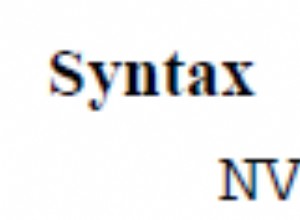Często spotykam problem z wydajnością, gdy użytkownicy muszą dopasować część ciągu do zapytania takiego jak:
... WHERE SomeColumn LIKE N'%SomePortion%';
W przypadku wiodącego symbolu wieloznacznego ten predykat nie jest zgodny z SARG — po prostu fantazyjny sposób na powiedzenie, że nie możemy znaleźć odpowiednich wierszy za pomocą wyszukiwania względem indeksu w SomeColumn .
Jednym z rozwiązań, o którym trochę się kręcimy, jest wyszukiwanie pełnotekstowe; jest to jednak rozwiązanie złożone i wymaga, aby wzorzec wyszukiwania składał się z pełnych słów, nie używał słów przerywających i tak dalej. Może to pomóc, jeśli szukamy wierszy, w których opis zawiera słowo „miękkie” (lub inne pochodne, takie jak „miękko” lub „miękko”), ale nie pomaga, gdy szukamy ciągów, które mogą być zawarte w słowach (lub które w ogóle nie są słowami, jak wszystkie kody SKU produktów zawierające „X45-B” lub wszystkie tablice rejestracyjne zawierające sekwencję „7RA”).
Co by było, gdyby SQL Server w jakiś sposób wiedział o wszystkich możliwych częściach ciągu? Mój proces myślowy przebiega zgodnie z trigram / trigraph w PostgreSQL. Podstawowa koncepcja polega na tym, że silnik może wyszukiwać podciągi w stylu punktowym, co oznacza, że nie trzeba skanować całej tabeli i analizować każdej pełnej wartości.
Konkretnym przykładem, którego tam używają, jest słowo cat . Oprócz pełnego słowa można je podzielić na części:c , ca i at (pomijają a i t z definicji – żaden końcowy podciąg nie może być krótszy niż dwa znaki). W SQL Server nie potrzebujemy, aby było to aż tak skomplikowane; tak naprawdę potrzebujemy tylko połowy trygramu – jeśli myślimy o zbudowaniu struktury danych zawierającej wszystkie podciągi cat , potrzebujemy tylko tych wartości:
- kot
- o
- t
Nie potrzebujemy c lub ca , ponieważ każdy, kto szuka LIKE '%ca%' może łatwo znaleźć wartość 1, używając LIKE 'ca%' zamiast. Podobnie każdy, kto szuka LIKE '%at%' lub LIKE '%a%' może użyć końcowego symbolu wieloznacznego tylko dla tych trzech wartości i znaleźć tę, która pasuje (np. LIKE 'at%' znajdzie wartość 2 i LIKE 'a%' znajdzie również wartość 2, bez konieczności znajdowania tych podciągów w wartości 1, z której pochodzi prawdziwy ból).
Tak więc, biorąc pod uwagę, że SQL Server nie ma wbudowanego niczego takiego, jak wygenerować taki trygram?
Oddzielna tabela fragmentów
Przestanę tu odwoływać się do „trygramu”, ponieważ nie jest to tak naprawdę analogiczne do tej funkcji w PostgreSQL. Zasadniczo zamierzamy zbudować osobną tabelę ze wszystkimi „fragmentami” oryginalnego ciągu. (Więc w cat na przykład byłaby nowa tabela z tymi trzema wierszami, a LIKE '%pattern%' wyszukiwania byłyby skierowane na tę nową tabelę jako LIKE 'pattern%' predykaty.)
Zanim zacznę pokazywać, jak moje zaproponowane rozwiązanie będzie działać, chciałbym wyraźnie zaznaczyć, że to rozwiązanie nie powinno być używane w każdym pojedynczym przypadku, w którym LIKE '%wildcard%' wyszukiwania są powolne. Ze względu na sposób, w jaki zamierzamy „rozbić” dane źródłowe na fragmenty, w praktyce jest to prawdopodobnie ograniczone do mniejszych ciągów, takich jak adresy lub nazwy, w przeciwieństwie do większych ciągów, takich jak opisy produktów lub streszczenia sesji.
