W moim poprzednim poście na temat statystyk przyrostowych, nowej funkcji w SQL Server 2014, pokazałem, w jaki sposób mogą one pomóc w skróceniu czasu trwania zadań konserwacyjnych. Dzieje się tak, ponieważ statystyki można aktualizować na poziomie partycji, a zmiany są scalane z głównym histogramem tabeli. Zauważyłem również, że Optymalizator zapytań nie używa tych statystyk na poziomie partycji podczas generowania planów zapytań, co może być czymś, czego ludzie oczekiwali. Nie istnieje żadna dokumentacja stwierdzająca, że przyrostowe statystyki będą lub nie będą używane przez Optymalizator zapytań. Więc skąd wiesz? Musisz to przetestować. :-)
Konfiguracja
Konfiguracja tego testu będzie podobna do tej w poprzednim poście, ale z mniejszą ilością danych. Zwróć uwagę, że domyślne rozmiary plików danych są mniejsze, a skrypt ładuje się tylko w kilku milionach wierszy danych:
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', --everything in 2011 '20120101', --everything in 2012 '20130101', --everything in 2013 '20140101', --everything in 2014 '20150101' --everything in 2015 ); GO CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Kiedy tworzymy indeks klastrowy dla dbo.Orders, utworzymy go bez STATISTICS_INCREMENTAL opcja włączona, więc zaczniemy od tradycyjnej tabeli podzielonej na partycje bez przyrostowych statystyk:
ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ([OrderDate], [PurchaseOrderID]) ON [OrderDateRangePScheme] ([OrderDate]);
Następnie załadujemy około 4 miliony wierszy, co na moim komputerze zajmuje niecałą minutę:
SET NOCOUNT ON; DECLARE @Loops SMALLINT = 0; DECLARE @Increment INT = 3000; WHILE @Loops < 1000 BEGIN INSERT [dbo].[Orders] ([PurchaseOrderID] ,[EmployeeID] ,[VendorID] ,[TaxAmt] ,[Freight] ,[SubTotal] ,[Status] ,[RevisionNumber] ,[ModifiedDate] ,[ShipMethodID] ,[ShipDate] ,[OrderDate] ,[TotalDue] ) SELECT [PurchaseOrderID] + @Increment , [EmployeeID] , [VendorID] , [TaxAmt] , [Freight] , [SubTotal] , [Status] , [RevisionNumber] , [ModifiedDate] , [ShipMethodID] , DATEADD(DAY, 365, [ShipDate]) , DATEADD(DAY, 365, [OrderDate]) , [TotalDue] + 365 FROM [Purchasing].[PurchaseOrderHeader]; CHECKPOINT; SET @Loops = @Loops + 1; SET @Increment = @Increment + 5000; END
Po załadowaniu danych zaktualizujemy statystyki za pomocą FULLSCAN (abyśmy mogli utworzyć możliwie spójny histogram do testów), a następnie zweryfikujemy, jakie dane mamy w każdej partycji:
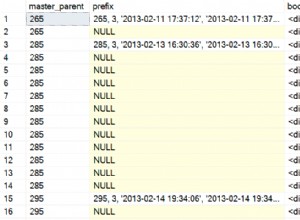
UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN; SELECT $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number] , MIN([o].[OrderDate]) AS [Min_Order_Date] , MAX([o].[OrderDate]) AS [Max_Order_Date] , COUNT(*) AS [Rows_In_Partition] FROM [dbo].[Orders] AS [o] GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) ORDER BY [Partition Number];
 Dane w każdej partycji po załadowaniu danych
Dane w każdej partycji po załadowaniu danych
Większość danych znajduje się na partycji 2015, ale są też dane z lat 2012, 2013 i 2014. A jeśli sprawdzimy dane wyjściowe z nieudokumentowanego DMV sys.dm_db_stats_properties_internal , widzimy, że nie istnieją żadne statystyki na poziomie partycji:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 sys.dm_db_stats_properties_internal dane wyjściowe pokazujące tylko jedną statystykę dla dbo.Orders
sys.dm_db_stats_properties_internal dane wyjściowe pokazujące tylko jedną statystykę dla dbo.Orders
Test
Testowanie wymaga prostego zapytania, którego możemy użyć do sprawdzenia, czy nastąpiła eliminacja partycji, a także do sprawdzenia szacunków na podstawie statystyk. Zapytanie nie zwraca żadnych danych, ale to nie ma znaczenia, interesuje nas, co myśli optymalizator zwróciłby, na podstawie statystyk:
SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
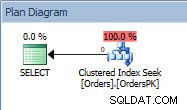 Plan zapytań dla instrukcji SELECT
Plan zapytań dla instrukcji SELECT
Plan ma Clustered Index Seek, a jeśli sprawdzimy właściwości, zobaczymy, że oszacował 4000 wierszy i uzyskał dostęp do partycji 5, która zawiera dane z 2014 roku.
