SQL Server 2014 przyniósł wiele nowych funkcji, które administratorzy baz danych i programiści chcieli przetestować i używać w swoich środowiskach, takich jak aktualizowalny klastrowany indeks magazynu kolumn, opóźniona trwałość i rozszerzenia puli buforów. Nieczęsto omawianą funkcją są statystyki przyrostowe. Jeśli nie używasz partycjonowania, nie jest to funkcja, którą możesz zaimplementować. Ale jeśli masz podzielone na partycje tabele w swojej bazie danych, przyrostowe statystyki mogły być czymś, czego niecierpliwie oczekiwałeś.
Uwaga:Benjamin Nevarez omówił pewne podstawy związane ze statystykami przyrostowymi w swoim poście z lutego 2014 r., Statystyka przyrostowa SQL Server 2014. I chociaż niewiele zmieniło się w sposobie działania tej funkcji od czasu jego posta i wydania z kwietnia 2014 r., wydawało się, że to dobry moment, aby zastanowić się, w jaki sposób włączenie przyrostowych statystyk może pomóc w wydajności konserwacji.
Statystyki przyrostowe są czasami nazywane statystykami na poziomie partycji, a to dlatego, że po raz pierwszy SQL Server może automatycznie tworzyć statystyki specyficzne dla partycji. Jednym z poprzednich wyzwań związanych z partycjonowaniem było to, że można było mieć 1 do n partycji dla tabeli, była tylko jedna (1) statystyka, która reprezentowała rozkład danych we wszystkich tych partycjach. Można utworzyć filtrowane statystyki dla tabeli partycjonowanej — jedną statystykę dla każdej partycji — aby zapewnić optymalizatorowi zapytań lepsze informacje o dystrybucji danych. Ale był to proces ręczny i wymagał skryptu do automatycznego tworzenia ich dla każdej nowej partycji.
W SQL Server 2014 używasz STATISTICS_INCREMENTAL opcja, aby SQL Server automatycznie tworzył te statystyki na poziomie partycji. Jednak te statystyki nie są używane, jak mogłoby się wydawać.
Wspomniałem wcześniej, że przed rokiem 2014 można było tworzyć filtrowane statystyki, aby zapewnić optymalizatorowi lepsze informacje o partycjach. Te przyrostowe statystyki? Nie są obecnie używane przez optymalizator. Optymalizator zapytań nadal używa tylko głównego histogramu, który reprezentuje całą tabelę. (Następny post, który to zademonstruje!)
Jaki jest więc sens przyrostowych statystyk? Jeśli założysz, że zmieniają się tylko dane na najnowszej partycji, najlepiej aktualizować statystyki tylko dla tej partycji. Możesz to zrobić teraz za pomocą przyrostowych statystyk – a to, co się dzieje, to fakt, że informacje są następnie scalane z powrotem do głównego histogramu. Histogram dla całej tabeli zostanie zaktualizowany bez konieczności czytania całej tabeli w celu aktualizacji statystyk, co może pomóc w wykonywaniu zadań konserwacyjnych.
Konfiguracja
Zaczniemy od utworzenia funkcji i schematu partycjonowania, a następnie nowej tabeli, którą podzielimy. Zauważ, że utworzyłem grupę plików dla każdej funkcji partycji, tak jak w środowisku produkcyjnym. Możesz utworzyć schemat partycji na tej samej grupie plików (np. PRIMARY ), jeśli nie możesz łatwo usunąć testowej bazy danych. Każda grupa plików ma również rozmiar kilku GB, ponieważ dodamy prawie 400 milionów wierszy.