Bardziej praktyczny przykład niż cat jest spojrzenie na Sales.Customer tabeli w przykładowej bazie danych WideWorldImporters. Ma wiersze adresowe (oba nvarchar(60) ), z cennymi danymi adresowymi w kolumnie DeliveryAddressLine2 (z nieznanego powodu). Ktoś może szukać kogoś, kto mieszka na ulicy o nazwie Hudecova , więc będą prowadzić takie wyszukiwanie:
SELECT CustomerID, DeliveryAddressLine2
FROM Sales.Customers
WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
/* This returns two rows:
CustomerID DeliveryAddressLine2
---------- ----------------------
61 1695 Hudecova Avenue
181 1846 Hudecova Crescent
*/ Jak można się spodziewać, SQL Server musi wykonać skanowanie, aby zlokalizować te dwa wiersze. Które powinno być proste; jednak ze względu na złożoność tabeli ta banalna kwerenda daje bardzo niechlujny plan wykonania (skanowanie jest podświetlone i zawiera ostrzeżenie o szczątkowych operacjach we/wy):
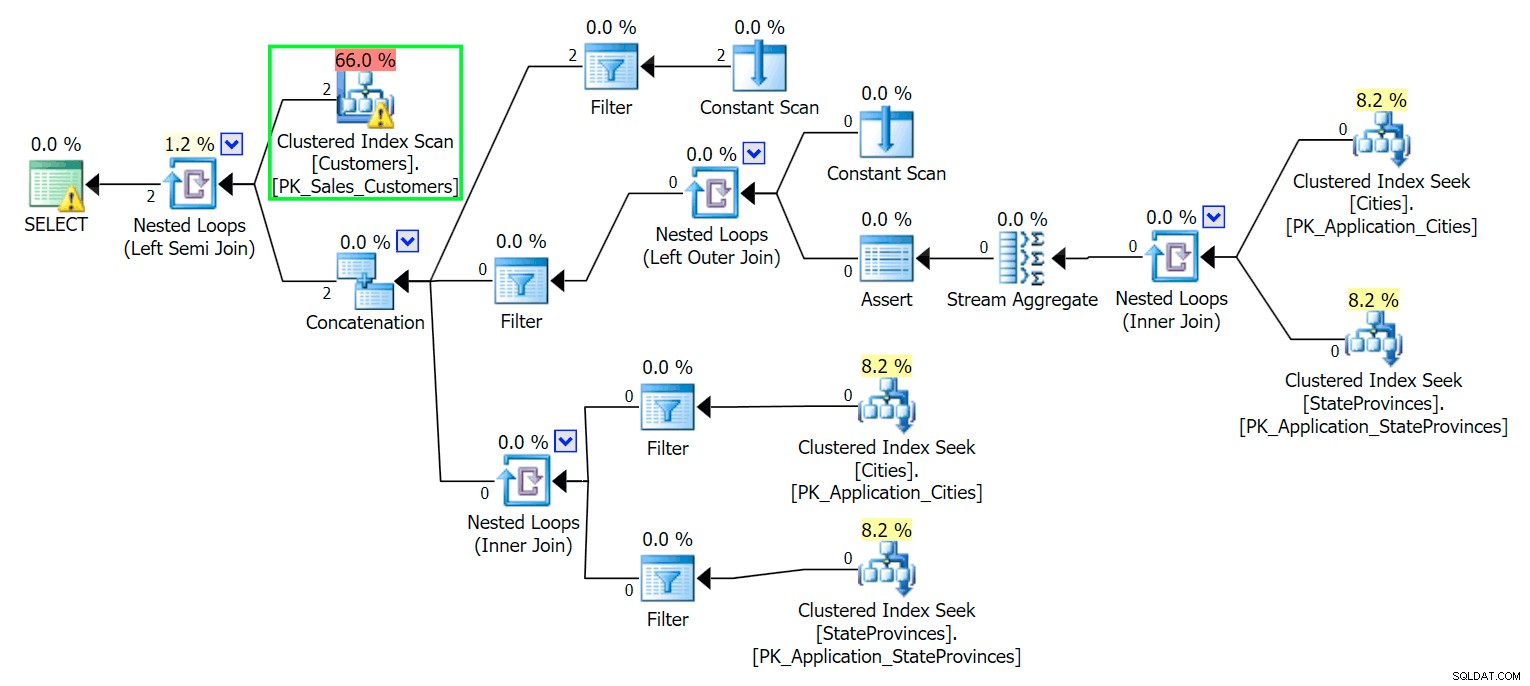
Bleccha. Aby nasze życie było proste i nie gonić za bandą czerwonych śledzi, stwórzmy nową tabelę z podzbiorem kolumn, a na początek po prostu wstawimy te same dwa wiersze z góry:
CREATE TABLE Sales.CustomersCopy ( CustomerID int IDENTITY(1,1) CONSTRAINT PK_CustomersCopy PRIMARY KEY, CustomerName nvarchar(100) NOT NULL, DeliveryAddressLine1 nvarchar(60) NOT NULL, DeliveryAddressLine2 nvarchar(60) ); GO INSERT Sales.CustomersCopy ( CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 ) SELECT CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 FROM Sales.Customers WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
