Post autorstwa Dana Holmesa, który bloguje na sql.dnhlms.com.
Książki SQL Server Books Online (BOL), oficjalne dokumenty i wiele innych źródeł pokazują, jak i dlaczego warto aktualizować statystyki w tabeli lub indeksie. Masz jednak tylko jeden sposób kształtowania tych wartości. Pokażę Ci, jak możesz tworzyć statystyki dokładnie tak, jak chcesz, w ramach dostępnych 200 kroków.
Zastrzeżenie :To działa dla mnie, ponieważ znam moją aplikację, moją bazę danych oraz regularne wzorce pracy i użytkowania aplikacji mojego użytkownika. Jednak używa nieudokumentowanych poleceń, a jeśli zostanie użyty niepoprawnie, może znacznie pogorszyć działanie aplikacji.W naszej aplikacji użytkownik Scheduling regularnie odczytuje i zapisuje dane reprezentujące zdarzenia na jutro i kilka następnych dni. Harmonogram nie wykorzystuje danych z dnia dzisiejszego i wcześniejszego. Z samego rana zestaw danych na jutro zaczyna się od kilkuset wierszy i do południa może wynosić 1400 i więcej. Poniższa tabela ilustruje liczbę wierszy. Te dane zostały zebrane rano w środę 18 listopada 2015 r. Historycznie można zauważyć, że normalna liczba wierszy wynosi około 1400, z wyjątkiem dni weekendowych i następnego dnia.
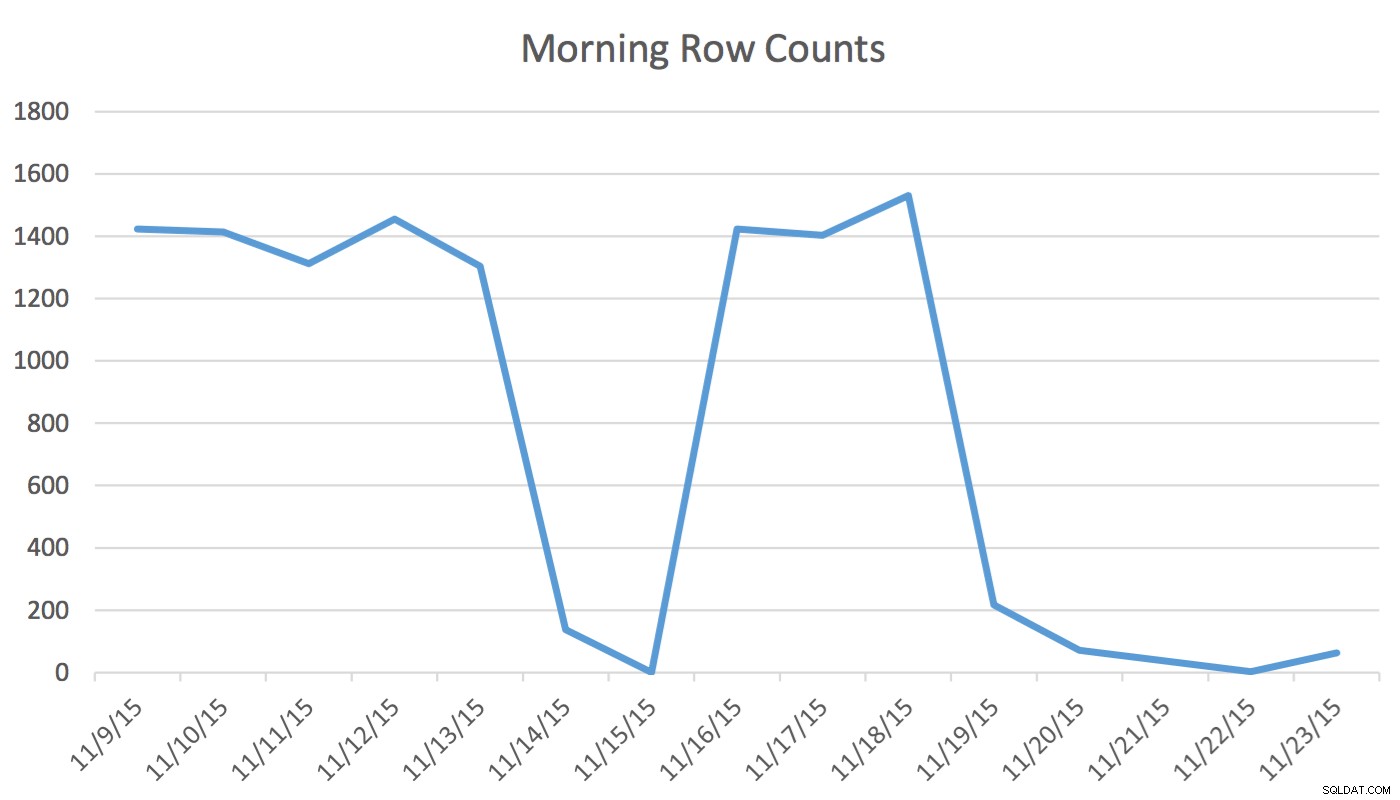
Dla Schedulera jedyne istotne dane to kilka następnych dni. To, co dzieje się dzisiaj i wydarzyło się wczoraj, nie ma związku z jego działalnością. Więc jak to powoduje problem? Ta tabela ma 2 259 205 wierszy, co oznacza, że zmiana