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 1024MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; /* create partition function */ CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', -- everything in 2011 '20120101', -- everything in 2012 '20130101', -- everything in 2013 '20140101', -- everything in 2014 '20150101' -- everything in 2015 ); GO /* create partition scheme */ CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO /* create the table */ CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Zanim dodamy dane, utworzymy indeks klastrowy i zauważmy, że składnia zawiera WITH (STATISTICS_INCREMENTAL = ON) opcja:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) WITH (STATISTICS_INCREMENTAL = ON) ON [OrderDateRangePScheme] ([OrderDate]);
Warto zauważyć, że jeśli spojrzysz na ALTER TABLE wpis w MSDN, nie zawiera tej opcji. Znajdziesz go tylko w ALTER INDEX wpis… ale to działa. Jeśli chcesz postępować zgodnie z dokumentacją co do joty, możesz uruchomić:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) ON [OrderDateRangePScheme] ([OrderDate]); GO ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON);
Po utworzeniu indeksu klastrowego dla schematu partycji załadujemy nasze dane, a następnie sprawdzimy, ile wierszy istnieje na partycję (pamiętaj, że zajmuje to ponad 7 minut na moim laptopie możesz dodać mniej wierszy w zależności od ilości dostępnego miejsca (i czasu):
/* load some data */
SET NOCOUNT ON;
DECLARE @Loops SMALLINT = 0;
DECLARE @Increment INT = 5000;
WHILE @Loops < 10000 -- adjust this to increase or decrease the number
-- of rows in the table, 10000 = 40 millon rows
BEGIN
INSERT [dbo].[Orders]
( [PurchaseOrderID]
,[EmployeeID]
,[VendorID]
,[TaxAmt]
,[Freight]
,[SubTotal]
,[Status]
,[RevisionNumber]
,[ModifiedDate]
,[ShipMethodID]
,[ShipDate]
,[OrderDate]
,[TotalDue]
)
SELECT
[PurchaseOrderID] + @Increment
, [EmployeeID]
, [VendorID]
, [TaxAmt]
, [Freight]
, [SubTotal]
, [Status]
, [RevisionNumber]
, [ModifiedDate]
, [ShipMethodID]
, [ShipDate]
, [OrderDate]
, [TotalDue]
FROM [Purchasing].[PurchaseOrderHeader];
CHECKPOINT;
SET @Loops = @Loops + 1;
SET @Increment = @Increment + 5000;
END
/* Check to see how much data exists per partition */
SELECT
$PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number]
, MIN([o].[OrderDate]) AS [Min_Order_Date]
