Autor gościnny:Andy Mallon (@AMtwo)
Nie, poważnie. Co to jest DTU?
Kiedy wdrażasz jakąkolwiek aplikację, jednym z pierwszych pytań, które się pojawiają, jest „Ile to będzie kosztować?” Większość z nas w pewnym momencie przeszła przez tego rodzaju ćwiczenie, aby określić rozmiar instalacji SQL Server, ale co, jeśli wdrażasz w chmurze? Dzięki wdrożeniom usługi Azure IaaS niewiele się zmieniło — nadal budujesz serwer na podstawie liczby procesorów, pewnej ilości pamięci i konfiguracji magazynu, aby zapewnić wystarczającą liczbę operacji we/wy na sekundę dla obciążenia. Jednak po przejściu do PaaS rozmiar bazy danych SQL Azure jest dostosowany do różnych warstw usług, w których wydajność jest mierzona w jednostkach DTU. Co to do cholery jest DTU?
Wiem, czym jest BTU. Może DTU to skrót od Database Thermal Unit? Czy jest to ilość mocy obliczeniowej potrzebna do podniesienia temperatury centrum danych o jeden stopień? Zamiast zgadywać, sprawdźmy dokumentację i zobaczmy, co Microsoft ma do powiedzenia:
[Database Transaction Unit] to mieszana miara operacji we/wy procesora, pamięci i danych oraz we/wy dziennika transakcji w stosunku określonym przez obciążenie testowe OLTP, zaprojektowane jako typowe dla rzeczywistych obciążeń OLTP. Podwojenie jednostek DTU przez zwiększenie poziomu wydajności bazy danych jest równoznaczne z podwojeniem zestawu zasobów dostępnych dla tej bazy danych.OK, to było moje drugie przypuszczenie – ale co to jest „mieszana miara”? Jak mogę przetłumaczyć moją wiedzę na temat określania rozmiaru serwera na określanie rozmiaru bazy danych SQL Azure? Niestety nie ma prostego sposobu na przetłumaczenie „2 rdzeni procesora i 4 GB pamięci” na pomiar DTU.
Czy nie ma kalkulatora DTU?
Tak! Microsoft daje nam kalkulator DTU do oszacowania właściwą warstwę usług Azure SQL Database. Aby z niego skorzystać, pobierz i uruchom skrypt PowerShell (sql-perfmon.ps1) na serwerze podczas uruchamiania obciążenia w programie SQL Server. Skrypt generuje plik CSV, który zawiera cztery liczniki wydajności:(1) całkowity % czasu procesora, (2) całkowitą liczbę odczytów dysku na sekundę, (3) całkowitą liczbę zapisów na dysku na sekundę oraz (4) całkowitą liczbę opróżnionych bajtów dziennika na sekundę. Te dane wyjściowe w formacie CSV są następnie przesyłane do kalkulatora DTU, który szacuje, jaka warstwa usług najlepiej spełni Twoje potrzeby. Jedyne dane, które Kalkulator DTU pobiera oprócz pliku CSV, to liczba rdzeni procesora na serwerze, który wygenerował plik. Kalkulator DTU to wciąż trochę czarna skrzynka — nie jest łatwo mapować to, co wiemy z naszych lokalnych baz danych na platformę Azure.
Chciałbym zwrócić uwagę, że definicja jednostki DTU jest taka, że jest to „mieszana miara procesora, pamięć oraz we/wy danych i we/wy dziennika transakcji…” Żaden z liczników wydajności używanych przez kalkulator DTU nie uwzględnia pamięci, ale jest wyraźnie wymieniony w definicji jako część obliczeń. Niekoniecznie jest to problem, ale jest to dowód na to, że kalkulator DTU nie będzie doskonały.
Wrzucę trochę syntetycznego obciążenia do kalkulatora DTU i zobaczę, czy uda mi się rozgryźć, jak działa ta czarna skrzynka. W rzeczywistości całkowicie sfabrykuję pliki CSV, abym mógł całkowicie kontrolować liczby perfmon, które ładujemy do kalkulatora DTU. Przejdźmy przez jedną metrykę na raz. Dla każdej metryki prześlemy sfabrykowane dane o wartości 25 minut (1500 sekund – lubię okrągłe liczby) i zobaczymy, jak te dane perfmon są konwertowane na jednostki DTU.
