Prosta definicja mediany to:
Mediana to środkowa wartość na posortowanej liście liczbAby nieco to wyjaśnić, możemy znaleźć medianę listy liczb, korzystając z następującej procedury:
- Posortuj liczby (w kolejności rosnącej lub malejącej, nie ma znaczenia w jakiej kolejności).
- Środkowa liczba (według pozycji) na posortowanej liście to mediana.
- Jeśli są dwie „równie średnie” liczby, mediana jest średnią z dwóch średnich wartości.
Aaron Bertrand wcześniej przetestował wydajność kilku sposobów obliczania mediany w SQL Server:
- Jaki jest najszybszy sposób obliczenia mediany?
- Najlepsze podejście do mediany zgrupowanej
Rob Farley niedawno dodał inne podejście mające na celu instalacje przed 2012 r.:
- Media przed SQL 2012
Ten artykuł przedstawia nową metodę wykorzystującą dynamiczny kursor.
Metoda OFFSET-FETCH 2012
Zaczniemy od przyjrzenia się najlepiej działającej implementacji, stworzonej przez Petera Larssona. Używa SQL Server 2012 OFFSET rozszerzenie ORDER BY klauzula, aby skutecznie zlokalizować jeden lub dwa środkowe wiersze potrzebne do obliczenia mediany.
PRZESUNIĘCIE Pojedyncza mediana
W pierwszym artykule Aarona testowano obliczanie pojedynczej mediany w tabeli zawierającej dziesięć milionów wierszy:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
Rozwiązanie Petera Larssona przy użyciu OFFSET rozszerzenie to:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Powyższy kod na stałe koduje wynik zliczania wierszy w tabeli. Wszystkie testowane metody obliczania mediany wymagają tej liczby w celu obliczenia mediany liczb wierszy, więc jest to koszt stały. Pozostawienie operacji liczenia rzędów poza harmonogramem pozwala uniknąć jednego możliwego źródła zmienności.
Plan wykonania dla OFFSET rozwiązanie jest pokazane poniżej:

Operator Top szybko pomija niepotrzebne wiersze, przekazując tylko jeden lub dwa wiersze potrzebne do obliczenia mediany do Stream Aggregate. Po uruchomieniu z wyłączoną ciepłą pamięcią podręczną i wyłączonym gromadzeniem planu wykonania to zapytanie działa przez 910 ms średnio na moim laptopie. Jest to maszyna z procesorem Intel i7 740QM działającym z częstotliwością 1,73 GHz z wyłączoną funkcją Turbo (dla spójności).
Zgrupowana mediana PRZESUNIĘCIA
W drugim artykule Aarona przetestowano wydajność obliczania mediany na grupę przy użyciu tabeli sprzedaży zawierającej milion wierszy z dziesięcioma tysiącami wpisów dla każdej ze stu sprzedawców:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
Ponownie, najlepiej działające rozwiązanie wykorzystuje OFFSET :
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK)
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Ważna część planu wykonania jest pokazana poniżej:

Górny wiersz planu dotyczy znalezienia liczby wierszy w grupie dla każdego sprzedawcy. W dolnym wierszu do obliczenia mediany dla każdego sprzedawcy są używane te same elementy planu, co w przypadku rozwiązania z medianą dla pojedynczej grupy. Po uruchomieniu z ciepłą pamięcią podręczną i wyłączonymi planami wykonania to zapytanie jest wykonywane w ciągu 320 ms średnio na moim laptopie.
Korzystanie z dynamicznego kursora
Nawet myśl o użyciu kursora do obliczenia mediany może wydawać się szalona. Kursory Transact SQL mają (w większości zasłużoną) reputację powolnych i nieefektywnych. Często uważa się również, że kursory dynamiczne są najgorszym typem kursora. Te punkty są ważne w niektórych okolicznościach, ale nie zawsze.
Kursory Transact SQL są ograniczone do przetwarzania pojedynczego wiersza na raz, więc mogą być rzeczywiście powolne, jeśli trzeba pobrać i przetworzyć wiele wierszy. Nie dotyczy to jednak obliczania mediany:wszystko, co musimy zrobić, to zlokalizować i pobrać jedną lub dwie średnie wartości skutecznie . Dynamiczny kursor jest bardzo odpowiedni do tego zadania, jak zobaczymy.
Dynamiczny kursor z pojedynczą medianą
Rozwiązanie dynamicznego kursora dla obliczenia pojedynczej mediany składa się z następujących kroków:
- Utwórz dynamicznie przewijany kursor nad uporządkowaną listą elementów.
- Oblicz pozycję pierwszego rzędu mediany.
- Zmień położenie kursora za pomocą
FETCH RELATIVE. - Zdecyduj, czy do obliczenia mediany potrzebny jest drugi wiersz.
