Jedną z wielu nowych funkcji wprowadzonych w SQL Server 2008 była kompresja danych. Kompresja na poziomie wiersza lub strony zapewnia możliwość zaoszczędzenia miejsca na dysku, z kompromisem polegającym na tym, że do kompresji i dekompresji danych potrzebuje nieco więcej procesora. Często twierdzi się, że większość systemów jest związana z IO, a nie z procesorem, więc kompromis jest tego wart. Połów? Aby korzystać z kompresji danych, trzeba było korzystać z wersji Enterprise. Wraz z wydaniem dodatku SP1 dla SQL Server 2016 to się zmieniło! Jeśli używasz wersji Standard programu SQL Server 2016 SP1 lub nowszej, możesz teraz korzystać z kompresji danych. Dostępna jest również nowa wbudowana funkcja kompresji, KOMPRESJA (i jej odpowiednik DEKOMPRESJA). Kompresja danych nie działa na danych poza wierszem, więc jeśli masz w tabeli kolumnę taką jak NVARCHAR(MAX) z wartościami zwykle większymi niż 8000 bajtów, dane nie zostaną skompresowane (dziękuję Adamowi Machaniowi za to przypomnienie) . Funkcja COMPRESS rozwiązuje ten problem i kompresuje dane do rozmiaru 2 GB. Co więcej, chociaż twierdzę, że funkcja powinna być używana tylko w przypadku dużych danych poza wierszami, pomyślałem, że porównanie jej bezpośrednio z kompresją wierszy i stron jest opłacalnym eksperymentem.
USTAWIENIA
W przypadku danych testowych pracuję ze skryptu, którego Aaron Bertrand używał wcześniej, ale wprowadziłem kilka poprawek. Stworzyłem osobną bazę danych do testowania, ale możesz użyć tempdb lub innej przykładowej bazy danych, a następnie zacząłem od tabeli Klienci, która ma trzy kolumny NVARCHAR. Rozważałem utworzenie większych kolumn i wypełnienie ich ciągami powtarzających się liter, ale użycie czytelnego tekstu daje próbkę, która jest bardziej realistyczna, a tym samym zapewnia większą dokładność.
Uwaga: Jeśli jesteś zainteresowany wdrożeniem kompresji i chcesz wiedzieć, jak wpłynie ona na pamięć masową i wydajność w Twoim środowisku, BARDZO POLECAM TESTOWANIE JĄ. Podaję Ci metodologię z przykładowymi danymi; wdrożenie tego w swoim środowisku nie powinno wiązać się z dodatkową pracą.
Jak zauważysz poniżej, po utworzeniu bazy danych włączamy Query Store. Po co tworzyć osobną tabelę, aby spróbować śledzić nasze metryki wydajności, skoro możemy po prostu korzystać z funkcji wbudowanych w SQL Server?!
USE [master]; GO CREATE DATABASE [CustomerDB] CONTAINMENT = NONE ON PRIMARY ( NAME = N'CustomerDB', FILENAME = N'C:\Databases\CustomerDB.mdf' , SIZE = 4096MB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ) LOG ON ( NAME = N'CustomerDB_log', FILENAME = N'C:\Databases\CustomerDB_log.ldf' , SIZE = 2048MB , MAXSIZE = UNLIMITED , FILEGROWTH = 65536KB ); GO ALTER DATABASE [CustomerDB] SET COMPATIBILITY_LEVEL = 130; GO ALTER DATABASE [CustomerDB] SET RECOVERY SIMPLE; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE = ON; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30), DATA_FLUSH_INTERVAL_SECONDS = 60, INTERVAL_LENGTH_MINUTES = 5, MAX_STORAGE_SIZE_MB = 256, QUERY_CAPTURE_MODE = ALL, SIZE_BASED_CLEANUP_MODE = AUTO, MAX_PLANS_PER_QUERY = 200 ); GO
Teraz skonfigurujemy kilka rzeczy w bazie danych:
USE [CustomerDB]; GO ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0; GO -- note: I removed the unique index on [Email] that was in Aaron's version CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Po utworzeniu tabeli dodamy trochę danych, ale dodajemy 5 milionów wierszy zamiast 1 miliona. Uruchomienie na moim laptopie zajmuje około ośmiu minut.
