Wcześniej pisałem na blogu o tym, dlaczego nie lubię sp_updatestats. Niedawno znalazłem inny powód, dla którego to nie jest mój przyjaciel. TL;DR:Nie aktualizuje statystyk zindeksowanych widoków. Teraz dokumentacja nie twierdzi, że tak, więc nie ma tutaj błędu. Dokumentacja MSDN wyraźnie stwierdza:
Uruchamia UPDATE STATISTICS dla wszystkich zdefiniowanych przez użytkownika i wewnętrznych tabel w bieżącej bazie danych.Ale… ilu z was pomyślało o swoich zindeksowanych widokach i zastanawiało się, czy zostały one zaktualizowane? Przyznaję, że nie. Zapominam o widokach indeksowanych, co jest niefortunne, ponieważ przy odpowiednim użyciu potrafią być naprawdę potężne. Mogą być również koszmarem do rozwikłania podczas rozwiązywania problemów, ale nie zamierzam dziś dyskutować o ich użyciu. Chcę tylko, abyś był świadomy, że nie są one aktualizowane przez sp_updatestats, i zobaczył, jakie masz opcje.
Konfiguracja
Ponieważ World Series właśnie się zakończyło, będziemy używać bazy danych Baseball do naszych testów. Możesz go pobrać ze strony zasobów SQLskills. Po przywróceniu utworzymy kopię tabeli dbo.Players o nazwie dbo.PlayerInfo, załadujemy do niej kilka tysięcy wierszy, a następnie utworzymy widok indeksowany, który połączy naszą nową tabelę z tabelą PitchingPost:
UŻYJ [BaseballData];GO CREATE TABLE [dbo].[PlayerInfo]( [lahmanID] [int] NOT NULL, [playerID] [varchar](10) NULL DEFAULT (NULL), [managerID] [varchar]( 10) NULL DEFAULT (NULL), [hofID] [varchar](10) NULL DEFAULT (NULL), [rocznikurodzenia] [int] NULL DEFAULT (NULL), [miesiąc urodzenia] [int] NULL DEFAULT (NULL), [data urodzenia] [int] NULL DEFAULT (NULL), [birthCountry] [varchar](50) NULL DEFAULT (NULL), [birthState] [varchar](2) NULL DEFAULT (NULL), [birthCity] [varchar](50) NULL DEFAULT (NULL), [rok śmierci] [int] NULL DEFAULT (NULL), [miesiączgonu] [int] NULL DEFAULT (NULL), [dzień śmierci] [int] NULL DEFAULT (NULL), [kraj śmierci] [varchar](50) NULL DEFAULT (NULL), [deathState] [varchar](2) NULL DEFAULT (NULL), [deathCity] [varchar](50) NULL DEFAULT (NULL), [nameFirst] [varchar](50) NULL DEFAULT (NULL), [nameLast] [varchar](50) NULL DEFAULT (NULL), [nameNote] [varchar](255) NULL DEFAULT (NULL), [nameGiven] [varchar](255) NULL DEFAULT (NULL), [nameNick] [varchar ](255) NULL DEFAULT (NULL), [waga] [int] NULL DEFAULT (NULL), [wysokość] [int] NULL, [nietoperze] [varchar](1) NULL DEFAULT (NULL), [rzuty] [varchar](1) NULL DEFAULT (NULL), [debiut] [varchar]( 10) NULL DEFAULT (NULL), [finalGame] [varchar](10) NULL DEFAULT (NULL), [college] [varchar](50) NULL DEFAULT (NULL), [lahman40ID] [varchar](9) NULL DEFAULT ( NULL), [lahman45ID] [varchar](9) NULL DEFAULT (NULL), [retroID] [varchar](9) NULL DEFAULT (NULL), [holtzID] [varchar](9) NULL DEFAULT (NULL), [bbrefID ] [varchar](9) NULL DEFAULT (NULL),KLUCZ PODSTAWOWY ([lahmanID] ASC) ON [PRIMARY]) ON [PRIMARY];GO INSERT INTO [dbo].