Przed przejściem przez problem z wydajnością przekazanych rekordów i jego rozwiązaniem, musimy przejrzeć strukturę tabel SQL Server.
Przegląd struktury tabeli
W SQL Server podstawową jednostką przechowywania danych są strony 8 KB . Każda strona zaczyna się od 96-bajtowego nagłówka, który przechowuje informacje systemowe o tej stronie. Następnie wiersze tabeli będą przechowywane na stronach danych szeregowo po nagłówku. Na końcu strony tabela przesunięć wierszy, która zawiera jeden wpis dla każdego wiersza, będzie przechowywana naprzeciwko kolejności wierszy na stronie. Ten wpis przesunięcia wiersza pokazuje, jak daleko od początku strony znajduje się pierwszy bajt tego wiersza.
SQL Server udostępnia nam dwa rodzaje tabel, oparte na strukturze tej tabeli. Klastrowany Tabela przechowuje i sortuje dane na stronach danych na podstawie wstępnie zdefiniowanych kolumn lub wartości kolumn klucza indeksu klastrowanego. Ponadto strony danych w tabeli klastrowanej są sortowane i łączone ze sobą na połączonej liście na podstawie wartości klucza indeksu klastrowanego. drzewo B Struktura indeksu klastrowego zapewnia szybką metodę dostępu do danych w oparciu o wartości klucza indeksu klastrowego. W przypadku wstawienia nowego wiersza lub zaktualizowania istniejącej wartości klucza w tabeli klastrowanej program SQL Server przechowa nową wartość w prawidłowej pozycji logicznej, która pasuje do rozmiaru wstawionego wiersza bez naruszania kryteriów porządkowania. Jeśli wstawiona lub zaktualizowana wartość jest większa niż dostępne miejsce na stronie danych, strona zostanie podzielona na dwie strony, aby dopasować się do nowej wartości.
Drugi typ tabel to Stos tabeli, w której dane nie są sortowane na stronach danych w dowolnej kolejności, a strony nie są ze sobą połączone, ponieważ w tej tabeli nie ma zdefiniowanego indeksu klastrowego, aby wymusić jakiekolwiek kryteria sortowania. Śledzenie stron, które nie są posortowane według żadnych kryteriów porządkowania lub połączone ze sobą w tabeli sterty, nie jest łatwą misją. Aby uprościć proces śledzenia alokacji stron w tabeli sterty, SQL Server używa Mapy alokacji indeksu (IAM), jedyne logiczne połączenie między stronami danych w tablicy sterty, przez utrzymywanie wpisu dla każdej strony danych w tablicy lub indeksu w tablicy IAM. Aby pobrać dowolne dane z tabeli sterty, SQL Server Engine skanuje uprawnienia w celu zlokalizowania zakresu, który tworzy 8 stron przechowujących żądane dane.
Problem z przekazanymi rekordami
Jeśli nowy wiersz zostanie wstawiony do tabeli sterty, SQL Server Engine przeskanuje Puste wolne miejsce (PFS) do śledzenia stanu alokacji i wykorzystania miejsca na każdej stronie danych w celu znalezienia pierwszej dostępnej lokalizacji na stronach danych, która pasuje do wstawionego rozmiaru wiersza. Następnie wiersz zostanie dodany do wybranej strony. Jeśli wstawiona wartość jest większa niż dostępne miejsce na stronach danych, nowa strona zostanie dodana do tej tabeli, aby móc wstawić nową wartość.
Z drugiej strony, jeśli istniejące dane w tabeli sterty zostaną zmodyfikowane, na przykład zaktualizowaliśmy łańcuch o zmiennej długości o większy rozmiar danych, a aktualna przestrzeń nie pasuje do nowych danych, dane zostaną przeniesione do innego fizycznego lokalizacja i przekazany rekord zostanie wstawiony do tabeli sterty w oryginalnej lokalizacji danych, aby wskazać nową lokalizację tych danych i uprościć lokalizację danych śledzenia. Nowa lokalizacja danych zawiera również wskaźnik wskazujący na wskaźnik przekazywania, aby zachować jego aktualność w przypadku przeniesienia danych z nowej lokalizacji i zapobiec długiemu łańcuchowi wskaźników przekazywania lub go usunąć. Może to również prowadzić do usunięcia rekordu przekazywania.