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (5000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (20000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name + c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn;
GO Teraz utworzymy jeszcze trzy tabele:jedną do kompresji wierszy, jedną do kompresji stron i jedną do funkcji KOMPRESUJ. Zauważ, że w przypadku funkcji KOMPRESUJ, musisz utworzyć kolumny jako typy danych VARBINARY. W rezultacie w tabeli nie ma indeksów nieklastrowych (ponieważ nie można utworzyć klucza indeksu w kolumnie varbinary).
CREATE TABLE [dbo].[Customers_Page] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Page] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Page] ON [dbo].[Customers_Page]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Page] ON [dbo].[Customers_Page]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Row] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Row] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Row] ON [dbo].[Customers_Row]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Row] ON [dbo].[Customers_Row]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Compress] ( [CustomerID] [int] NOT NULL, [FirstName] [varbinary](max) NOT NULL, [LastName] [varbinary](max) NOT NULL, [EMail] [varbinary](max) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Compress] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO
Następnie skopiujemy dane z [dbo].[Klienci] do pozostałych trzech tabel. To jest zwykłe WSTAWIANIE dla naszych tabel stron i wierszy i zajmuje około dwóch do trzech minut dla każdego WSTAWIANIA, ale istnieje problem ze skalowalnością funkcji KOMPRESUJ:próba wstawienia 5 milionów wierszy za jednym zamachem po prostu nie jest rozsądna. Poniższy skrypt wstawia wiersze w partiach po 50 000 i wstawia tylko 1 milion wierszy zamiast 5 milionów. Wiem, to znaczy, że nie jesteśmy tutaj prawdziwymi jabłkami do porównania, ale nie mam z tym problemu. Wstawienie 1 miliona wierszy na moim komputerze zajmuje 10 minut; możesz dostosować skrypt i wstawić 5 milionów wierszy do własnych testów.
INSERT dbo.Customers_Page WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO INSERT dbo.Customers_Row WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO SET NOCOUNT ON DECLARE @StartID INT = 1 DECLARE @EndID INT = 50000 DECLARE @Increment INT = 50000 DECLARE @IDMax INT = 1000000 WHILE @StartID < @IDMax BEGIN INSERT dbo.Customers_Compress WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT top 100000 CustomerID, COMPRESS(FirstName), COMPRESS(LastName), COMPRESS(EMail), [Active] FROM dbo.Customers WHERE [CustomerID] BETWEEN @StartID AND @EndID; SET @StartID = @StartID + @Increment; SET @EndID = @EndID + @Increment; END
Po wypełnieniu wszystkich naszych tabel możemy sprawdzić rozmiar. W tym momencie nie zaimplementowaliśmy kompresji ROW ani PAGE, ale użyto funkcji KOMPRESUJ:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [o].[name], [i].[index_id];
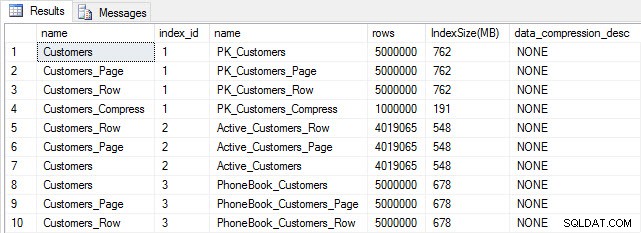 Rozmiar tabeli i indeksu po wstawieniu
Rozmiar tabeli i indeksu po wstawieniu
Zgodnie z oczekiwaniami wszystkie tabele z wyjątkiem Customers_Compress mają mniej więcej ten sam rozmiar. Teraz przebudujemy indeksy we wszystkich tabelach, wdrażając kompresję wierszy i stron odpowiednio w Customers_Row i Customers_Page.