[PlayerInfo] ([lahmanID] ,[playerID] ,[IDkierownika] ,[IDhof] ,[Rokurodzenia] ,[Miesiącurodzenia] ,[Dzieńurodzenia] ,[Krajurodzenia] ,[Państwo urodzenia] ,[Miasto urodzenia] ,[Rokzgonu] ,[Miesiączgonu] ,[Dzieńzgonu] ,[Kraj zgonu] , DeathState] ,[miasto śmierci] ,[imięNazwisko] ,[imięNazwisko] ,[imięNotatka] ,[imięDane] ,[imięNick] ,[waga] ,[wzrost] ,[nietoperze] ,[rzuty] ,[debiut] ,[finał] ,[uczelnia] ,[lahman40ID] ,[lahman45ID] ,[ retroID] , [holtzID] , [bbrefID])SELECT [lahmanID] ,[playerID] ,[managerID] ,[hofID] ,[RokUrodzenia] ,[Miesiącurodzenia] ,[Dzieńurodzenia] ,[Krajurodzenia] ,[Stan urodzenia] ,[Miasto urodzenia ] ,[RokZgonu] ,[MiesiącZgonu] ,[DzieńZgonu] ,[KrajZgonu] ,[Państwozgonu] ,[Miasto zgonu] ,[NazwiskoPierwsze] ,[NazwiskoNazwisko] ,[NazwiskoUwaga] ,[NazwiskoNadane] ,[NazwiskoNick] ,[waga] , [wysokość] , [nietoperze] , [rzuty] , [debiut] , [finalGame] , [uczelnia] , [lahman40ID] ,[lahman45ID] ,[retroI D] ,[holtzID] ,[bbrefID]FROM [dbo].[Gracze]GDZIE [lahmanID] <=10000; UTWÓRZ WIDOK [PlayerPostSeason] Z POWIĄZANIAMI SCHEMATÓW WYBIERZ [p].[lahmanID], [p].[nameFirst], [p].[nameLast], [p].[debiut], [p].[finalGame], [pp ].[IDRoku], [pp].[runda], [pp].[IDzespołu], [pp].[W], [pp].[L], [pp].[G] Z [dbo]. [PlayerInfo] [p] JOIN [dbo].[PitchingPost] [pp] ON [p].[ID gracza] =[pp].[ID gracza]; UTWÓRZ NIEPOWTARZALNY INDEKS KLASTROWY [CI_PlayerPostSeason] W [PlayerPostSeason] ([lahmanID], [yearID], [runda]); UTWÓRZ INDEKS NIESKLASTRAROWANY [NCI_PlayerPostSeason_Name] W [PlayerPostSeason] ([nameFirst], [nameLast]);
Jeśli sprawdzimy statystyki dla indeksów klastrowanych i nieklastrowanych, zobaczymy, że istnieją:
DBCC SHOW_STATISTICS („PlayerPostSeason”, CI_PlayerPostSeason) Z STAT_HEADER;GODBCC SHOW_STATISTICS („PlayerPostSeason”, NCI_PlayerPostSeason_Name) Z STAT_HEADER;GO
 Statystyki wyświetlania indeksu po początkowym utworzeniu
Statystyki wyświetlania indeksu po początkowym utworzeniu
Teraz wstawimy więcej wierszy do PlayerInfo:
INSERT INTO [dbo].[Informacje Gracza] ([ID lahman] , [ID gracza] , [ID kierownika] , [ID hof] , [Rokurodzenia] ,[Miesiącurodzenia] ,[Dzieńurodzenia] ,[Krajurodzenia] ,[Stan urodzenia] ,[ miasto urodzenia] ,[rok zgonu] ,[miesiąc zgonu] ,[dzień zgonu] ,[kraj zgonu] ,[stan zgonu] ,[miasto zgonu] ,[imięImię] ,[imięNazwisko] ,[imięNotatka] ,[imięNadane] ,[imięNick] ,[waga] ,[wysokość] ,[nietoperze] ,[rzuty] ,[debiut] ,[finalGame] ,[uczelnia] ,[lahman40ID] ,[lahman45ID] ,[retroID] ,[holtzID] ,[bbrefID])SELECT [lahmanID] , [ID gracza] , [ID menedżera] , [ID hof] , [Rok urodzenia] , [Miesiąc urodzenia] , [Dzień urodzenia] , [Kraj urodzenia] , [Państwo urodzenia] , [Miasto urodzenia] ,[Rok śmierci] ,[Miesiąc śmierci] ,[Dzień śmierci] ,[Kraj śmierci] ,[Państwo śmierci] ,[Miasto śmierci] ,[imięNazwisko] ,[imięNazwisko] ,[imięNazwisko] ,[imięNadane] ,[imięNick] ,[waga] ,[ wzrost] , [nietoperze] , [rzuty] , [debiut] , [finalGame] , [uczelnia] , [lahman40ID] ,[lahman45ID] ,[retroID] ,[holtzID] ,[bbrefID]OD [dbo].[Gracze] GDZIE [lahmanID]> 10000;
A jeśli sprawdzimy sys.dm_db_stats_properties, możemy zobaczyć modyfikacje wierszy:
SELECT [sch].[nazwa] AS [Schema], [tak].[nazwa] AS [NazwaObiektu], [tak].[typ] AS [TypObiektu], [ss].[nazwa] AS [Statystyka ], [sp].[last_updated] AS [StatsLastUpdated] , [sp].[rows] AS [RowsInTable] , [sp].[rows_sampled] AS [RowsSampled] , [sp].[licznik_modyfikacji] AS [RowModifications]FROM [sys].[obiekty] [tak]JOIN [sys].[statystyki] [ss] ON [so].[object_id] =[ss].[object_id]JOIN [sys].[schematy] [sch] ON [ tak].[schema_id] =[sch].[schema_id]OUTER APPLY [sys].[dm_db_stats_properties]([so].[object_id], [ss].[stats_id]) spWHERE [so].[name] =' PlayerPostSeason';
 Wiersze zmodyfikowane w widoku indeksowanym przez sys.dm_db_stats_properties
Wiersze zmodyfikowane w widoku indeksowanym przez sys.dm_db_stats_properties
I dla zabawy, jeśli sprawdzimy sys.sysindexes, zobaczymy tam również modyfikacje:
SELECT [tak].[nazwa], [si].[nazwa], [si].[wiersz], [si].[rowmodctr]FROM [sys].[sysindexes] [si]JOIN [sys] .[objects] [tak] ON [si].[id] =[tak].[object_id]GDZIE [tak].[name] ='PlayerPostSeason';
 Wiersze zmodyfikowane w widoku indeksowanym za pomocą sys.sysindexes
Wiersze zmodyfikowane w widoku indeksowanym za pomocą sys.sysindexes
Teraz sys.sysindexes jest przestarzały, ale jeśli pamiętasz z mojego poprzedniego postu, to właśnie tego używa sp_updatestats, aby zobaczyć, co zostało zmodyfikowane. Ale… lista obiektów dla sys.indexes jest sterowana przez zapytanie skierowane do sys.objects, które, jeśli pamiętasz, filtrują tabele użytkowników („U”) i tabele wewnętrzne („IT”). Nie obejmuje widoków („V”) w tym filtrze. W związku z tym, gdy uruchamiamy sp_updatestats i sprawdzamy dane wyjściowe (nieuwzględnione dla zwięzłości), nie ma wzmianki o naszym widoku PlayerPostSeason.