, MAX([o].[OrderDate]) AS [Max_Order_Date]
, COUNT(*) AS [Rows In Partition]
FROM [dbo].[Orders] AS [o]
GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate])
ORDER BY [Partition Number];
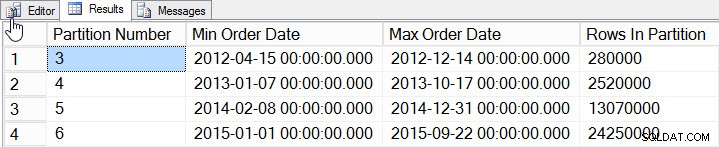 Dane na partycję
Dane na partycję
Dodaliśmy dane za lata 2012-2015, ze znacznie większą liczbą danych w latach 2014 i 2015. Zobaczmy, jak wyglądają nasze statystyki:
DBCC SHOW_STATISTICS ('dbo.Orders',[OrdersPK]);
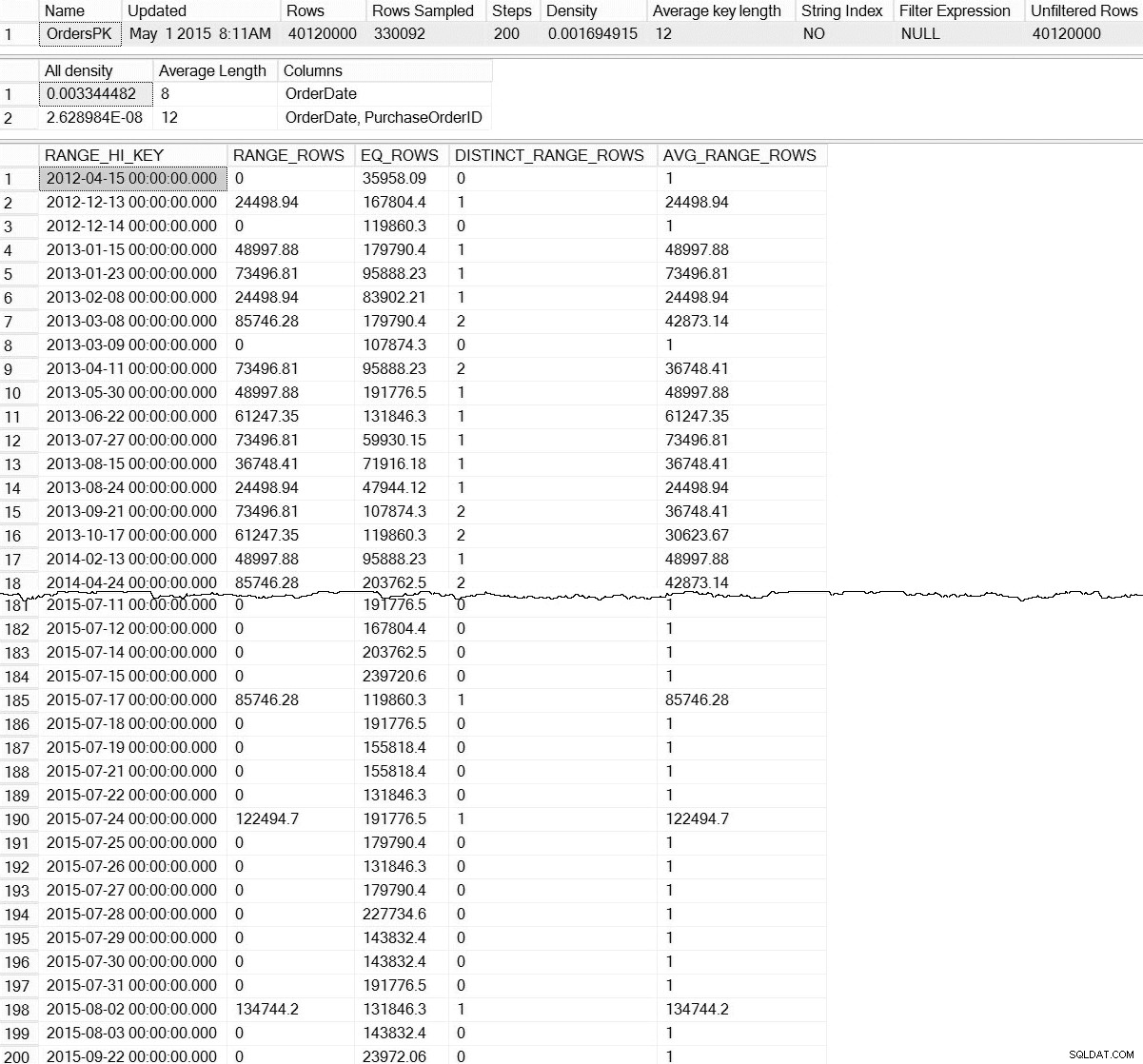 DBCC SHOW_STATISTICS dane wyjściowe dla dbo.Orders (kliknij, aby powiększyć)
DBCC SHOW_STATISTICS dane wyjściowe dla dbo.Orders (kliknij, aby powiększyć)
Z domyślnym DBCC SHOW_STATISTICS polecenie, nie mamy żadnych informacji o statystykach na poziomie partycji. Nie bój się; nie jesteśmy całkowicie skazani – istnieje nieudokumentowana funkcja dynamicznego zarządzania, sys.dm_db_stats_properties_internal . Pamiętaj, że nieudokumentowany oznacza, że nie jest obsługiwany (nie ma wpisu MSDN dla DMF) i że może się zmienić w dowolnym momencie bez żadnego ostrzeżenia ze strony Microsoft. To powiedziawszy, to dobry początek, aby zorientować się, co istnieje dla naszych przyrostowych statystyk:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 Informacje o histogramie z dm_db_stats_properties_internal (kliknij, aby powiększyć)
Informacje o histogramie z dm_db_stats_properties_internal (kliknij, aby powiększyć)
To o wiele ciekawsze. Tutaj widzimy dowód na istnienie statystyk na poziomie partycji (i nie tylko). Ponieważ ten DKZ nie jest udokumentowany, musimy dokonać pewnej interpretacji. Na dziś skupimy się na pierwszych siedmiu wierszach w danych wyjściowych, gdzie pierwszy wiersz reprezentuje histogram dla całej tabeli (zwróć uwagę na rows wartości 40 mln), a kolejne wiersze przedstawiają histogramy dla każdej partycji. Niestety, partition_number wartość w tym histogramie nie zgadza się z numerem partycji z sys.dm_db_index_physical_stats dla partycjonowania prawostronnego (poprawnie koreluje dla partycjonowania lewostronnego). Zauważ również, że to wyjście zawiera również last_updated i modification_counter kolumn, które są pomocne podczas rozwiązywania problemów i mogą być używane do tworzenia skryptów konserwacyjnych, które inteligentnie aktualizują statystyki na podstawie wieku lub modyfikacji wierszy.
