W zeszłym tygodniu podczas konferencji GroupBy przedstawiłem moją sesję T-SQL :Bad Habits and Best Practices. Powtórka wideo i inne materiały są dostępne tutaj:
- T-SQL:złe nawyki i najlepsze praktyki
Jedną z rzeczy, o których zawsze wspominam podczas tej sesji, jest to, że generalnie wolę GROUP BY nad DISTINCT podczas eliminowania duplikatów. Chociaż DISTINCT lepiej wyjaśnia intencje, a funkcja GROUP BY jest wymagana tylko wtedy, gdy występują agregacje, w wielu przypadkach są one wymienne.
Zacznijmy od czegoś prostego, używając Importerów z całego świata. Te dwa zapytania dają ten sam wynik:
SELECT DISTINCT Description FROM Sales.OrderLines; SELECT Description FROM Sales.OrderLines GROUP BY Description;
I faktycznie uzyskują swoje wyniki przy użyciu dokładnie tego samego planu wykonania:

Ci sami operatorzy, ta sama liczba odczytów, znikome różnice w procesorze i całkowitym czasie trwania (na zmianę „wygrywają”).
Dlaczego więc miałbym polecać używanie bardziej słownej i mniej intuicyjnej składni GROUP BY zamiast DISTINCT? Cóż, w tym prostym przypadku jest to rzut monetą. Jednak w bardziej złożonych przypadkach