Teraz, jeśli uruchomimy to samo zapytanie, które wykonaliśmy w tabeli głównej, otrzymamy coś znacznie bardziej rozsądnego, na co można spojrzeć jako punkt wyjścia. To nadal będzie skan, bez względu na to, co zrobimy – jeśli dodamy indeks z DeliveryAddressLine2 jako wiodąca kolumna klucza, najprawdopodobniej otrzymamy skanowanie indeksu z wyszukiwaniem klucza w zależności od tego, czy indeks obejmuje kolumny w zapytaniu. Tak jak jest, otrzymujemy klastrowe skanowanie indeksu:
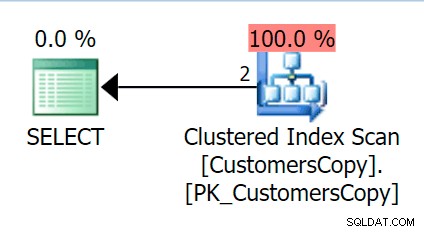
Następnie stwórzmy funkcję, która „rozbije” te wartości adresów na fragmenty. Spodziewalibyśmy się 1846 Hudecova Crescent , na przykład, aby mieć następujący zestaw fragmentów:
- 1846 Półksiężyc Hudecova
- 846 Półksiężyc Hudecova
- 46 Półksiężyc Hudecova
- 6 półksiężyc Hudecova
- Hudecova Crescent
- Hudecova Crescent
- udecova półksiężyc
- dekova półksiężyc
- ecova półksiężyc
- Cova półksiężyc
- owa półksiężyc
- va Crescent
- półksiężyc
- Półksiężyc
- Półksiężyc
- ponowne
- rodzący
- zapach
- cent
- ent
- nie
- t
Napisanie funkcji, która wygeneruje to wyjście, jest dość trywialne – potrzebujemy tylko rekurencyjnego CTE, którego można użyć do przechodzenia przez każdy znak na całej długości danych wejściowych:
CREATE FUNCTION dbo.CreateStringFragments( @input nvarchar(60) )
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
WITH x(x) AS
(
SELECT 1 UNION ALL SELECT x+1 FROM x WHERE x < (LEN(@input))
)
SELECT Fragment = SUBSTRING(@input, x, LEN(@input)) FROM x
);
GO
SELECT Fragment FROM dbo.CreateStringFragments(N'1846 Hudecova Crescent');
-- same output as above bulleted list Teraz stwórzmy tabelę, w której będą przechowywane wszystkie fragmenty adresu i do którego Klienta należą:
CREATE TABLE Sales.CustomerAddressFragments ( CustomerID int NOT NULL, Fragment nvarchar(60) NOT NULL, CONSTRAINT FK_Customers FOREIGN KEY(CustomerID) REFERENCES Sales.CustomersCopy(CustomerID) ); CREATE CLUSTERED INDEX s_cat ON Sales.CustomerAddressFragments(Fragment, CustomerID);
Następnie możemy wypełnić to tak:
INSERT Sales.CustomerAddressFragments(CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f;
Dla naszych dwóch wartości wstawia to 42 wiersze (jeden adres ma 20 znaków, a drugi 22). Teraz nasze zapytanie brzmi:
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
INNER JOIN Sales.CustomerAddressFragments AS f
ON f.CustomerID = c.CustomerID
AND f.Fragment LIKE N'Hudecova%'; Oto znacznie ładniejszy plan — dwa indeksowane *wyszukiwane* w klastrze i zagnieżdżone pętle łączą się:
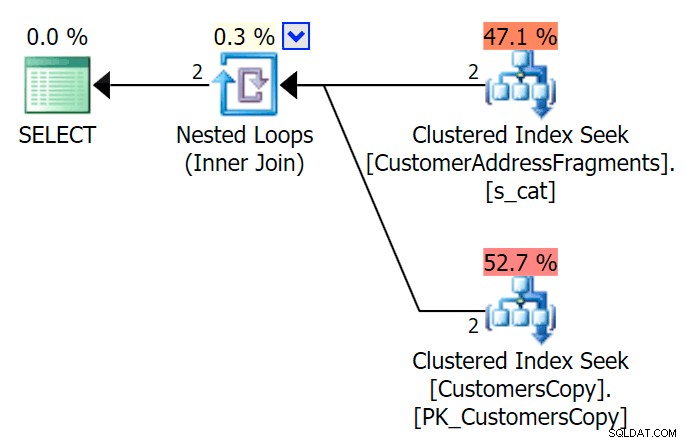
Możemy to również zrobić w inny sposób, używając EXISTS :
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
WHERE EXISTS
(
SELECT 1 FROM Sales.CustomerAddressFragments
WHERE CustomerID = c.CustomerID
AND Fragment LIKE N'Hudecova%'
); Oto plan, który na pierwszy rzut oka wydaje się droższy – wybiera skanowanie tabeli CustomersCopy. Wkrótce zobaczymy, dlaczego jest to lepsze podejście do zapytań:
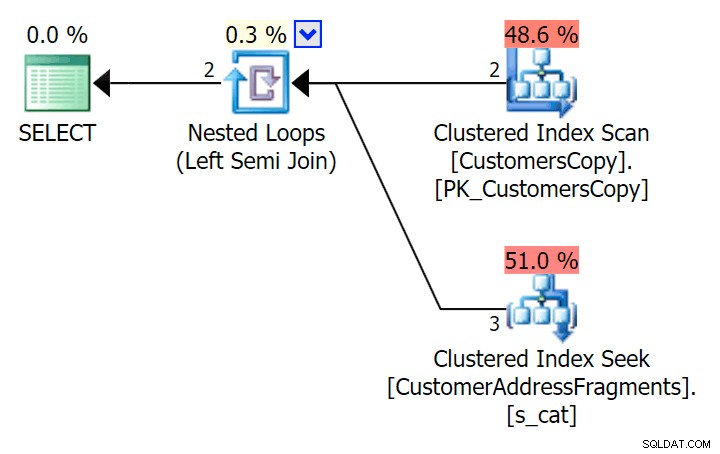
Teraz, w tym ogromnym zestawie danych składającym się z 42 wierszy, różnice widoczne w czasie trwania i we/wy są tak niewielkie, że są nieistotne (i w rzeczywistości przy tym małym rozmiarze skanowanie w stosunku do tabeli bazowej wygląda taniej pod względem I/ O niż pozostałe dwa plany korzystające z tabeli fragmentów):

