W kilku moich postach z zeszłego roku wykorzystałem motyw, w którym ludzie widzą określony typ oczekiwania, a następnie reagują w sposób „podskakujący” na to czekanie. Zazwyczaj oznacza to stosowanie się do kiepskich porad internetowych i podejmowanie drastycznych, niewłaściwych działań lub wyciąganie pochopnych wniosków na temat przyczyny problemu, a następnie marnowanie czasu i wysiłku na pogoń za dziką gęsią.
Jednym z typów oczekiwania, w którym reakcje odruchowe są najsilniejsze i gdzie istnieją najgorsze rady, jest czekanie CXPACKET. Jest to również typ oczekiwania, który jest najczęściej najwyższym oczekiwaniem na serwerach ludzi (według moich dwóch dużych ankiet dotyczących typów oczekiwania z 2010 i 2014 r. – zobacz tutaj, aby uzyskać szczegółowe informacje), więc omówię go w tym poście.
Co oznacza typ oczekiwania CXPACKET?
Najprostszym wyjaśnieniem jest to, że CXPACKET oznacza, że masz zapytania działające równolegle i *zawsze* zobaczysz, że CXPACKET czeka na zapytanie równoległe. Oczekiwanie CXPACKET NIE oznacza, że masz problematyczną równoległość – musisz sięgnąć głębiej, aby to ustalić.
Jako przykład operatora równoległego rozważ operator Repartition Streams, który ma następującą ikonę w graficznych planach zapytań:

A oto obrazek, który pokazuje, co się dzieje pod względem równoległych wątków dla tego operatora, ze stopniem równoległości (DOP) równym 4:
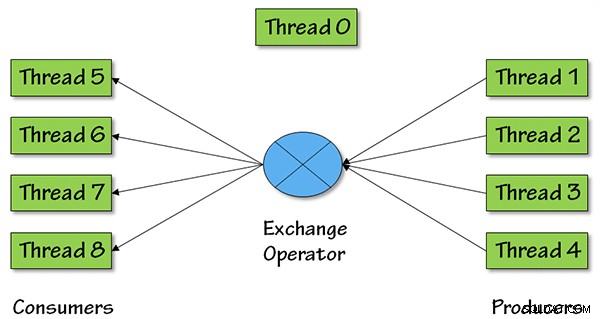
Dla DOP =4 będą cztery wątki producenta, które będą pobierać dane z wcześniejszego planu zapytań, a następnie dane wrócą do reszty planu zapytania przez cztery wątki konsumentów.
Możesz zobaczyć różne wątki w operatorze równoległym, które czekają na zasób, używając sys.dm_os_waiting_tasks DMV, w exec_context_id kolumna (ten post zawiera mój skrypt do tego).
Zawsze istnieje wątek „kontrolny” dla każdego planu równoległego, który przez przypadek historyczny ma zawsze identyfikator wątku 0. Wątek kontrolny zawsze rejestruje oczekiwanie CXPACKET, którego czas trwania jest równy czasowi wykonania planu. Paul White ma tutaj świetne wyjaśnienie wątków w równoległych planach.
Jedynym przypadkiem, w którym wątki niekontrolujące będą rejestrować oczekiwania CXPACKET, jest zakończenie ich przed innymi wątkami operatora. Może się to zdarzyć, jeśli jeden z wątków utknie w oczekiwaniu na zasób przez długi czas, więc sprawdź, jaki jest typ oczekiwania w wątku, który nie wyświetla CXPACKET (przy użyciu mojego skryptu powyżej) i odpowiednio rozwiąż problemy. Może się to również zdarzyć z powodu przekrzywionego rozłożenia pracy między wątki, a dokładniej omówię tę sprawę w moim następnym poście (jest to spowodowane nieaktualnymi statystykami i innymi problemami z szacowaniem kardynalności).
Należy zauważyć, że w SQL Server 2016 z dodatkiem SP2 i SQL Server 2017 RTM CU3 wątki konsumenckie nie rejestrują już oczekiwania CXPACKET. Rejestrują oczekiwania CXCONSUMER, które są łagodne i można je zignorować. Ma to na celu zmniejszenie liczby generowanych czekań CXPACKET, a pozostałe z większym prawdopodobieństwem będą wykonalne.
Nieoczekiwany równoległość?
Biorąc pod uwagę, że CXPACKET oznacza po prostu, że występuje paralelizm, pierwszą rzeczą, na którą należy zwrócić uwagę, jest to, czy oczekujesz paralelizmu dla zapytania, które go używa. Moje zapytanie da ci identyfikator węzła planu zapytania, w którym zachodzi równoległość (wyciąga identyfikator węzła z planu zapytania XML, jeśli typem oczekiwania wątku jest CXPACKET), więc poszukaj tego identyfikatora węzła i ustal, czy równoległość ma sens .