DISTINCT może w efekcie wykonać więcej pracy. Zasadniczo DISTINCT zbiera wszystkie wiersze, w tym wszelkie wyrażenia, które muszą zostać ocenione, a następnie wyrzuca duplikaty. GROUP BY może (ponownie, w niektórych przypadkach) odfiltrować zduplikowane wiersze przed wykonywanie którejkolwiek z tych prac.
Porozmawiajmy na przykład o agregacji ciągów. Podczas gdy w SQL Server v.Next będziesz mógł używać STRING_AGG (zobacz posty tutaj i tutaj), reszta z nas musi kontynuować FOR XML PATH (i zanim powiesz mi, jak niesamowite są rekurencyjne CTE dla tego, proszę przeczytaj też ten post). Możemy mieć takie zapytanie, które próbuje zwrócić wszystkie zamówienia z tabeli Sales.OrderLines, wraz z opisami pozycji jako listę rozdzielaną pionową kreską:
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Jest to typowe zapytanie do rozwiązania tego rodzaju problemu, z następującym planem wykonania (ostrzeżenie we wszystkich planach dotyczy tylko niejawnej konwersji wychodzącej z filtra XPath):
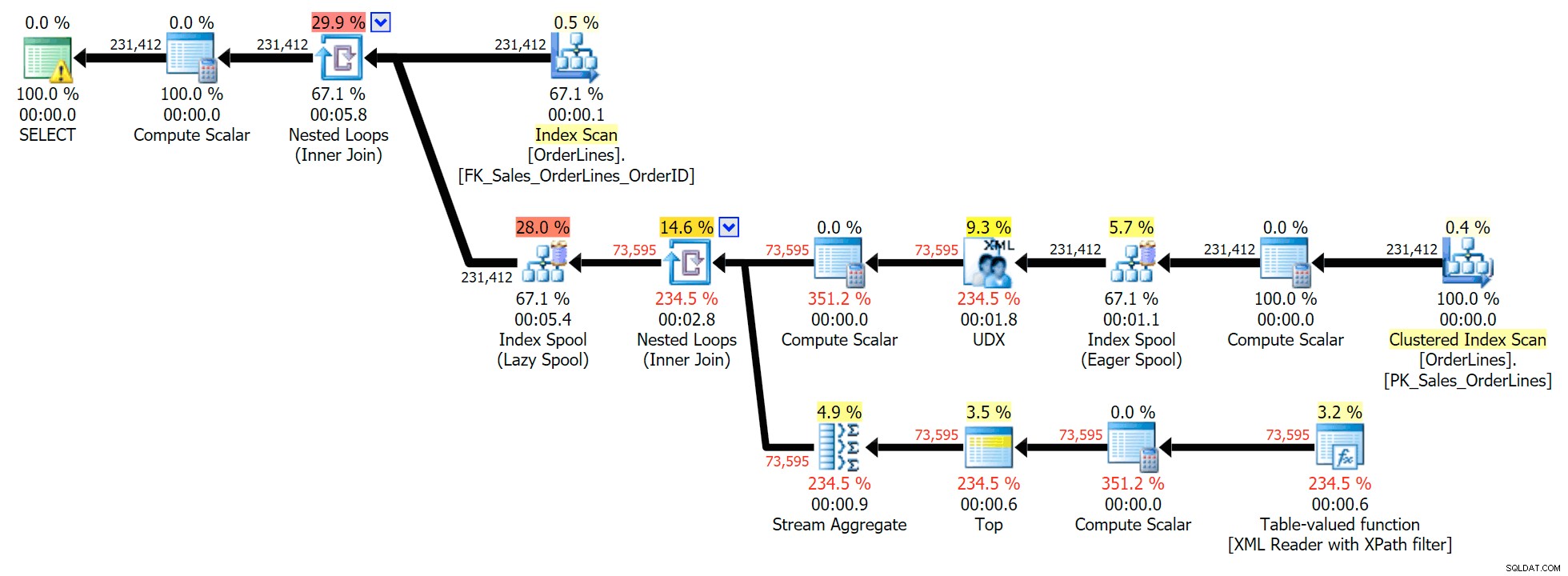
Jednak ma problem, który możesz zauważyć w wyjściowej liczbie wierszy. Z pewnością możesz to zauważyć, gdy od niechcenia skanujesz dane wyjściowe:

Dla każdego zamówienia widzimy listę oddzieloną rurkami, ale widzimy wiersz dla każdej pozycji w każdym zamówieniu. Odruchową reakcją jest rzucenie DISTINCT na liście kolumn:
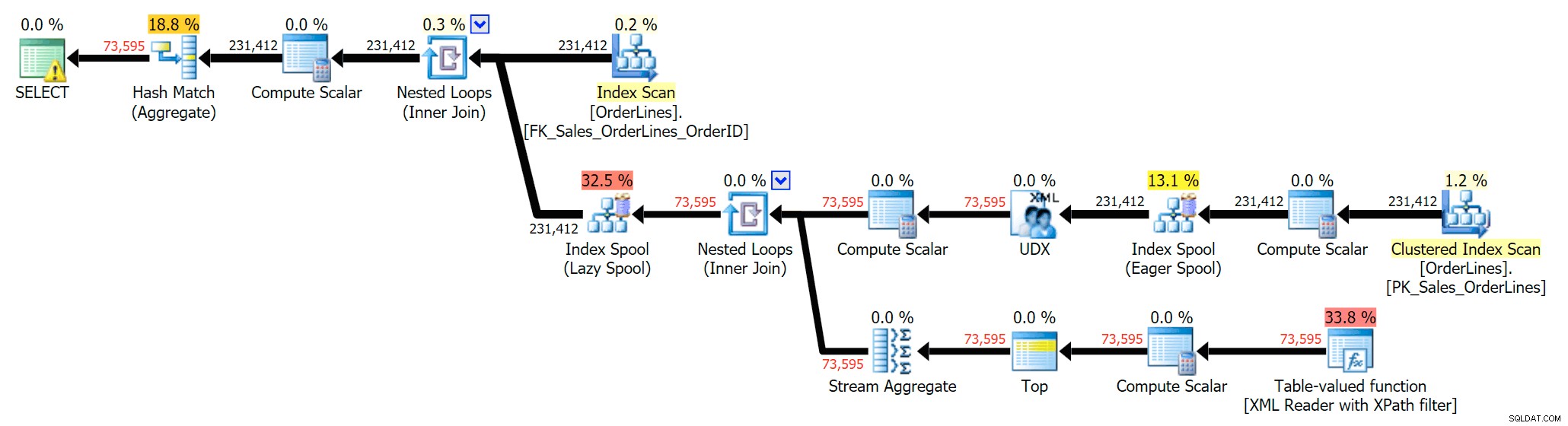
SELECT DISTINCT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Eliminuje to duplikaty (i zmienia właściwości porządkowania skanów, dzięki czemu wyniki niekoniecznie pojawiają się w przewidywalnej kolejności) i daje następujący plan wykonania:
Innym sposobem, aby to zrobić, jest dodanie GROUP BY dla OrderID (ponieważ podzapytanie nie wymaga wyraźnie potrzeby do ponownego odniesienia w GRUPIE WG):
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o GROUP BY o.OrderID;
Daje to te same wyniki (chociaż zamówienie zostało zwrócone) i nieco inny plan:
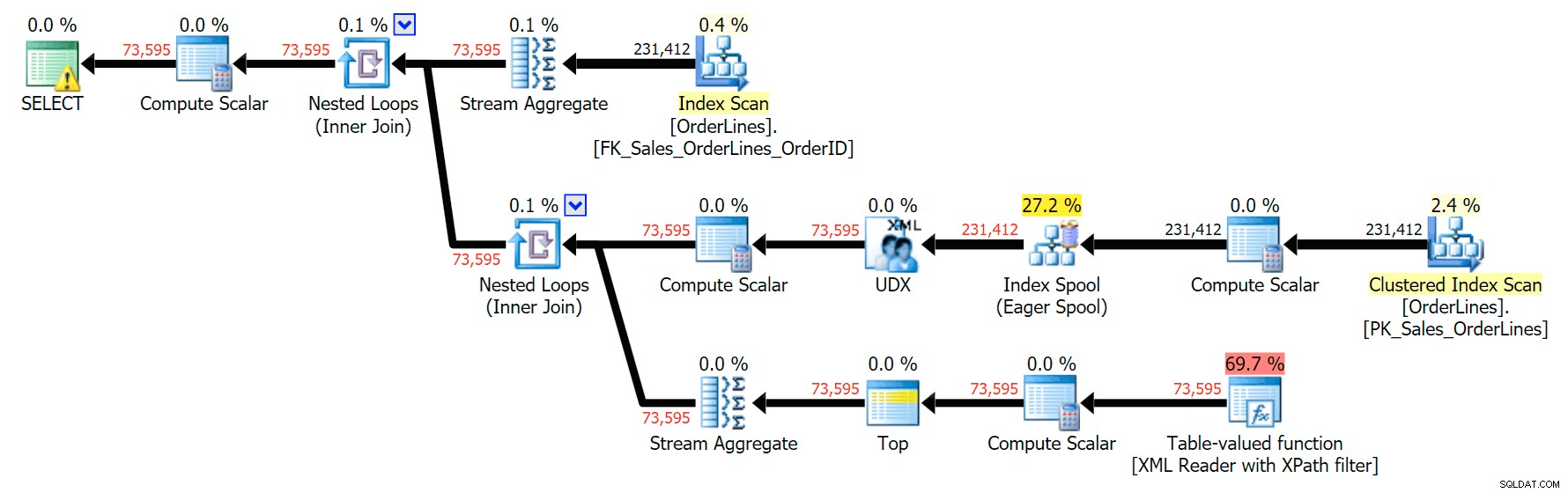
Jednak wskaźniki wydajności są interesujące do porównania.

Odmiana DISTINCT trwała 4 razy dłużej, zużywała 4 razy więcej procesora i prawie 6 razy więcej odczytów w porównaniu z odmianą GROUP BY. (Pamiętaj, że te zapytania zwracają dokładnie te same wyniki).
