
Gość autor:Derik Hammer (@SQLHammer)
Niedawno Aaron Bertrand pisał na blogu o szkodliwych, wszechobecnych mitach dotyczących wydajności SQL Server. Jako rozszerzenie tej serii blogów, obalę ten powszechny mit:
Czytanie instrukcji
Idąc prosto do źródła, spojrzałem na artykuł Books Online na temat tabel, który zawiera zmienne tabel. Mimo że artykuł odnosi się do korzyści płynących z używania zmiennych tabeli, wyraźnie brakuje faktu, że są one w 100% w pamięci.
Brak potwierdzenia nie oznacza jednak negatywu. Ponieważ tabele OLTP w pamięci zostały wydane, w BOL jest teraz znacznie więcej dokumentacji do przetwarzania w pamięci. Właśnie tam znalazłem ten artykuł na temat przyspieszania tabel tymczasowych i zmiennych tabel przy użyciu optymalizacji pamięci.
Cały artykuł kręci się wokół tego, jak sprawić, by tymczasowe obiekty korzystały z funkcji OLTP w pamięci i tutaj znalazłem odpowiedź, której szukałem.
„Tradycyjna zmienna tabeli reprezentuje tabelę w bazie danych tempdb. Aby uzyskać znacznie większą wydajność, zmienną tabeli można zoptymalizować pod kątem pamięci”.Zmienne tabel nie są konstrukcjami w pamięci. Aby użyć technologii w pamięci, musisz wyraźnie zdefiniować TYP, który jest zoptymalizowany pod kątem pamięci i użyć tego TYPU do zdefiniowania zmiennej tabeli.
Udowodnij to
Dokumentacja to jedno, ale zobaczenie jej na własne oczy to zupełnie co innego. Wiem, że tabele tymczasowe tworzą obiekty w tempdb i zapisują dane na dysku. Najpierw pokażę, jak to wygląda w przypadku tabel tymczasowych, a następnie użyję tej samej metody, aby zweryfikować hipotezę, że zmienne tabeli działają w ten sam sposób.
Analiza zapisów dziennika
To zapytanie uruchomi PUNKT KONTROLNY, aby dać mi czysty punkt początkowy, a następnie pokaże liczbę rekordów dziennika i nazwy transakcji, które istnieją w dzienniku.
USE tempdb; GO CHECKPOINT; GO SELECT COUNT(*) [Count] FROM sys.fn_dblog (NULL, NULL); SELECT [Transaction Name] FROM sys.fn_dblog (NULL, NULL) WHERE [Transaction Name] IS NOT NULL;
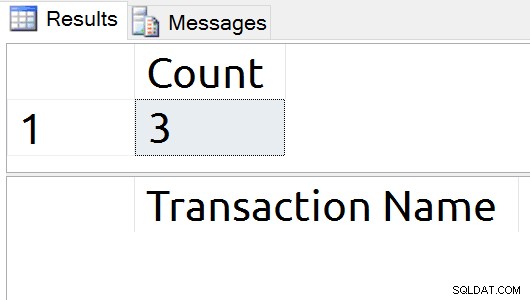
Częste uruchamianie T-SQL dało spójną liczbę trzech rekordów na SQL Server 2016 SP1.
Tworzy to tymczasową tabelę i wyświetla rekord obiektu, udowadniając, że jest to rzeczywisty obiekt w tempdb.
USE tempdb; GO DROP TABLE IF EXISTS #tmp; GO CREATE TABLE #tmp (id int NULL); SELECT name FROM sys.objects o WHERE is_ms_shipped = 0;

Teraz ponownie pokażę zapisy dziennika. Nie uruchomię ponownie polecenia CHECKPOINT.
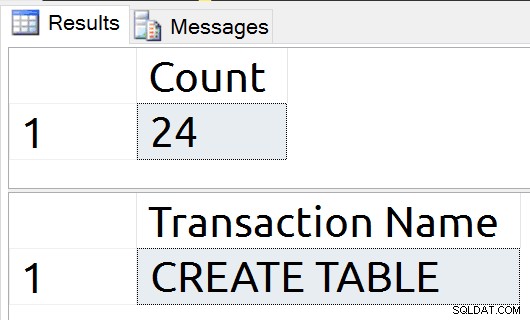
Zapisano dwadzieścia jeden rekordów dziennika, co dowodzi, że są to zapisy na dysku, a nasza CREATE TABLE jest wyraźnie uwzględniona w tych rekordach dziennika.
Aby porównać te wyniki ze zmiennymi tabeli, zresetuję eksperyment, uruchamiając CHECKPOINT, a następnie wykonując poniższy T-SQL, tworząc zmienną tabeli.
USE tempdb; GO DECLARE @var TABLE (id int NULL); SELECT name FROM sys.objects o WHERE is_ms_shipped = 0;
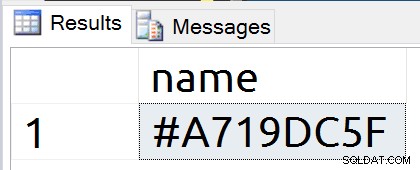
Po raz kolejny mamy nowy rekord obiektu. Tym razem jednak nazwa jest bardziej losowa niż w przypadku tabel tymczasowych.