- Jeśli nie, natychmiast zwróć pojedynczą wartość mediany.
- W przeciwnym razie pobierz drugą wartość za pomocą
FETCH NEXT. - Oblicz średnią z dwóch wartości i zwróć.
Zwróć uwagę, jak bardzo ta lista odzwierciedla prostą procedurę znajdowania mediany podaną na początku tego artykułu. Pełna implementacja kodu Transact SQL jest pokazana poniżej:
-- Dynamic cursor
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE
@RowCount bigint, -- Total row count
@Row bigint, -- Median row number
@Amount1 integer, -- First amount
@Amount2 integer, -- Second amount
@Median float; -- Calculated median
SET @RowCount = 10000000;
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
DECLARE Median CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
O.val
FROM dbo.obj AS O
ORDER BY
O.val;
OPEN Median;
-- Calculate the position of the first median row
SET @Row = (@RowCount + 1) / 2;
-- Move to the row
FETCH RELATIVE @Row
FROM Median
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value we have
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Median
INTO @Amount2;
-- Calculate the median value from the two values
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
SELECT Median = @Median;
SELECT DynamicCur = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Plan wykonania dla FETCH RELATIVE instrukcja pokazuje, że dynamiczny kursor skutecznie przemieszcza się do pierwszego wiersza wymaganego do obliczenia mediany:
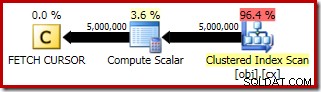
Plan dla FETCH NEXT (wymagane tylko, jeśli istnieje drugi środkowy wiersz, tak jak w tych testach) to pobranie pojedynczego wiersza z zapisanej pozycji kursora:
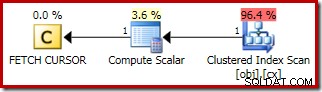
Zalety korzystania z dynamicznego kursora to:
- Unika przemierzania całego zestawu (czytanie zatrzymuje się po znalezieniu rzędów środkowych); oraz
- Żadna tymczasowa kopia danych nie jest tworzona w tempdb , tak jak w przypadku kursora statycznego lub z zestawem klawiszy.
Zauważ, że nie możemy określić FAST_FORWARD kursor tutaj (pozostawiając wybór planu statycznego lub dynamicznego optymalizatorowi), ponieważ kursor musi być przewijalny, aby obsługiwać FETCH RELATIVE . Dynamiczny i tak jest optymalnym wyborem.
Po uruchomieniu z wyłączoną ciepłą pamięcią podręczną i wyłączonym gromadzeniem planu wykonania to zapytanie działa przez 930 ms średnio na mojej maszynie testowej. To trochę wolniej niż 910 ms dla OFFSET rozwiązanie, ale dynamiczny kursor jest znacznie szybszy niż inne metody testowane przez Aarona i Roba i nie wymaga SQL Server 2012 (lub nowszego).
Nie zamierzam tutaj powtarzać testowania innych metod sprzed 2012 roku, ale jako przykład wielkości luki w wydajności, poniższe rozwiązanie numeracji wierszy zajmuje 1550 ms średnio (70% wolniej):
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK)
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT RowNumber = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());

Grupowy test dynamicznego kursora mediany
Można łatwo rozszerzyć rozwiązanie dynamicznego kursora z pojedynczą medianą o obliczanie median zgrupowanych. Ze względu na spójność zamierzam użyć zagnieżdżonych kursorów (tak, naprawdę):
- Otwórz statyczny kursor nad sprzedawcami i liczbą wierszy.
- Oblicz medianę dla każdej osoby, używając za każdym razem nowego dynamicznego kursora.
- Zapisz każdy wynik w zmiennej tabeli, gdy idziemy.
Kod jest pokazany poniżej:
-- Timing
DECLARE @s datetime2 = SYSUTCDATETIME();
-- Holds results
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
-- Variables
DECLARE
@SalesPerson integer, -- Current sales person
@RowCount bigint, -- Current row count
@Row bigint, -- Median row number
@Amount1 float, -- First amount
@Amount2 float, -- Second amount
@Median float; -- Calculated median
-- Row counts per sales person
DECLARE SalesPersonCounts
CURSOR
LOCAL
FORWARD_ONLY
STATIC
READ_ONLY
FOR
SELECT
SalesPerson,
COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
ORDER BY SalesPerson;
OPEN SalesPersonCounts;
-- First person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
WHILE @@FETCH_STATUS = 0
BEGIN
-- Records for the current person
-- Note dynamic cursor
DECLARE Person CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
S.Amount
FROM dbo.Sales AS S
WHERE
S.SalesPerson = @SalesPerson
ORDER BY
S.Amount;
OPEN Person;
-- Calculate median row 1
SET @Row = (@RowCount + 1) / 2;
-- Move to median row 1
FETCH RELATIVE @Row
FROM Person
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Person
INTO @Amount2;
-- Calculate the median value
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
-- Add the result row
INSERT @Result (SalesPerson, Median)
VALUES (@SalesPerson, @Median);
-- Finished with the person cursor
CLOSE Person;
DEALLOCATE Person;
-- Next person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
END;
---- Results
--SELECT
-- R.SalesPerson,
-- R.Median
--FROM @Result AS R;
-- Tidy up
CLOSE SalesPersonCounts;
DEALLOCATE SalesPersonCounts;
-- Show elapsed time
SELECT NestedCur = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Kursor zewnętrzny jest celowo statyczny, ponieważ wszystkie wiersze w tym zestawie zostaną dotknięte (również kursor dynamiczny nie jest dostępny z powodu operacji grupowania w zapytaniu źródłowym). Tym razem w planach wykonania nie ma nic szczególnie nowego ani interesującego.