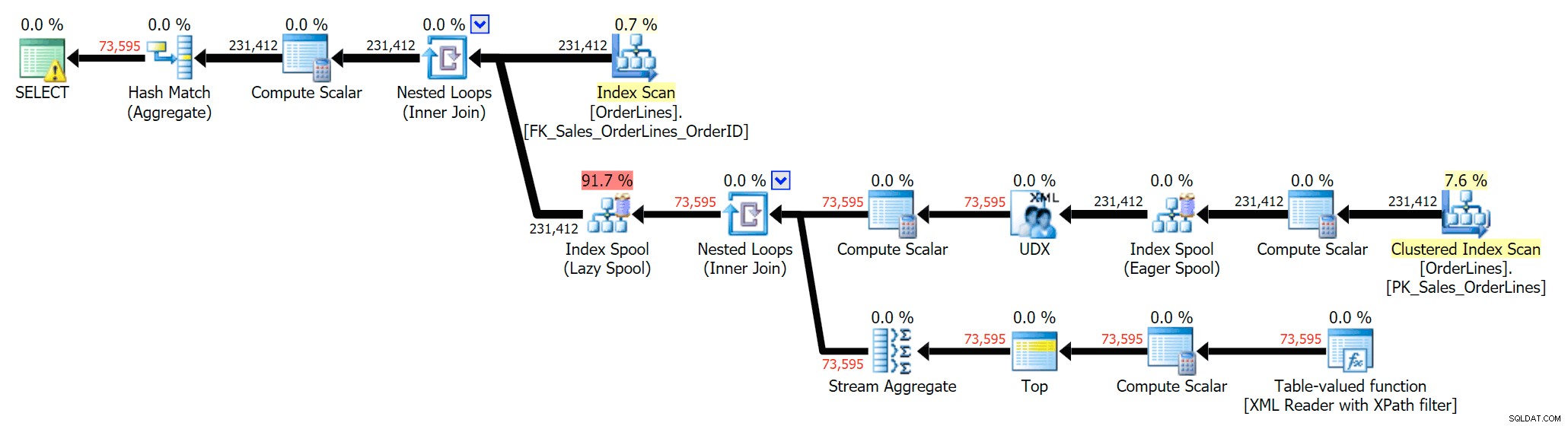
Możemy również porównać plany wykonania, gdy zmienimy koszty z CPU + I/O połączone na tylko I/O, funkcja dostępna wyłącznie w Plan Explorer. Pokazujemy również przeszacowane wartości (oparte na rzeczywistej koszty obserwowane podczas wykonywania zapytania, funkcja dostępna tylko w Plan Explorer). Oto plan DISTINCT:
A oto plan GROUP BY:
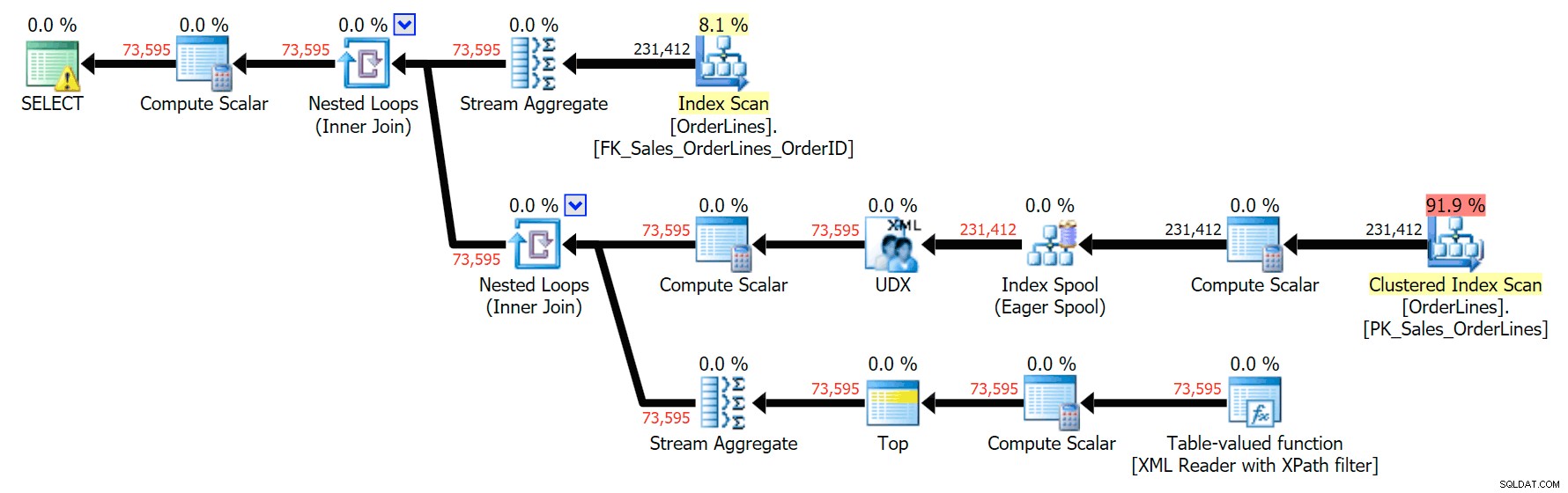
Widać, że w planie GROUP BY prawie cały koszt I/O znajduje się w skanach (tutaj jest podpowiedź dla skanowania CI, pokazująca koszt I/O wynoszący ~3,4 „dolarów za zapytania”). Jednak w planie DISTINCT większość kosztów I/O znajduje się w buforze indeksu (a oto podpowiedź; koszt I/O to ~41,4 „dolarów za zapytania”). Zwróć uwagę, że procesor jest znacznie wyższy w przypadku buforowania indeksu. Porozmawiamy o „dolarach za zapytania” innym razem, ale chodzi o to, że bufor indeksu jest ponad 10 razy droższy niż skanowanie – a mimo to skanowanie jest nadal takie samo 3,4 w obu planach. To jeden z powodów, dla których zawsze wkurza mnie, gdy ludzie mówią, że muszą „naprawić” operatora w planie o najwyższym koszcie. Niektórzy operatorzy w planie zawsze być najdroższym; to nie znaczy, że trzeba to naprawić.
@AaronBertrand te zapytania nie są tak naprawdę logicznie równoważne — DISTINCT jest w obu kolumnach, podczas gdy Twoja GROUP BY jest tylko w jednej