liczby wierszy od rana do południa nie wystarczy do wywołania aktualizacji statystyk zainicjowanej przez SQL Server. Ponadto ręcznie zaplanowane zadanie, które tworzy statystyki za pomocą UPDATE STATISTICS wypełnia histogram próbką wszystkich danych w tabeli, ale może nie zawierać odpowiednich informacji. Ta delta liczby wierszy wystarczy, aby zmienić plan. Jednak bez aktualizacji statystyk i dokładnego histogramu plan nie zmieni się na lepsze wraz ze zmianą danych.
Odpowiedni wybór histogramu dla tej tabeli z kopii zapasowej z dnia 11.04.2015 może wyglądać tak:
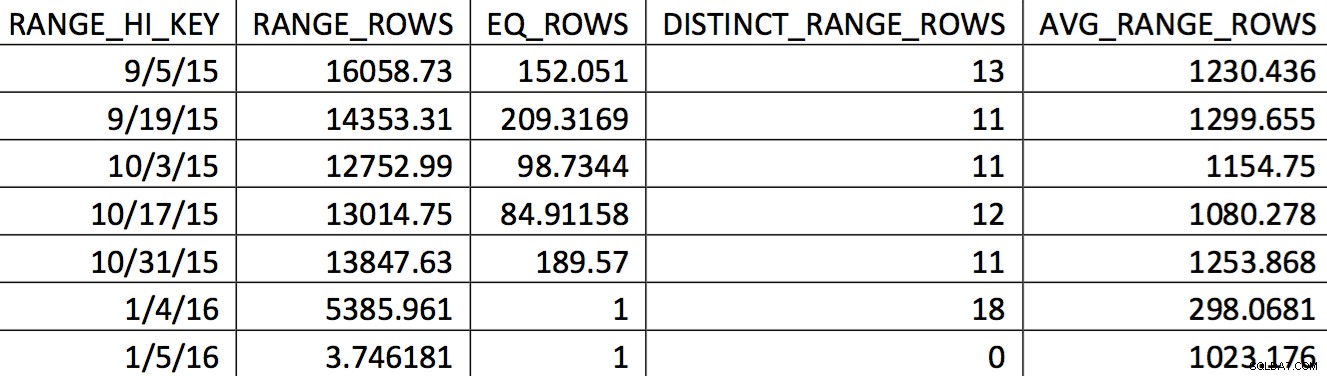
Interesujące wartości nie są dokładnie odzwierciedlone na histogramie. Dla daty 11.05.2015 przyjęta zostałaby wysoka wartość z 1.04.2016. Na podstawie wykresu ten histogram wyraźnie nie jest dobrym źródłem informacji dla optymalizatora dla interesującej go daty. Wymuszanie wartości użycia na histogramie nie jest wiarygodne, więc jak możesz to zrobić? Moja pierwsza próba polegała na wielokrotnym użyciu WITH SAMPLE opcja UPDATE STATISTICS i przeszukuj histogram, aż potrzebne mi wartości znajdą się na histogramie (wysiłek opisany tutaj). Ostatecznie to podejście okazało się zawodne.
Ten histogram może prowadzić do planu z tego typu zachowaniem. Niedoszacowanie liczby wierszy tworzy sprzężenie zagnieżdżone w pętli i wyszukiwanie indeksu. Odczyty są następnie wyższe niż powinny być z powodu tego wyboru planu. Wpłynie to również na czas trwania wyciągu.