Co by było, gdybyśmy zapełnili te tabele dużo większą ilością danych? Moja kopia Sales.Customers ma 663 wierszy, więc jeśli połączymy to ze sobą, otrzymalibyśmy około 440 000 wierszy. Po prostu zmiksujmy 400K i wygenerujmy znacznie większą tabelę:
TRUNCATE TABLE Sales.CustomerAddressFragments; DELETE Sales.CustomersCopy; DBCC FREEPROCCACHE WITH NO_INFOMSGS; INSERT Sales.CustomersCopy WITH (TABLOCKX) (CustomerName, DeliveryAddressLine1, DeliveryAddressLine2) SELECT TOP (400000) c1.CustomerName, c1.DeliveryAddressLine1, c2.DeliveryAddressLine2 FROM Sales.Customers c1 CROSS JOIN Sales.Customers c2 ORDER BY NEWID(); -- fun for distribution -- this will take a bit longer - on my system, ~4 minutes -- probably because I didn't bother to pre-expand files INSERT Sales.CustomerAddressFragments WITH (TABLOCKX) (CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f; -- repeated for compressed version of the table -- 7.25 million rows, 278MB (79MB compressed; saving those tests for another day)
Teraz, aby porównać plany wydajności i wykonania przy różnych możliwych parametrach wyszukiwania, przetestowałem powyższe trzy zapytania z następującymi predykatami:
| Zapytanie | Predykaty | ||||
|---|---|---|---|---|---|
| GDZIE DeliveryLineAddress2 LIKE… | N'%Hudecova%' | N'%cova%' | N'%ova%' | N'%va%' | |
| JOIN … GDZIE fragment LIKE … | N'Hudecova%' | N'cova%' | N'ova%' | N'va%' | |
| GDZIE ISTNIEJE (… GDZIE fragment LIKE…) | |||||
Ponieważ usuwamy litery ze wzorca wyszukiwania, spodziewam się, że uzyskam więcej wierszy i być może różne strategie wybrane przez optymalizator. Zobaczmy, jak poszło dla każdego wzoru:
Hudecova%
Dla tego wzorca skanowanie było nadal takie samo dla warunku LIKE; jednak przy większej ilości danych koszt jest znacznie wyższy. Wyszukiwania w tabeli fragmentów naprawdę się opłacają przy tej liczbie wierszy (1206), nawet przy bardzo niskich szacunkach. Plan EXISTS dodaje odrębny rodzaj, którego można oczekiwać, aby dodać do kosztów, chociaż w tym przypadku kończy się wykonaniem mniejszej liczby odczytów:

 Plan JOIN do tabeli fragmentów
Plan JOIN do tabeli fragmentów 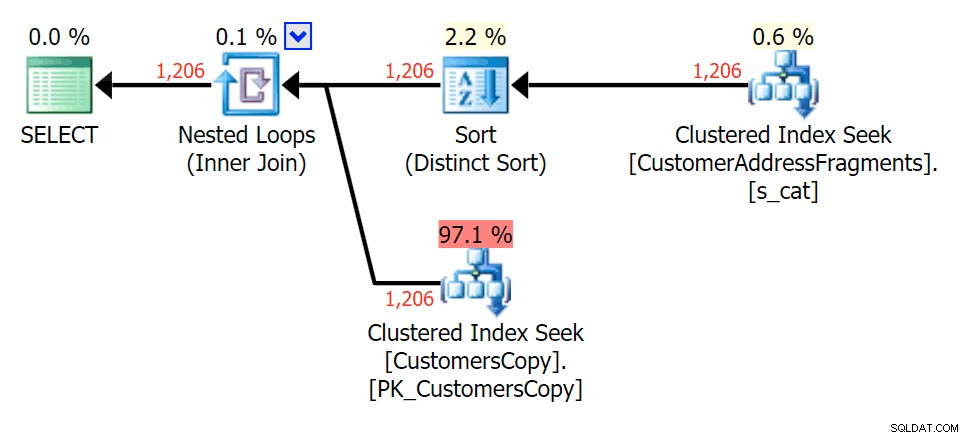 Plan ISTNIEJE w odniesieniu do tabeli fragmentów
Plan ISTNIEJE w odniesieniu do tabeli fragmentów cova%
Gdy usuwamy niektóre litery z naszego predykatu, widzimy, że odczyty są w rzeczywistości nieco wyższe niż przy oryginalnym skanowaniu indeksu klastrowego, a teraz przechodzimy -oszacuj wiersze. Mimo to nasz czas trwania pozostaje znacznie krótszy w przypadku obu zapytań fragmentarycznych; różnica tym razem jest bardziej subtelna – oba mają rodzaje (tylko ISTNIEJE):

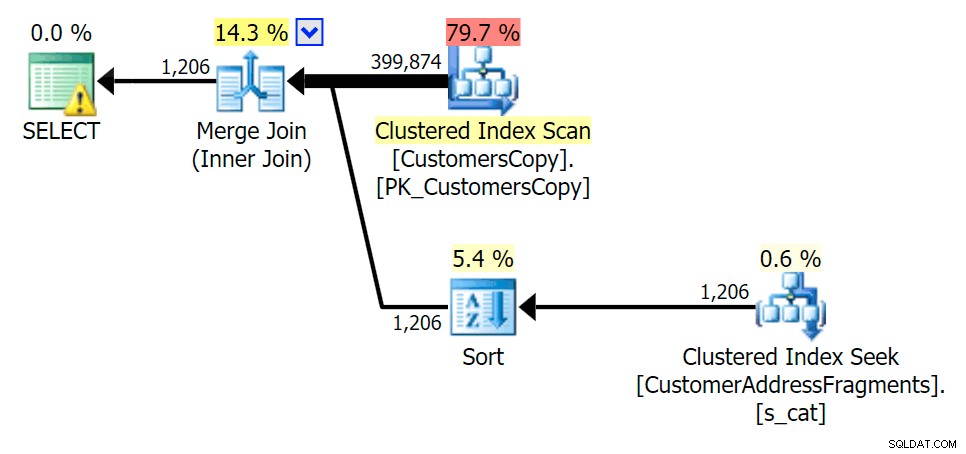 Plan JOIN do tabeli fragmentów
Plan JOIN do tabeli fragmentów 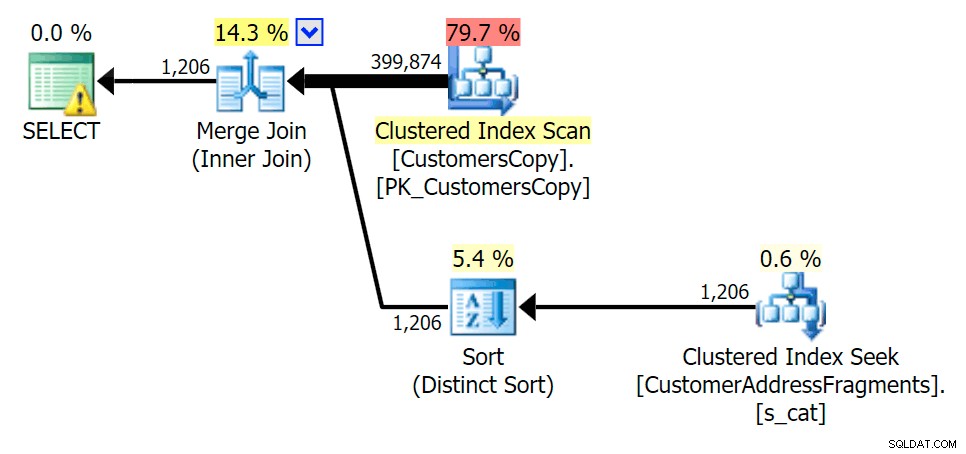 Plan ISTNIEJE w odniesieniu do tabeli fragmentów
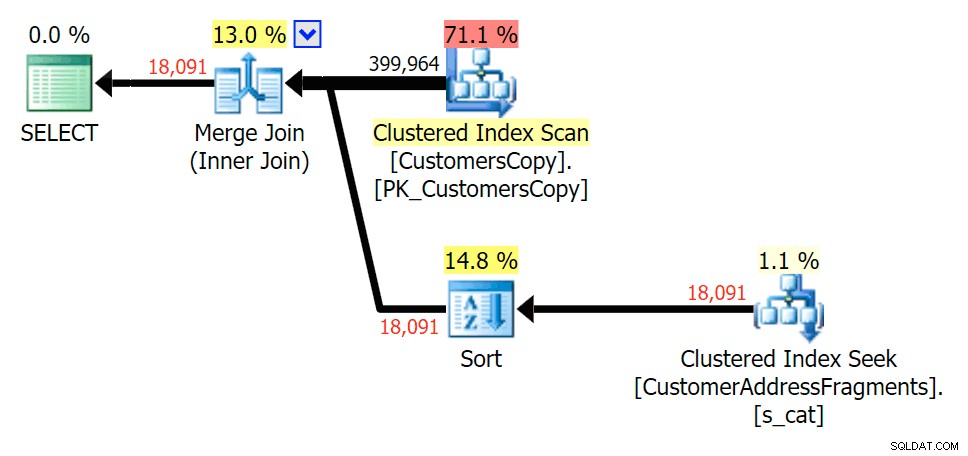
Plan ISTNIEJE w odniesieniu do tabeli fragmentów jaja%
Zdejmowanie dodatkowego listu niewiele się zmieniło; chociaż warto zauważyć, o ile szacowane i rzeczywiste wiersze przeskakują tutaj – co oznacza, że może to być powszechny wzorzec podłańcuchów. Oryginalne zapytanie LIKE jest nadal nieco wolniejsze niż zapytania fragmentaryczne.