— Adam Machani (@AdamMachanic) 20 stycznia 2017
Chociaż Adam Machani ma rację, gdy mówi, że te zapytania są semantycznie różne, wynik jest taki sam – otrzymujemy tę samą liczbę wierszy, zawierających dokładnie te same wyniki i zrobiliśmy to przy znacznie mniejszej liczbie odczytów i procesora.
Tak więc, chociaż DISTINCT i GROUP BY są identyczne w wielu scenariuszach, tutaj jest jeden przypadek, w którym podejście GROUP BY zdecydowanie prowadzi do lepszej wydajności (kosztem mniej jasnej deklaratywnej intencji w samym zapytaniu). Chciałbym się dowiedzieć, czy sądzisz, że są jakieś scenariusze, w których DISTINCT jest lepsze niż GROUP BY, przynajmniej pod względem wydajności, która jest znacznie mniej subiektywna niż styl lub czy stwierdzenie musi być samodokumentowane.
Ten post pasuje do mojej serii „niespodzianek i założeń”, ponieważ wiele rzeczy, które uważamy za prawdy na podstawie ograniczonych obserwacji lub konkretnych przypadków użycia, można przetestować w innych scenariuszach. Musimy tylko pamiętać, aby poświęcić na to czas w ramach optymalizacji zapytań SQL…
Referencje
- Zgrupowana konkatenacja w SQL Server
- Zgrupowana konkatenacja:zamawianie i usuwanie duplikatów
- Cztery praktyczne przypadki użycia grupowej konkatenacji
- SQL Server v.Next:wydajność STRING_AGG()
- SQL Server v.Next:Wydajność STRING_AGG, część 2