Niedawno zostałem skarcony za sugerowanie, że w niektórych przypadkach indeks nieklastrowy będzie działał lepiej dla określonego zapytania niż indeks klastrowy. Ta osoba stwierdziła, że indeks klastrowy jest zawsze najlepszy, ponieważ z definicji zawsze obejmuje, oraz że każdy indeks nieklastrowany z niektórymi lub wszystkimi tymi samymi kolumnami kluczy był zawsze zbędny.
Z radością zgodzę się, że indeks klastrowy zawsze obejmuje (i aby uniknąć tutaj jakichkolwiek niejasności, będziemy trzymać się tabel opartych na dyskach z tradycyjnymi indeksami B-drzewa).
 Nie zgadzam się jednak, że indeks klastrowy jest zawsze szybciej niż indeks nieklastrowy. Nie zgadzam się również, że zawsze jest zbędne tworzenie indeksu nieklastrowanego lub ograniczenia unikatowego składającego się z tych samych (lub niektórych z tych samych) kolumn w kluczu klastrowania.
Nie zgadzam się jednak, że indeks klastrowy jest zawsze szybciej niż indeks nieklastrowy. Nie zgadzam się również, że zawsze jest zbędne tworzenie indeksu nieklastrowanego lub ograniczenia unikatowego składającego się z tych samych (lub niektórych z tych samych) kolumn w kluczu klastrowania.
Weźmy ten przykład, Warehouse.StockItemTransactions , z WideWorldImporters. Indeks klastrowy jest implementowany za pomocą klucza podstawowego tylko w StockItemTransactionID kolumna (dość typowa, gdy masz jakiś zastępczy identyfikator wygenerowany przez TOŻSAMOŚĆ lub SEKWENCJĘ).
Dość powszechną rzeczą jest wymaganie zliczenia całej tabeli (chociaż w wielu przypadkach są lepsze sposoby). Może to być doraźne oględziny lub jako część procedury stronicowania. Większość ludzi zrobi to w ten sposób:
SELECT COUNT(*) FROM Warehouse.StockItemTransactions;
W bieżącym schemacie zostanie użyty indeks nieklastrowy:
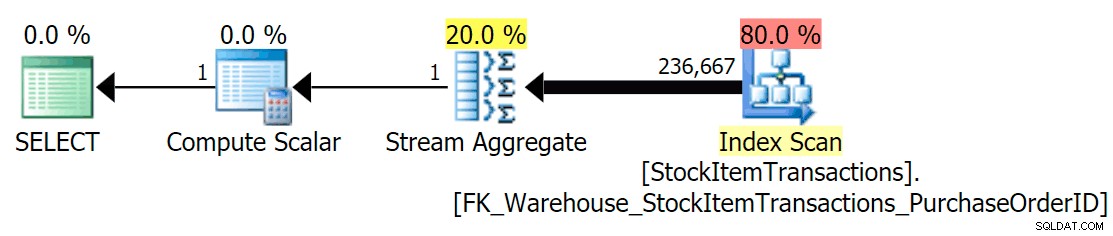
Wiemy, że indeks nieklastrowy nie zawiera wszystkich kolumn w indeksie klastrowym. Operacja liczenia musi tylko mieć pewność, że wszystkie wiersze są uwzględnione, bez zwracania uwagi na to, które kolumny są obecne, więc SQL Server zwykle wybierze indeks z najmniejszą liczbą stron (w tym przypadku wybrany indeks ma ~414 stron).
Teraz uruchommy zapytanie ponownie, tym razem porównując je do zapytania ze wskazówką, które wymusza użycie indeksu klastrowego.
