Gdy użytkownicy żądają danych z systemu, zazwyczaj lubią je widzieć w określonej kolejności… nawet jeśli zwracają tysiące wierszy. Jak wie wielu administratorów baz danych i programistów, ORDER BY może wprowadzić chaos do planu zapytań, ponieważ wymaga sortowania danych. Czasami może to wymagać operatora SORT w ramach wykonywania zapytania, co może być kosztowną operacją, szczególnie jeśli oszacowania są wyłączone i rozlewają się na dysk. W idealnym świecie dane są już posortowane dzięki indeksowi (indeksy i sortowania bardzo się uzupełniają). Często mówimy o tworzeniu indeksu pokrywającego w celu spełnienia zapytania — aby optymalizator nie musiał wracać do tabeli bazowej lub indeksu klastrowego w celu uzyskania dodatkowych kolumn. Być może słyszałeś, jak ludzie mówią, że kolejność kolumn w indeksie ma znaczenie. Czy zastanawiałeś się kiedyś, jak wpływa to na operacje SORTOWANIA?
Badanie ORDER BY i sortuje
Zaczniemy od nowej kopii bazy danych AdventureWorks2014 w wystąpieniu programu SQL Server 2014 (wersja 12.0.2000). Jeśli uruchomimy proste zapytanie SELECT względem Sales.SalesOrderHeader bez ORDER BY, zobaczymy zwykły stary Clustered Index Scan (przy użyciu SQL Sentry Plan Explorer):
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader];
 Zapytanie bez ORDER BY, skanowanie indeksu klastrowego
Zapytanie bez ORDER BY, skanowanie indeksu klastrowego
Teraz dodajmy ORDER BY, aby zobaczyć, jak zmienia się plan:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID];
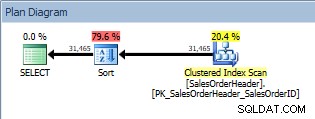 Zapytanie z ORDER BY, skanowanie indeksu klastrowego i sortowanie
Zapytanie z ORDER BY, skanowanie indeksu klastrowego i sortowanie
Oprócz skanowania indeksu klastrowego mamy teraz sortowanie wprowadzone przez optymalizator, a jego szacowany koszt jest znacznie wyższy niż koszt skanowania. Teraz szacowany koszt jest po prostu szacowany i nie możemy tutaj powiedzieć z całkowitą pewnością, że Sort pochłonął 79,6% kosztu zapytania. Aby naprawdę zrozumieć, jak drogi jest sortowanie, musielibyśmy przyjrzeć się również IO STATISTICS, co wykracza poza dzisiejszy cel.
Teraz, jeśli było to zapytanie, które było często wykonywane w twoim środowisku, prawdopodobnie rozważyłbyś dodanie indeksu, aby je obsługiwać. W tym przypadku nie ma klauzuli WHERE, po prostu pobieramy cztery kolumny i porządkujemy według jednej z nich. Logiczną pierwszą próbą indeksowania byłoby:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_CustomerID_OrderDate_SubTotal] ON [Sales].[SalesOrderHeader]( [CustomerID] ASC) INCLUDE ( [OrderDate], [SubTotal]);
Po dodaniu indeksu zawierającego wszystkie żądane przez nas kolumny ponownie uruchomimy nasze zapytanie i pamiętajmy, że indeks wykonał pracę związaną z posortowaniem danych. Widzimy teraz skanowanie indeksu względem naszego nowego indeksu nieklastrowanego:
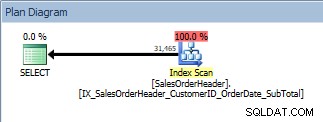 Zapytanie z ORDER BY, skanowany jest nowy, nieklastrowany indeks
Zapytanie z ORDER BY, skanowany jest nowy, nieklastrowany indeks
To jest dobra wiadomość. Ale co się stanie, jeśli ktoś zmieni to zapytanie – albo dlatego, że użytkownicy mogą określić, według jakich kolumn chcą uporządkować, albo dlatego, że programista zażądał zmiany? Na przykład, być może użytkownicy chcą widzieć ID klienta i ID zamówienia sprzedaży w kolejności malejącej:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] DESC;
