W 2014 roku napisałem artykuł o nazwie Performance Tuning the Whole Query Plan. Przyjrzano się sposobom znalezienia stosunkowo niewielkiej liczby odrębnych wartości z umiarkowanie dużego zbioru danych i doszło do wniosku, że rozwiązanie rekurencyjne może być optymalne. Ten wpis uzupełniający ponownie omawia pytanie dotyczące SQL Server 2019, używając większej liczby wierszy.
Środowisko testowe
Będę używał bazy danych Stack Overflow 2013 o pojemności 50 GB, ale wystarczy każda duża tabela z małą liczbą odrębnych wartości.
Będę szukał odrębnych wartości w BountyAmount kolumna dbo.Votes tabela, prezentowana w kolejności rosnącej kwoty bounty. Tabela Głosy ma prawie 53 miliony wierszy (dokładnie 52 928 720). Istnieje tylko 19 różnych kwot nagród, w tym NULL .
Baza danych Stack Overflow 2013 jest dostarczana bez indeksów nieklastrowanych, aby zminimalizować czas pobierania. W Id znajduje się klastrowany indeks klucza podstawowego kolumna dbo.Votes stół. Jest ustawiony na zgodność z SQL Server 2008 (poziom 100), ale zaczniemy od bardziej nowoczesnego ustawienia SQL Server 2017 (poziom 140):
ALTER DATABASE StackOverflow2013
SET COMPATIBILITY_LEVEL = 140;
Testy zostały przeprowadzone na moim laptopie przy użyciu SQL Server 2019 CU 2. Ta maszyna ma cztery procesory i7 (hiperwątkowość do 8) z podstawową prędkością 2,4 GHz. Posiada 32 GB pamięci RAM, z czego 24 GB dostępne dla instancji SQL Server 2019. Próg kosztu równoległości jest ustawiony na 50.
Każdy wynik testu reprezentuje najlepsze z dziesięciu przebiegów, ze wszystkimi wymaganymi danymi i stronami indeksu w pamięci.
1. Indeks klastrowy sklepu wierszowego
Aby ustawić linię bazową, pierwsze uruchomienie to zapytanie szeregowe bez żadnego nowego indeksowania (i pamiętaj, że jest to baza danych ustawiona na poziom zgodności 140):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (MAXDOP 1);
To skanuje indeks klastrowy i używa agregacji skrótu trybu wiersza w celu znalezienia odrębnych wartości BountyAmount :
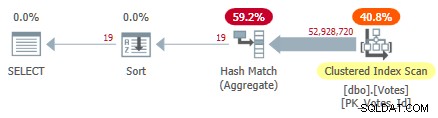 Serialowy plan indeksowania klastrowego
Serialowy plan indeksowania klastrowego
Zajmuje to 10 500 ms do ukończenia, używając tej samej ilości czasu procesora. Pamiętaj, że jest to najlepszy czas na dziesięć przebiegów ze wszystkimi danymi w pamięci. Automatycznie tworzone próbkowane statystyki dotyczące BountyAmount kolumny zostały utworzone przy pierwszym uruchomieniu.
Około połowa czasu, który upłynął, jest spędzana na skanowaniu indeksu klastrowego, a około połowa na agregacie Hash Match Aggregate. Sortowanie ma tylko 19 wierszy do przetworzenia, więc zajmuje tylko około 1 ms. Wszyscy operatorzy w tym planie używają wykonywania w trybie wierszowym.
Usuwanie MAXDOP 1 wskazówka podaje równoległy plan:
 Plan równoległego indeksowania klastrowego
Plan równoległego indeksowania klastrowego
Jest to plan, który optymalizator wybiera bez żadnych wskazówek w mojej konfiguracji. Zwraca wyniki w 4,200ms używając łącznie 32 800 ms procesora (w DOP 8).
