Typ i liczba blokad nabytych i zwolnionych podczas wykonywania zapytania może mieć zaskakujący wpływ na wydajność (przy użyciu poziomu izolacji blokowania, takiego jak domyślny zatwierdzony odczyt), nawet jeśli nie występuje oczekiwanie ani blokowanie. W planach wykonania nie ma informacji wskazujących ilość aktywności blokującej podczas wykonywania, co utrudnia wykrycie, kiedy nadmierne blokowanie powoduje problem z wydajnością.
Aby zbadać niektóre mniej znane zachowania blokowania w SQL Server, ponownie wykorzystam zapytania i przykładowe dane z mojego ostatniego postu na temat obliczania median. W tym poście wspomniałem, że OFFSET zgrupowane rozwiązanie mediany wymagało jawnego PAGLOCK wskazówka dotycząca blokowania, aby uniknąć poważnych strat z zagnieżdżonym kursorem rozwiązanie, więc zacznijmy od szczegółowego przyjrzenia się przyczynom takiego stanu rzeczy.
Rozwiązanie z grupowaną medianą PRZESUNIĘCIA
Pogrupowany test mediany ponownie wykorzystał przykładowe dane z wcześniejszego artykułu Aarona Bertranda. Poniższy skrypt odtwarza tę konfigurację z milionem wierszy, składającą się z dziesięciu tysięcy rekordów dla każdego ze stu wyimaginowanych sprzedawców:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
SQL Server 2012 (i nowsze) OFFSET rozwiązanie stworzone przez Petera Larssona jest następujące (bez żadnych wskazówek dotyczących blokowania):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Poniżej przedstawiono ważne części planu egzekucyjnego:

Gdy wszystkie wymagane dane znajdują się w pamięci, to zapytanie zostanie wykonane w ciągu 580 ms średnio na moim laptopie (z SQL Server 2014 Service Pack 1). Wydajność tego zapytania można poprawić do 320 ms po prostu dodając wskazówkę dotyczącą blokowania szczegółowości strony do tabeli Sprzedaż w podzapytaniu Apply:
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK) -- NEW!
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Plan wykonania pozostaje niezmieniony (no cóż, oczywiście poza tekstem wskazówki dotyczącej blokowania w showplan XML):
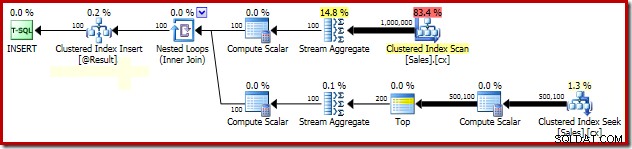
Zgrupowana analiza blokowania mediany
Wyjaśnienie radykalnej poprawy wydajności dzięki PAGLOCK wskazówka jest dość prosta, przynajmniej na początku.
Jeśli ręcznie monitorujemy aktywność blokowania podczas wykonywania tego zapytania, widzimy, że bez wskazówki dotyczącej szczegółowości blokowania strony, SQL Server uzyskuje i zwalnia ponad pół miliona blokad na poziomie wierszy podczas wyszukiwania indeksu klastrowego. Nie można winić blokowania; samo pozyskiwanie i zwalnianie tak wielu blokad znacznie obciąża wykonanie tego zapytania. Żądanie blokad na poziomie strony znacznie zmniejsza aktywność blokowania, co skutkuje znacznie lepszą wydajnością.
Problem z wydajnością blokowania tego konkretnego planu jest ograniczony do wyszukiwania indeksu klastrowego w powyższym planie. Pełne skanowanie indeksu klastrowego (używanego do obliczenia liczby wierszy obecnych dla każdego sprzedawcy) automatycznie używa blokad na poziomie strony. To interesujący punkt. Szczegółowe zachowanie silnika SQL Server w zakresie blokowania nie jest w dużym stopniu udokumentowane w Books Online, ale różni członkowie zespołu SQL Server na przestrzeni lat poczynili kilka ogólnych uwag, w tym fakt, że nieograniczone skanowanie zwykle zaczyna się od strony blokady, podczas gdy mniejsze operacje zwykle zaczynają się od blokad rzędów.