Procesor
Zamierzam stworzyć plik CSV, który symuluje 16-rdzeniowy serwer, powoli zwiększając wykorzystanie procesora, aż do osiągnięcia 100%. Ponieważ zamierzam symulować wzrost na 16-rdzeniowym serwerze, stworzę mój plik CSV, aby zwiększał się o 1/16 miejsca naraz - zasadniczo symulując maksymalizację jednego rdzenia, następnie drugiego maksymalizacji, a następnie trzeciego, itd. Przez cały czas CSV będzie pokazywał zero odczytów, zapisów i opróżnień dziennika. Serwer nigdy nie wygenerowałby takiego obciążenia — ale o to właśnie chodzi. Całkowicie izoluję wykorzystanie procesora, aby móc zobaczyć, jak procesor wpływa na jednostki DTU.
Utworzę plik CSV, który ma jeden wiersz na sekundę, a co 94 sekundy będę zwiększać licznik całkowitego czasu procesora % o ~6%. Pozostałe trzy liczniki będą we wszystkich przypadkach wyzerowane. Teraz przesyłam ten plik do kalkulatora DTU (i mówię kalkulatorowi DTU, aby rozważył 16 rdzeni), a oto wynik:
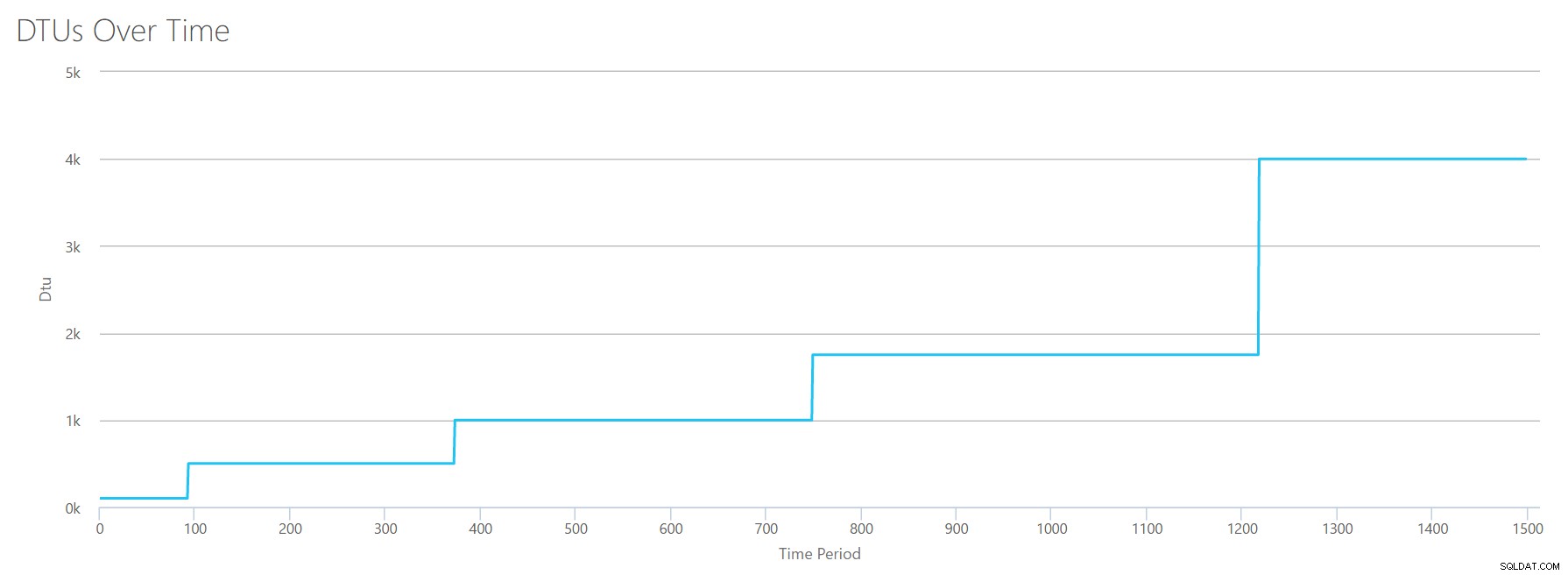
Czekać? Czy nie zwiększyłem wykorzystania procesora w 16 równych krokach? Ten wykres DTU pokazuje tylko pięć kroków. Musiałem schrzanić. Nie – mój plik CSV miał 16 równych kroków, ale to (najwyraźniej) nie przekłada się równomiernie na jednostki DTU. Przynajmniej nie według kalkulatora DTU. W oparciu o nasz test maksymalnego wykorzystania procesora, nasze mapowanie warstwy procesora do jednostki DTU na usługę wyglądałoby tak:
| Liczba rdzeni | DTU | Poziom usług |
|---|---|---|
| 1 | 100 | Standardowy – S3 |
| 2-4 | 500 | Premium – P4 |
| 5-8 | 1000 | Premium – P6 |
| 9-13 | 1750 | Premium – P11 |
| 14-16 | 4000 | Premia – P15 |
Spojrzenie na te dane mówi nam kilka rzeczy:
- Jeden rdzeń procesora w 100% wykorzystany to 100 jednostek DTU.