2. Indeks nieklastrowany
Skanowanie całej tabeli, aby znaleźć tylko BountyAmount wydaje się nieefektywny, więc naturalne jest, aby spróbować dodać indeks nieklastrowany tylko w jednej kolumnie, której potrzebuje to zapytanie:
CREATE NONCLUSTERED INDEX b ON dbo.Votes (BountyAmount);
Tworzenie tego indeksu zajmuje trochę czasu (1m 40s). MAXDOP 1 zapytanie używa teraz Stream Aggregate, ponieważ optymalizator może używać indeksu nieklastrowanego do prezentowania wierszy w BountyAmount kolejność:
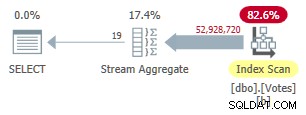 Szeregowy nieklastrowany plan trybu wierszy
Szeregowy nieklastrowany plan trybu wierszy
Działa to przez 9300ms (zużywa tyle samo czasu procesora). Przydatne ulepszenie w stosunku do oryginalnych 10500 ms, ale nie wstrząsające ziemią.
Usuwanie MAXDOP 1 wskazówka podaje równoległy plan z agregacją lokalną (na wątek):
 Równoległy nieklastrowy plan trybu wierszy
Równoległy nieklastrowy plan trybu wierszy
Wykonuje się to w 3400 ms przy użyciu 25 800 ms czasu procesora. Być może będziemy w stanie lepiej radzić sobie z kompresją wierszy lub stron w nowym indeksie, ale chcę przejść do bardziej interesujących opcji.
3. Tryb wsadowy w sklepie Row Store (BMOR)
Teraz ustaw bazę danych w trybie zgodności z SQL Server 2019, używając:
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 150;
Daje to optymalizatorowi swobodę wyboru trybu wsadowego w magazynie wierszowym, jeśli uzna to za warte zachodu. Może to zapewnić niektóre z zalet wykonywania w trybie wsadowym bez konieczności indeksowania magazynu kolumn. Aby uzyskać szczegółowe informacje techniczne i nieudokumentowane opcje, zobacz doskonały artykuł Dmitrija Pilugina na ten temat.
Niestety, optymalizator nadal wybiera wykonanie w trybie pełnego wiersza przy użyciu agregacji strumieni zarówno dla zapytań testowych, jak i równoległych. Aby uzyskać tryb wsadowy w planie wykonania sklepu wierszowego, możemy dodać wskazówkę, aby zachęcić do agregacji za pomocą dopasowania skrótu (który może działać w trybie wsadowym):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (HASH GROUP, MAXDOP 1); Daje nam to plan ze wszystkimi operatorami działającymi w trybie wsadowym:
 Serialowy tryb wsadowy w planie sklepu wierszowego
Serialowy tryb wsadowy w planie sklepu wierszowego
Wyniki są zwracane w 2600 ms (wszystkie procesory jak zwykle). To już jest szybsze niż równoległe plan trybu wiersza (upłynął 3400 ms) przy znacznie mniejszym wykorzystaniu procesora (2600 ms w porównaniu z 25 800 ms).
Usuwanie MAXDOP 1 wskazówka (ale zachowując HASH GROUP ) daje równoległy tryb wsadowy w planie magazynu wierszowego:
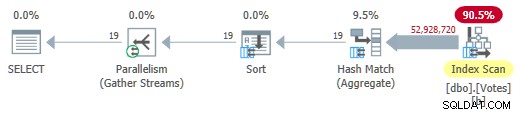 Równoległy tryb wsadowy w planie sklepu wierszowego
Równoległy tryb wsadowy w planie sklepu wierszowego
Działa to w zaledwie 725 ms przy użyciu procesora 5700 ms.
4. Tryb wsadowy w sklepie kolumnowym
Wynik równoległego trybu wsadowego w sklepie rzędowym jest imponującą poprawą. Możemy zrobić jeszcze lepiej, zapewniając reprezentację danych w magazynie kolumnowym. Aby wszystko inne pozostało bez zmian, dodam nieklastrowany indeks sklepu kolumn tylko na tej kolumnie, której potrzebujemy:
CREATE NONCLUSTERED COLUMNSTORE INDEX nb ON dbo.Votes (BountyAmount);
Jest on wypełniany z istniejącego nieklastrowego indeksu b-drzewa, a jego utworzenie zajmuje tylko 15 sekund.