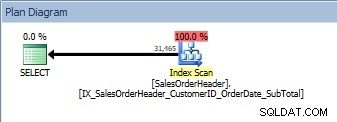 Zapytanie z dwiema kolumnami w ORDER BY, skanowany jest nowy, nieklastrowany indeks
Zapytanie z dwiema kolumnami w ORDER BY, skanowany jest nowy, nieklastrowany indeks
Mamy ten sam plan; nie dodano operatora sortowania. Jeśli spojrzymy na indeks za pomocą sp_helpindex Kimberly Tripp (niektóre kolumny zostały zwinięte, aby zaoszczędzić miejsce), możemy zobaczyć, dlaczego plan się nie zmienił:
 Wyjście sp_helpindex
Wyjście sp_helpindex
Kolumna klucza dla indeksu to CustomerID, ale ponieważ SalesOrderID jest kolumną klucza dla indeksu klastrowego, jest ona również częścią klucza indeksu, w związku z czym dane są sortowane według CustomerID, a następnie SalesOrderID. Zapytanie zażądało danych posortowanych według tych dwóch kolumn w kolejności malejącej. Indeks został utworzony z obiema kolumnami w porządku rosnącym, ale ponieważ jest to lista podwójnie połączona, indeks można czytać wstecz. Możesz to zobaczyć w okienku Właściwości w Management Studio dla nieklastrowanego operatora skanowania indeksu:
 Okienko właściwości nieklastrowego skanowania indeksu, pokazujące, że było odwrócone
Okienko właściwości nieklastrowego skanowania indeksu, pokazujące, że było odwrócone
Świetnie, nie ma problemów z tym zapytaniem… ale co z tym:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] ASC;
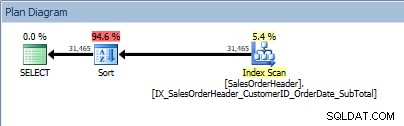 Zapytanie z dwiema kolumnami w ORDER BY i dodane sortowanie
Zapytanie z dwiema kolumnami w ORDER BY i dodane sortowanie
Nasz operator SORT pojawia się ponownie, ponieważ dane pochodzące z indeksu nie są posortowane w żądanej kolejności. Zobaczymy to samo zachowanie, jeśli posortujemy według jednej z uwzględnionych kolumn:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] ASC, [OrderDate] ASC;
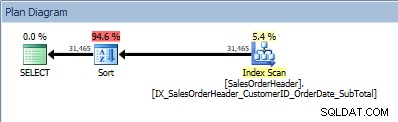 Zapytanie z dwiema kolumnami w ORDER BY i dodane sortowanie
Zapytanie z dwiema kolumnami w ORDER BY i dodane sortowanie
Co się stanie, jeśli (w końcu) dodamy predykat i nieznacznie zmienimy ORDER BY?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] = 13464 ORDER BY [SalesOrderID];
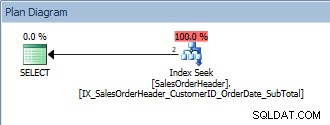 Zapytanie z pojedynczym predykatem i ORDER BY
Zapytanie z pojedynczym predykatem i ORDER BY
To zapytanie jest prawidłowe, ponieważ ponownie SalesOrderID jest częścią klucza indeksu. Dla tego jednego CustomerID dane są już uporządkowane według SalesOrderID. Co się stanie, jeśli zapytamy o zakres identyfikatorów klientów, posortowanych według identyfikatorów SalesOrderID?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 13464 AND 13466 ORDER BY [SalesOrderID];
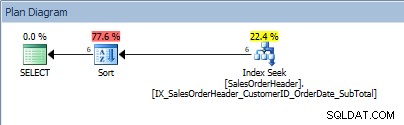 Zapytanie z zakresem wartości w predykacie i ORDER BY
Zapytanie z zakresem wartości w predykacie i ORDER BY
Szczury, nasz SORT powrócił. Fakt, że dane są uporządkowane według CustomerID, pomaga tylko w wyszukiwaniu indeksu w celu znalezienia tego zakresu wartości; dla ORDER BY SalesOrderID, optymalizator musi wstawić Sort, aby umieścić dane w żądanej kolejności.