- DTU zwiększają rodzaj liniowo wraz ze wzrostem procesora, ale pozornie w napadach i zrywach.
- Warstwy usług Podstawowa i Standardowa są równe mniej niż jednemu rdzeniowi procesora.
- Każdy serwer wielordzeniowy przekształciłby się w pewien rozmiar w warstwie usługi Premium.
Czyta
Tym razem użyję tej samej metodologii. Wygeneruję CSV ze wzrastającymi liczbami dla licznika odczytów/sekundę, z innymi licznikami perfmon na zero. Z czasem będę powoli zwiększał tę liczbę. Tym razem zwiększajmy porcje 2000, co 100 sekund, aż osiągniemy 30000. To daje nam ten sam całkowity czas 25 minut – jednak tym razem mam 15 kroków zamiast 16. (lubię okrągłe liczby).
Kiedy przesyłamy ten plik CSV do kalkulatora DTU, otrzymujemy następujący wykres DTU:
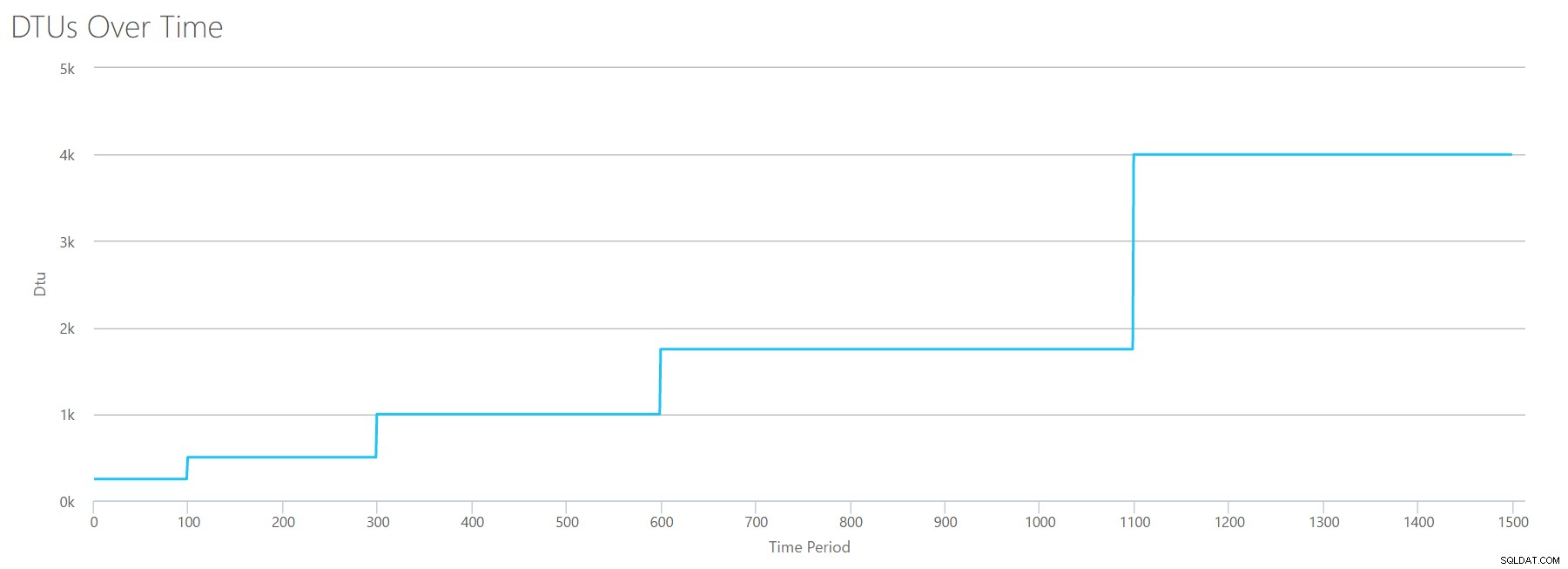
Poczekaj chwilę… wygląda to całkiem podobnie do pierwszego wykresu. Ponownie, zwiększa się w 5 nierównych krokach, mimo że w moim pliku miałem 15 równych kroków. Spójrzmy na to w formacie tabelarycznym:
| Odczyty/s | DTU | Poziom usług |
|---|---|---|
| 2000 | 250 | Premium – P2 |
| 4000-6000 | 500 | Premium – P4 |
| 8000-12000 | 1000 | Premium – P6 |
| 14000-22000 | 1750 | Premium – P11 |
| 24000-30000 | 4000 | Premium – P15 |
Ponownie widzimy, że poziomy Podstawowy i Standardowy są dość szybko przeskakiwane (mniej niż 2000 odczytów/s), ale warstwa Premium jest dość szeroka i obejmuje od 2000 do 30000 odczytów na sekundę. W powyższej tabeli „Odczyty/s” można prawdopodobnie uznać za „IOPS”… Lub, technicznie, po prostu „OPS”, ponieważ nie ma zapisów stanowiących „wejściową” część IOPS.