Optymalizator zapytań udostępnia niektóre informacje do aparatu magazynu, w tym oszacowania kardynalności, wewnętrzne wskazówki dotyczące poziomu izolacji i granulacji blokowania, które optymalizacje wewnętrzne można bezpiecznie zastosować i tak dalej. Znowu te szczegóły nie są udokumentowane w Books Online. Ostatecznie silnik pamięci masowej korzysta z różnych informacji, aby zdecydować, które blokady są wymagane w czasie wykonywania i na jakim poziomie szczegółowości należy je zastosować.
Na marginesie i pamiętając, że mówimy o zapytaniu wykonywanym na domyślnym poziomie izolacji transakcji odczytu popełnionej blokady, zauważ, że blokady wierszy podjęte bez wskazówki dotyczącej szczegółowości nie będą w tym przypadku eskalować do blokady tabeli. Dzieje się tak, ponieważ normalne zachowanie w przypadku zatwierdzenia odczytu polega na zwolnieniu poprzedniej blokady tuż przed uzyskaniem kolejnej blokady, co oznacza, że w danym momencie będzie utrzymywana tylko jedna blokada współdzielonego wiersza (z powiązanymi blokadami współużytkowanymi na wyższym poziomie). Ponieważ liczba jednocześnie utrzymywanych blokad wierszy nigdy nie osiąga progu, nie jest podejmowana żadna eskalacja blokad.
Rozwiązanie z pojedynczą medianą OFFSET
Test wydajności dla obliczenia pojedynczej mediany wykorzystuje inny zestaw danych przykładowych, ponownie odtworzony z wcześniejszego artykułu Aarona. Poniższy skrypt tworzy tabelę z dziesięcioma milionami wierszy pseudolosowych danych:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
OFFSET rozwiązanie to:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Plan powykonawczy to:

To zapytanie jest wykonywane w 910 ms średnio na mojej maszynie testowej. Wydajność pozostaje niezmieniona, jeśli PAGLOCK dodana jest wskazówka, ale powodem tego nie jest to, o czym myślisz…
Analiza pojedynczego blokowania mediany
Możesz oczekiwać, że silnik pamięci i tak wybierze współdzielone blokady na poziomie strony, ze względu na skanowanie indeksu klastrowego, wyjaśniając, dlaczego PAGLOCK podpowiedź nie ma żadnego efektu. W rzeczywistości monitorowanie blokad podejmowanych podczas wykonywania tego zapytania ujawnia, że w ogóle nie są stosowane żadne blokady współdzielone (S), na dowolnym poziomie szczegółowości . Jedyne podejmowane blokady to współdzielone intencje (IS) na poziomie obiektu i strony.
Wyjaśnienie tego zachowania składa się z dwóch części. Pierwszą rzeczą, którą należy zauważyć, jest to, że Clustered Index Scan znajduje się poniżej operatora Top w planie wykonania. Ma to istotny wpływ na szacunki liczności, jak pokazano w (szacunkowym) planie przedwykonawczym:

OFFSET i FETCH klauzule w zapytaniu odwołują się do wyrażenia i zmiennej, więc optymalizator zapytań odgaduje liczbę wierszy, które będą potrzebne w czasie wykonywania. Standardowe przypuszczenie dla Top to sto wierszy. To oczywiście okropne przypuszczenie, ale wystarczy przekonać silnik pamięci, aby blokował szczegółowość wierszy zamiast na poziomie strony.
Jeśli wyłączymy efekt „celu wiersza” operatora Top przy użyciu udokumentowanej flagi śledzenia 4138, szacowana liczba wierszy podczas skanowania zmieni się na dziesięć milionów (co nadal jest błędne, ale w innym kierunku). To wystarczy, aby zmienić decyzję o szczegółowości blokowania mechanizmu pamięci masowej, tak aby były podejmowane współdzielone blokady na poziomie strony (uwaga, nie współdzielone przez intencję):
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1
OPTION (QUERYTRACEON 4138); -- NEW!