Chociaż metoda przekierowania Forwarded Records zmniejsza potrzebę operacji odbudowy tabel i indeksów nieklastrowanych intensywnie korzystających z zasobów w celu aktualizowania adresów danych za każdym razem, gdy zmienia się lokalizacja danych, podwaja również liczbę odczytów wymaganych do pobrania danych. SQL Server najpierw odwiedzi starą lokalizację, gdzie znajdzie przekazany rekord, który przekierowuje go do nowej lokalizacji danych. Następnie odczyta żądane dane, dwukrotnie wykonując operację odczytu. Ponadto problem Forwarded Records prowadzi do zmiany danych sekwencyjnych w odczytywanych danych losowych, co negatywnie wpływa na wydajność operacji pobierania danych w czasie.
Stwórzmy następującą stertę ForwardRecordDemo tabeli za pomocą poniższej instrukcji T-SQL CREATE TABLE:
CREATE TABLE ForwardRecordDemo ( ID INT IDENTITY (1,1), Emp_Name NVARCHAR (50), Emp_BirthDate DATETIME, Emp_Salary INT )
Następnie wypełnij tę tabelę rekordami 3K do celów testowych, używając poniższej instrukcji INSERT INTO T-SQL:
INSERT INTO ForwardRecordDemo VALUES ('John','2000-05-05',500)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Zaid','1999-01-07',700)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Frank','1988-07-04',900)
GO 1000 Identyfikacja problemu z przekazanymi rekordami
Informacje o typie tabeli i liczbie stron zużywanych podczas przechowywania danych tabeli, a także procent fragmentacji indeksu i liczbę przekazanych rekordów dla określonej tabeli można wyświetlić, wysyłając zapytanie do sys.dm_db_index_physical_stats funkcja dynamicznego zarządzania systemem i przechodząc do SZCZEGÓŁOWYCH tryb, aby zwrócić liczbę rekordów przekazywania. Aby to zrobić, użyj poniższego skryptu T-SQL:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Jak widać z wyniku zapytania, poprzednia tabela jest tabelą sterty, w której nie utworzono indeksu klastrowego w celu sortowania danych na stronach i łączenia stron między sobą. Wiersze 3K wstawione do tabeli są przypisane do 15 strony danych, bez przekazanych rekordów i zerowego procentu fragmentacji, jak pokazano w poniższym wyniku:

Gdy definiujesz typ danych kolumny jako VARCHAR lub NVARCHAR, wartość określona w definicji typu danych jest maksymalnym dozwolonym rozmiarem dla tego ciągu, bez pełnego rezerwowania tej ilości podczas zapisywania wartości na stronach danych. Na przykład Jan imię i nazwisko pracownika wstawione do tej tabeli zarezerwuje tylko 8 bajtów z maksymalnie 100 bajtów dla tej kolumny, biorąc pod uwagę, że zapisanie ciągu NVARCHAR podwoi liczbę bajtów wymaganych dla kolumny VARCHAR, jak pokazano w DATALENGTH wynik funkcji poniżej:
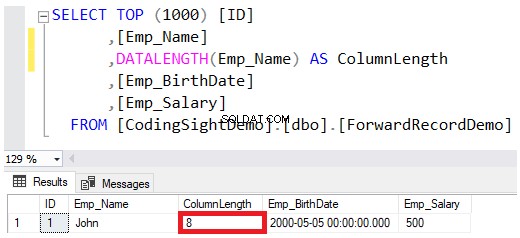
Jeśli chcesz zaktualizować wartość kolumny Emp_Name, aby uwzględnić pełne imię i nazwisko pracownika Jana, użyj poniższego oświadczenia UPDATE:
UPDATE ForwardRecordDemo SET Emp_Name='John David Micheal' WHERE Emp_Name='John'