W tym momencie możesz się zastanawiać, dlaczego skupiam się na operatorze sortowania pojawiającym się w planach zapytań. To dlatego, że jest drogi. Może to być kosztowne pod względem zasobów (pamięć, IO) i/lub czasu trwania.
Sortowanie może mieć wpływ na czas trwania zapytania, ponieważ jest to operacja typu stop-and-go. Cały zestaw danych musi zostać posortowany przed następną operacją w planie. Jeśli trzeba uporządkować tylko kilka wierszy danych, to nie jest taka wielka sprawa. Czy to tysiące czy miliony wierszy? Teraz czekamy.
Oprócz ogólnego czasu trwania zapytania musimy również pomyśleć o wykorzystaniu zasobów. Weźmy 31 465 wierszy, z którymi pracowaliśmy, i wepchnijmy je do zmiennej tabeli, a następnie uruchommy początkowe zapytanie z ORDER BY na ID klienta:
DECLARE @t TABLE (CustomerID INT, SalesOrderID INT, OrderDate DATETIME, SubTotal MONEY); INSERT @t SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader]; SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM @t ORDER BY [CustomerID];
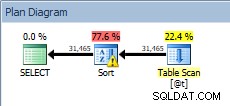 Zapytanie o zmienną tabeli z sortowaniem
Zapytanie o zmienną tabeli z sortowaniem
Nasz SORT powrócił i tym razem ma ostrzeżenie (zwróć uwagę na żółty trójkąt z wykrzyknikiem). Ostrzeżenia nie są dobre. Jeśli spojrzymy na właściwości tego rodzaju, zobaczymy ostrzeżenie „Operator użył tempdb do rozlania danych podczas wykonywania z poziomem rozlania 1”:
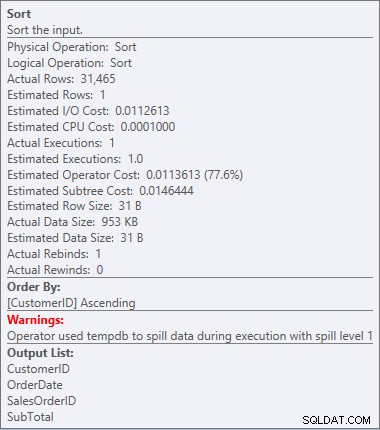 Ostrzeżenie o sortowaniu
Ostrzeżenie o sortowaniu
To nie jest coś, co chcę widzieć w planie. Optymalizator oszacował, ile miejsca będzie potrzebne w pamięci do posortowania danych i zażądał tej pamięci. Ale kiedy rzeczywiście miał wszystkie dane i zaczął je sortować, silnik zdał sobie sprawę, że nie ma wystarczającej ilości pamięci (optymalizator żądał za mało!), więc operacja sortowania się rozlała. W niektórych przypadkach może to rozlać się na dysk, co oznacza, że odczyty i zapisy są powolne. Nie tylko czekamy tylko na uporządkowanie danych, ale jest to jeszcze wolniejsze, ponieważ nie możemy zrobić tego wszystkiego w pamięci. Dlaczego optymalizator nie zażądał wystarczającej ilości pamięci? Miał złe oszacowanie danych potrzebnych do sortowania:
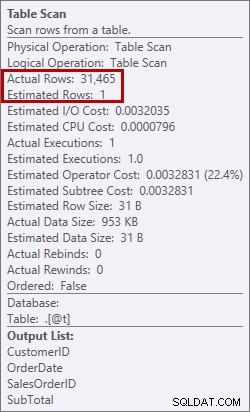 Oszacowanie 1 wiersza w porównaniu z rzeczywistym 31 465 wierszami
Oszacowanie 1 wiersza w porównaniu z rzeczywistym 31 465 wierszami
W tym przypadku wymusiłem złe oszacowanie za pomocą zmiennej tabeli. Znane są problemy z oszacowaniami statystyk i zmiennymi tabel (Aaron Bertrand ma świetny post na temat możliwości rozwiązania tego problemu), a tutaj optymalizator uważał, że ze skanowania tabeli zostanie zwrócony tylko 1 wiersz, a nie 31 465.