SELECT COUNT(*) FROM Warehouse.StockItemTransactions; SELECT COUNT(*) /* with hint */ FROM Warehouse.StockItemTransactions WITH (INDEX(1));
Otrzymujemy prawie identyczny kształt planu, ale widzimy ogromną różnicę w odczytach (414 dla wybranego indeksu w porównaniu do 1982 dla indeksu klastrowego):
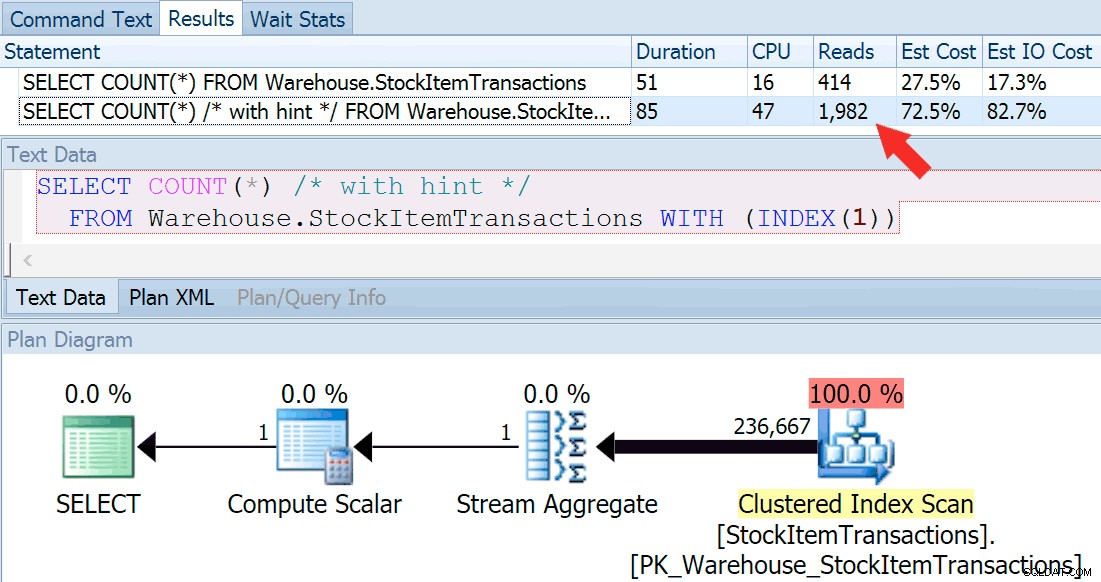
Czas trwania jest nieco wyższy dla indeksu klastrowego, ale różnica jest znikoma, gdy mamy do czynienia z małą ilością danych w pamięci podręcznej na szybkim dysku. Ta rozbieżność byłaby znacznie wyraźniejsza przy większej ilości danych, na wolnym dysku lub w systemie z obciążeniem pamięci.
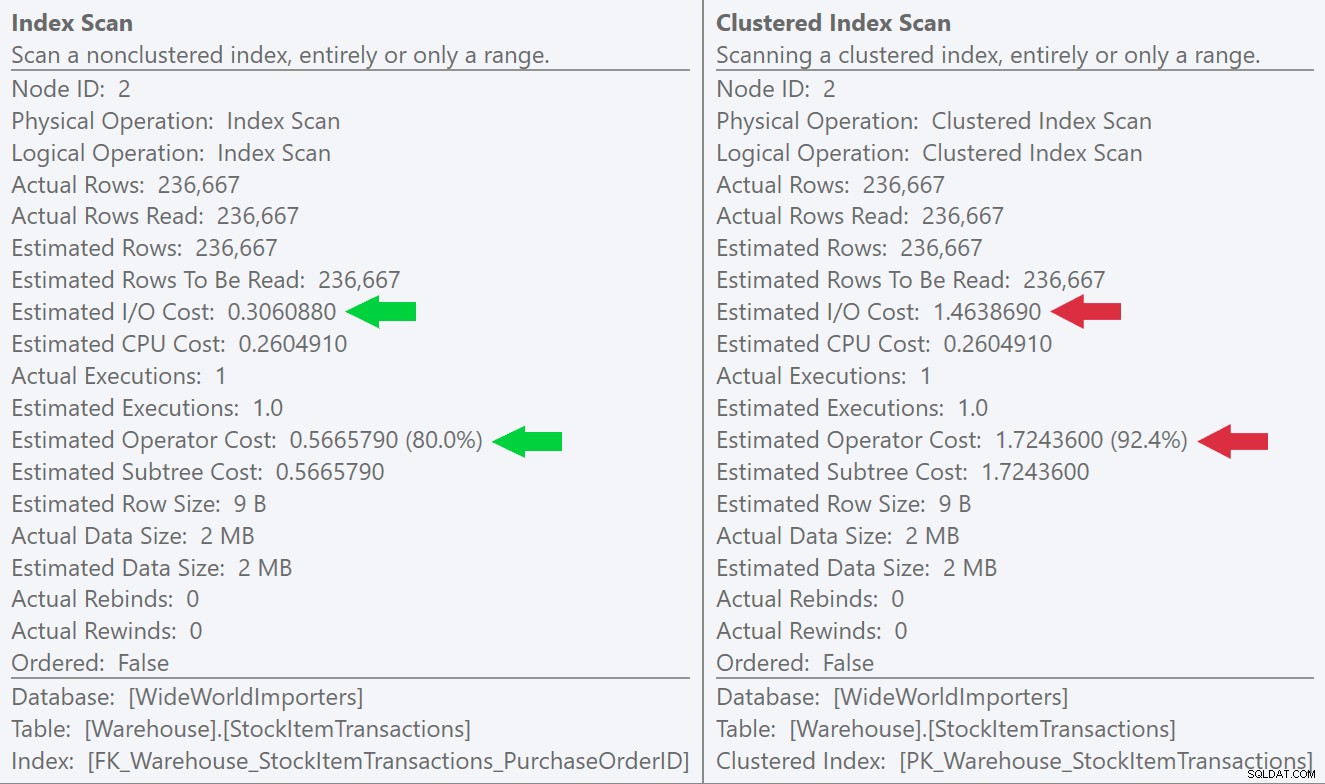