Sprawdź długość zaktualizowanej kolumny za pomocą DATALENGTH funkcjonować. Zobaczysz, że długość kolumny Emp_Name w zaktualizowanych wierszach została rozszerzona o 28 bajtów na każdą kolumnę, czyli około 3,5 dodatkowe strony danych do tej tabeli, jak pokazano w poniższym wyniku:
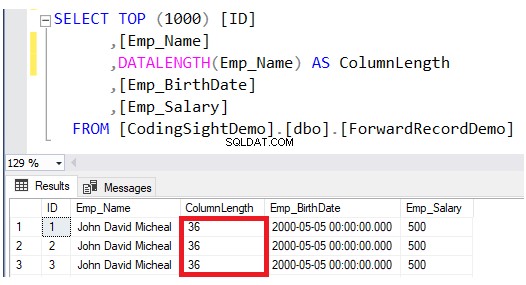
Następnie sprawdź liczbę przekazanych rekordów po operacji aktualizacji, wysyłając zapytanie do funkcji dynamicznego zarządzania systemu sys.dm_db_index_physical_stats. Aby to zrobić, użyj poniższego skryptu T-SQL:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Jak widać, zaktualizowanie kolumny Emp_Name w rekordach 1 tys. większymi wartościami ciągu bez dodawania nowego rekordu spowoduje przypisanie dodatkowych 5 stron do tej tabeli, a nie 3,5 strony, jak oczekiwano wcześniej. Stanie się tak z powodu wygenerowania 484 przekazane rekordy, aby wskazać nowe lokalizacje przeniesionych danych. Może to spowodować, że tabela będzie wynosić 33% pofragmentowane, jak pokazano wyraźnie poniżej:

Ponownie, jeśli uda Ci się zaktualizować wartość kolumny Emp_Name, aby zawierała pełne imię i nazwisko pracownika Zaid, użyj poniższego oświadczenia UPDATE:
UPDATE ForwardRecordDemo SET Emp_Name='Zaid Fuad Zreeq' WHERE Emp_Name='Zaid'
Sprawdź długość zaktualizowanej kolumny za pomocą DATALENGTH funkcjonować. Zobaczysz, że długość kolumny Emp_Name w zaktualizowanych wierszach została powiększona o 22 bajtów na każdą kolumnę, czyli około 2,7 dodatkowe strony danych dodane do tej tabeli, jak pokazano w poniższym wyniku:
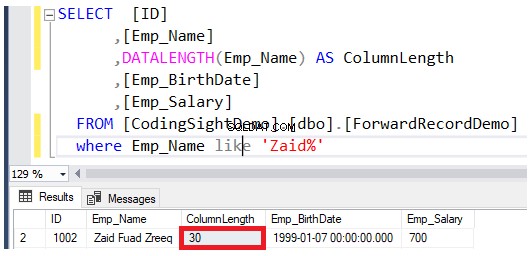
Sprawdź liczbę przekazanych rekordów po wykonaniu operacji aktualizacji. Możesz to zrobić, wysyłając zapytanie do funkcji dynamicznego zarządzania systemem sys.dm_db_index_physical_stats przy użyciu tego samego skryptu T-SQL poniżej:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Wynik pokaże, że zaktualizowanie kolumny Emp_Name w innych rekordach 1 tys. z większymi wartościami ciągu bez wstawiania nowego wiersza spowoduje przypisanie kolejnych 4 stron do tej tabeli, zamiast 2,7 stron zgodnie z oczekiwaniami. Stanie się tak z powodu wygenerowania dodatkowych 417 przekazane rekordy w celu wskazania nowych lokalizacji przeniesionych danych i utrzymania tych samych 33% procent fragmentacji, jak pokazano poniżej:

Naprawianie problemu z przekazanymi rekordami
Najprostszym sposobem rozwiązania problemu z przekazanymi rekordami jest oszacowanie maksymalnej długości ciągu, który będzie przechowywany w kolumnie i przypisanie go przy użyciu stałej długości typ danych dla tej kolumny zamiast używania typu danych o zmiennej długości. Optymalnym trwałym sposobem rozwiązania problemu z przekazanymi rekordami jest dodanie indeksu klastrowego do tego stołu. W ten sposób tabela zostanie całkowicie przekonwertowana na tabelę klastrową, która jest sortowana na podstawie wartości klucza indeksu klastrowanego. Będzie kontrolować kolejność istniejących danych, nowo wstawionych i zaktualizowanych danych, które nie pasują do aktualnie dostępnego miejsca na stronie danych, jak opisano wcześniej we wstępie do tego artykułu.