Interesującą rzeczą jest wykonanie. Pomimo wielokrotnego tworzenia i cofania alokacji wewnętrznego kursora dynamicznego rozwiązanie to działa naprawdę dobrze na zestawie danych testowych. Po wyłączeniu ciepłej pamięci podręcznej i planów wykonania skrypt kursora kończy się w 330 ms średnio na mojej maszynie testowej. To znowu trochę wolniej niż 320 ms zarejestrowane przez OFFSET zgrupowana mediana, ale znacznie przewyższa inne standardowe rozwiązania wymienione w artykułach Aarona i Roba.
Ponownie, jako przykład różnicy w wydajności w porównaniu z innymi metodami spoza 2012 r., poniższe rozwiązanie numeracji wierszy działa przez 485 ms średnio na moim stanowisku testowym (50% gorzej):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median numeric(38, 6) NOT NULL
);
INSERT @Result
SELECT
S.SalesPerson,
CA.Median
FROM
(
SELECT
SalesPerson,
NumRows = COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
) AS S
CROSS APPLY
(
SELECT AVG(1.0 * SQ1.Amount) FROM
(
SELECT
S2.Amount,
rn = ROW_NUMBER() OVER (
ORDER BY S2.Amount)
FROM dbo.Sales AS S2 WITH (PAGLOCK)
WHERE
S2.SalesPerson = S.SalesPerson
) AS SQ1
WHERE
SQ1.rn BETWEEN (S.NumRows + 1)/2 AND (S.NumRows + 2)/2
) AS CA (Median);
SELECT RowNumber = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());

Podsumowanie wyników
W teście pojedynczej mediany kursor dynamiczny trwał 930 ms w porównaniu z 910 ms dla OFFSET metody.
W zgrupowanym teście mediany kursor zagnieżdżony działał przez 330 ms w porównaniu z 320 ms dla OFFSET .
W obu przypadkach metoda kursora była znacznie szybsza niż metody inne niż OFFSET metody. Jeśli chcesz obliczyć pojedynczą lub zgrupowaną medianę dla instancji sprzed 2012 r., kursor dynamiczny lub zagnieżdżony naprawdę może być optymalnym wyborem.
Wydajność zimnej pamięci podręcznej
Niektórzy z was mogą się zastanawiać nad wydajnością zimnej pamięci podręcznej. Uruchamianie następujących czynności przed każdym testem:
CHECKPOINT; DBCC DROPCLEANBUFFERS;
Oto wyniki testu z pojedynczą medianą:
OFFSET metoda:940 ms
Kursor dynamiczny:955 ms
Dla mediany zgrupowanej:
OFFSET metoda:380 ms
Zagnieżdżone kursory:385 ms
Ostateczne myśli
Dynamiczne rozwiązania kursora są naprawdę znacznie szybsze niż rozwiązania inne niż OFFSET metody zarówno dla pojedynczych, jak i grupowanych median, przynajmniej z tymi przykładowymi zestawami danych. Celowo zdecydowałem się ponownie wykorzystać dane testowe Aarona, aby zestawy danych nie były celowo przekrzywione w kierunku dynamicznego kursora. Tam może być innymi dystrybucjami danych, dla których dynamiczny kursor nie jest dobrym rozwiązaniem. Niemniej jednak pokazuje, że wciąż zdarzają się sytuacje, w których kursor może być szybkim i skutecznym rozwiązaniem właściwego problemu. Nawet dynamiczne i zagnieżdżone kursory.
Czytelnicy o orlim wzroku mogli zauważyć PAGLOCK wskazówka w OFFSET zgrupowany test mediany. Jest to wymagane do uzyskania najlepszej wydajności, z powodów, które omówię w następnym artykule. Bez tego rozwiązanie 2012 faktycznie przegrywa z zagnieżdżonym kursorem o przyzwoity margines (590 ms w porównaniu z 330 ms ).