Jeśli spojrzymy na podpowiedzi dla operacji skanowania, zobaczymy, że chociaż liczba wierszy i szacowane koszty procesora są identyczne, duża różnica wynika z szacowanego kosztu operacji we/wy (ponieważ SQL Server wie, że w indeks klastrowy niż indeks nieklastrowy):
Możemy zobaczyć tę różnicę jeszcze wyraźniej, jeśli utworzymy nowy, unikalny indeks tylko na kolumnie ID (co czyni go „zbędnym” w przypadku indeksu klastrowego, prawda?):
CREATE UNIQUE INDEX NewUniqueNCIIndex ON Warehouse.StockItemTransactions(StockItemTransactionID);
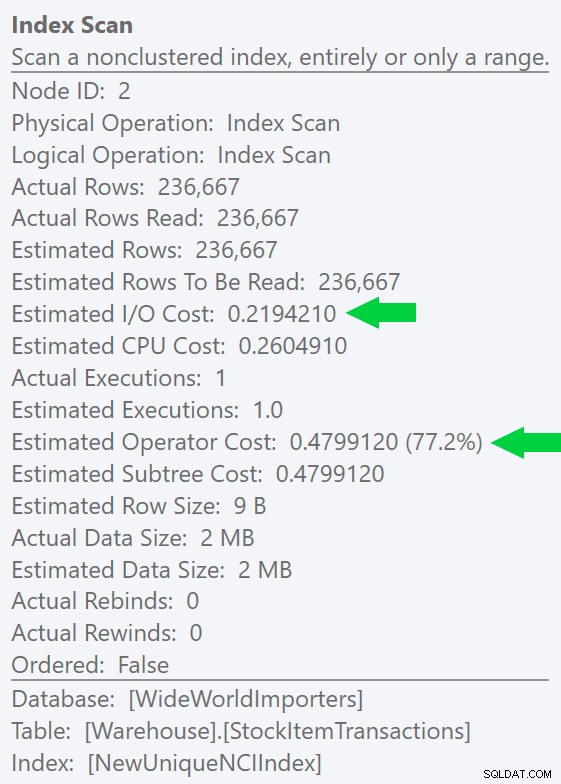 Uruchomienie podobnego zapytania z jawną wskazówką dotyczącą indeksu daje ten sam kształt planu, ale jeszcze niższy szacowany we/wy koszt (a nawet krótszy czas trwania) – patrz zdjęcie po prawej stronie. A jeśli uruchomisz oryginalne zapytanie bez podpowiedzi, zobaczysz, że SQL Server również wybiera ten indeks.