Pisze
Jeśli utworzymy plik CSV przy użyciu tej samej formuły, której użyliśmy do odczytów, i prześlemy ten plik CSV do kalkulatora DTU, otrzymamy wykres identyczny z wykresem dla odczytów:
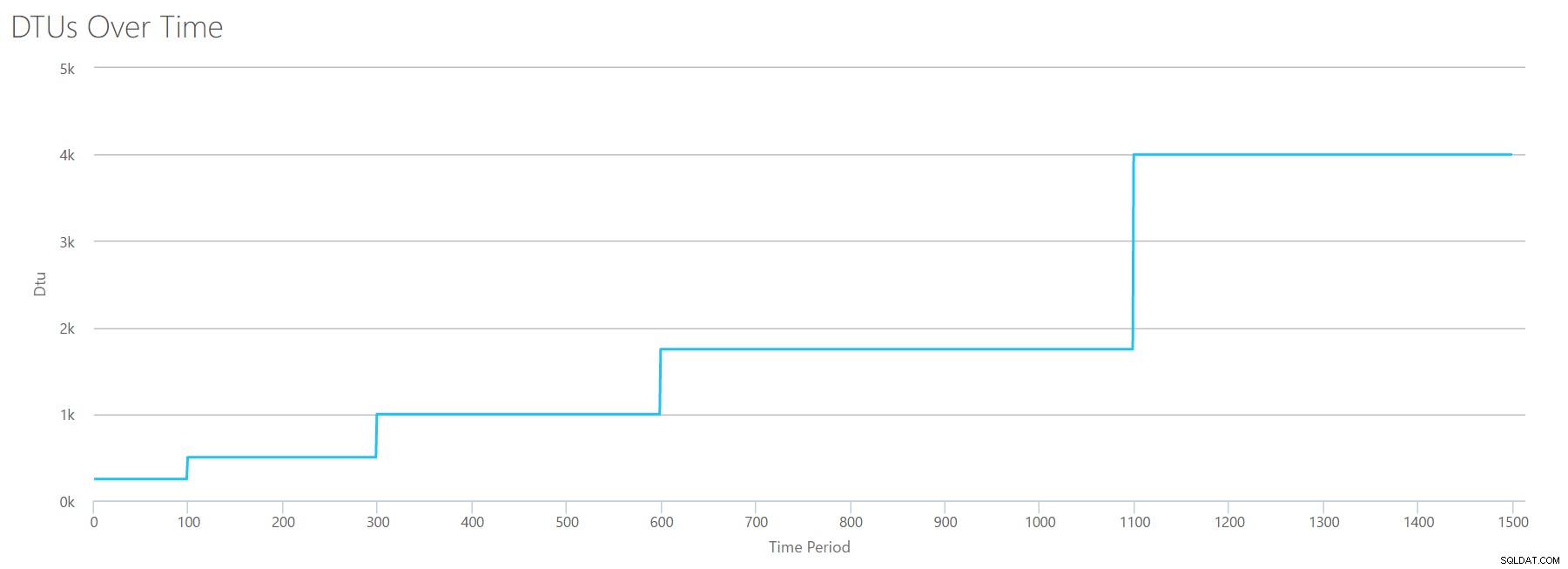
IOPS to IOPS, więc niezależnie od tego, czy jest to odczyt, czy zapis, wygląda na to, że obliczenia DTU uwzględniają je w równym stopniu. Wydaje się, że wszystko, co wiemy (lub myślimy, że wiemy) o odczytach, odnosi się w równym stopniu do zapisów.
Opróżniono bajty dziennika
Dotarliśmy do ostatniego licznika perfmon:bajty dziennika opróżniane na sekundę. Jest to kolejna miara IO, ale specyficzna dla dziennika transakcji SQL Server. Jeśli do tej pory nie zrozumiałeś, tworzę te pliki CSV, aby wysokie wartości były obliczane jako P15 Azure DB, a następnie po prostu dzielę wartość, aby podzielić ją na równe kroki. Tym razem zamierzamy przejść od 5 milionów do 75 milionów w krokach co 5 milionów. Podobnie jak we wszystkich poprzednich testach, pozostałe liczniki perfmon będą wynosić zero. Ponieważ ten licznik perfmonów jest podawany w bajtach na sekundę, a my mierzymy w milionach, możemy pomyśleć o jednostce, z którą czujemy się bardziej komfortowo:megabajtach na sekundę.