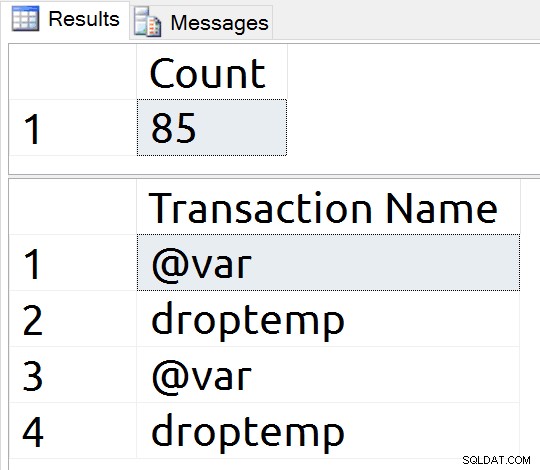
Jest osiemdziesiąt dwa nowe rekordy w dzienniku i nazwy transakcji, które potwierdzają, że moja zmienna jest zapisywana w dzienniku, a tym samym na dysku.
Właściwie w pamięci
Teraz nadszedł czas, aby zniknęły zapisy dziennika.
Utworzyłem grupę plików OLTP w pamięci, a następnie utworzyłem typ tabeli zoptymalizowany pod kątem pamięci.
USE Test; GO CREATE TYPE dbo.inMemoryTableType AS TABLE ( id INT NULL INDEX ix1 ) WITH (MEMORY_OPTIMIZED = ON); GO
Ponownie wykonałem punkt kontrolny, a następnie utworzyłem tabelę zoptymalizowaną pod kątem pamięci.
USE Test; GO DECLARE @var dbo.inMemoryTableType; INSERT INTO @var (id) VALUES (1) SELECT * from @var; GO
Po przejrzeniu dziennika nie zauważyłem żadnej aktywności w dzienniku. Ta metoda jest w rzeczywistości w 100% w pamięci.
Zabierz
Zmienne tabel używają bazy danych tempdb, podobnie jak tabele tymczasowe używają tempdb. Zmienne tabel nie są konstrukcjami w pamięci, ale mogą się nimi stać, jeśli używasz typów tabel zdefiniowanych przez użytkownika zoptymalizowanych pod kątem pamięci. Często uważam, że tabele tymczasowe są znacznie lepszym wyborem niż zmienne tabelowe. Głównym tego powodem jest to, że zmienne tabeli nie mają statystyk i, w zależności od wersji i ustawień programu SQL Server, oszacowania wierszy są oszacowane na 1 lub 100 wierszy. W obu przypadkach są to domysły i stają się szkodliwymi fragmentami dezinformacji w procesie optymalizacji zapytań.
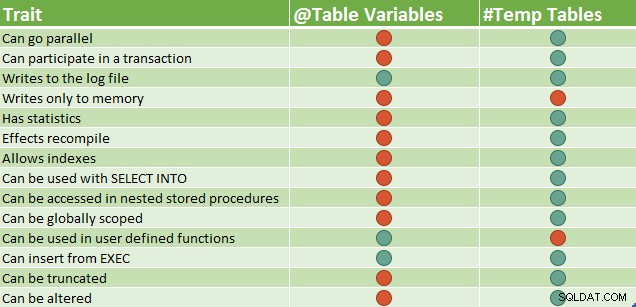
Należy zauważyć, że niektóre z tych różnic w funkcjach mogą się zmieniać w czasie — na przykład w najnowszych wersjach programu SQL Server można utworzyć dodatkowe indeksy w zmiennej tabeli przy użyciu składni indeksu wbudowanego. Poniższa tabela ma trzy indeksy; klucz podstawowy (domyślnie klastrowany) i dwa indeksy nieklastrowane:
DECLARE @t TABLE ( a int PRIMARY KEY, b int, INDEX x (b, a DESC), INDEX y (b DESC, a) );
Jest świetna odpowiedź na DBA Stack Exchange, gdzie Martin Smith szczegółowo opisuje różnice między zmiennymi tabel a tabelami #temp:
- Jaka jest różnica między tabelą tymczasową a zmienną tabeli w SQL Server?
O autorze
 Derik jest specjalistą od danych i świeżo upieczonym Microsoft Data Platform MVP, skupiającym się na SQL Server. Jego pasja skupia się wokół wysokiej dostępności, odzyskiwania po awarii, ciągłej integracji i automatycznej konserwacji. Jego doświadczenie obejmuje wieloletnie administrowanie bazami danych, doradztwo oraz przedsięwzięcia przedsiębiorcze w branży finansowej i opieki zdrowotnej. Obecnie jest starszym administratorem baz danych odpowiedzialnym za zespół ds. operacji baz danych w głównej siedzibie Subway Franchise World. Kiedy nie pracuje ani nie prowadzi bloga na SQLHammer.com, Derik poświęca swój czas rodzinie #sql jako lider grupy użytkowników FairfieldPASS SQL Server w Stamford w stanie Connecticut.
Derik jest specjalistą od danych i świeżo upieczonym Microsoft Data Platform MVP, skupiającym się na SQL Server. Jego pasja skupia się wokół wysokiej dostępności, odzyskiwania po awarii, ciągłej integracji i automatycznej konserwacji. Jego doświadczenie obejmuje wieloletnie administrowanie bazami danych, doradztwo oraz przedsięwzięcia przedsiębiorcze w branży finansowej i opieki zdrowotnej. Obecnie jest starszym administratorem baz danych odpowiedzialnym za zespół ds. operacji baz danych w głównej siedzibie Subway Franchise World. Kiedy nie pracuje ani nie prowadzi bloga na SQLHammer.com, Derik poświęca swój czas rodzinie #sql jako lider grupy użytkowników FairfieldPASS SQL Server w Stamford w stanie Connecticut. 