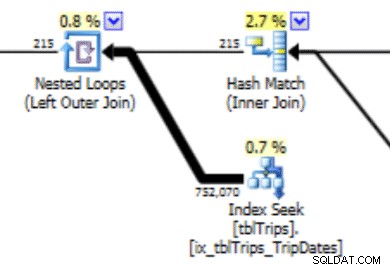
Znacznie lepiej działałoby tworzenie danych dokładnie tak, jak chcesz, a oto jak to zrobić.
Istnieje nieobsługiwana opcja UPDATE STATISTICS :STATS_STREAM . Jest to używane przez dział obsługi klienta firmy Microsoft do eksportowania i importowania statystyk, dzięki czemu mogą uzyskać odtworzenie optymalizatora bez posiadania wszystkich danych w tabeli. Możemy skorzystać z tej funkcji. Pomysł polega na stworzeniu tabeli, która naśladuje DDL statystyki, którą chcemy dostosować. Odpowiednie dane są dodawane do tabeli. Statystyki są eksportowane i importowane do oryginalnej tabeli.
W tym przypadku jest to tabela z 200 wierszami z datami innymi niż NULL i 1 wierszem zawierającym wartości NULL. Dodatkowo na tej tabeli znajduje się indeks, który odpowiada indeksowi, który ma złe wartości histogramu.
Nazwa tabeli to tblTripsScheduled . Ma indeks nieklastrowy na (id, TheTripDate) i indeks klastrowy na TheTripDate . Istnieje kilka innych kolumn, ale ważne są tylko te, które są uwzględnione w indeksie.
Utwórz tabelę (tabelę tymczasową, jeśli chcesz), która naśladuje tabelę i indeks. Tabela i indeks wyglądają tak:
CREATE TABLE #tbltripsscheduled_cix_tripsscheduled(
id INT NOT NULL
, tripdate DATETIME NOT NULL
, PRIMARY KEY NONCLUSTERED(id, tripdate)
);
CREATE CLUSTERED INDEX thetripdate ON #tbltripsscheduled_cix_tripsscheduled(tripdate);
Następnie tabelę należy wypełnić 200 wierszami danych, na których powinny opierać się statystyki. W mojej sytuacji jest to dzień do następnych sześćdziesięciu dni. Ostatnie i późniejsze 60 dni są wypełniane „losowym” wyborem co 10 dni. (cnt wartość w CTE jest wartością debugowania. Nie odgrywa roli w ostatecznych wynikach). Kolejność malejąca dla rn kolumna zapewnia uwzględnienie 60 dni, a następnie jak największej części przeszłości.
DECLARE @date DATETIME = '20151104';
WITH tripdates
AS
(
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE NOT thetripdate BETWEEN @date AND @date
AND thetripdate < DATEADD(DAY, 60, @date) --only look 60 days out GROUP BY thetripdate
HAVING DATEDIFF(DAY, 0, thetripdate) % 10 = 0
UNION ALL
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE thetripdate BETWEEN @date AND DATEADD(DAY, 60, @date)
GROUP BY thetripdate
),
tripdate_top_200
AS
(
SELECT *
FROM
(
SELECT *, ROW_NUMBER() OVER(ORDER BY thetripdate DESC) rn
FROM tripdates
) td
WHERE rn <= 200
)
INSERT #tbltripsscheduled_cix_tripsscheduled (id, tripdate)
SELECT t.tripid, t.thetripdate
FROM tripdate_top_200 tp
INNER JOIN dbo.tbltripsscheduled t ON t.thetripdate = tp.thetripdate;
Nasza tabela jest teraz wypełniona wszystkimi wierszami, które są wartościowe dla użytkownika w danym dniu, oraz wybranymi wierszami historycznymi. Jeśli kolumna TheTripdate był nullable, wstawka zawierałaby również następujące elementy:
UNION ALL SELECT id, thetripdate FROM dbo.tbltripsscheduled WHERE thetripdate IS NULL;
Następnie aktualizujemy statystyki indeksu naszej tabeli tymczasowej.
UPDATE STATISTICS #tbltrips_IX_tbltrips_tripdates (tripdates) WITH FULLSCAN;
Teraz wyeksportuj te statystyki do tabeli tymczasowej. Ten stół wygląda tak. Dopasowuje dane wyjściowe DBCC SHOW_STATISTICS WITH HISTOGRAM .