W związku z tym, jeśli masz zindeksowane widoki i polegasz na sp_updatestats w celu aktualizacji statystyk, statystyki widoków nie są aktualizowane. Domyślam się jednak, że większość z was ma włączoną opcję automatycznej aktualizacji statystyk dla swoich baz danych. To dobrze, ponieważ dzięki tej opcji statystyki widoku zostaną zaktualizowane, jeśli zostały unieważnione. Wiemy, że dokonaliśmy ponad 2000 modyfikacji indeksów na PlayerPostSeason. Jeśli zapytanie jest selektywne, nasz plan zapytań powinien korzystać z indeksu NCI_PlayerPostSeason_Name, a ponieważ statystyki są nieaktualne, powinny zostać zaktualizowane. Sprawdźmy:
SELECT *FROM [PlayerPostSeason]WHERE [nameFirst] ='Madison';GO
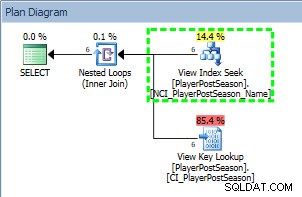 Plan zapytań z SELECT względem indeksu nieklastrowanego
Plan zapytań z SELECT względem indeksu nieklastrowanego
W planie widzimy, że użyto indeksu nieklastrowego NCI_PlayerPostSeason_Name, a jeśli sprawdzimy statystyki:
 Statystyki po automatycznej aktualizacji
Statystyki po automatycznej aktualizacji
Rzeczywiście, statystyki dla indeksu nieklastrowanego zostały zaktualizowane. Ale oczywiście nie chcemy polegać na automatycznej aktualizacji do zarządzania statystykami, chcemy być proaktywni. Mamy dwie opcje:
- Zadanie konserwacyjne
- Niestandardowy skrypt
Zadanie konserwacji statystyk aktualizacji zajmuje zaktualizuj statystyki widoku. Nie jest to specjalnie wywoływane w dowolnym miejscu interfejsu użytkownika, ale jeśli utworzymy plan konserwacji z zadaniem aktualizacji statystyk i uruchomimy go, statystyki dla indeksowanego widoku zostaną zaktualizowane. Wadą zadania konserwacji statystyk aktualizacji jest to, że jest to podejście młota kowalskiego. Aktualizuje wszystkie statystyki, niezależnie od tego, czy jest to potrzebne (jest prawie tak złe, jak sp_updatestats). Wolę niestandardowy skrypt, w którym SQL Server aktualizuje tylko to, co zostało zmodyfikowane. Jeśli nie lubisz kręcić własnego skryptu, możesz użyć skryptu Ola Hallengren. Często aktualizuje się statystyki w ramach przebudowy indeksu i reorganizacji. Na przykład ze skryptem Oli w zadaniu SQL Agent miałbyś:
sqlcmd -E -S $(ESCAPE_SQUOTE(SRVR)) -d master -Q "WYKONAJ [dbo].[IndexOptimize] @Databases ='BaseballData', @FragmentationLow =NULL, @FragmentationMedium ='INDEX_REORGANIZE', @FragmentationHigh ='ILDEX_ ', @FragmentationLevel1 =5, @FragmentationLevel2 =30, @UpdateStatistics ='WSZYSTKO', @OnlyModifiedStatistics ='T', @LogToTable ='T'" –bDzięki tej opcji, jeśli statystyki zostały zmodyfikowane, zostaną one zaktualizowane, a jeśli sprawdzimy procedurę składowaną [dbo].[IndexOptimize], możemy zobaczyć, gdzie Ola sprawdza modyfikacje:
-- Czy dane w statystykach zostały zmodyfikowane od ostatniej aktualizacji statystyk? IF @CurrentStatisticsID NIE JEST NULL I @UpdateStatistics NIE JEST NULL AND @OnlyModifiedStatistics ='Y' BEGIN SET @CurrentCommand10 ='' IF @LockTimeout NIE JEST NULL SET @CurrentCommand10 ='USTAW LOCK_TIMEOUT ' + CAST(@LockTimeout * 1000) + '; ' IF (@Version>=10.504000 AND @Version <11) LUB @Version>=11.03000 BEGIN SET @CurrentCommand10 =@CurrentCommand10 + 'USE ' + QUOTENAME(@CurrentDatabaseName) + '; Jeśli istnieje @CurrentDatabaseName) + '.sys.sysindexes sysindexes WHERE sysindexes.[id] =@ParamObjectID AND sysindexes.[indid] =@ParamStatisticsID AND sysindexes.[rowmodctr] <> 0) BEGIN SET @ParamStatisticsModified END =
W przypadku wersji, które obsługują DMF sys.dm_db_stats_properties, Ola sprawdza, czy nie zostały zmodyfikowane statystyki, a dla wersji, które nie obsługują nowego DMF sys.dm_db_stats_properties, sprawdzana jest tabela systemowa sys.sysindexes. Moją jedyną skargą jest to, że skrypt zachowuje się tak samo jak sp_updatestats:jeśli przynajmniej jeden wiersz został zmodyfikowany, statystyki zostaną zaktualizowane.