 Plan JOIN do tabeli fragmentów
Plan JOIN do tabeli fragmentów 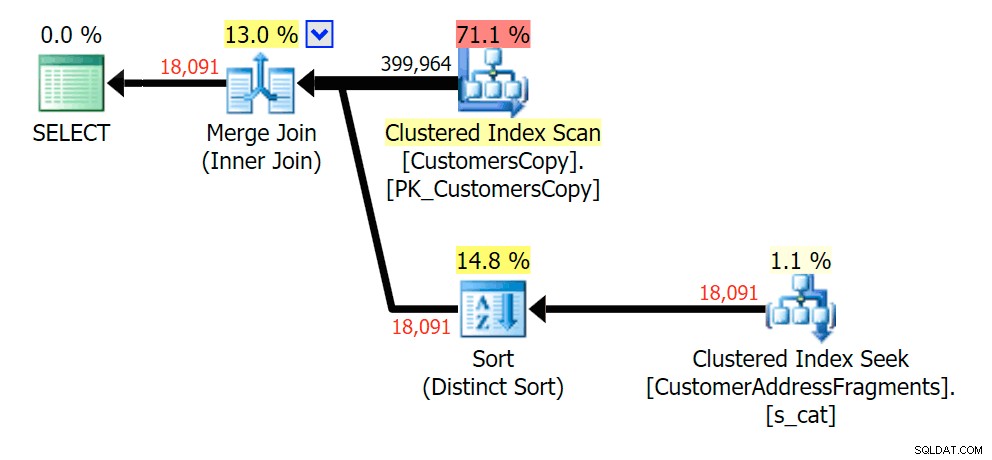 Plan ISTNIEJE w odniesieniu do tabeli fragmentów
Plan ISTNIEJE w odniesieniu do tabeli fragmentów v%
Do dwóch liter wprowadza to naszą pierwszą rozbieżność. Zauważ, że JOIN daje więcej wierszy niż oryginalne zapytanie lub EXISTS. Dlaczego miałoby to być?

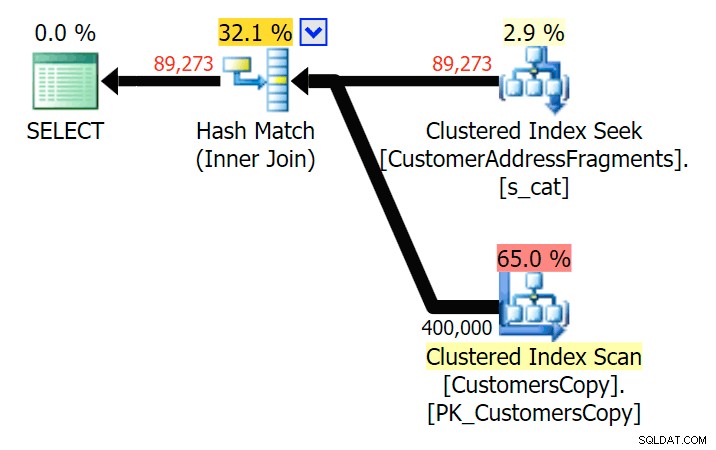 Plan JOIN do tabeli fragmentów
Plan JOIN do tabeli fragmentów 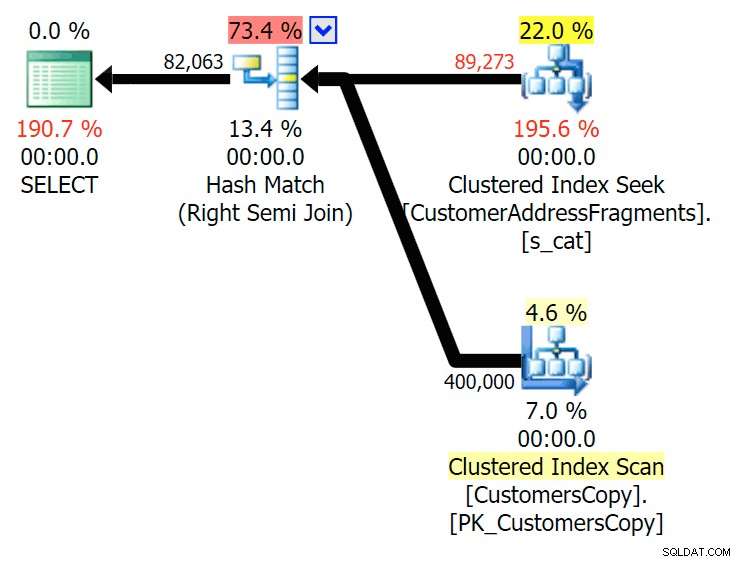 Plan ISTNIEJE w odniesieniu do tabeli fragmentów Nie musimy daleko szukać. Pamiętaj, że istnieje fragment rozpoczynający się od każdego kolejnego znaku w oryginalnym adresie, co oznacza coś w rodzaju
Plan ISTNIEJE w odniesieniu do tabeli fragmentów Nie musimy daleko szukać. Pamiętaj, że istnieje fragment rozpoczynający się od każdego kolejnego znaku w oryginalnym adresie, co oznacza coś w rodzaju 899 Valentova Road będzie miał dwa wiersze w tabeli fragmentów, które zaczynają się od va (pomijając rozróżnienie wielkości liter). Więc dopasujesz na obu Fragment = N'Valentova Road' i Fragment = N'va Road' . Oszczędzę ci poszukiwań i podam jeden z wielu przykładów: SELECT TOP (2) c.CustomerID, c.DeliveryAddressLine2, f.Fragment FROM Sales.CustomersCopy AS c INNER JOIN Sales.CustomerAddressFragments AS f ON c.CustomerID = f.CustomerID WHERE f.Fragment LIKE N'va%' AND c.DeliveryAddressLine2 = N'899 Valentova Road' AND f.CustomerID = 351; /* CustomerID DeliveryAddressLine2 Fragment ---------- -------------------- -------------- 351 899 Valentova Road va Road 351 899 Valentova Road Valentova Road */
To łatwo wyjaśnia, dlaczego JOIN tworzy więcej wierszy; jeśli chcesz dopasować wynik oryginalnego zapytania LIKE, powinieneś użyć EXISTS. Fakt, że prawidłowe wyniki można zwykle uzyskać również w sposób mniej zasobochłonny, jest tylko premią. (Byłbym zdenerwowany widząc, że ludzie wybierają DOŁĄCZ, gdyby była to wielokrotnie bardziej wydajna opcja - zawsze powinieneś przedkładać prawidłowe wyniki nad martwienie się o wydajność.)
Podsumowanie
