 W moim ostatnim poście „Jeden sposób na uzyskanie indeksu wyszukiwania wiodącego symbolu wieloznacznego” wspomniałem, że potrzebowałby wyzwalaczy, aby poradzić sobie z utrzymaniem zalecanych przeze mnie fragmentów. Kilka osób skontaktowało się ze mną, aby zapytać, czy mogę zademonstrować te wyzwalacze.
W moim ostatnim poście „Jeden sposób na uzyskanie indeksu wyszukiwania wiodącego symbolu wieloznacznego” wspomniałem, że potrzebowałby wyzwalaczy, aby poradzić sobie z utrzymaniem zalecanych przeze mnie fragmentów. Kilka osób skontaktowało się ze mną, aby zapytać, czy mogę zademonstrować te wyzwalacze.
Upraszczając z poprzedniego wpisu, załóżmy, że mamy następujące tabele – zbiór firm, a następnie tabelę CompanyNameFragments, która pozwala na wyszukiwanie pseudo-wildcards w dowolnym podłańcuchu nazwy firmy:
CREATE TABLE dbo.Companies ( CompanyID int CONSTRAINT PK_Companies PRIMARY KEY, Name nvarchar(100) NOT NULL ); GO CREATE TABLE dbo.CompanyNameFragments ( CompanyID int NOT NULL, Fragment nvarchar(100) NOT NULL ); CREATE CLUSTERED INDEX CIX_CNF ON dbo.CompanyNameFragments(Fragment, CompanyID);
Biorąc pod uwagę tę funkcję generowania fragmentów (jedyną zmianą w stosunku do oryginalnego artykułu jest zwiększenie @input do obsługi 100 znaków):
CREATE FUNCTION dbo.CreateStringFragments( @input nvarchar(100) )
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
WITH x(x) AS
(
SELECT 1 UNION ALL SELECT x+1 FROM x WHERE x < (LEN(@input))
)
SELECT Fragment = SUBSTRING(@input, x, LEN(@input)) FROM x
);
GO Możemy stworzyć pojedynczy wyzwalacz, który obsłuży wszystkie trzy operacje:
CREATE TRIGGER dbo.Company_MaintainFragments
ON dbo.Companies
FOR INSERT, UPDATE, DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE f FROM dbo.CompanyNameFragments AS f
INNER JOIN deleted AS d
ON f.CompanyID = d.CompanyID;
INSERT dbo.CompanyNameFragments(CompanyID, Fragment)
SELECT i.CompanyID, fn.Fragment
FROM inserted AS i
CROSS APPLY dbo.CreateStringFragments(i.Name) AS fn;
END
GO Działa to bez sprawdzania, jaki rodzaj operacji miał miejsce, ponieważ:
- W przypadku UPDATE lub DELETE nastąpi DELETE – w przypadku UPDATE nie będziemy zawracać sobie głowy próbami dopasowania fragmentów, które pozostaną takie same; po prostu rozwalimy je wszystkie, żeby można je było zastępować masowo. W przypadku INSERT instrukcja DELETE nie przyniesie efektu, ponieważ w
deletednie będzie wierszy . - W przypadku INSERT lub UPDATE nastąpi INSERT. W przypadku DELETE instrukcja INSERT nie przyniesie efektu, ponieważ w
insertednie będzie wierszy .
Teraz, aby upewnić się, że to działa, zróbmy kilka zmian w Companies tabeli, a następnie sprawdź nasze dwa stoły.