Jeśli nie lubisz pisać własnego kodu do zarządzania statystykami, polecam pozostać przy skrypcie Oli. Ale jeśli chcesz bardziej ukierunkować swoje aktualizacje, polecam użycie sys.dm_db_stats_properties. Ten DMF jest dostępny tylko dla SQL Server 2008R2 SP2 i nowszych oraz SQL Server 2012 SP1 i nowszych, więc jeśli korzystasz z niższej wersji, musisz użyć sys.indexes. Ale dla tych z was, którzy mają dostęp do sys.dm_db_stats_properties, oto zapytanie na początek:
SELECT [sch].[nazwa] AS [Schema], [tak].[nazwa] AS [NazwaObiektu], [tak].[typ] AS [TypObiektu], [ss].[nazwa] AS [Statystyka ], [sp].[last_updated] AS [StatsLastUpdated] , [sp].[rows] AS [RowsInTable] , [sp].[rows_sampled] AS [RowsSampled] , CAST(100 * [sp].[rows_sampled] / [sp].[wiersze] AS DECIMAL (18, 2)) AS [Próbka procentowa], [sp].[licznik_modyfikacji] AS [RowModifications] , CAST(100 * [sp].[licznik_modyfikacji] / [sp].[wiersze ] AS DECIMAL(18, 2)) AS [Zmiana procentowa] Z [sys].[obiektów] AS [tak]INNER JOIN [sys].[statystyki] AS [ss] ON [tak].[id_obiektu] =[ss] .[object_id]INNER JOIN [sys].[schemas] AS [sch] ON [so].[schema_id] =[sch].[schema_id]OUTER APPLY [sys].[dm_db_stats_properties]([so].[object_id] , [ss].[stats_id]) AS [sp]WHERE [tak].[type] IN ('U','V')AND ((CAST(100 * [sp].[licznik_modyfikacji] / [sp]. [wiersze] AS DECIMAL(18,2))>=10,0))ORDER BY CAST(100 * [sp].[licznik_modyfikacji] / [sp].[wiersze] AS DECIMAL(18, 2)) DESC; Zauważ, że za pomocą sys.objects filtrujemy według tabel i widoków; możesz to zmienić, aby uwzględnić tabele systemowe. Następnie można zmodyfikować predykat, aby pobierać tylko wiersze na podstawie procentu zmodyfikowanych wierszy lub kombinacji procentu modyfikacji i liczby wierszy (w przypadku tabel z milionami lub miliardami wierszy odsetek ten może być niższy niż w przypadku małych tabel).
Podsumowanie
Wiadomość, którą można zabrać do domu, jest dość jasna:nie polecam używania sp_updatestats do zarządzania statystykami. Statystyki są aktualizowane po zmianie co najmniej jednego wiersza (co jest bardzo niskim progiem aktualizacji statystyk), a statystyki widoków indeksowanych nie zaktualizowany. Nie jest to kompleksowa i wydajna metoda zarządzania statystykami… a zadanie aktualizacji statystyk w planie konserwacji nie jest dużo lepsze. Aktualizuje statystyki zindeksowanych widoków, ale aktualizuje co statystyki, niezależnie od modyfikacji. Niestandardowy skrypt jest naprawdę dobrą drogą, ale zrozum, że skrypt Ola Hallengren, jeśli aktualizujesz na podstawie modyfikacji, aktualizuje się również, gdy tylko wiersz został zmodyfikowany (ale przynajmniej otrzymuje zindeksowane widoki). Na koniec, aby uzyskać najlepszą kontrolę, spójrz na własny skrypt do zarządzania statystykami. Dałem ci podstawowe zapytanie na początek. Jeśli możesz zablokować kilka godzin na ćwiczenie pisania w T-SQL, a następnie je przetestować, będziesz mieć gotowy działający niestandardowy skrypt dla swoich baz danych, zanim nadejdą święta.