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY V.BountyAmount
OPTION (MAXDOP 1); Optymalizator wybiera pełny plan trybu wsadowego, w tym skanowanie indeksu magazynu kolumn:
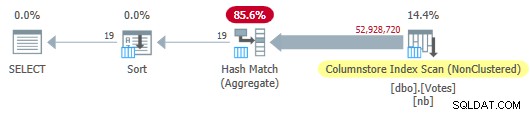 Plan magazynu kolumn szeregowych
Plan magazynu kolumn szeregowych
Działa to w 115 ms używając tej samej ilości czasu procesora. Optymalizator wybiera ten plan bez żadnych wskazówek dotyczących konfiguracji mojego systemu, ponieważ szacowany koszt planu jest poniżej progu kosztu równoległości .
Aby uzyskać plan równoległy, możemy obniżyć próg kosztów lub skorzystać z nieudokumentowanej podpowiedzi:
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (USE HINT ('ENABLE_PARALLEL_PLAN_PREFERENCE')); W każdym razie plan równoległy to:
 Plan magazynu kolumn równoległych
Plan magazynu kolumn równoległych
Czas, jaki upłynął od zapytania, został teraz skrócony do 30 ms , zużywając 210 ms procesora.
5. Tryb wsadowy w sklepie kolumnowym z przyciskiem w dół
Obecny najlepszy czas wykonania wynoszący 30 ms jest imponujący, zwłaszcza w porównaniu z oryginalnymi 10 500 ms. Niemniej jednak trochę szkoda, że musimy przekazać prawie 53 miliony wierszy (w 58 868 partiach) ze skanowania do agregatu Hash Match Aggregate.
Byłoby dobrze, gdyby SQL Server mógł zepchnąć agregację w dół do skanowania i po prostu zwrócić różne wartości bezpośrednio z magazynu kolumn. Możesz pomyśleć, że musimy wyrazić DISTINCT jako GROUP BY aby uzyskać Grouped Aggregate Pushdown, ale jest to logicznie nadmiarowe, a nie cała historia.
Przy obecnej implementacji SQL Server musimy faktycznie obliczyć agregację aby aktywować agregację pushdown. Co więcej, musimy używać zagregowany wynik jakoś lub optymalizator po prostu usunie go jako niepotrzebny.
Jednym ze sposobów napisania zapytania w celu osiągnięcia agregacji pushdown jest dodanie logicznie nadmiarowego dodatkowego wymagania porządkowania:
SELECT
V.BountyAmount
FROM dbo.Votes AS V
GROUP BY
V.BountyAmount
ORDER BY
V.BountyAmount,
COUNT_BIG(*) -- New!
OPTION (MAXDOP 1); Plan seryjny to teraz:
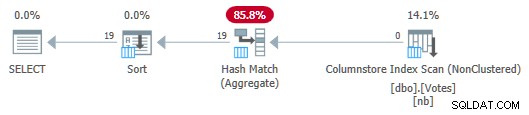 Plan magazynu kolumn szeregowych z funkcją Aggregate Push Down
Plan magazynu kolumn szeregowych z funkcją Aggregate Push Down
Zauważ, że żadne wiersze nie są przekazywane ze Skanowania do Agregatu! Pod okładkami częściowe agregaty BountyAmount wartości i powiązane z nimi liczby wierszy są przekazywane do agregatu Hash Match Aggregate, który sumuje agregaty częściowe, tworząc wymaganą agregację końcową (globalną). Jest to bardzo wydajne, co potwierdza czas, który upłynął 13ms (z których wszystko to czas procesora). Przypominamy, że poprzedni plan szeregowy trwał 115 ms.
Aby skompletować zestaw, możemy otrzymać wersję równoległą w taki sam sposób jak poprzednio:
 Plan magazynu kolumn równoległych z funkcją Aggregate Push Down
Plan magazynu kolumn równoległych z funkcją Aggregate Push Down
Działa to przez 7ms używając łącznie 40 ms procesora.
To wstyd, że musimy obliczyć i użyć agregatu, którego nie potrzebujemy tylko po to, aby przesunąć w dół. Być może w przyszłości zostanie to ulepszone, aby DISTINCT i GROUP BY bez agregatów można zepchnąć w dół do skanowania.