ALTER INDEX ALL ON dbo.Customers REBUILD; GO ALTER INDEX ALL ON dbo.Customers_Page REBUILD WITH (DATA_COMPRESSION = PAGE); GO ALTER INDEX ALL ON dbo.Customers_Row REBUILD WITH (DATA_COMPRESSION = ROW); GO ALTER INDEX ALL ON dbo.Customers_Compress REBUILD;
Jeśli sprawdzimy rozmiar tabeli po kompresji, teraz możemy zobaczyć nasze oszczędności miejsca na dysku:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [i].[index_id], [IndexSize(MB)] DESC;
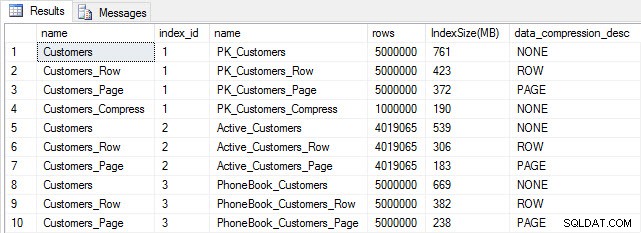
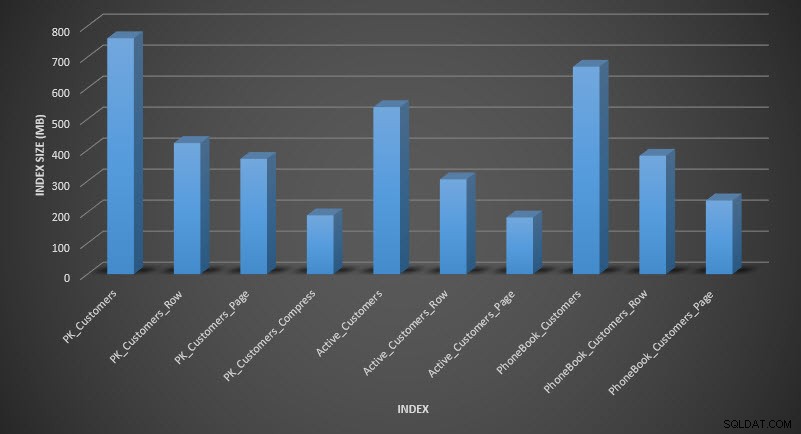 Rozmiar indeksu po kompresji
Rozmiar indeksu po kompresji
Zgodnie z oczekiwaniami kompresja wierszy i stron znacznie zmniejsza rozmiar tabeli i jej indeksów. Funkcja COMPRESS zaoszczędziła nam najwięcej miejsca – indeks klastrowy jest o jedną czwartą rozmiaru oryginalnej tabeli.
BADANIE WYDAJNOŚCI ZAPYTANIA
Zanim przetestujemy wydajność zapytań, zwróć uwagę, że możemy użyć Query Store do sprawdzenia wydajności INSERT i REBUILD:
SELECT [q].[query_id], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], AVG([rs].[avg_duration])/1000 [AvgDuration_ms], AVG([rs].[avg_cpu_time]) [AvgCPU], AVG([rs].[avg_logical_io_reads]) [AvgLogicalReads], AVG([rs].[avg_physical_io_reads]) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] LEFT OUTER JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [qt].[query_sql_text] LIKE '%INSERT%' OR [qt].[query_sql_text] LIKE '%ALTER%' GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [q].[query_id];
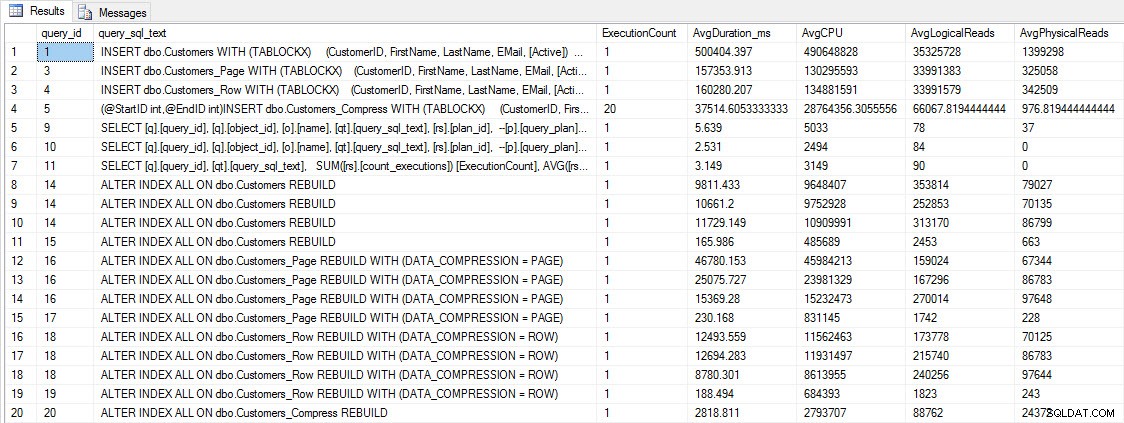 WSTAW i ODBUDUJ wskaźniki wydajności
WSTAW i ODBUDUJ wskaźniki wydajności
Chociaż te dane są interesujące, bardziej ciekawi mnie, jak kompresja wpływa na moje codzienne zapytania SELECT. Mam zestaw trzech procedur przechowywanych, z których każda ma jedną kwerendę SELECT, dzięki czemu każdy indeks jest używany. Stworzyłem te procedury dla każdej tabeli, a następnie napisałem skrypt, który pobierał wartości imienia i nazwiska do testów. Oto skrypt do tworzenia procedur.