Jednym z typowych przypadków nieoczekiwanego paralelizmu jest sytuacja, gdy skanowanie tabeli ma miejsce, gdy oczekujesz mniejszego wyszukiwania lub skanowania indeksu. Zobaczysz to albo w planie zapytań, albo zobaczysz wiele czekań PAGEIOLATCH_SH (omówionych szczegółowo tutaj) wraz z czekaniami CXPACKET (klasyczny wzorzec statystyk oczekiwania, na który należy zwrócić uwagę). Istnieje wiele przyczyn nieoczekiwanego skanowania tabel, w tym:
- Brak indeksu nieklastrowego, więc skanowanie tabeli jest jedyną alternatywą
- Nieaktualne statystyki, więc Optymalizator zapytań uważa, że skanowanie tabeli jest najlepszą metodą dostępu do danych do użycia
- Niejawna konwersja z powodu niezgodności typu danych między kolumną tabeli a zmienną lub parametrem, co oznacza, że nie można użyć indeksu nieklastrowego
- Arytmetyka wykonywana na kolumnie tabeli zamiast na zmiennej lub parametrze, co oznacza, że nie można użyć indeksu nieklastrowanego
We wszystkich tych przypadkach rozwiązanie jest podyktowane tym, jaka jest główna przyczyna.
Ale co, jeśli nie ma oczywistego przypadku głównego, a zapytanie zostanie uznane za wystarczająco drogie, aby uzasadnić plan równoległy?
Zapobieganie równoległości
Optymalizator zapytań decyduje między innymi o utworzeniu planu zapytania równoległego, jeśli plan szeregowy ma wyższy koszt niż cost threshold for parallelism , ustawienie sp_configure dla wystąpienia. Próg kosztów równoległości (lub CTFP) jest domyślnie ustawiony na pięć, co oznacza, że plan nie musi być bardzo drogi, aby uruchomić tworzenie planu równoległego.
Jednym z najłatwiejszych sposobów zapobiegania niechcianej równoległości jest zwiększenie CTFP do znacznie większej liczby, im wyższy jest ustawiony, tym mniej prawdopodobne będą tworzone plany równoległe. Niektórzy zalecają ustawienie CTFP na wartość od 25 do 50, ale tak jak w przypadku wszystkich ustawień, które można modyfikować, najlepiej jest przetestować różne wartości i zobaczyć, co najlepiej sprawdza się w danym środowisku. Jeśli potrzebujesz nieco bardziej zautomatyzowanej metody, która pomoże wybrać dobrą wartość CTFP, Jonathan napisał post na blogu, w którym znajduje się zapytanie do analizy pamięci podręcznej planu i uzyskania sugerowanej wartości CTFP. Jako przykład, mamy jednego klienta z CTFP ustawionym na 200, a inny ustawiony na maksimum – 32767 – jako sposób na przymusowe zapobieganie wszelkim paralelizmom.
Możesz się zastanawiać, dlaczego drugi klient musiał używać CTFP jako metody młota do zapobiegania równoległości, kiedy można by pomyśleć, że mogliby po prostu ustawić serwer „maksymalny stopień równoległości” (lub MAXDOP) na 1. Cóż, każdy z dowolnym poziomem uprawnień może określ wskazówkę dotyczącą MAXDOP zapytania i zastąp ustawienie MAXDOP serwera, ale nie można nadpisać CTFP.
I to jest kolejna metoda ograniczania równoległości – ustawienie podpowiedzi MAXDOP w zapytaniu, którego nie chcesz wykonywać równolegle.
Możesz także obniżyć ustawienie MAXDOP serwera, ale jest to drastyczne rozwiązanie, ponieważ może uniemożliwić wszystkim korzystanie z równoległości. Obecnie często zdarza się, że serwery mają mieszane obciążenia, na przykład z niektórymi zapytaniami OLTP i niektórymi zapytaniami raportowania. Jeśli obniżysz MAXDOP serwera, zmniejszysz wydajność zapytań raportujących.
Lepszym rozwiązaniem, gdy występuje mieszane obciążenie, byłoby użycie CTFP, jak opisałem powyżej, lub skorzystanie z narzędzia Resource Governor (obawiam się, że jest to tylko Enterprise). Możesz użyć Resource Governor, aby podzielić obciążenia na grupy obciążenia, a następnie ustawić MAX_DOP (podkreślenie nie jest literówką) dla każdej grupy obciążenia. Dobrą rzeczą w korzystaniu z Resource Governor jest to, że MAX_DOP nie może zostać zastąpiony przez wskazówkę dotyczącą zapytania MAXDOP.
Podsumowanie
Nie wpadaj w pułapkę myślenia, że CXPACKET czeka automatycznie, co oznacza, że masz złą równoległość, i na pewno nie postępuj zgodnie z niektórymi z internetowych porad dotyczących trzaskania serwerem przez ustawienie MAXDOP na 1. Nie spiesz się aby zbadać, dlaczego widzisz, że CXPACKET czeka i czy jest to coś, czym należy się zająć, czy tylko artefakt obciążenia, które działa poprawnie.
Jeśli chodzi o ogólne statystyki oczekiwania, więcej informacji na temat ich używania do rozwiązywania problemów z wydajnością można znaleźć w:
- Moja seria wpisów na blogu SQLskills, zaczynająca się od statystyk Wait lub proszę powiedz mi, gdzie to boli
- Moja biblioteka typów Wait Types i Latch Classes tutaj
- Mój kurs szkoleniowy online Pluralsight SQL Server:Rozwiązywanie problemów z wydajnością za pomocą statystyk oczekiwania
- Doradca wydajności SQL Sentry
W następnym artykule z tej serii omówię przekrzywioną równoległość i przedstawię prosty sposób, aby zobaczyć, jak to się dzieje. Do tego czasu życzę miłego rozwiązywania problemów!