Przesyłamy ten plik CSV do kalkulatora DTU i otrzymujemy następujący wykres:
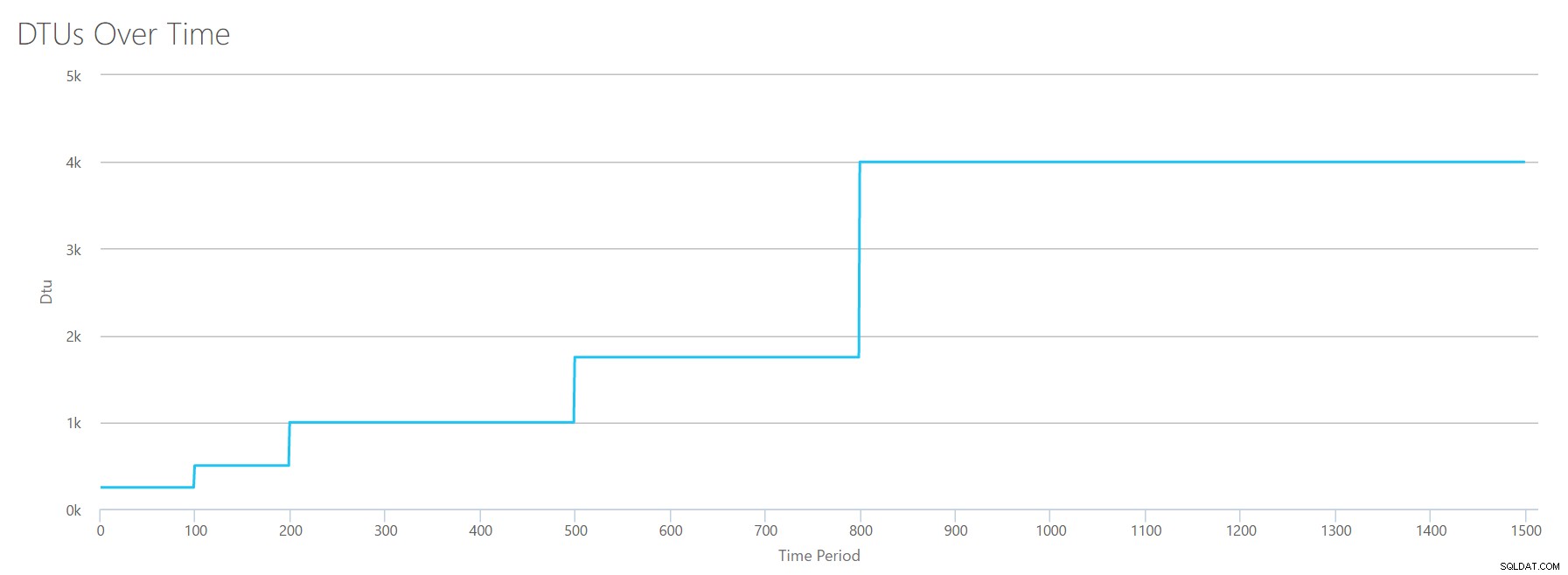
| Megabajty dziennika opróżnione/s | DTU | Poziom usług |
|---|---|---|
| 5 | 250 | Premium – P2 |
| 10 | 500 | Premium – P4 |
| 15-25 | 1000 | Premium – P6 |
| 30-40 | 1750 | Premium – P11 |
| 45-75 | 4000 | Premium – P15 |
Kształt tego wykresu staje się dość przewidywalny. Tyle że tym razem przechodzimy przez poziomy nieco szybciej, osiągając P15 po zaledwie 8 krokach (w porównaniu do 11 dla IO i 12 dla CPU). To może prowadzić do myślenia:„To będzie moje najwęższe gardło!” ale nie byłbym tego taki pewien. Jak często generujesz 75 MB dziennika w ciągu sekundy? ? To 4,5 GB na minutę . To dużo aktywności w bazach danych. Moje syntetyczne obciążenie niekoniecznie jest obciążeniem realistycznym.
Łączenie wszystkiego
OK, teraz, gdy widzieliśmy, gdzie niektóre górne limity są w izolacji, połączę dane i zobaczę, jak się porównują, gdy procesor, we/wy i we/wy dziennika transakcji zachodzą jednocześnie – w końcu , czy nie tak to się dzieje?