Po utworzeniu procedur składowanych możemy uruchomić poniższy skrypt, aby je wywołać. Rozpocznij i poczekaj kilka minut…
SET NOCOUNT ON; GO DECLARE @RowNum INT = 1; DECLARE @Round INT = 1; DECLARE @ID INT = 1; DECLARE @FN NVARCHAR(64); DECLARE @LN NVARCHAR(64); DECLARE @SQLstring NVARCHAR(MAX); DROP TABLE IF EXISTS #FirstNames, #LastNames; SELECT DISTINCT [FirstName], DENSE_RANK() OVER (ORDER BY [FirstName]) AS RowNum INTO #FirstNames FROM [dbo].[Customers] SELECT DISTINCT [LastName], DENSE_RANK() OVER (ORDER BY [LastName]) AS RowNum INTO #LastNames FROM [dbo].[Customers] WHILE 1=1 BEGIN SELECT @FN = ( SELECT [FirstName] FROM #FirstNames WHERE RowNum = @RowNum) SELECT @LN = ( SELECT [LastName] FROM #LastNames WHERE RowNum = @RowNum) SET @FN = SUBSTRING(@FN, 1, 5) + '%' SET @LN = SUBSTRING(@LN, 1, 5) + '%' EXEC [dbo].[usp_FindActiveCustomer_C] @FN; EXEC [dbo].[usp_FindAnyCustomer_C] @LN; EXEC [dbo].[usp_FindSpecificCustomer_C] @ID; EXEC [dbo].[usp_FindActiveCustomer_P] @FN; EXEC [dbo].[usp_FindAnyCustomer_P] @LN; EXEC [dbo].[usp_FindSpecificCustomer_P] @ID; EXEC [dbo].[usp_FindActiveCustomer_R] @FN; EXEC [dbo].[usp_FindAnyCustomer_R] @LN; EXEC [dbo].[usp_FindSpecificCustomer_R] @ID; EXEC [dbo].[usp_FindActiveCustomer_CS] @FN; EXEC [dbo].[usp_FindAnyCustomer_CS] @LN; EXEC [dbo].[usp_FindSpecificCustomer_CS] @ID; IF @ID < 5000000 BEGIN SET @ID = @ID + @Round END ELSE BEGIN SET @ID = 2 END IF @Round < 26 BEGIN SET @Round = @Round + 1 END ELSE BEGIN IF @RowNum < 2260 BEGIN SET @RowNum = @RowNum + 1 SET @Round = 1 END ELSE BEGIN SET @RowNum = 1 SET @Round = 1 END END END GO
Po kilku minutach spójrz na zawartość Query Store:
SELECT [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], CAST(AVG([rs].[avg_duration])/1000 AS DECIMAL(10,2)) [AvgDuration_ms], CAST(AVG([rs].[avg_cpu_time]) AS DECIMAL(10,2)) [AvgCPU], CAST(AVG([rs].[avg_logical_io_reads]) AS DECIMAL(10,2)) [AvgLogicalReads], CAST(AVG([rs].[avg_physical_io_reads]) AS DECIMAL(10,2)) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [q].[object_id] <> 0 GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [o].[name];
Zobaczysz, że większość procedur składowanych została wykonana tylko 20 razy, ponieważ dwie procedury przeciwko [dbo].[Customers_Compress] są naprawdę powolny. To nie jest niespodzianka; ani [FirstName], ani [LastName] nie są indeksowane, więc każde zapytanie będzie musiało przeskanować tabelę. Nie chcę, aby te dwa zapytania spowalniały moje testowanie, więc zamierzam zmodyfikować obciążenie i skomentować EXEC [dbo].[usp_FindActiveCustomer_CS] i EXEC [dbo].[usp_FindAnyCustomer_CS], a następnie uruchomić go ponownie. Tym razem pozwolę mu działać przez około 10 minut, a kiedy ponownie spojrzę na dane wyjściowe Query Store, teraz mam dobre dane. Poniżej znajdują się surowe liczby, a poniżej wykresy ulubionych menedżerów.