-- First, let's insert two companies -- (table contents after insert shown in figure 1 below) INSERT dbo.Companies(Name) VALUES(N'Banana'), (N'Acme Corp'); -- Now, let's update company 2 to 'Orange' -- (table contents after update shown in figure 2 below): UPDATE dbo.Companies SET Name = N'Orange' WHERE CompanyID = 2; -- Finally, delete company #1 -- (table contents after delete shown in figure 3 below): DELETE dbo.Companies WHERE CompanyID = 1;
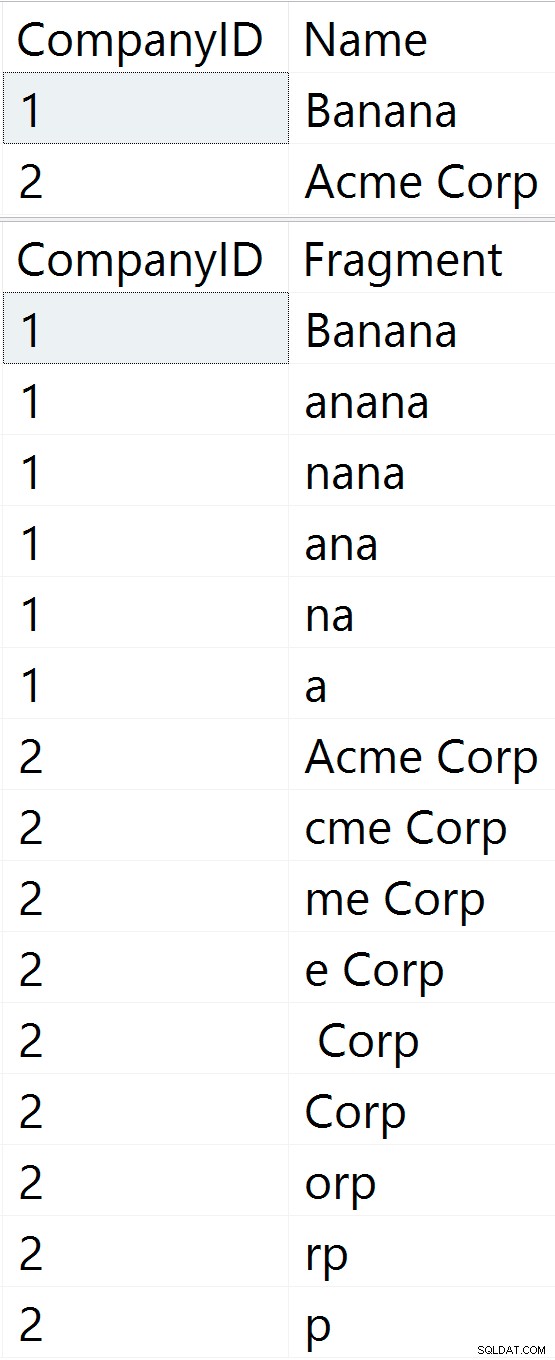 Rysunek 1: Początkowa zawartość tabeli Rysunek 1: Początkowa zawartość tabeli | 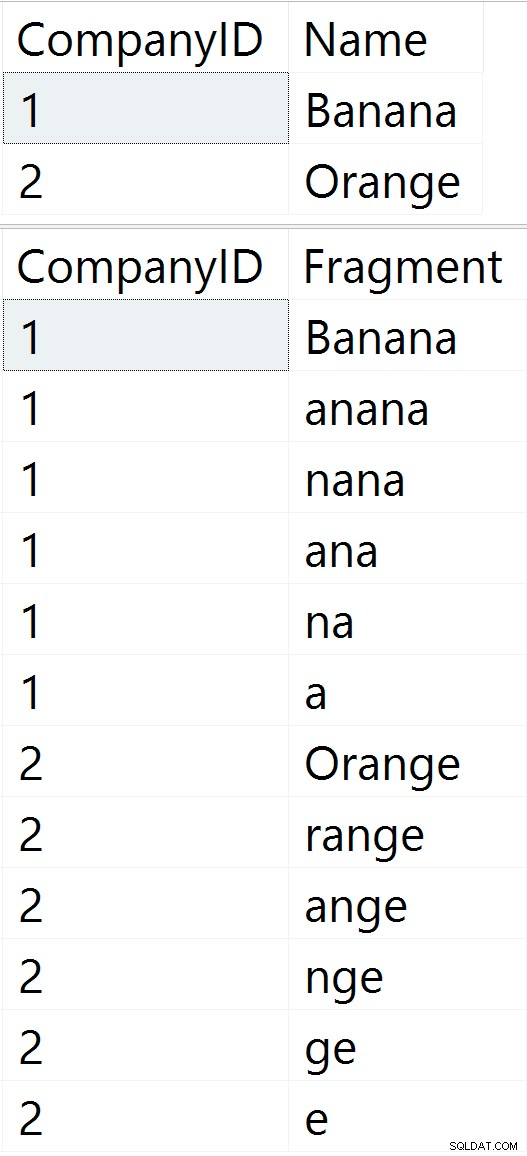 Rysunek 2: Zawartość tabeli po aktualizacji Rysunek 2: Zawartość tabeli po aktualizacji | 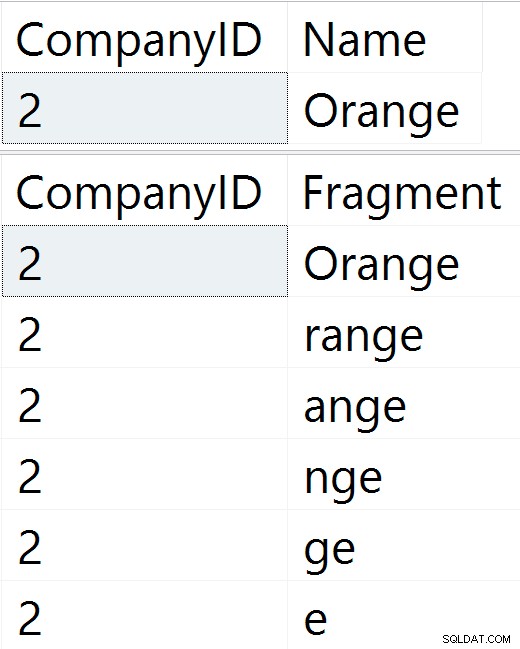 Rysunek 3: Zawartość tabeli po usunięciu Rysunek 3: Zawartość tabeli po usunięciu |
Zastrzeżenie (dla osób zajmujących się uczciwością referencyjną)
Zauważ, że jeśli ustawisz odpowiednie klucze obce między tymi dwiema tabelami, będziesz musiał użyć zamiast wyzwalacza do obsługi usuwania, w przeciwnym razie będziesz mieć problem z kurczakiem i jajkiem – nie możesz czekać, aż *po* rodzicu wiersz jest usuwany, aby usunąć wiersze podrzędne. Musisz więc ustawić ON DELETE CASCADE (którego osobiście nie lubię) lub dwa wyzwalacze wyglądałyby tak (wyzwalacz po nadal musiałby wykonać parę DELETE/INSERT w przypadku UPDATE):
CREATE TRIGGER dbo.Company_DeleteFragments
ON dbo.Companies