Aby zbudować ten plik CSV, po prostu wziąłem istniejące wartości, których użyliśmy dla każdego powyższego testu, i połączyłem te wartości w jeden plik CSV, który daje ten piękny wykres:
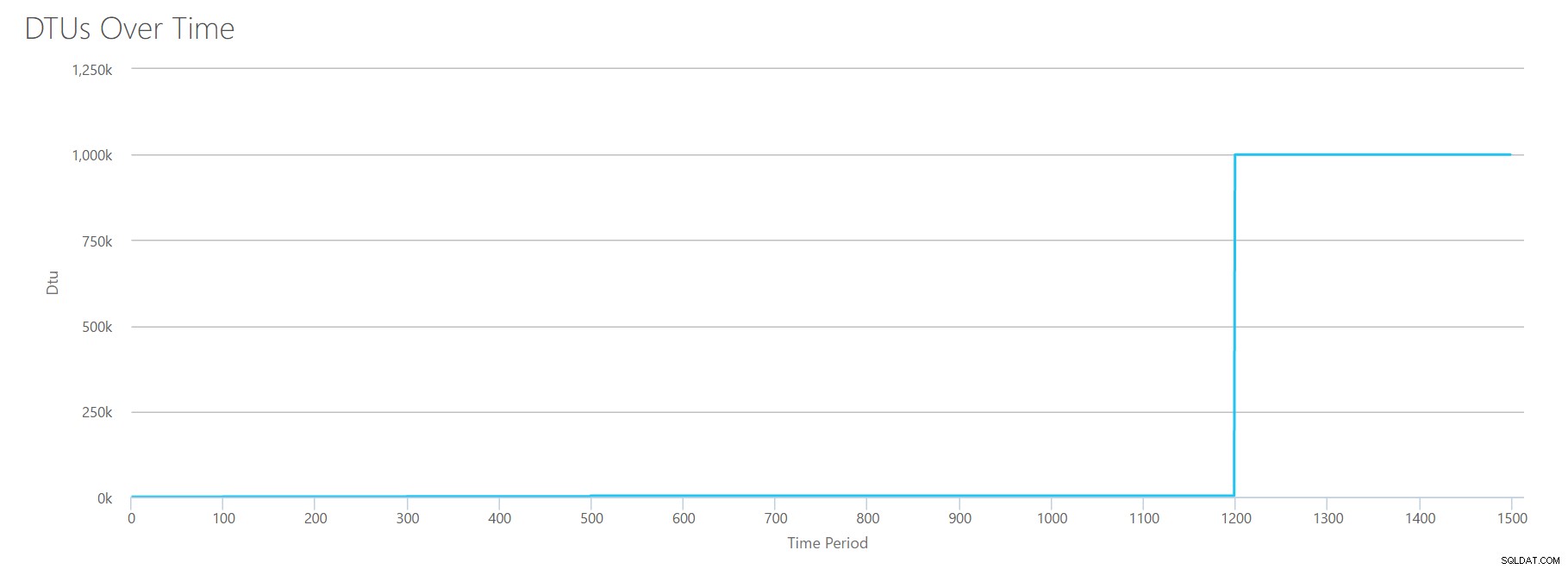
Daje również komunikat:
W oparciu o wykorzystanie bazy danych Twoje obciążenie SQL Server jest poza zakresem . W tej chwili nie istnieje poziom usługi/poziom wydajności, który obejmowałby Twoje wykorzystanie.Jeśli spojrzysz na oś Y, zobaczysz, że trafiliśmy „1,000k” (tj. 1 milion) DTU w 1200 sekundzie znaku. To wydaje się… uhh… złe? Jeśli spojrzymy na powyższe testy, 1200 sekund nastąpiło, gdy wszystkie 4 indywidualne metryki osiągnęły poziom 4000 DTU, poziom P15. To ma sens, że bylibyśmy poza zasięgiem, ale kształt wykresu nie ma dla mnie sensu – myślę, że kalkulator DTU po prostu wyrzucił swoje ręce i powiedział:„Nieważne, Andy. To dużo. dużo. To bajillion DTU. To obciążenie nie pasuje do Azure SQL Database."
OK, więc co się dzieje przed 1200 sekund znaku? Skróćmy plik CSV i prześlijmy go ponownie do kalkulatora mając tylko pierwsze 1200 sekund. Maksymalne wartości dla każdej kolumny to:81% procesora (lub apx 13 rdzeni przy 100%), 24000 odczytów/s, 24000 zapisów/s i 60 MB opróżnionych dzienników/s.