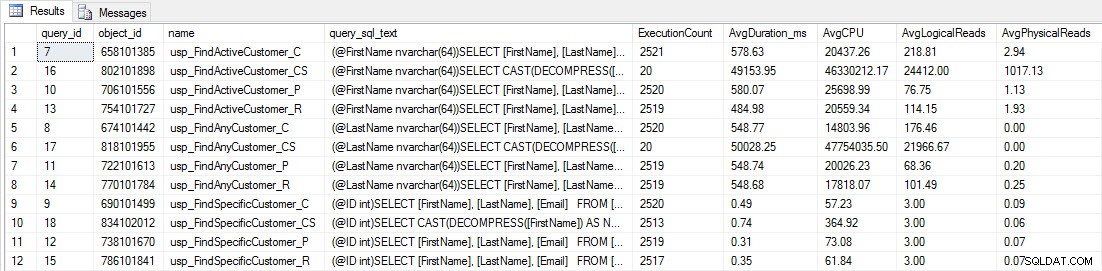 Dane wydajności z magazynu zapytań
Dane wydajności z magazynu zapytań
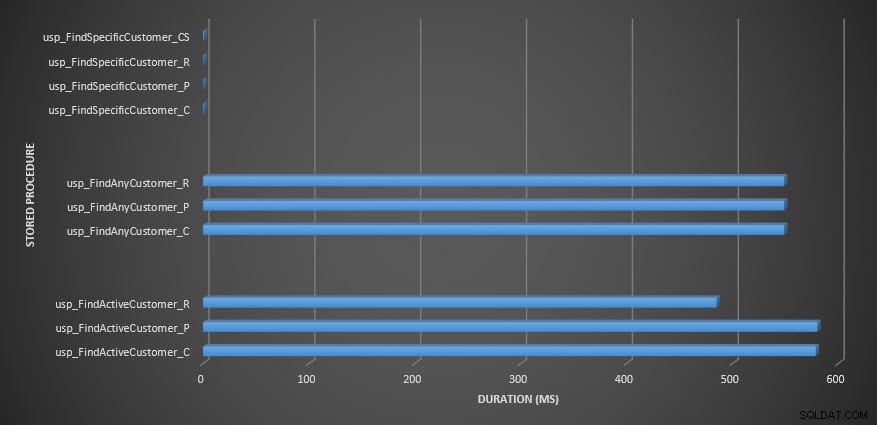 Czas trwania procedury składowanej
Czas trwania procedury składowanej
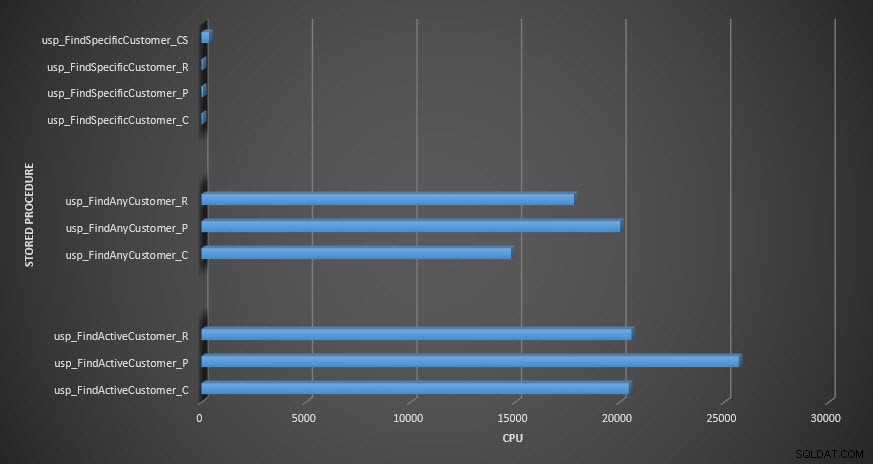 Procesor procedur zapisanych w bazie
Procesor procedur zapisanych w bazie
Przypomnienie:Wszystkie procedury składowane, które kończą się na _C, pochodzą z tabeli nieskompresowanej. Procedury kończące się na _R to tabela skompresowana wierszami, te kończące się na _P są skompresowane na stronie, a ta z _CS używa funkcji COMPRESS (usunąłem wyniki dla tej tabeli dla usp_FindAnyCustomer_CS i usp_FindActiveCustomer_CS, ponieważ tak bardzo przekrzywiły wykres, że straciliśmy różnice w pozostałych danych). Procedury usp_FindAnyCustomer_* i usp_FindActiveCustomer_* wykorzystywały indeksy nieklastrowane i zwracały tysiące wierszy dla każdego wykonania.
Spodziewałem się, że czas trwania procedur usp_FindAnyCustomer_* i usp_FindActiveCustomer_* dla tabel skompresowanych wierszy i stron będzie dłuższy w porównaniu z tabelą nieskompresowaną, ze względu na obciążenie związane z dekompresją danych. Dane magazynu zapytań nie spełniają moich oczekiwań — czas trwania tych dwóch procedur składowanych jest mniej więcej taki sam (lub mniej w jednym przypadku!) w tych trzech tabelach. Logiczne operacje we/wy dla zapytań były prawie takie same we wszystkich tabelach nieskompresowanych oraz skompresowanych stron i wierszy.