Jasne jest, że w tym konkretnym przypadku – z kolumną adresu nvarchar(60) oraz maksymalna długość 26 znaków – rozbicie każdego adresu na fragmenty może przynieść ulgę w kosztownych wyszukiwaniach z „wiodącymi symbolami wieloznacznymi”. Wydaje się, że większa wypłata ma miejsce, gdy wzorzec wyszukiwania jest większy, a co za tym idzie, bardziej unikalny. Wykazałem również, dlaczego EXISTS jest lepsze w scenariuszach, w których możliwe jest wielokrotne dopasowanie – dzięki JOIN otrzymasz nadmiarowe dane wyjściowe, chyba że dodasz logikę „największej liczby n na grupę”.
Ostrzeżenia
Jako pierwszy przyznam, że to rozwiązanie jest niedoskonałe, niekompletne i niedopracowane:
- Będziesz musiał zsynchronizować tabelę fragmentów z tabelą bazową za pomocą wyzwalaczy – najprostszym byłoby wstawianie i aktualizowanie, usuwanie wszystkich wierszy dla tych klientów i ponowne ich wstawianie, a w przypadku usuwania oczywiście usuwanie wierszy z fragmentów stół.
- Jak wspomniano, to rozwiązanie działało lepiej dla tego konkretnego rozmiaru danych i może nie działać tak dobrze dla innych długości łańcucha. Wymagałoby to dalszych testów, aby upewnić się, że jest odpowiedni dla rozmiaru kolumny, średniej długości wartości i typowej długości parametru wyszukiwania.
- Ponieważ będziemy mieć wiele kopii fragmentów, takich jak „Półksiężyc” i „Ulica” (nieważne te same lub podobne nazwy ulic i numery domów), możemy je dodatkowo znormalizować, przechowując każdy unikalny fragment w tabeli fragmentów, a potem jeszcze inną tabelę, która działa jako tabela połączeń wiele-do-wielu. Konfiguracja byłaby o wiele bardziej kłopotliwa i nie jestem pewien, czy można by wiele zyskać.
- Nie zbadałem jeszcze w pełni kompresji strony, wydaje się, że – przynajmniej teoretycznie – może to przynieść pewne korzyści. Mam też wrażenie, że w niektórych przypadkach implementacja magazynu kolumn może być również korzystna.
W każdym razie, wszystko to powiedziawszy, chciałem po prostu podzielić się nim jako rozwijającym się pomysłem i poprosić o wszelkie opinie na temat jego praktyczności w konkretnych przypadkach użycia. Mogę zagłębić się w więcej szczegółów w przyszłym poście, jeśli poinformujesz mnie, jakie aspekty tego rozwiązania Cię interesują.