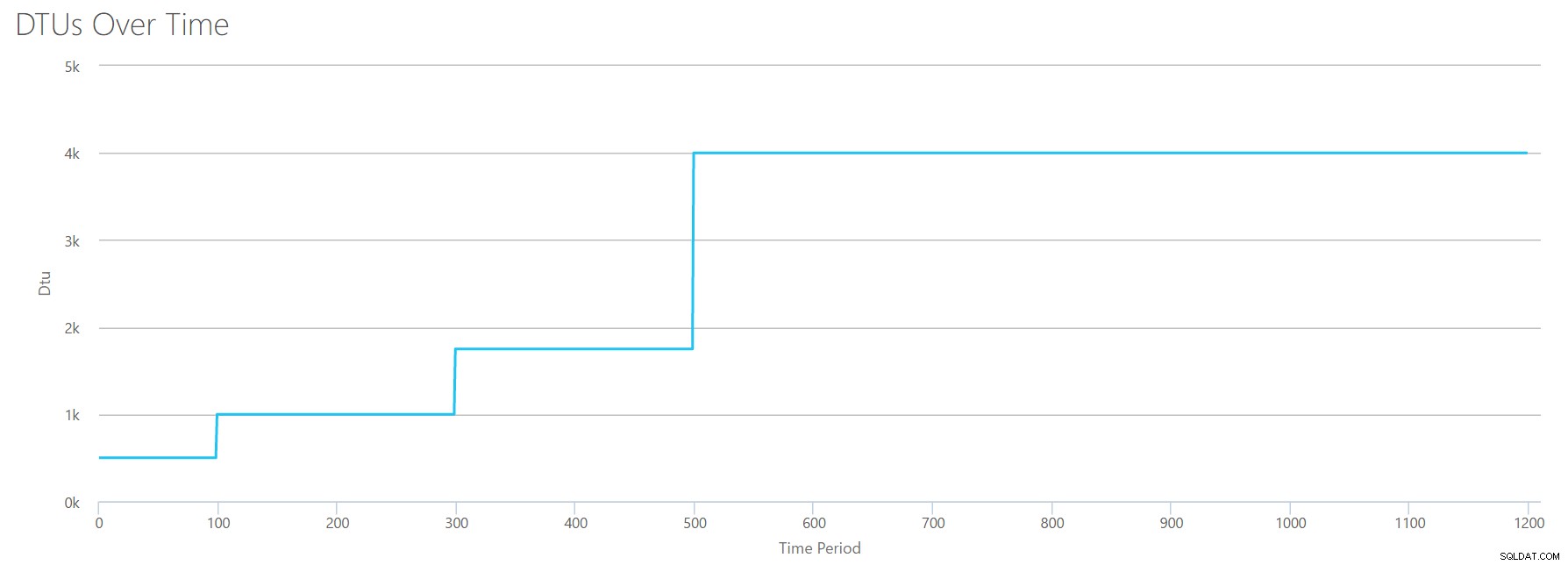
Witaj stary przyjacielu… Ten znajomy kształt powraca. Oto podsumowanie danych z pliku CSV i szacunków kalkulatora DTU dla całkowitego użycia jednostek DTU i poziomu usług.
| Liczba rdzeni | Odczyty/s | Zapisów/s | Megabajty dziennika opróżnione/s | DTU | Poziom usług |
|---|---|---|---|---|---|
| 1 | 2000 | 2000 | 5 | 500 | Premium – P4 |
| 2-3 | 4000-6000 | 4000-6000 | 10 | 1000 | Premium – P6 |
| 4-5 | 8000-10000 | 8000-10000 | 15-25 | 1750 | Premium – P11 |
| 6-13 | 12000-24000 | 12000-24000 | 30-40 | 4000 | Premium – P15 |
Teraz przyjrzyjmy się, jak poszczególne obliczenia DTU (kiedy ocenialiśmy je oddzielnie) w porównaniu z obliczeniami DTU z ostatniej kontroli:
| CPU DTU | Odczytaj jednostki DTU | Zapisz jednostki DTU | DTU opróżniania dziennika | Suma całkowitej liczby jednostek DTU | Oszacowanie kalkulatora DTU | Poziom usług |
|---|---|---|---|---|---|---|
| 100 | 250 | 250 | 250 | 850 | 500 | Premium – P4 |
| 500 | 500 | 500 | 500 | 2000 | 1000 | Premium – P6 |
| 500-1000 | 1000 | 1000 | 1000 | 3500-4000 | 1750 | Premium – P11 |
| 1000-1750 | 1000-1750 | 1000-1750 | 1750 | 4750-7000 | 4000 | Premium – P15 |
Zauważysz, że obliczenie DTU nie jest tak proste, jak dodanie osobnych DTU. Jak mówi definicja, którą przytoczyłem na początku, jest to „mieszana miara” tych oddzielnych metryk. Formuła używana do „mieszania” jest skomplikowana i tak naprawdę nie mamy tej formuły. Widzimy, że szacunki kalkulatora DTU są niższe niż suma oddzielnych obliczeń DTU.