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Szacunkowy plan wykonania sporządzony pod flagą śledzenia 4138 to:

Wracając do głównego przykładu, oszacowanie stu wierszy ze względu na odgadnięty cel wiersza oznacza, że aparat magazynu wybiera blokadę na poziomie wiersza. Jednak obserwujemy tylko blokady intencji (IS) na poziomie tabeli i strony. Te blokady wyższego poziomu byłyby całkiem normalne, gdybyśmy widzieli blokady współdzielone (S) na poziomie wiersza, więc gdzie one się podziały?
Odpowiedź brzmi, że aparat pamięci zawiera inną optymalizację, która w pewnych okolicznościach może pominąć blokady współdzielone na poziomie wiersza. Po zastosowaniu tej optymalizacji nadal nabywane są blokady wyższego poziomu ze współdzieleniem intencji.
Podsumowując, dla zapytania z jedną medianą:
- Użycie zmiennej i wyrażenia w
OFFSETklauzula oznacza, że optymalizator odgaduje liczność. - Niskie oszacowanie oznacza, że aparat pamięci masowej decyduje o strategii blokowania na poziomie wiersza.
- Wewnętrzna optymalizacja oznacza, że blokady S na poziomie wiersza są pomijane w czasie wykonywania, pozostawiając tylko blokady IS na poziomie strony i obiektu.
Zapytanie z pojedynczym medianą miałoby ten sam problem z wydajnością blokowania wierszy, co mediana zgrupowana (ze względu na niedokładne oszacowanie optymalizatora zapytań), ale zostało zapisane przez oddzielną optymalizację silnika pamięci masowej, która spowodowała zablokowanie tylko stron i tabel ze współużytkowaniem intencji w czasie wykonywania.
Ponowny test grupowej mediany
Być może zastanawiasz się, dlaczego wyszukiwanie indeksu klastrowego w zgrupowanym teście mediany nie korzystało z tej samej optymalizacji aparatu pamięci masowej w celu pominięcia blokad współdzielonych na poziomie wiersza. Dlaczego użyto tak wielu wspólnych blokad wierszy, dzięki czemu PAGLOCK wskazówka jest konieczna?
Krótka odpowiedź brzmi, że ta optymalizacja nie jest dostępna dla INSERT...SELECT zapytania. Jeśli uruchomimy SELECT samodzielnie (tzn. bez zapisywania wyników do tabeli) i bez PAGLOCK wskazówka, optymalizacja blokowania wierszy z pomijaniem jest zastosowano:
DECLARE @s datetime2 = SYSUTCDATETIME();
--DECLARE @Result AS table
--(
-- SalesPerson integer PRIMARY KEY,
-- Median float NOT NULL
--);
--INSERT @Result
-- (SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());
Stosowane są tylko blokady intencji (IS) na poziomie tabeli i strony, a wydajność wzrasta do tego samego poziomu, co w przypadku użycia PAGLOCK wskazówka. Oczywiście nie znajdziesz tego zachowania w dokumentacji i w każdej chwili może się ono zmienić. Mimo to dobrze jest być tego świadomym.
Ponadto, jeśli się zastanawiasz, flaga śledzenia 4138 nie ma w tym przypadku wpływu na wybór szczegółowości blokowania aparatu magazynu, ponieważ szacowana liczba wierszy w wyszukiwaniu jest zbyt niska (na iterację zastosowania), nawet przy wyłączonym celu wiersza.
Zanim wyciągniesz wnioski na temat działania zapytania, sprawdź liczbę i rodzaj blokad, które są przyjmowane podczas wykonywania. Chociaż SQL Server zwykle wybiera „właściwą” szczegółowość, zdarzają się sytuacje, w których może się nie udać, czasami z dramatycznym wpływem na wydajność.