Najszybszy sposób obliczenia mediany wykorzystuje SQL Server 2012 OFFSET rozszerzenie ORDER BY klauzula. Kolejne najszybsze rozwiązanie, działające blisko sekundy, korzysta z (prawdopodobnie zagnieżdżonego) dynamicznego kursora, który działa we wszystkich wersjach. W tym artykule omówiono typowy ROW_NUMBER sprzed 2012 r. rozwiązanie problemu obliczania mediany, aby zobaczyć, dlaczego działa gorzej i co można zrobić, aby przyspieszyć.
Pojedynczy test mediany
Przykładowe dane do tego testu składają się z pojedynczej tabeli zawierającej dziesięć milionów wierszy (odtworzonej z oryginalnego artykułu Aarona Bertranda):
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); Rozwiązanie OFFSET
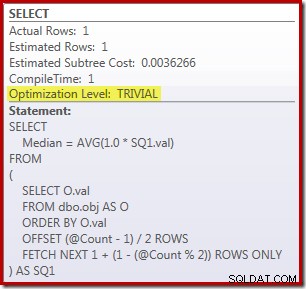
Aby ustawić benchmark, oto rozwiązanie OFFSET w SQL Server 2012 (lub nowsze) stworzone przez Petera Larssona:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - (@Count % 2)) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Zapytanie mające na celu zliczenie wierszy w tabeli jest wykomentowane i zastąpione wartością zakodowaną na stałe, aby skoncentrować się na wydajności kodu podstawowego. Po wyłączeniu ciepłej pamięci podręcznej i zbierania planów wykonania to zapytanie działa przez 910 ms średnio na mojej maszynie testowej. Plan wykonania pokazano poniżej:

Na marginesie, interesujące jest to, że to umiarkowanie złożone zapytanie kwalifikuje się do trywialnego planu:
Rozwiązanie ROW_NUMBER
W przypadku systemów z systemem SQL Server 2008 R2 lub starszym najlepsze rozwiązania alternatywne wykorzystują kursor dynamiczny, jak wspomniano wcześniej. Jeśli nie możesz (lub nie chcesz) rozważyć tego jako opcji, naturalne jest, aby pomyśleć o emulacji OFFSET 2012 plan wykonania przy użyciu ROW_NUMBER .
Podstawową ideą jest ponumerowanie wierszy w odpowiedniej kolejności, a następnie odfiltrowanie tylko jednego lub dwóch wierszy potrzebnych do obliczenia mediany. W Transact SQL można to napisać na kilka sposobów; kompaktowa wersja, która zawiera wszystkie kluczowe elementy, wygląda następująco:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
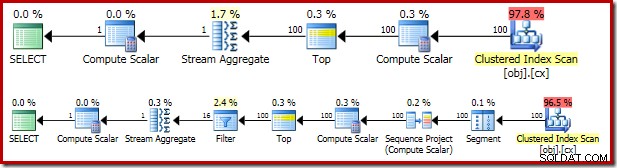
Wynikowy plan wykonania jest dość podobny do OFFSET wersja:

Warto przyjrzeć się każdemu z operatorów planów po kolei, aby w pełni je zrozumieć:
- Operator segmentu jest w tym planie zbędny. Będzie to wymagane, jeśli
ROW_NUMBERfunkcja rankingowa miałaPARTITION BYklauzuli, ale tak nie jest. Mimo to pozostaje w ostatecznym planie. - Projekt Sequence dodaje obliczony numer wiersza do strumienia wierszy.
- Skalar obliczeniowy definiuje wyrażenie związane z potrzebą niejawnej konwersji
valkolumny na numeryczne, aby można ją było pomnożyć przez stały literał1.0w zapytaniu. To obliczenie jest odraczane do czasu, gdy będzie potrzebne późniejszemu operatorowi (którym jest Stream Aggregate). Ta optymalizacja środowiska uruchomieniowego oznacza, że niejawna konwersja jest wykonywana tylko dla dwóch wierszy przetwarzanych przez agregację strumienia, a nie dla 5 000 001 wierszy wskazanych dla obliczeń skalarnych. - Operator Top jest wprowadzany przez optymalizator zapytań. Rozpoznaje, że co najwyżej tylko pierwszy
(@Count + 2) / 2wiersze są potrzebne w zapytaniu. Mogliśmy dodaćTOP ... ORDER BYw podzapytaniu, aby to było wyraźne, ale ta optymalizacja sprawia, że jest to w dużej mierze niepotrzebne. - Filtr implementuje warunek w
WHEREklauzula, odfiltrowując wszystkie wiersze oprócz dwóch „środkowych” potrzebnych do obliczenia mediany (wprowadzony Top jest również oparty na tym warunku). - Agregacja strumienia oblicza
SUMiCOUNTz dwóch rzędów środkowych. - Ostateczny skalar obliczeniowy oblicza średnią z sumy i liczby.
Pierwsza wydajność
W porównaniu z OFFSET planu, możemy się spodziewać, że dodatkowe operatory Segmentu, Projektu Sekwencji i Filtra będą miały niekorzystny wpływ na wydajność. Warto poświęcić chwilę na porównanie szacowanych koszty dwóch planów:
OFFSET plan ma szacunkowy koszt 0,0036266 jednostek, podczas gdy ROW_NUMBER plan jest szacowany na 0,0036744 jednostki. Są to bardzo małe liczby i nie ma między nimi dużej różnicy.
Być może więc zaskakujące jest to, że ROW_NUMBER zapytanie faktycznie działa przez 4000 ms średnio w porównaniu z 910 ms średnia dla OFFSET rozwiązanie. Część tego wzrostu można z pewnością wytłumaczyć kosztami operatorów dodatkowych planów, ale współczynnik czterokrotny wydaje się przesadny. Musi być w tym coś więcej.
Prawdopodobnie zauważyłeś również, że szacunki dotyczące kardynalności dla obu szacowanych planów powyżej są beznadziejnie błędne. Wynika to z działania operatorów Top, które mają wyrażenie odwołujące się do zmiennej jako limity liczby wierszy. Optymalizator zapytań nie widzi zawartości zmiennych w czasie kompilacji, więc korzysta z domyślnego przypuszczenia 100 wierszy. Oba plany faktycznie napotykają 5 000 001 wierszy w czasie wykonywania.
To wszystko jest bardzo interesujące, ale nie wyjaśnia bezpośrednio, dlaczego ROW_NUMBER zapytanie jest ponad cztery razy wolniejsze niż OFFSET wersja. W końcu szacowana kardynalność 100 wierszy jest tak samo błędna w obu przypadkach.
Poprawa wydajności rozwiązania ROW_NUMBER
W moim poprzednim artykule widzieliśmy, jak wydajność zgrupowanej mediany OFFSET test można prawie podwoić, po prostu dodając PAGLOCK wskazówka. Ta wskazówka zastępuje normalną decyzję aparatu pamięci masowej o nabyciu i zwolnieniu współdzielonych blokad na poziomie szczegółowości wierszy (ze względu na niską oczekiwaną kardynalność).
Jako dalsze przypomnienie, PAGLOCK wskazówka była niepotrzebna w pojedynczej medianie OFFSET test ze względu na oddzielną wewnętrzną optymalizację, która może pomijać współdzielone blokady na poziomie wiersza, co skutkuje tylko niewielką liczbą intencjonalnych blokad współdzielonych na poziomie strony.
Możemy się spodziewać ROW_NUMBER pojedyncza mediana, aby skorzystać z tej samej wewnętrznej optymalizacji, ale tak nie jest. Monitorowanie aktywności blokowania podczas ROW_NUMBER zapytanie zostanie wykonane, widzimy ponad pół miliona współdzielonych blokad na poziomie poszczególnych wierszy zostanie zabrany i zwolniony.
Więc teraz wiemy, na czym polega problem, możemy poprawić wydajność blokowania w ten sam sposób, w jaki robiliśmy to wcześniej:albo za pomocą PAGLOCK wskazówkę dotyczącą szczegółowości blokady lub zwiększając oszacowanie kardynalności za pomocą udokumentowanej flagi śledzenia 4138.
Wyłączenie „celu wiersza” przy użyciu flagi śledzenia jest mniej zadowalającym rozwiązaniem z kilku powodów. Po pierwsze, działa tylko w SQL Server 2008 R2 lub nowszym. Najprawdopodobniej wolelibyśmy OFFSET rozwiązanie w programie SQL Server 2012, co skutecznie ogranicza poprawkę flagi śledzenia tylko do programu SQL Server 2008 R2. Po drugie, zastosowanie flagi śledzenia wymaga uprawnień na poziomie administratora, chyba że zastosowano je za pomocą przewodnika po planie. Trzecim powodem jest to, że wyłączenie celów wierszy dla całego zapytania może mieć inne niepożądane skutki, szczególnie w bardziej złożonych planach.
Natomiast PAGLOCK wskazówka jest skuteczna, dostępna we wszystkich wersjach SQL Server bez żadnych specjalnych uprawnień i nie ma żadnych poważnych skutków ubocznych poza szczegółowością blokowania.
Stosowanie PAGLOCK wskazówka do ROW_NUMBER zapytanie znacznie zwiększa wydajność:od 4000 ms do 1500 ms:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK) -- New!
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
1500 ms wynik jest nadal znacznie wolniejszy niż 910 ms dla OFFSET rozwiązanie, ale przynajmniej jest teraz na tym samym boisku. Pozostała różnica w wydajności wynika po prostu z dodatkowej pracy w planie wykonania:

W OFFSET plan, pięć milionów wierszy jest przetwarzanych aż do góry (z wyrażeniami zdefiniowanymi w obliczeniach skalarnych odroczonych, jak omówiono wcześniej). W ROW_NUMBER plan, taka sama liczba wierszy musi zostać przetworzona przez segment, projekt sekwencji, górę i filtr.