6. Rekurencyjne wyrażenie tabelowe w trybie wiersza
Na początku obiecałem wrócić do rozwiązania rekursywnego CTE używanego do znajdowania małej liczby duplikatów w dużym zbiorze danych. Implementacja obecnego wymagania przy użyciu tej techniki jest dość prosta, chociaż kod jest z konieczności dłuższy niż wszystko, co widzieliśmy do tej pory:
WITH R AS
(
-- Anchor
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH FIRST 1 ROW ONLY
UNION ALL
-- Recursive
SELECT
Q1.BountyAmount
FROM
(
SELECT
V.BountyAmount,
rn = ROW_NUMBER() OVER (
ORDER BY V.BountyAmount ASC)
FROM R
JOIN dbo.Votes AS V
ON V.BountyAmount > ISNULL(R.BountyAmount, -1)
) AS Q1
WHERE
Q1.rn = 1
)
SELECT
R.BountyAmount
FROM R
ORDER BY
R.BountyAmount ASC
OPTION (MAXRECURSION 0); Pomysł ma swoje korzenie w tak zwanym przeskakiwaniu indeksu:znajdujemy najniższą interesującą wartość na początku indeksu b-drzewa w kolejności rosnącej, a następnie szukamy następnej wartości w kolejności indeksu i tak dalej. Struktura indeksu b-drzewa sprawia, że znalezienie następnej najwyższej wartości jest bardzo wydajne — nie ma potrzeby skanowania duplikatów.
Jedyną prawdziwą sztuczką jest przekonanie optymalizatora, aby pozwolił nam użyć TOP w „rekurencyjnej” części CTE, aby zwrócić jedną kopię każdej odrębnej wartości. Proszę zapoznać się z moim poprzednim artykułem, jeśli potrzebujesz odświeżenia szczegółów.
Plan wykonania (opisany ogólnie przez Craiga Freedmana tutaj) to:
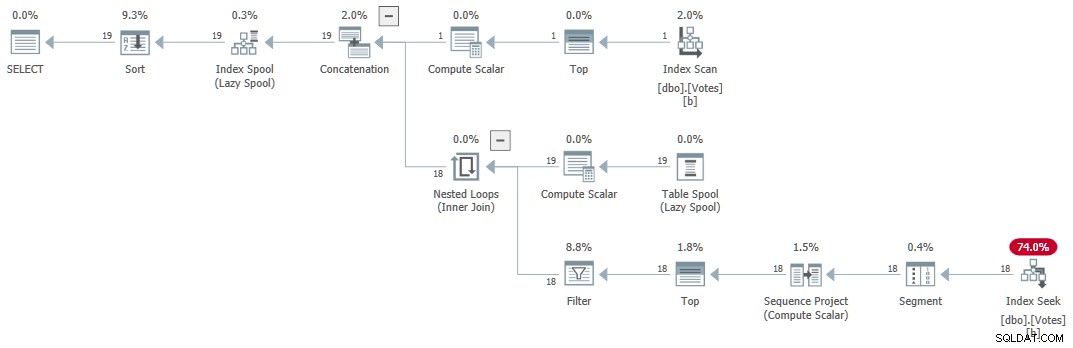 Szeregowe rekurencyjne CTE
Szeregowe rekurencyjne CTE
Zapytanie zwraca poprawne wyniki w ciągu 1ms używając 1 ms procesora, zgodnie z Sentry One Plan Explorer.
7. Iteracyjny T-SQL
Podobną logikę można wyrazić za pomocą WHILE pętla. Kod może być łatwiejszy do odczytania i zrozumienia niż rekurencyjne CTE. Pozwala to również uniknąć używania sztuczek w celu obejścia wielu ograniczeń rekurencyjnej części CTE. Wydajność jest konkurencyjna przy około 15 ms. Ten kod służy do zainteresowania i nie jest uwzględniony w tabeli podsumowania wyników.