Mapowanie jednostek DTU na tradycyjny sprzęt
Weźmy dane z kalkulatora DTU i spróbujmy zebrać kilka przypuszczeń dotyczących mapowania tradycyjnego sprzętu na niektóre warstwy Azure SQL Database.
Po pierwsze, załóżmy, że „odczyty/s” i „zapisy/s” są tłumaczone bezpośrednio na IOPS, bez potrzeby tłumaczenia. Po drugie, załóżmy, że dodanie tych dwóch liczników da nam całkowitą liczbę IOPS. Po trzecie, przyznajmy, że nie mamy pojęcia, czym jest użycie pamięci, i nie mamy sposobu, aby wyciągnąć jakiekolwiek wnioski na tym froncie.
Podczas szacowania specyfikacji sprzętu wybiorę również możliwy rozmiar maszyny wirtualnej platformy Azure, który będzie pasował do każdej konfiguracji sprzętowej. Istnieje wiele podobnych rozmiarów maszyn wirtualnych Azure, z których każdy jest zoptymalizowany pod kątem różnych metryk wydajności, ale poszedłem dalej i ograniczyłem się do serii A i DSv2.
| Liczba rdzeni | IOPS | Pamięć | DTU | Poziom usług | Porównywalny rozmiar maszyny wirtualnej Azure |
|---|---|---|---|---|---|
| 1 rdzeń, 5% wykorzystania | 10 | ??? | 5 | Podstawowe | Standard_A0, rzadko używany |
| <1 rdzeń | 150 | ??? | 100 | Standardowy S0-S3 | Standard_A0, nie w pełni wykorzystany |
| 1 rdzeń | do 4000 | ??? | 500 | Premium – P4 | Standard_DS1_v2 |
| 2-3 rdzenie | do 12000 | ??? | 1000 | Premium – P6 | Standard_DS3_v2 |
| 4-5 rdzeni | do 20000 | ??? | 1750 | Premium – P11 | Standard_DS4_v2 |
| 6-13 | do 48000 | ??? | 4000 | Premium – P15 | Standard_DS5_v2 |
Poziom podstawowy jest niesamowicie ograniczony. Jest dobry do okazjonalnego/okazjonalnego użytku i jest tanim sposobem na „zaparkowanie” bazy danych, gdy jej nie używasz. Ale jeśli używasz prawdziwej aplikacji, warstwa Podstawowa nie będzie dla Ciebie działać.
Poziom Standardowy również jest dość ograniczony, ale w przypadku małych aplikacji jest w stanie spełnić Twoje potrzeby. Jeśli masz serwer 2-rdzeniowy z kilkoma bazami danych, te bazy danych mogą pasować do warstwy Standardowa. Podobnie, jeśli masz serwer z tylko jedną bazą danych z 1 rdzeniem procesora w 100% (lub 2 rdzeniami z 50%), prawdopodobnie wystarczy moc wystarczająca, aby przechylić skalę do warstwy usług Premium-P1.
Jeśli korzystasz z serwera wielordzeniowego w środowisku lokalnym (lub IaaS), będziesz szukać w warstwie usług Premium w Azure SQL Database. To tylko kwestia określenia, ile mocy procesora i we/wy potrzebujesz do obciążenia. Twój 2-rdzeniowy serwer o pojemności 4 GB prawdopodobnie zapewnia lokalizację w pobliżu bazy danych SQL Azure SQL P6. W przypadku czystego obciążenia procesora (z zerowym we/wy) baza danych P15 może obsłużyć 16 rdzeni przetwarzania, ale po dodaniu we/wy do miksu wszystko, co jest większe niż ~12 rdzeni, nie mieści się w Azure SQL Database.
Następnym razem wezmę trochę rzeczywistych obciążeń i porównam wydajność w różnych warstwach usług. Czy szacunki Kalkulatora DTU będą dokładne? Dowiemy się.
O autorze
 Andy Mallon jest administratorem baz danych SQL Server i Microsoft Data Platform MVP, który zarządza bazami danych w służbie zdrowia, finansach, e - handel i sektory non-profit. Od 2003 roku Andy wspiera środowiska OLTP o dużej objętości i wysokiej dostępności o wysokich wymaganiach w zakresie wydajności. Andy jest założycielem BostonSQL, współorganizatorem SQLSaturday Boston i blogów w am2.co.
Andy Mallon jest administratorem baz danych SQL Server i Microsoft Data Platform MVP, który zarządza bazami danych w służbie zdrowia, finansach, e - handel i sektory non-profit. Od 2003 roku Andy wspiera środowiska OLTP o dużej objętości i wysokiej dostępności o wysokich wymaganiach w zakresie wydajności. Andy jest założycielem BostonSQL, współorganizatorem SQLSaturday Boston i blogów w am2.co.