[ Część 1 | Część 2 | Część 3 | Część 4 ]
Wiele napisano przez lata o zrozumieniu i optymalizacji SELECT zapytań, ale raczej mniej o modyfikacji danych. Ta seria postów dotyczy problemu, który jest specyficzny dla INSERT , UPDATE , DELETE i MERGE zapytania – problem Halloween.
Fraza „Halloween Problem” została pierwotnie ukuta w odniesieniu do SQL UPDATE zapytanie, które miało dać 10% podwyżki każdemu pracownikowi, który zarobił mniej niż 25 000 $. Problem polegał na tym, że zapytanie dawało 10% podwyżek, dopóki wszyscy zarobił co najmniej 25 000 $. W dalszej części tej serii zobaczymy, że podstawowy problem dotyczy również INSERT , DELETE i MERGE zapytań, ale w przypadku tego pierwszego wpisu pomocne będzie sprawdzenie UPDATE problem w szczegółach.
Tło
Język SQL umożliwia użytkownikom określanie zmian w bazie danych za pomocą UPDATE oświadczenie, ale składnia nie mówi nic o jak silnik bazy danych powinien dokonać zmian. Z drugiej strony, standard SQL określa, że wynik UPDATE musi być taki sam, jak gdyby został wykonany w trzech oddzielnych i nienakładających się fazach:
- Wyszukiwanie tylko do odczytu określa rekordy do zmiany i nowe wartości kolumn
- Zmiany są stosowane do dotkniętych rekordów
- Ograniczenia spójności bazy danych są weryfikowane
Zaimplementowanie tych trzech faz dosłownie w silniku bazy danych dałoby poprawne wyniki, ale wydajność może nie być zbyt dobra. Wyniki pośrednie na każdym etapie będą wymagały pamięci systemu, zmniejszając liczbę zapytań, które system może wykonywać jednocześnie. Wymagana pamięć może również przekraczać tę, która jest dostępna, co wymaga zapisania przynajmniej części zestawu aktualizacji do pamięci dyskowej i późniejszego ponownego odczytu. Wreszcie, co nie mniej ważne, każdy wiersz w tabeli musi być dotykany wiele razy w tym modelu wykonania.
Alternatywną strategią jest przetworzenie UPDATE wiersz na raz. Ma to tę zaletę, że dotyka każdego wiersza tylko raz i generalnie nie wymaga pamięci do przechowywania (chociaż niektóre operacje, takie jak pełne sortowanie, muszą przetworzyć pełny zestaw danych wejściowych przed utworzeniem pierwszego wiersza danych wyjściowych). Ten iteracyjny model jest używany przez silnik wykonywania zapytań SQL Server.
Wyzwaniem dla optymalizatora zapytań jest znalezienie iteracyjnego (wiersz po wierszu) planu wykonania, który spełnia wymagania UPDATE semantyki wymaganej przez standard SQL, przy jednoczesnym zachowaniu wydajności i współbieżności wynikających z wykonywania potokowego.
Przetwarzanie aktualizacji
Aby zilustrować pierwotną kwestię, zastosujemy 10% podwyżkę do każdego pracownika zarabiającego mniej niż 25 000 USD, korzystając z opcji Employees tabela poniżej:

CREATE TABLE dbo.Employees
(
Name nvarchar(50) NOT NULL,
Salary money NOT NULL
);
INSERT dbo.Employees
(Name, Salary)
VALUES
('Brown', $22000),
('Smith', $21000),
('Jones', $25000);
UPDATE e
SET Salary = Salary * $1.1
FROM dbo.Employees AS e
WHERE Salary < $25000; Trzyfazowa strategia aktualizacji
Pierwsza faza tylko do odczytu znajduje wszystkie rekordy, które spełniają WHERE predykat klauzuli i zapisuje wystarczającą ilość informacji, aby druga faza wykonała swoją pracę. W praktyce oznacza to zarejestrowanie unikalnego identyfikatora dla każdego kwalifikującego się wiersza (klucze indeksu klastrowego lub identyfikator wiersza sterty) oraz nową wartość wynagrodzenia. Po zakończeniu pierwszej fazy cały zestaw informacji o aktualizacji jest przekazywany do drugiej fazy, która lokalizuje każdy rekord do aktualizacji przy użyciu unikalnego identyfikatora i zmienia wynagrodzenie na nową wartość. Trzecia faza następnie sprawdza, czy żadne ograniczenia integralności bazy danych nie zostały naruszone przez końcowy stan tabeli.
Strategia iteracyjna
To podejście odczytuje jeden wiersz naraz z tabeli źródłowej. Jeśli wiersz spełnia warunki WHERE predykatu klauzuli, stosuje się podwyżkę wynagrodzenia. Ten proces powtarza się, dopóki wszystkie wiersze ze źródła nie zostaną przetworzone. Przykładowy plan wykonania przy użyciu tego modelu pokazano poniżej:

Jak zwykle w przypadku opartego na zapotrzebowaniu potoku SQL Server, wykonanie rozpoczyna się od operatora znajdującego się najbardziej po lewej stronie — UPDATE w tym przypadku. Żąda wiersza z Aktualizacji tabeli, która prosi o wiersz ze skalaru obliczeniowego, a następnie w dół łańcucha do skanowania tabeli:
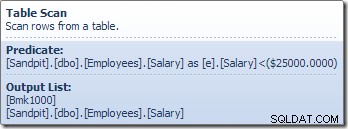
Operator Table Scan odczytuje pojedynczo wiersze z aparatu magazynu, dopóki nie znajdzie takiego, który spełnia wymagania predykatu Salary. Lista wyjściowa na powyższej grafice przedstawia operator Table Scan zwracający identyfikator wiersza i bieżącą wartość kolumny Wynagrodzenie dla tego wiersza. Pojedynczy wiersz zawierający odniesienia do tych dwóch informacji jest przekazywany do skalaru obliczeniowego:
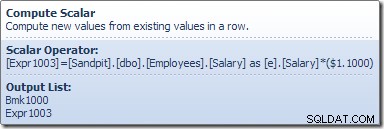
Skalar obliczeniowy definiuje wyrażenie, które stosuje podwyżkę wynagrodzenia do bieżącego wiersza. Zwraca wiersz zawierający odwołania do identyfikatora wiersza i zmodyfikowane wynagrodzenie do aktualizacji tabeli, która wywołuje aparat pamięci w celu wykonania modyfikacji danych. Ten iteracyjny proces trwa do momentu, gdy w skanowaniu tabeli zabraknie wierszy. Ten sam podstawowy proces jest stosowany, jeśli tabela ma indeks klastrowy:
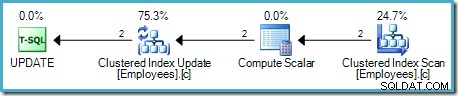
Główna różnica polega na tym, że klucze indeksu klastrowego i uniquifier (jeśli jest obecny) są używane jako identyfikator wiersza zamiast identyfikatora RID sterty.
Problem
Przejście od logicznej trójfazowej operacji zdefiniowanej w standardzie SQL do fizycznego, iteracyjnego modelu wykonania wprowadziło szereg subtelnych zmian, z których tylko jedną przyjrzymy się dzisiaj. W naszym przykładzie może wystąpić problem, jeśli w kolumnie Wynagrodzenie znajduje się indeks nieklastrowany, którego optymalizator zapytań zdecyduje się użyć do znalezienia kwalifikujących się wierszy (Wynagrodzenie <25 000 USD):
CREATE NONCLUSTERED INDEX nc1 ON dbo.Employees (Salary);
Model wykonywania wiersz po wierszu może teraz generować nieprawidłowe wyniki, a nawet wpaść w nieskończoną pętlę. Rozważmy (wyobrażony) iteracyjny plan wykonania, który szuka indeksu wynagrodzeń, zwraca wiersz do skalaru obliczeniowego, a ostatecznie do operatora aktualizacji:

W tym planie jest kilka dodatkowych skalarów obliczeniowych ze względu na optymalizację, która pomija konserwację indeksu nieklastrowanego, jeśli wartość wynagrodzenia nie uległa zmianie (możliwe tylko dla wynagrodzenia zerowego w tym przypadku).
Ignorując to, ważną cechą tego planu jest to, że mamy teraz uporządkowane częściowe skanowanie indeksu, które przekazuje wiersz na raz do operatora, który modyfikuje ten sam indeks (zielone podświetlenie na powyższej grafice Eksploratora SQL Sentry Plan Explorer wyraźnie pokazuje klastrowany Operator aktualizacji indeksu obsługuje zarówno tabelę podstawową, jak i indeks nieklastrowany).
W każdym razie problem polega na tym, że przetwarzając jeden wiersz na raz, aktualizacja może przesunąć bieżący wiersz przed pozycję skanowania używaną przez funkcję wyszukiwania indeksu do zlokalizowania wierszy do zmiany. Praca z przykładem powinna nieco rozjaśnić to stwierdzenie:
Indeks nieklastrowany jest kluczowany i sortowany rosnąco według wartości wynagrodzenia. Indeks zawiera również wskaźnik do wiersza nadrzędnego w tabeli podstawowej (identyfikator RID sterty lub klucze indeksu klastrowego plus unikyfikator, jeśli to konieczne). Aby ułatwić śledzenie przykładu, załóżmy, że tabela podstawowa ma teraz unikalny indeks klastrowy w kolumnie Nazwa, więc zawartość indeksu nieklastrowanego na początku przetwarzania aktualizacji to:
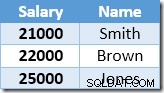
Pierwszy wiersz zwrócony przez Index Seek to pensja Smitha w wysokości 21 000 USD. Ta wartość jest aktualizowana do 23 100 USD w tabeli podstawowej i indeksie nieklastrowym przez operator Clustered Index. Indeks nieklastrowy zawiera teraz:
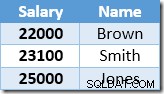
Następny wiersz zwrócony przez funkcję Index Seek będzie wpisem o wartości 22 000 USD dla Browna, który został zaktualizowany do 24 200 USD:
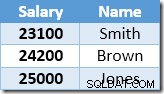
Teraz funkcja Index Seek znajduje wartość 23 100 USD dla Smitha, która jest aktualizowana ponownie , do 25 410 USD. Proces ten trwa, dopóki wszyscy pracownicy nie uzyskają wynagrodzenia w wysokości co najmniej 25 000 USD – co nie jest prawidłowym wynikiem dla danej UPDATE zapytanie. Ten sam efekt w innych okolicznościach może prowadzić do niekontrolowanej aktualizacji, która kończy się dopiero wtedy, gdy serwerowi zabraknie miejsca w logu lub wystąpi błąd przepełnienia (może wystąpić w tym przypadku, jeśli ktoś miałby zerową pensję). To jest problem Halloween, ponieważ dotyczy aktualizacji.
Unikanie problemu Halloween w przypadku aktualizacji
Czytelnicy o orlim wzroku zauważą, że szacunkowe wartości procentowe kosztów w wyimaginowanym planie Index Seek nie sumują się do 100%. To nie jest problem z Plan Explorerem – celowo usunąłem kluczowego operatora z planu:

Optymalizator zapytań rozpoznaje, że ten plan aktualizacji potokowej jest podatny na problem Halloween, i wprowadza bufor tabeli Chętny, aby zapobiec jego wystąpieniu. Nie ma podpowiedzi ani flagi śledzenia, aby uniemożliwić włączenie bufora do tego planu wykonania, ponieważ jest to wymagane dla poprawności.
Jak sama nazwa wskazuje, buforowanie chętnie zużywa wszystkie wiersze swojego operatora podrzędnego (Index Seek) przed zwróceniem wiersza do swojego rodzica Compute Scalar. Efektem tego jest wprowadzenie całkowitej separacji faz – wszystkie kwalifikujące się wiersze są odczytywane i zapisywane w pamięci tymczasowej przed wykonaniem jakichkolwiek aktualizacji.
To przybliża nas do trójfazowej logicznej semantyki standardu SQL, choć pamiętaj, że wykonanie planu jest nadal zasadniczo iteracyjne, z operatorami po prawej stronie bufora tworzącymi kursor odczytu , a operatory po lewej stronie tworzą kursor zapisu . Zawartość szpuli jest nadal odczytywana i przetwarzana wiersz po wierszu (nie jest przekazywana en masse ponieważ porównanie ze standardem SQL mogłoby w inny sposób doprowadzić do przekonania).
Wady rozdziału faz są takie same, jak wspomniano wcześniej. Bufor tabeli zużywa tempdb miejsce (strony w puli buforów) i może wymagać fizycznych odczytów i zapisów na dysku pod obciążeniem pamięci. Optymalizator zapytań przypisuje szacowany koszt do szpuli (z zastrzeżeniem wszystkich zwykłych zastrzeżeń dotyczących szacowania) i wybiera między planami, które wymagają ochrony przed problemem Halloween, a tymi, które tego nie robią na podstawie szacowanego kosztu w normalny sposób. Oczywiście optymalizator może błędnie wybrać jedną z opcji z dowolnego z normalnych powodów.
W tym przypadku kompromis polega na zwiększeniu wydajności poprzez szukanie bezpośrednio kwalifikujących się rekordów (tych z pensją <25 000 USD) w porównaniu z szacowanym kosztem szpuli wymaganym do uniknięcia problemu Halloween. Plan alternatywny (w tym konkretnym przypadku) to pełne skanowanie indeksu klastrowego (lub sterty). Ta strategia nie wymaga takiej samej ochrony Halloween, ponieważ klawisze indeksu klastrowanego nie są modyfikowane:

Ponieważ klawisze indeksu są stabilne, wiersze nie mogą przesuwać pozycji w indeksie między iteracjami, unikając w tym przypadku problemu Halloween. W zależności od kosztu środowiska wykonawczego klastrowego skanowania indeksu w porównaniu z wcześniej widzianą kombinacją wyszukiwania indeksu i buforowania tabeli chętnych, jeden plan może zostać wykonany szybciej niż drugi. Inną kwestią jest to, że plan z Ochroną Halloween uzyska więcej blokad niż plan w pełni potokowy, a blokady będą utrzymywane dłużej.
Ostateczne myśli
Zrozumienie problemu Halloween i wpływu, jaki może on mieć na plany zapytań dotyczących modyfikacji danych, pomoże ci przeanalizować plany wykonania zmiany danych i może zaoferować możliwości uniknięcia kosztów i skutków ubocznych niepotrzebnej ochrony tam, gdzie dostępna jest alternatywa.
Istnieje kilka form problemu Halloween, z których nie wszystkie są spowodowane czytaniem i pisaniem do kluczy wspólnego indeksu. Problem Halloween nie ogranicza się również do UPDATE zapytania. Optymalizator zapytań ma więcej sztuczek w rękawie, aby uniknąć problemu Halloween, poza separacją faz metodą brute-force przy użyciu bufora tabeli Chętni. Te (i nie tylko) punkty zostaną omówione w kolejnych częściach tej serii.
[ Część 1 | Część 2 | Część 3 | Część 4 ]