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE f FROM dbo.CompanyNameFragments AS f
INNER JOIN deleted AS d
ON f.CompanyID = d.CompanyID;
DELETE c FROM dbo.Companies AS c
INNER JOIN deleted AS d
ON c.CompanyID = d.CompanyID;
END
GO
CREATE TRIGGER dbo.Company_MaintainFragments
ON dbo.Companies
FOR INSERT, UPDATE
AS
BEGIN
SET NOCOUNT ON;
DELETE f FROM dbo.CompanyNameFragments AS f
INNER JOIN deleted AS d
ON f.CompanyID = d.CompanyID;
INSERT dbo.CompanyNameFragments(CompanyID, Fragment)
SELECT i.CompanyID, fn.Fragment
FROM inserted AS i
CROSS APPLY dbo.CreateStringFragments(i.Name) AS fn;
END
GO Podsumowanie
Ten post miał na celu pokazanie, jak łatwo jest skonfigurować wyzwalacze, które utrzymają wyszukiwalne fragmenty ciągów w celu usprawnienia wyszukiwania symboli wieloznacznych, przynajmniej w przypadku ciągów o średniej wielkości. Teraz nadal wiem, że tego rodzaju pomysł wydaje się zwariowany, ale wciąż o tym mówię, ponieważ jestem przekonany, że istnieją dobre przypadki użycia.
W następnym poście pokażę, jak zobaczyć wpływ tego wyboru:Możesz łatwo skonfigurować reprezentatywne obciążenia, aby porównać koszty zasobów związane z utrzymywaniem fragmentów z oszczędnością wydajności w czasie wykonywania zapytania. Przyjrzę się różnym długościom ciągów, a także różnym równoważeniom obciążenia (głównie odczyt vs. głównie zapis) i spróbuję znaleźć idealne miejsca i niebezpieczne strefy.