Wymagana minimalizacja konserwacji
Podstawową wartością statystyk przyrostowych w tej chwili jest możliwość aktualizowania statystyk partycji i łączenia ich w histogram na poziomie tabeli bez konieczności aktualizowania statystyk dla całej tabeli (a zatem czytania całej tabeli). Aby zobaczyć to w akcji, najpierw zaktualizujmy statystyki dla partycji, która przechowuje dane z 2015 r., partycji 5, a my zarejestrujemy poświęcony czas i zrobimy zrzut sys.dm_io_virtual_file_stats DMF przed i po, aby zobaczyć, ile występuje I/O:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH RESAMPLE ON PARTITIONS(6); GO SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture AS f INNER JOIN #SecondCapture AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Wyjście:
Czasy wykonania programu SQL Server:czas procesora =203 ms, czas, który upłynął =240 ms.
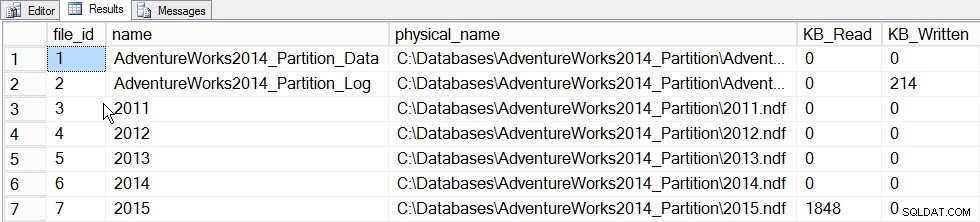 Dane File_stats po aktualizacji jednej partycji
Dane File_stats po aktualizacji jednej partycji
Jeśli spojrzymy na sys.dm_db_stats_properties_internal wyjście, widzimy, że last_updated zmieniono zarówno dla histogramu 2015, jak i histogramu na poziomie tabeli (a także kilku innych węzłów, które są do późniejszego zbadania):
 Zaktualizowane informacje o histogramie z dm_db_stats_properties_internal
Zaktualizowane informacje o histogramie z dm_db_stats_properties_internal
Teraz zaktualizujemy statystyki za pomocą FULLSCAN dla tabeli, a zrobimy migawkę file_stats przed i po:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH FULLSCAN SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture2 AS f INNER JOIN #SecondCapture2 AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Wyjście:
Czasy wykonywania programu SQL Server:czas procesora =12720 ms, czas, który upłynął =13646 ms
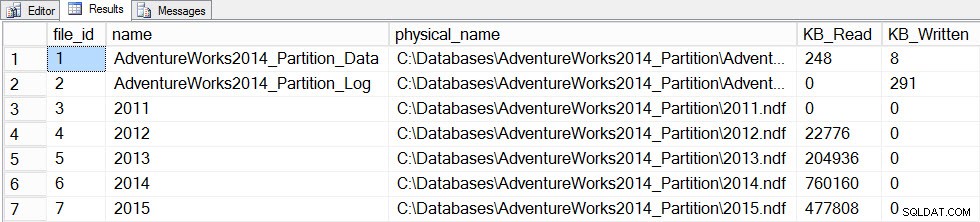 Dane statystyki plików po aktualizacji za pomocą pełnego skanowania
Dane statystyki plików po aktualizacji za pomocą pełnego skanowania
Aktualizacja trwała znacznie dłużej (13 sekund w porównaniu do kilkuset milisekund) i generowała znacznie więcej operacji we/wy. Jeśli sprawdzimy sys.dm_db_stats_properties_internal ponownie stwierdzamy, że last_updated zmieniono dla wszystkich histogramów:
 Informacje o histogramie z dm_db_stats_properties_internal po pełnym skanowaniu
Informacje o histogramie z dm_db_stats_properties_internal po pełnym skanowaniu
Podsumowanie
Chociaż statystyki przyrostowe nie są jeszcze używane przez optymalizator kwerend w celu dostarczania informacji o każdej partycji, zapewniają one zwiększenie wydajności podczas zarządzania statystykami dla tabel partycjonowanych. Jeśli statystyki wymagają aktualizacji tylko dla wybranych partycji, tylko te mogą zostać zaktualizowane. Nowe informacje są następnie scalane z histogramem na poziomie tabeli, zapewniając optymalizatorowi bardziej aktualne informacje, bez kosztów odczytywania całej tabeli. Idąc dalej, mamy nadzieję, że te statystyki na poziomie partycji będzie być używane przez optymalizator. Bądź na bieżąco…