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @Result table
(
BountyAmount integer NULL UNIQUE CLUSTERED
);
DECLARE @BountyAmount integer;
-- First value in index order
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
-- Next higher value
WHILE @@ROWCOUNT > 0
BEGIN
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
WHERE
V.BountyAmount > ISNULL(@BountyAmount, -1)
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
END;
-- Accumulated results
SELECT
R.BountyAmount
FROM @Result AS R
ORDER BY
R.BountyAmount; Tabela podsumowania skuteczności
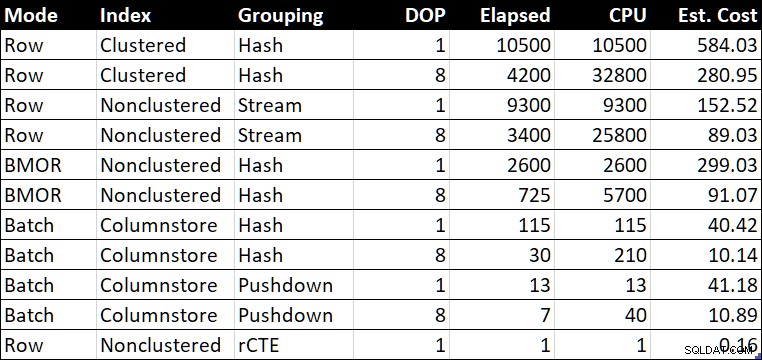 Tabela podsumowania wydajności (czas trwania/procesor w milisekundach)
Tabela podsumowania wydajności (czas trwania/procesor w milisekundach)
„Szac. Koszt” pokazuje szacunkowy koszt optymalizatora dla każdego zapytania, zgodnie z raportem w systemie testowym.
Ostateczne myśli
Znalezienie niewielkiej liczby odrębnych wartości może wydawać się dość specyficznym wymaganiem, ale na przestrzeni lat spotykałem się z nimi dość często, zwykle w ramach dostrajania większego zapytania.
Ostatnie kilka przykładów miało dość zbliżone wyniki. Wiele osób byłoby zadowolonych z dowolnego wyniku poniżej drugiego, w zależności od priorytetów. Nawet wynik 2600 ms w trybie wsadowym w trybie seryjnym w sklepie rzędowym wypada dobrze w porównaniu z najlepszym równoległym plany trybu wierszowego, które dobrze wróżą znacznemu przyspieszeniu poprzez samo uaktualnienie do SQL Server 2019 i włączenie poziomu zgodności bazy danych 150. Nie każdy będzie mógł szybko przejść do magazynu kolumnowego, a i tak nie zawsze będzie to właściwe rozwiązanie . Tryb wsadowy w magazynie wierszy zapewnia zgrabny sposób na osiągnięcie niektórych korzyści możliwych w przypadku przechowywania kolumn, zakładając, że możesz przekonać optymalizatora, aby zdecydował się go użyć.
Zagregowana kolumna sklepu z równoległymi kolumnami przesuń w dół wynik 57 milionów wierszy przetworzone w 7ms (przy użyciu 40 ms procesora) jest niezwykłe, szczególnie biorąc pod uwagę sprzęt. Szeregowy wynik zagregowania w dół 13ms jest równie imponująca. Byłoby wspaniale, gdybym nie musiał dodawać bezsensownego zbiorczego wyniku, aby uzyskać te plany.
Dla tych, którzy nie mogą jeszcze przejść do SQL Server 2019 lub magazynu kolumnowego, rekursywne CTE jest nadal opłacalnym i wydajnym rozwiązaniem, gdy istnieje odpowiedni indeks b-drzewa, a liczba potrzebnych odrębnych wartości jest dość niewielka. Byłoby fajnie, gdyby SQL Server mógł uzyskać dostęp do takiego b-drzewa bez konieczności pisania rekurencyjnego CTE (lub równoważnego iteracyjnego kodu T-SQL zapętlonego przy użyciu WHILE ).
Innym możliwym rozwiązaniem problemu jest utworzenie widoku indeksowanego. Zapewni to wyraźne wartości z dużą wydajnością. Wadą, jak zwykle, jest to, że każda zmiana w tabeli bazowej będzie wymagała aktualizacji liczby wierszy przechowywanych w zmaterializowanym widoku.
Każde z przedstawionych tutaj rozwiązań ma swoje miejsce w zależności od wymagań. Posiadanie szerokiej gamy dostępnych narzędzi jest ogólnie rzecz biorąc dobrą rzeczą podczas dostrajania zapytań. W większości przypadków wybrałbym jedno z rozwiązań w trybie wsadowym, ponieważ ich wydajność będzie dość przewidywalna bez względu na liczbę obecnych duplikatów.