanie z podwójną numeracją wierszy (2950 ms), co jest tak mało prawdopodobne, jak mogłoby się wydawać.
Ostateczne myśli
Mogą istnieć jeszcze lepsze sposoby napisania tej aktualizacji, które działają jeszcze lepiej niż powyższe „ręczne rozwiązanie HP”. Wyniki wydajności mogą nawet różnić się w zależności od sprzętu i konfiguracji programu SQL Server, ale żaden z nich nie jest głównym punktem tego artykułu. Nie oznacza to, że nie jestem zainteresowany lepszymi zapytaniami lub porównaniami wydajności – jestem.
Chodzi o to, że w SQL Server dzieje się o wiele więcej, niż jest to ujawnione w planach wykonania. Mam nadzieję, że niektóre szczegóły omówione w tym dość długim artykule będą interesujące, a nawet przydatne dla niektórych osób.
Dobrze jest mieć oczekiwania dotyczące wydajności i wiedzieć, jakie kształty i właściwości planu są ogólnie korzystne. Tego rodzaju doświadczenie i wiedza będą Ci dobrze służyć w przypadku 99% lub więcej zapytań, o które kiedykolwiek zostaniesz poproszony. Czasami jednak dobrze jest spróbować czegoś nieco dziwnego lub niezwykłego, aby zobaczyć, co się stanie i zweryfikować te oczekiwania.