Jeśli chodzi o procesor, w procedurach składowanych usp_FindActiveCustomer i usp_FindAnyCustomer był on zawsze wyższy dla skompresowanych tabel. Procesor był porównywalny dla procedury usp_FindSpecificCustomer, która zawsze była pojedynczym wyszukiwaniem w indeksie klastrowym. Zwróć uwagę na wysoki procesor (ale stosunkowo krótki czas trwania) dla procedury usp_FindSpecificCustomer względem tabeli [dbo].[Customer_Compress], która wymagała funkcji DECOMPRESS do wyświetlania danych w czytelnym formacie.
PODSUMOWANIE
Dodatkowy procesor wymagany do pobrania skompresowanych danych istnieje i można go zmierzyć za pomocą Query Store lub tradycyjnych metod określania wartości bazowych. W oparciu o te wstępne testy, procesor jest porównywalny dla wyszukiwań pojedynczych, ale rośnie wraz z większą ilością danych. Chciałem zmusić SQL Server do dekompresji więcej niż tylko 10 stron – chciałem co najmniej 100. Wykonałem wariacje tego skryptu, w którym zwrócono dziesiątki tysięcy wierszy, a wyniki były zgodne z tym, co tutaj widzisz. Oczekuję, że aby zobaczyć znaczne różnice w czasie trwania ze względu na czas potrzebny na dekompresję danych, zapytania musiałyby zwrócić setki tysięcy lub miliony wierszy. Jeśli pracujesz w systemie OLTP, nie chcesz zwracać tylu wierszy, więc testy tutaj powinny dać wyobrażenie o tym, jak kompresja może wpłynąć na wydajność. Jeśli jesteś w hurtowni danych, prawdopodobnie zobaczysz dłuższy czas trwania wraz z wyższym procesorem podczas zwracania dużych zestawów danych. Chociaż funkcja COMPRESS zapewnia znaczną oszczędność miejsca w porównaniu z kompresją stron i wierszy, spadek wydajności pod względem procesora oraz brak możliwości indeksowania skompresowanych kolumn ze względu na ich typ danych, sprawiają, że jest ona opłacalna tylko w przypadku dużych ilości danych, które nie zostaną wyszukiwane.