Uruchomienie podobnego zapytania z jawną wskazówką dotyczącą indeksu daje ten sam kształt planu, ale jeszcze niższy szacowany we/wy koszt (a nawet krótszy czas trwania) – patrz zdjęcie po prawej stronie. A jeśli uruchomisz oryginalne zapytanie bez podpowiedzi, zobaczysz, że SQL Server również wybiera ten indeks.
Może wydawać się to oczywiste, ale wiele osób uważa, że indeks klastrowy jest tutaj najlepszym wyborem. SQL Server prawie zawsze będzie mocno faworyzować jakąkolwiek metodę, która zapewni najtańszy sposób wykonania wszystkich operacji we/wy, aw przypadku pełnego skanowania będzie to „najchudszy” indeks. Może się to również zdarzyć w przypadku obu typów wyszukiwań (skanowania pojedynczego i zakresu), przynajmniej gdy indeks obejmuje.
Teraz, jak zawsze, to nie w jakikolwiek sposób oznacza to, że powinieneś iść i utworzyć dodatkowe indeksy we wszystkich swoich tabelach, aby spełnić zapytania licznikowe. Jest to nie tylko nieefektywny sposób sprawdzania rozmiaru tabeli (ponownie, zobacz ten artykuł), ale także indeks do obsługi, który musiałby oznaczać, że wykonujesz to zapytanie częściej niż aktualizujesz dane. Pamiętaj, że każdy indeks wymaga miejsca na dysku, miejsca w pamięci, a wszystkie zapisy w tabeli muszą również dotykać każdego indeksu (odfiltrowane indeksy na bok).
Podsumowanie
Mógłbym wymyślić wiele innych przykładów, które pokazują, kiedy nieklastrowany może być użyteczny i wart kosztów utrzymania, nawet przy duplikowaniu kluczowych kolumn indeksu klastrowego. Indeksy nieklastrowane można tworzyć z tymi samymi kolumnami kluczy, ale w innej kolejności kluczy, lub z różnymi ASC/DESC w samych kolumnach, aby lepiej obsługiwać alternatywną kolejność prezentacji. Możesz również mieć indeksy nieklastrowane, które przenoszą tylko mały podzbiór wierszy za pomocą filtra. Wreszcie, jeśli możesz spełnić swoje najczęstsze zapytania za pomocą cieńszych, nieklastrowanych indeksów, jest to również lepsze w przypadku zużycia pamięci.
Ale tak naprawdę, moim celem w tej serii jest jedynie pokazanie kontrprzykładu, który ilustruje szaleństwo wygłaszania ogólnych stwierdzeń takich jak to. Zostawię wam wyjaśnienie od Paula White'a, który w odpowiedzi DBA.SE wyjaśnia, dlaczego taki indeks nieklastrowy może w rzeczywistości działać znacznie lepiej niż indeks klastrowy. Dzieje się tak nawet wtedy, gdy obydwa używają obu typów wyszukiwania:
- Różnica między klastrowym wyszukiwaniem indeksu a nieklastrowanym wyszukiwaniem indeksu