Jeśli dodanie indeksu klastrowego do tej tabeli nie jest opcją dla określonych wymagań, takich jak tabele pomostowe lub tabele ETL, można tymczasowo rozwiązać problem z przekazanymi rekordami, monitorując przekazane rekordy i odbudowując tabelę sterty w celu jej usunięcia, co spowoduje zaktualizować również wszystkie indeksy nieklastrowane w tej tabeli sterty. Funkcjonalność przebudowy tabeli sterty została wprowadzona w SQL Server 2008 za pomocą ALTER TABLE…REBUILD Polecenie T-SQL.
Aby zobaczyć wpływ przekazanych rekordów na wydajność zapytań dotyczących pobierania danych, uruchom zapytanie SELECT, które przeprowadza wyszukiwanie w oparciu o wartości kolumny Emp_Nameю Jednak przed wykonaniem zapytania włącz statystyki TIME i IO:
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
W rezultacie zobaczysz, że 925 operacje odczytu logicznego są wykonywane w celu pobrania żądanych danych w ciągu 84ms jak pokazano poniżej:

Aby odbudować tabelę sterty w celu usunięcia wszystkich przekazanych rekordów, użyj polecenia ALTER TABLE…REBUILD:
ALTER TABLE ForwardRecordDemo REBUILD;
Uruchom tę samą instrukcję SELECT ponownie:
SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
Statystyki TIME i IO pokażą Ci, że tylko 21 logiczne operacje odczytu w porównaniu z 925 operacje odczytu logicznego z dołączonymi przekazanymi rekordami są wykonywane w celu pobrania żądanych danych w ciągu 79ms :

Aby sprawdzić liczbę przekazanych rekordów po odbudowaniu tabeli sterty, uruchom funkcję dynamicznego zarządzania systemem sys.dm_db_index_physical_stats, użyj tego samego skryptu T-SQL poniżej:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Zobaczysz, że tylko 21 strony, z poprzednimi 3 strony wykorzystane przez Forwarded Records są przypisane do tej tabeli w celu przechowywania danych, co jest podobne do szacowanego wyniku, jaki otrzymaliśmy podczas operacji wstawiania i aktualizowania danych (15+3,5+2,7). Po odbudowaniu tabeli sterty wszystkie przekazane rekordy są teraz usuwane. W rezultacie mamy tabelę bez fragmentacji:

Problem z przekazanymi rekordami to ważny problem z wydajnością, który administratorzy bazy danych powinni wziąć pod uwagę podczas planowania utrzymanie stołu sterty. Poprzednie wyniki są pobierane z naszej tabeli testowej, która zawiera tylko rekordy 3K. Możesz sobie wyobrazić liczbę stron, które zostaną zmarnowane przez przekazane rekordy i pogorszenie wydajności we/wy z powodu odczytywania dużej liczby przekazanych rekordów podczas czytania z ogromnych tabel!
Referencje:
- Przewodnik po architekturze stron i zakresów
- dm_db_index_physical_stats (Transact-SQL)
- ZMIEŃ TABELĘ (Transact-SQL)
- Wiedza o „przekazanych rekordach” może pomóc zdiagnozować trudne do znalezienia problemy z wydajnością