CREATE TABLE #stats_with_stream
(
stream VARBINARY(MAX) NOT NULL
, rows INT NOT NULL
, pages INT NOT NULL
);
DBCC SHOW_STATISTICS posiada opcję eksportu statystyk jako strumienia. To jest ten strumień, którego chcemy. Ten strumień jest również tym samym strumieniem, co UPDATE STATISTICS używa opcji strumienia. Aby to zrobić:
INSERT INTO #stats_with_stream --SELECT * FROM #stats_with_stream
EXEC ('DBCC SHOW_STATISTICS (N''tempdb..#tbltripsscheduled_cix_tripsscheduled'', thetripdate)
WITH STATS_STREAM,NO_INFOMSGS'); Ostatnim krokiem jest utworzenie kodu SQL, który aktualizuje statystyki naszej tabeli docelowej, a następnie wykonanie go.
DECLARE @sql NVARCHAR(MAX);
SET @sql = (SELECT 'UPDATE STATISTICS tbltripsscheduled(cix_tbltripsscheduled) WITH
STATS_STREAM = 0x' + CAST('' AS XML).value('xs:hexBinary(sql:column("stream"))',
'NVARCHAR(MAX)') FROM #stats_with_stream );
EXEC (@sql); W tym momencie zastąpiliśmy histogram naszym niestandardowym. Możesz zweryfikować, sprawdzając histogram:
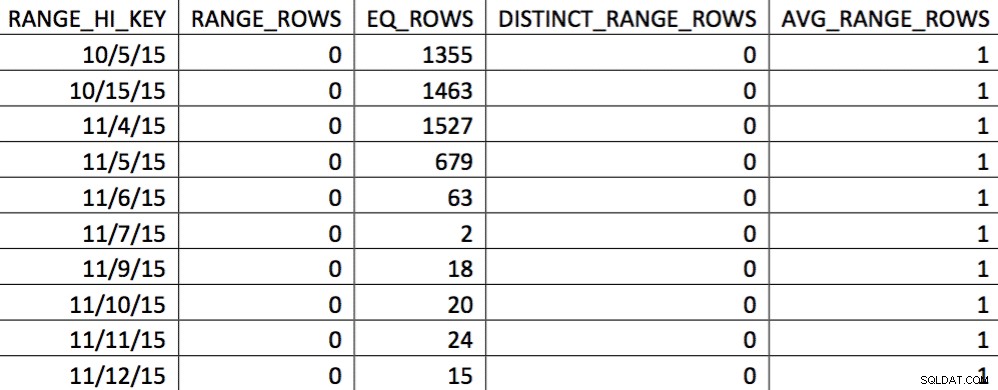
W tym wyborze danych z dnia 04.11 są reprezentowane wszystkie dni od dnia 04.11, a dane historyczne są reprezentowane i dokładne. Wracając do pokazanej wcześniej części planu zapytań, można zauważyć, że optymalizator dokonał lepszego wyboru na podstawie poprawionych statystyk:
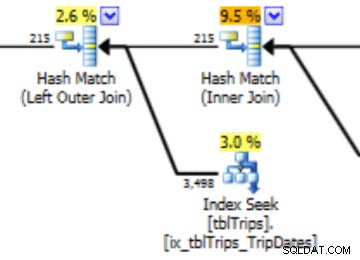
Importowane statystyki mają korzystny wpływ na wydajność. Koszt obliczenia statystyk znajduje się w tabeli „offline”. Jedynym przestojem dla tabeli produkcyjnej jest czas trwania importu strumienia.
Ten proces wykorzystuje nieudokumentowane funkcje i wygląda na to, że może być niebezpieczny, ale pamiętaj, że można łatwo cofnąć:zestawienie statystyk aktualizacji. Jeśli coś pójdzie nie tak, statystyki można zawsze zaktualizować za pomocą standardowego T-SQL.
Zaplanowanie regularnego uruchamiania tego kodu może znacznie pomóc optymalizatorowi w tworzeniu lepszych planów, biorąc pod uwagę zestaw danych, który zmienia się w punkcie krytycznym, ale nie na tyle, aby uruchomić aktualizację statystyk.
Kiedy skończyłem pierwszą wersję roboczą tego artykułu, liczba wierszy w tabeli na pierwszym wykresie zmieniła się z 217 na 717. To jest zmiana o 300%. To wystarczy, aby zmienić zachowanie optymalizatora, ale nie wystarczy, aby uruchomić aktualizację statystyk. Ta zmiana danych pozostawiłaby zły plan. Ten problem został rozwiązany dzięki opisanemu tutaj procesowi.
Referencje:
- AKTUALIZUJ STATYSTYKI (książki online)
- Dokument statystyczny SQL 2008
- Wyszukiwanie punktu krytycznego