Opcje
Co więc możesz zrobić jako DBA lub programista, aby uniknąć sortowania w swoich planach zapytań? Szybka odpowiedź brzmi:„Nie zamawiaj swoich danych”. Ale to nie zawsze jest realistyczne. W niektórych przypadkach możesz odciążyć to sortowanie do klienta lub do warstwy aplikacji – ale użytkownicy nadal muszą czekać, aby posortować dane w tam warstwa. W sytuacjach, w których nie możesz zmienić sposobu działania aplikacji, możesz zacząć od przejrzenia indeksów.
Jeśli obsługujesz aplikację, która umożliwia użytkownikom uruchamianie zapytań ad-hoc lub zmieniasz porządek sortowania, aby mogli zobaczyć uporządkowane dane tak, jak chcą… będziesz miał najtrudniejszy czas (ale nie jest to przegrana przyczyna, więc nie przestawaj jeszcze czytać!). Nie możesz indeksować dla każdej opcji. Jest to nieefektywne i stworzysz więcej problemów niż rozwiążesz. Tutaj najlepiej jest porozmawiać z użytkownikami (wiem, że czasami opuszczenie zakątka lasu jest straszne, ale spróbuj). W przypadku zapytań, które użytkownicy uruchamiają najczęściej, dowiedz się, jak zazwyczaj lubią przeglądać dane. Tak, możesz to również uzyskać z pamięci podręcznej planów — możesz pobierać zapytania i plany, aż do zadowolenia, aby zobaczyć, co robią. Ale szybciej rozmawia się z użytkownikami. Dodatkową korzyścią jest to, że możesz wyjaśnić, dlaczego pytasz i dlaczego pomysł „sortowania według wszystkich kolumn, ponieważ mogę” nie jest taki dobry. Wiedza to połowa sukcesu. Jeśli możesz poświęcić trochę czasu na edukację swoich zaawansowanych użytkowników i użytkowników, którzy szkolą nowych ludzi, możesz zrobić coś dobrego.
Jeśli obsługujesz aplikację z ograniczonymi opcjami ORDER BY, możesz przeprowadzić prawdziwą analizę. Sprawdź, jakie istnieją odmiany ORDER BY, określ, które kombinacje są wykonywane najczęściej, i zindeksuj, aby wspierać te zapytania. Prawdopodobnie nie uderzysz wszystkich, ale nadal możesz wywrzeć wpływ. Możesz pójść o krok dalej, rozmawiając z programistami i edukując ich na temat problemu oraz sposobu jego rozwiązania.
Wreszcie, gdy patrzysz na plany zapytań z operacjami SORT, nie skupiaj się tylko na usunięciu sortowania. Spójrz gdzie sortowanie występuje w planie. Jeśli dzieje się to po lewej stronie planu i jest zazwyczaj kilka rzędów, mogą istnieć inne obszary o większym współczynniku poprawy, na których należy się skoncentrować. Sortowanie po lewej to wzorzec, na którym się dzisiaj skupiliśmy, ale sortowanie nie zawsze występuje z powodu ORDER BY. Jeśli widzisz sortowanie po prawej stronie planu, a przez tę część planu przechodzi wiele wierszy, wiesz, że znalazłeś dobre miejsce do rozpoczęcia dostrajania.