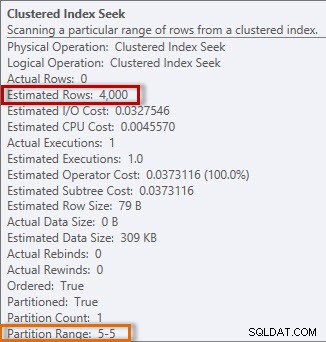 Szacunkowe i aktualne informacje z Clustered Index Seek
Szacunkowe i aktualne informacje z Clustered Index Seek
Jeśli spojrzymy na histogram dla tabeli dbo.Orders, konkretnie w obszarze danych z kwietnia 2014 r., widzimy, że nie ma kroku dla 01.04.2014, więc optymalizator szacuje liczbę wierszy dla tej daty za pomocą kroku dla 2014-04-24, gdzie AVG_RANGE_ROWS wynosi 4000 (dla dowolnej wartości między 2014-02-14 a 2014-04-23 włącznie, optymalizator oszacuje, że zostanie zwróconych 4000 wierszy).
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
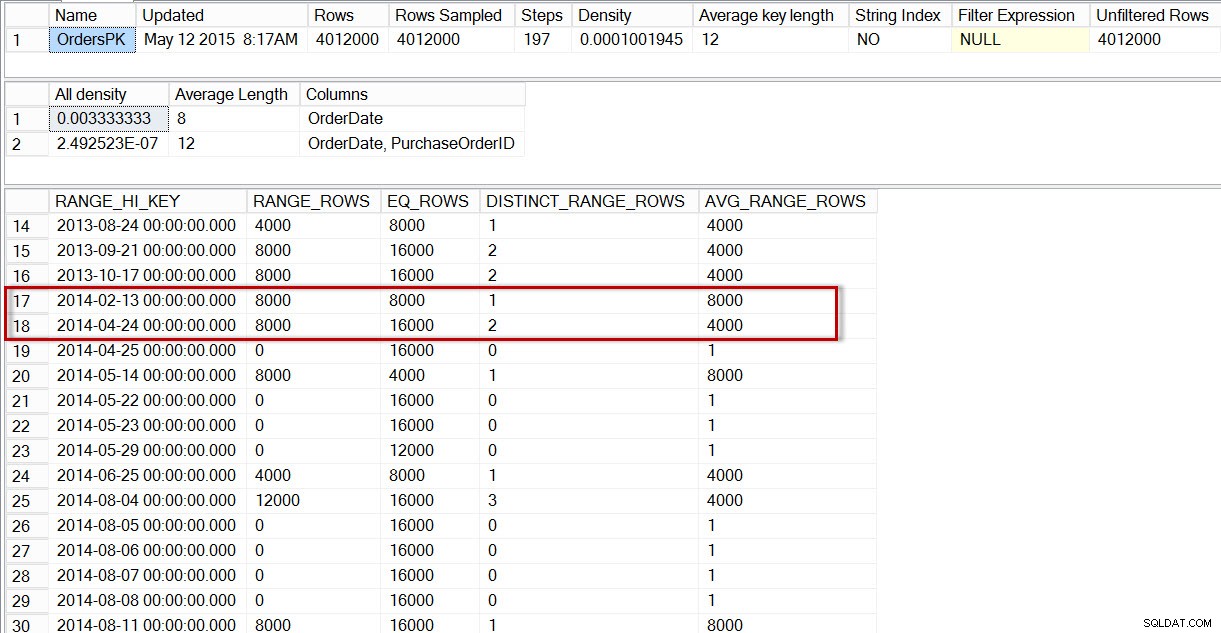 Dystrybucja w histogramie dbo.Orders
Dystrybucja w histogramie dbo.Orders
Kosztorys i plan są całkowicie oczekiwane. Włączmy przyrostowe statystyki i zobaczmy, co otrzymamy.
ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON); GO UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN;
Jeśli ponownie uruchomimy nasze zapytanie względem sys.dm_db_stats_properties_internal , widzimy przyrostowe statystyki:
 sys.dm_db_stats_properties_internal pokazujący informacje o przyrostowych statystykach
sys.dm_db_stats_properties_internal pokazujący informacje o przyrostowych statystykach
Teraz ponownie uruchommy nasze zapytanie dbo.Orders i uruchomimy DBCC FREEPROCCACHE po pierwsze, aby w pełni upewnić się, że plan nie zostanie ponownie wykorzystany:
DBCC FREEPROCCACHE; GO SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
Otrzymujemy ten sam plan i tę samą wycenę:
Plan zapytań dla instrukcji SELECT
Szacunkowe i aktualne informacje z Clustered Index Seek
Jeśli sprawdzimy główny histogram dla dbo.Orders, zobaczymy prawie ten sam histogram co poprzednio:
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
 Histogram dla dbo.Orders, po włączeniu statystyk przyrostowych
Histogram dla dbo.Orders, po włączeniu statystyk przyrostowych
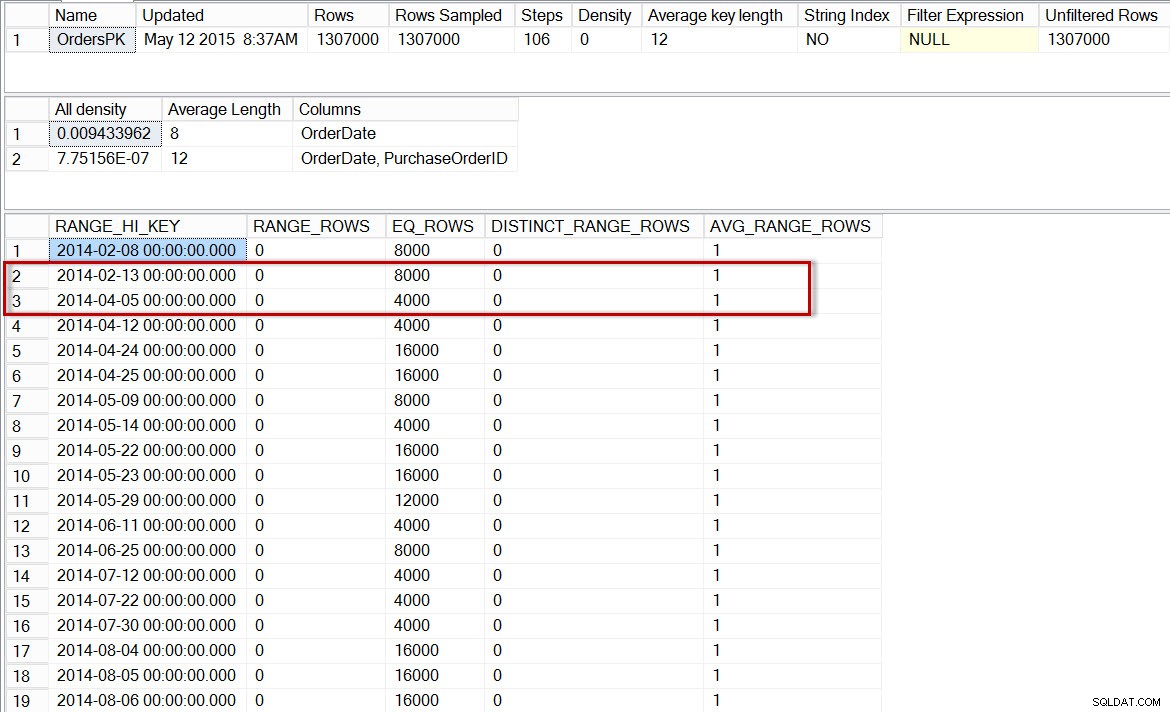
Sprawdźmy teraz histogram partycji z danymi 2014 (możemy to zrobić za pomocą nieudokumentowanej flagi śledzenia 2309, która pozwala na określenie numeru partycji jako dodatkowego argumentu do DBCC SHOW_STATISTICS ):
DBCC TRACEON(2309);
GO
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK', 6);
Histogram dla partycji dbo.Orders z 2014 r. po włączeniu statystyk przyrostowych
Tutaj widzimy, że znowu nie ma kroku dla 2014-04-01, ale jest 0 RANGE_ROWS między 2014-02-13 a 2014-04-05, z AVG_RANGE_ROWS z 1. Jeśli optymalizator używał histogramu do statystyk poziomu partycji, szacunkowa liczba wierszy dla 2014-04-01 wyniosłaby 1.
Uwaga:partycja zidentyfikowana jako używana w planie zapytania to 5, ale zauważysz, że DBCC SHOW_STATISTICS instrukcja odwołuje się do partycji 6. Założeniem jest niespójność metadanych statystycznych (częsty błąd typu „off-by-one”, prawdopodobnie spowodowany liczeniem od 0 do 1), która może, ale nie musi, zostać naprawiona w przyszłości. Zrozum, że flaga śledzenia nie jest obecnie udokumentowana i nie zaleca się jej używania w środowisku produkcyjnym.
Podsumowanie
Dodanie przyrostowych statystyk w wersji SQL Server 2014 jest krokiem we właściwym kierunku w celu poprawy oszacowań liczności dla tabel partycjonowanych. Jednak, jak wykazaliśmy, bieżąca wartość statystyk przyrostowych jest ograniczona do skróconego czasu trwania konserwacji, ponieważ te przyrostowe statystyki nie są jeszcze używane przez Optymalizator zapytań.